母函数
对于一般的排列组合算法题, 可首先尝试通过母函数来解决。
在数学中,某个序列的母函数(Generating function,又称生成函数)是一种形式幂级数,其每一项的系数可以提供关于这个序列的信息。使用母函数解决问题的方法称为母函数方法。
母函数可分为很多种,包括普通母函数、指数母函数、L级数、贝尔级数和狄利克雷级数。对每个序列都可以写出以上每个类型的一个母函数。构造母函数的目的一般是为了解决某个特定的问题,因此选用何种母函数视乎序列本身的特性和问题的类型。
母函数的两个原则是:
- 把组合问题的加法法则和幂级数的乘幂对应起来
- 母函数的思想就是把离散数列和幂级数一 一对应起来,把离散数列间的相互结合关系对应成为幂级数间的运算关系,最后由幂级数形式来确定离散数列的构造
普通母函数
我们先举一个简单例子, 假设有1克、2克、3克、4克的砝码各一 枚,请问我们能称出哪几种重量?每种重量各有几种可能方案?
我们先来看看穷举的过程,先假设使用一个1g的砝码,然后再假设在此情况下,使用2g的砝码,在此基础上,再假设使用一个3g的,再假设使用一个4g的,这就是第一中情况,这种方案称出的重量为10g。
改变上面的一个假设条件,比如假设没有使用4g的,只是用了1g、2g、3g,这种方案称出的是6g,以此类推,将所有的可能列举出来后即可得到全部的方案。
在上述过程中, 每次对于1g的砝码都有两种情况,使用还是不使用,其他的砝码也一样。因此每一种砝码的状态都可以有两种砝码状态,以此类推总共就有2*2*2*2=16中方案,当然其中包含一种一个砝码也没有的0g方案。
我们最后可以穷举出结果:1g、2g、8g、9g、10g各有一种方案,3g、4g、5g、6g、7g各有两种,总共十五种,这是在不算一种0g的方案的时候,算上就是16种,和上面的过程相符。
可以看到挑选不同种类砝码之间是独立的, 也就是说假如现在有1g和2g两个砝码, 所有可能状态是, 其中||代表逻辑或, &&代表逻辑与, 每个用 “||”分开的一项都是一种方案。“&&”表示同时满足第一项和第二项的条件。:
(使用1g&&使用2g) || (不使用1g&&使用2g) || (使用1g&&不使用2g) || (不使用1g&&不使用2g)
可以看出共有四种状态, 而这四种状态可以概括为:
(使用1g || 不使用1g) && (使用2g || 不使用2g)
上面这个表达式与乘法表达式很像, 那么如果把“||”看成加法,“&&”看成乘法,和多项式的乘法一模一样。题目需要的是几种砝码组合后的重量,是一个加法关系,但是在上式中“&&”是一种类似于乘法的运算关系。我们希望找到一种运算关系,以乘法的形式运算,但是结果表现出类似于加法的关系。 因此我们自然地想到可以用幂运算来表达。
依然以1g和2g两个砝码进行说明, 假如用, 表示1g砝码, 表示2g砝码, 注意幂指数代表是几g砝码。
那么之前的 (使用1g || 不使用1g) && (使用2g || 不使用2g) 这个条件就可以通过如下运算式表示(我们之前提到过&&相当于, ||相当于+):
注意上式中的代表不使用当前砝码, 因为使用0g砝码就相当于不使用砝码。可以理解为, 本来在该放1g,2g,3g砝码的地方放入了一个 0g 砝码作为替换。所以就有:
很显然,有四种方案,0g、1g、2g、3g,结果与我们穷举的结果相同,而如果结果中有相同的项,那么合并同类项后每一项的系数就是这种重量有几种实现方案。我们现在用这种方法表示 1g,2g,3g,4g 四种砝码的所有情况。
其中代表由四种砝码组合成3g砝码共有两种情况, 1g+2g和3g本身。注意前面的系数2代表组成当前砝码质量3共有2种不同组合方式。
接着我们把问题改一下, 求用1g、2g、3g的砝码称出总重量小于10g的不同重量的方案数。这题乍看上去和之前没区别, 不过需要注意的是, 此处砝码是无限的。那么我们如何用母函数表达出 无限 这种性质呢?
