更多信息请查看原文:https://www.yanxishe.com/TextTranslation/2484?from=jianshu0325
在word2vec教程的第2部分(此处是第1部分)中,我将介绍对基本Skip-gram模型的一些其他修改,这些修改对于实际使训练变得可行且非常重要。
当您阅读有关Word2Vec的Skip-gram模型的教程时,您可能已经注意到了一些东西——它是一个巨大的神经网络!
在我给出的示例中,我们有包含300个维度的单词向量和10,000个单词的词汇。 回想一下,神经网络有两个权重矩阵-隐藏层和输出层。 这两个层都有一个权重矩阵,每个矩阵的权重为300 x 10,000 = 3百万!
在较大的神经网络上运行梯度下降