我们以2g砝码为例,因为我们有无限个2g砝码,所以我们可以把2个2g砝码组合成一个4g砝码,3个2g砝码组合成一个6g砝码,依次类推,我们光靠2g砝码, 就可以扩充我们已有的砝码种类为 1g,2g,3g,4g,6g,8g,10g。如果我们按照这种方法接着对1g和3g砝码做扩充, 那么我们能得到从1g到10g的所有砝码种类。为何最大是10呢, 因为我们此处规定了所有砝码组合最大不超过10g, 那么超过10g的砝码也就没了意义, 所以我们只需要最大为10g的砝码种类。
那么之前的公式就可以变为 ():
\begin{align}
&\qquad(1g砝码的所有组合)\cdot(2g砝码的所有组合)\cdot(3g砝码的所有组合)\
&\
&=(x^0 +x^1 + x^2 + x^3 +\cdots+x{10})\cdot(x0+x2+x4+x6+x8+x{10})\cdot(x0+x3+x6+x^9)\
\end{align}
将括号打开后所得的多项式的系数就是不同重量的组合方式。
现在我们来考虑一下情况下的通项公式:
其中(注意, 上边是多项式的通项公式, 跟我们之前举的例子没有关系):
K对应具体问题中物品的种类数。
v[i]表示该乘积表达式第i个因子的权重,对应于上诉问题为每个砝码的的重量。
表示该乘积表达式第i个因子的起始系数,对应于具体问题中的每个物品的最少个数,即最少要取多少个。
表示该乘积表达式第i个因子的终止系数,对应于具体问题中的每个物品的最多个数,即最多要取多少个。
假如我们现在题目是:给2张1元,5张2元,3张5元,要得到15元,有多少种组合?
根据上述问题, 我们可以得到表达式:
我们注意到第一个多项式, 其代表是有1元的所有组合的情况, 即为(0张1元 || 1张1元 || 2张1元)。因为我们相当于是从0张1元开始, 到2张1元停止。所以我们此时有。
以此类推, 代表由2元组成的表达式, 故可表示 (0张2元 || 1张2元 || 2张2元 || 3张2元 || 4张2元 || 5张2元 ), 故此时有
第三个表达式是由5元组成, 故
总结一下, ={1,2,5}, ={0,0,0}, ={2,5,4}。一般情况下都为0, 但也有特殊情况。
已知Fib(n)=Fib(n-1)+Fib(n-2), 这里假设Fib(1)=1,Fib(2)=1。因为Fib(1)和Fib(2)都为1, 也就是说一次项和二次项的系数都为1, 那么根据如下三个求递推公式的原则:
1.将递推关系变成母函数方程
2.求解母函数方程
3.将母函数变成幂级数形式
我们首先写出斐波那契数列的生成函数
等式两边同时乘, 有:
两式相加, 有:
我们对比, 可得:
所以我们可以得到:
可以令: , 得到两根为: , , 所以我们可以知道:
假设, 通分有: 。由系数关系可得, 所以
我们可知:
是以公比为的等比数列,是以公比为的等比数列,所以其通项公式为:
若有1克、2克、3克、4克的砝码各一 枚,能称出哪几种重量?各有几种可能方案?
构造母函数,如果用x的指数表示称出的重量,则:
1个1克的砝码可以用函数表示,(前面的这个1表示1克的砝码个数为0, 即)
1个2克的砝码可以用函数表示,
1个3克的砝码可以用函数表示,
1个4克的砝码可以用函数表示,
那么几种砝码的组合情况的用乘积表示有:
其中系数即为方案数,譬如乘出重量为6的物品共有2种方案。
求用1分、2分、3分的邮票贴出不同数值的方案数?
这个相对于上面的那个例子是:这个邮票可以重复。可知其生成函数为:
重为 的砝码, 如何放在天平的两端, 记可称重量为n的物体的不同方式为, 则的母函数为:
其中表示砝码a1和物体放在同一个托盘内, 表示砝码和物体放在不同的托盘内, 则为用一个0g的砝码代替, 即不用1g这个砝码的意思。
重为 的砝码, 若只可以放在天平的一端, 记可称重量为n的物体的不同方式为, 则的母函数为:
数的划分,将整数分解为若干个整数(相当于将n个苹果放在n个无区别的盘子里,每个盘子可以放多个,也可以不放)
假设1出现的次数为记为, 2出现的次数记为 。k出现的次数记为,那么生成函数为:
前面的意思是当出现一个2时为,当出现两个2时为
为什么当出现n时,只有两项, 因为是将数n划分为若干项,所以不能超过该数,且由数1到n项数依次要
#include
#include
using namespace std;
int specificChoice(int query_value,const vector > &choices){ //接受两个参数, 一个是要查询组合种类的数值, 一个是一个vector, vector中每个pair代表<砝码重量, 该重量砝码的数量>, <2,4>代表2g的砝码有4个
int maximum=0;
for(auto &t:choices){
maximum+=t.first*t.second; //此处求出最高的幂次项, 作为下面循环的停止条件。
}
/*
为了计算多项式, 我们首先要初始化一个vector用来存多项式的每个项, 该vector的下标指代的是幂, 值为该幂的项所对应的系数。即cumulative_coeff[2]=5代表x^2项的系数为5, 即5x^2
*/
vector cumulative_coeff(maximum+1,0); //注意此处maximum也要取到, 所以初始化的大小要加一
vector temp(maximum+1,0);
cumulative_coeff[0]=1; //我们此处需要把砝码重量为0的值初始化为1, 因为后来迭代都需要从该处开始, 后续的计算方式都是以此作为基础
/*
假设我们有1g,2g,3g砝码各一个, 故有多项式为(1+x)(1+x^2)(1+x^3), 我们首先说明, 作为最外层循环, i是用来以每个多项式为基本单位来遍历的, 即(1+x),(1+x^2)和(1+x^3)这三个多项式, 故i遍历三次。实际上i的遍历次数取决于我们传入的物品种类数目
既然i指代的每个具体的表达式, j相当于是遍历上一轮得到的cumulative_coeff的结果的, 然后在j的循环中, 还有一个k的循环, k是用来遍历当前多项式中每个元素的。
因为(1+x)(1+x^2)(1+x^3)最终最高次幂是6, 所以在经过初始化后, 我们的cumulative_coeff列表为:
1 0 0 0 0 0 0
我们开始第一轮迭代, 当i=0时, 我们遍历第一个多项式(1+x), 然后我们现在需要把这个(1+x)累加到cumulative_coeff中, 那么我们就对cumulative_coeff整个用j遍历一遍。在每一轮遍历j的过程中, 我们用k来遍历当前(1+x)这个多项式, 并将其累加到j遍历到的地方
当j=0时, 相当于选择cumulative_coeff[0],
当k=0时, 即代表选择了(1+x)中的1, temp[k+j]+=(cumulative_coeff[0]=1)
当k=choices[i].first=1时, 即代表选择了(1+x)中的x, temp[k+j]+=temp[0+1]=(cumulative_coeff[0]=1) , 这就是用temp的意义, 不会重复+=, 否则如果直接在cumulative_coeff上做+=的话每次就重复计算了
当j=1时, 相当于选择cumulative_coeff[1],
当k=0时, 即代表选择了(1+x)中的1, temp[1]+=(cumulative_coeff[1]=0) 在上一轮j=0中temp[1]已经被加为1了, 在此轮加0
当k=choices[i].first=1时, 即代表选择了(1+x)中的x, temp[2]=cumulative_coeff[1]=0
当j=2,3,4,5,6时, 因为cumulative_coeff[j]=0, 所以对应的temp[j+k]+=0
......
在遍历完所有的j后, 将temp上的值赋给cumulative_coeff, 注意不是+=而是=, 然后将temp所有元素重新初始化为0
此时cumulative_coeff为:
1 1 0 0 0 0 0
开始第二轮迭代, 当i=1时, 我们遍历第而个多项式(1+x^2), 然后我们现在需要把这个(1+x^2)累加到上一轮的cumulative_coeff中, 注意此处是1g,2g,3g砝码各一个, 如果不止一个的话k的最大值就不止是1:
当j=0时, 相当于选择cumulative_coeff[0],
当k=0时, 即代表选择了(1+x^2)中的1, temp[k+j]+=1 注意temp在上一轮结束的时候已经全部初始化为0, 所以此处结果是temp[0]=1
当k=choices[i].first=2时, 即代表选择了(1+x^2)中的x^2, temp[k+j]+=(cumulative_coeff[0]=1) , 故temp[2]=1
......
*/
for(int i=0;i: ";
for(int co=0;co<=maximum;co++){ //每一轮结束后输出本轮累加的cumulative_coeff, 便于理解
cout< > inputs;
//给定3个2g的砝码, 4个3g的砝码, 2个5g的砝码
inputs.push_back({2,3});
inputs.push_back({3,4});
inputs.push_back({5,2});
//求解用这些砝码得到总重量为28g的所有可能组合数量
cout< 将正整数n表示成一系列正整数之和: , 其中。
正整数的这种表示称为正整数的划分。求正整数n的不同划分个数。
例如正整数6有如下11种不同的划分:
6
5+1
4+2 4+1+1;
3+3 3+2+1 3+1+1+1;
2+2+2 2+2+1+1 2+1+1+1+1;
1+1+1+1+1+1
现在就是无限砝码问题了, 设置一个最大上界为正整数n, 然后只要小于等于n的数, 其每个数都可以被选用无数次。假设正整数n为6, 则我们有1,2,3,4,5,6这6个砝码, 每个都有无限的数量, 仅仅要求不同砝码组合的总重量小于整数n。
那么我们可以对上面的稍加变形
int infiniteChoice(int NUM){
vector cumulative_coeff(NUM+1,0);
vector temp(NUM+1,0);
cumulative_coeff[0]=1;
/*
注意i要从1开始加起, 如果i是0的话, 底下的k+=i就会一直是k+=0, 就会陷入死循环, 而且因为我们只对0g砝码做了初始化, 所以本来也要从1g砝码开始考虑。
之所以上面那个代码i是从0开始加起, 是因为在循环中, k+=choices[i].first 。choices[i].first一般来说不为0。
总体来说我们所要做的改动就是, i的上界变为了NUM, 因为只要小于NUM的所有砝码都是有无限个的, 所以产生的多项式是:
(1+x+x^2+x^3+...)(1+x^2+x^4...)(1+x^3+x^6...)......(1+x^n)
第二个改动是, k不再被砝码的数量所限制了, 每一轮循环的限制条件变为了仅剩 k+j<=NUM。而且k每一轮也从 k+=choices[i].first变为了k+=1, 因为现在i就指代砝码重量本身, 毕竟现在的砝码重量种类是从1到n一个连续的序列。
其他就没什么改动了
*/
for(int i=1;i<=NUM;i++)
{
for(int j=0; j<=NUM; j++){
for(int k=0; k+j<=NUM; k+=i)
{
temp[j+k] += cumulative_coeff[j];
}
}
for(int j=0; j<=NUM; ++j){
cumulative_coeff[j] = temp[j];
temp[j] = 0;
}
}
return cumulative_coeff[NUM];
}
卡特兰数
我们首先来看一个例子, 假如现在有 n 个+1 和 n个-1, 总计2n个数, 要用其组成一个序列, 要求在序列中任何一点k上, 都有, 其中。换句话说, 即:
序列1: 1 1 -1 -1 1 ...
序列2: 1 -1 1 -1 -1 ...
序列1看上去是暂时没错的, 因为无论在哪个位置, 该位置之前(包括该元素)的元素和都大于等于0, 而序列2不是, 所以序列二不满足要求
我们满足上述要求的称为卡特兰数, 假设我们设不满足上述要求的序列的数量为, 那么就等于n 个+1 和 n个-1 的的数量。
这个所有排列组合的数量如果用排列组合来表示即为 , 怎么理解这个呢?
我们可以理解为, 假设现在有一个长度为2n的空的插槽, 我们从这2n个插槽中选出n个插槽, 插入n个+1, 那么剩下的插槽自然都是-1了。故为。注意此处的与卡特兰数的表示没有什么关系, 只是都用来表示而已。
那我们现在有了 , 下一步就是要求了。
我们假设有一个最小的k令, 由于此处k是最小的, 所以必有, 并且k是一个奇数。为了帮助理解, 我们假设现在有如下这个不满足要求的序列(n=7):
1 -1 1 1 -1 -1 1 -1 -1 1 1 1 -1 -1
那么这个最小的k等于多少呢, 等于9(下标从1开始算), 即在之前, 序列为:
1 -1 1 1 -1 -1 1 -1
其和为刚好为0, 加上后, 即加上-1, 其和即为-1了, 而且此时也是奇数。此时我们将前项(包括第k项)的-1变为1, 1变为-1, k后面的序列不变, 那么上述序列变为:
-1 1 -1 -1 1 1 -1 1 1 1 1 -1 -1
很显然, 此时整个序列中有8个+1, 有6个-1。(因为把原来是-1的n变为了+1, 所以+1数量加一, -1数量减一)。而最初的序列有7个+1和7个-1, 故当时n=7。所以在改变后, 现在有n+1个+1, 有n-1个-1。
扩展来说, 所有不满足卡特兰数条件的序列, 其经过翻转前k项后都会导致整个2n序列变为包含n+1个+1和n-1个1, 那么换个角度来看, 是否只要满足一个2n序列, 只要其包含n+1个+1和n-1个-1, 其所有的排列组合就等价于所有不满足卡特兰数序列的2n序列。换句话说, 包含n+1个+1和n-1个-1的序列的任何排列组合方式, 都可以将其按上述的方式反向翻转, 得到一个最小k元素, 满足。那么这么一来, 不满足卡特兰数列条件的2n序列就一个包含n+1个+1和n-1个-1的2n序列。如果觉得此处证明不严谨请查阅编程之美4.3。
那么很显然, 其就是我们要找的序列, 故, 即相当于从2n个插槽中选出n+1个插入+1或是n-1个插入-1, 注意其中 。
因此我们就有 (其中) :
这就是我们要求的卡特兰数的公式, 根据上式可得其递推公式为:
同时, 其还有如下性质(注意等式左边是而右边的项是):
以及:
而其增长趋势, 即复杂度为:
我们可以把+1看为入栈, 而-1看做是出栈, 不能对一个空栈做出栈操作, 也就是说在每次出栈操作时, 要确保栈中元素大于0。换句话说, 也就是说对于序列中任意一个元素, 都有。假设我们有n个数, 其入栈和出栈的排列总数为, 例如1,2,3入栈的出栈排序有123,132,213,231和321五种。
如上文所说,对于任意的k,前k个元素中-1的个数小等于+1的个数的序列计数,我们可以不停地变换形式,比如将-1看成右括号,+1看成左括号,就变成了合法括号表达式的个数。比如2个左括号和2个右括号组成的合法表达式有 种, 是 ()() 和 (()) 。也就是说')'不能先于'('出现, 即')'出现时前面一定要有一个'('与其匹配。
既然如上一点都把括号加上去了,那么顺便就再次转换,n+1个数连乘,乘法顺序有种。或者更常见的, 三个矩阵连乘, 不过因为矩阵符合乘法结合率, 所以跟三数连乘没什么区别。
因为比如我们三个数连乘abc,那么等于在式子上加括号,有2种乘法顺序,分别是和。
我们再取n为3来看看, 注意此处n指的是'('或')'单括号的数量,n为3的时候就是4个数相乘了,那么我们设为abcd,最初的标号定在a上,我们对于n为3得到合法的括号序列有5个,分别是:((())),()(()),()()(),(())()和(()()),那么我们将一个左括号看成是当前操作数指针往右移动一个位置,一个右括号看成是当前操作数和左边最近的一块操作数相乘起来,那么对应的五个表达式就是:a(b(cd)),(ab)(cd),((ab)c)d,(a(bc))d和a((bc)d),他们之间是一一对应关系。
n个节点的二叉搜索树的所有可能形态数为。注意是二叉搜索树, 即左子节点比父节点小, 右子节点比父节点大。
假设我们现在有一个有序序列[1,2,3,4,5,6,7,8], 问总共能组成多少种不同的二叉搜索树。为了能得到所有可能二叉树的情况, 我们需要遍历这个序列, 将序列中每个元素分别当做一次根节点。
假设我们现在选择了下标为2的元素3(下标从0开始)作为根节点, 那么此时该根节点的左子树和右子树中包含的节点是不是确定的? 注意是二叉搜索树, 所以{1,2}落在了左子树, {4,5,6,7,8}落在了右子树。
而且此时左子树和右子树的排列方式是相互独立的, {1,2}有2中方式组成一个二叉搜索树, {4,5,6,7,8}有42种方式(先不用管这个是怎么得到的)组成一个二叉搜索树。那么, 此时当以3作为根节点时, 所有子树的可能情况总和就是
再次重申, 左子树和右子树是相互独立的, 所以两者的排列组合相当于是笛卡尔积, 所以是2*42=84相乘。
我们再来思考一下, 当以3作为根节点将序列分为{1,2}和{4,5,6,7,8}以及当以6作为根节点将序列分为{1,2,3,4,5}和{7,8}时, 其结果是否是一样的呢? 其实两者最后的结果是一样的, 都是84。
那么, 这说明了, 当一个根节点把一个有序数列(注意有序这个条件)分成左右两个子树时, 分到子树中的元素的值不重要, 即{1,2}和{7,8}两者没什么区别, 重要的是分到子树中的元素的数量。即只要分到左子树或右子树中2个元素, 那么无论这两个元素是{1,2},{3,4}还是{5,6}, 其最终该子树的排列组合数量都是2。
那么[1,2,3,4,5,6,7,8]这个序列可能产生的所有可能BST(二叉搜索树)的数量就等于令序列中每一个元素为根节点时, 左子树乘右子树得到的笛卡尔积, 即像2*42=84那样。
我们把这个过程抽象一下, 假设我们现在用第i个元素将序列分成左右两个序列, 该左右两个序列是不是又可以分别被当成新的序列, 递归地再分别被分成两半。而且就像我们上面证明的, 分成两半时每个序列中元素本身值不重要, 序列中每个元素的数量才重要, 那么我们就可以得出如下递推公式:
其中代表该序列中包含i个元素, 代表其包含n-1-i个元素, 注意因为每一轮需要将当前作为根节点的节点排除在外, 所以此处是n-1-i。 假如序列长度为n=8, i=2时, 即相当于用从左往右数第3个元素(i是从下标0开始的)作为根节点, 那么此处左子树就有i=2个节点, 右子树就有8-1-2=5个节点。注意此处有个trick, 因为我们输入的n=8, 所以当我们用n-1的时候就自动将当前根节点排除在外了。 即n-1-i跟的上界是n-1没直接关系, 的上界是用来从0到n-1遍历这n个元素, 分别用其作为根节点。
那么和怎么求呢, 此时需要将分到左子树和右子树的序列分别当做新的输入序列, 重新开始递归求解。
我们看上述递推公式, 再与卡特兰数的递推公式对比一下:
会发现唯一的区别就是用n-1替换为了n, 也就是说, 其就是卡特兰数, 那么此时我们可以直接使用卡特兰数的公式求解。
即:
long C=1;
for(int i=0;i其中n代表序列的长度。
对于一个n*n的正方形网格,每次我们能向右或者向上移动一格,而且不能越过对角线。那么从左下角到右上角的所有在副对角线右下方的路径总数为。

我们将一条水平向右走记为+1, 向上走记为-1, 那么就组成了一个n个+1和n个-1的序列, 我们所要保证的就是前k步中向右走的个数不小于向上走的次数, 换句话说前k个元素的和非负, 就是我们关于Catalan数的定义。
给定一个n边形, 要求用n-3条不相交的对角线将其分为n-2个三角形, 求共有多少种分法。下图是六边形, 其总共有14种分法。

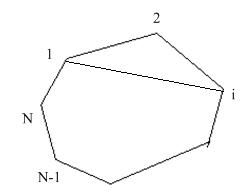
还记得我们在二叉搜索树那部分提到的左右子树递归分割吗, 此处也是相同的道理。假设n边型共有n个顶点, 依次将其编号为 。从中任选一个顶点, 连接和。
如上图, 那么我们这条线段将多边形分成了两部分, 一部分是从到共k个点, 故为k边形。而这个k边形又可以当做全新的多边形, 递归地进行下一次分割。
另一部分是从共n-k+1个点(因为和点本身也包含在内故要+1)。
那么此时我们就求得了递推公式, 即:
那么, 我们下一步就该求的上界了, 的上界就是在递归的一开始, 我们最多能选多少个点作为和的连线? 换句话说也就是求k的取值问题。其实的取值范围是{}共n-2个选择。
为什么是到而不是到呢?注意看上图, 和是不是连在一起, 那也就是说我们没法用这条线断将多边形分为两部分。所以此时的通项公式可以写为:
注意, n边形的n要大于等于3。
写为代码为:
C[2]=C[3]=1;
for(int i=4;i
C[i]=0;
for(int j=2;j<=i-1;j++)
C[i]+=C[j]*C[i-j+1];
}
那么我们此时就想, 能不能把这个通项公式简化一些呢?
既然讨论所谓的“1边型”、“2边型”其实根本没有意义,“3边型”及以上才有意义,而且3是n的起始值,那么不妨令表示n+2边型的划分数,这样就从开始。换句话说, 我们此时需要改变一下设定n的方式, 之前是把n设定为n边形边的数量。现在加入给定的是六边形, 我们就将n设定为6-2=4。以此类推, n代表求的是n+2边形, 此时我们既可以得到如下递推公式:
对于集合的不交叉划分的数目为,这里解释一下不交叉划分。
我们对于集合{a,b}和{c,d},假设他们组成了两个区间[a,b]和[c,d],我们假设两个区间不重合,那么以下四种情况当做是不交叉的:a 对于集合,将里面元素两两分为一子集,共n个,若任意两个子集都是不交叉的,那么我们称此时的这个划分为一个不交叉划分。此时不交叉的划分数就是我们的了,证明也很容易,我们将每个子集中较小的数用左括号代替,较大的用右括号代替,那么带入原来的1至2n的序列中就形成了合法括号问题,就是我们第二点的结论。例如我们的集合{1,2,3,4,5,6}的不交叉划分有五个:{{1,2},{3,4},{5,6}},{{1,2},{3,6},{4,5}},{{1,4},{2,3},{5,6}},{{1,6},{2,3},{4,5}}和{{1,6},{2,5},{3,4}}。 我们先绘制如下的一张图片,即n为5的时候的阶梯: 这个证明是怎么进行的呢?首先我们令n等于5, 即5层阶梯, 我们注意到每个切割出来的矩形都必需包括一块标示为*的小正方形,那么我们此时将每个*与#标示的两角作为矩形, 将其取出, 作为一种情况, 那么取出矩形后的阶梯就剩下两个小阶梯, 这两个小阶梯就是两个更小的子问题了。 我们可以联想二叉搜索树那部分, 每次选择一个节点, 将序列分成左右两半, 此处是每次选择一个以*和#作为对角的矩形, 将整个阶梯分为两半。 那么具体的分法看下图, 每种不同颜色的框代表是一种取出矩形的方法, 注意观察取出框内元素时, 阶梯内剩余的元素被分为了两个小阶梯。 因此我们有 这道题咋看上去毫无头绪, 但是抽象一下, 就是: 在一个2行n列的格子中填入1到2n这些数值使得每个格子内的数值都比其右边和下边的所有数值都小的情况数。 假设我们有8个数, 即 1 2 3 4 5 6 7 8, 即此时n=4, 然后我们令这8个数从小到大排列, 现在我们从中随机选4个数, 放到第一行中, 剩下4个数放到第二行中, 假设我们的排列顺序是: 1 2 3 4 其中1 2 3 4四个数在第一行, 5 6 7 8四个数在第二行, 假设在第一行设为0, 在第二行设为1, 那么这8个数所在队列就可以表示为 1 2 3 4 5 6 7 8 如果我们的排列顺序是: 1 2 5 7 其中1 2 5 7四个数在第一行, 3 4 6 8四个数在第二行, 那么这8个数就可以表示为: 1 2 3 4 5 6 7 8 看出规律来了吗, 这其实就是卡特兰数的变体, 假设我们现在有一个 不符合规则 的排队顺序: 1 2 5 3 那么对应的0和1序列就是: 1 2 3 4 5 6 7 8 你会发现, 不对啊, 这虽然5比3大违背了规则, 但是从01序列上来看, 其符合卡特兰数的条件啊, 是不是错了, 其实没错, 因为我们此处只考虑组合, 而不是排列, 因为你会发现, 下面这个排队顺序与上面那个不符合规则的排队顺序, 生成的01序列是一样的, 都是00010111: 1 2 3 5 也就是说, 对于一种01序列, 很显然只有一种排队方式是正确的, 是一一映射的关系, 譬如: 1 2 3 5 | 1 3 2 5 | 1 2 5 3 | 3 1 2 5 | 3 5 2 1 | 5 3 1 2 ... 上述所有排队方式, 都对应着00010111, 但是其中只有一种是正确的, 也就是排队方式跟01序列是一一对应的映射关系, 那么也就是说, 我们可以完全不考虑排队方式, 只考虑总共有多少种可行的01序列即可, 因为一种01序列对应且只对应着一种排队方式 而我们实践后发现, 可行的01序列就是卡特兰数的要求, 可以类比于出栈入栈问题, 即, 至此, 完全转化为卡特兰数问题 部分参考http://daybreakcx.is-programmer.com/posts/17315.html, https://www.cnblogs.com/wuyuegb2312/p/3016878.html#bop和https://www.cnblogs.com/13224ACMer/p/4671551.html
n层的阶梯切割为n个矩形的切法数也是, 如下图所示(下图为n=4的情况):
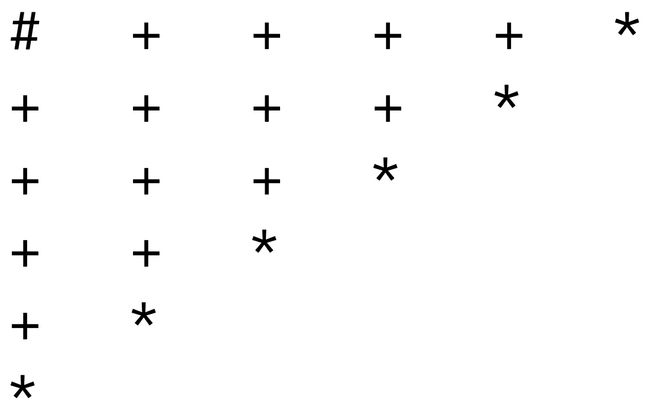

很显然这就是一个卡特兰数。故其满足通项公式
假如有2n个人, 其身高都各不相同, 要求现在将这2n个人排成两排, 要求: (1)每人比左边的人高, 比右边的人矮 (2)在同一列中的两个人, 后面的比前面的高。
5 6 7 8
0 0 0 0 1 1 1 1
3 4 6 8
0 0 1 1 0 1 0 1
4 6 7 8
0 0 0 1 0 1 1 1
4 6 7 8
4 6 7 8 | 4 7 6 8 | 4 6 8 7 | 7 4 6 8 | 7 8 6 4 | 8 7 4 6 ...
在写这篇文章中, 浏览了很多博客, 如果有哪篇博客被引用我却忘了指出, 恳请告知, 我即刻修改。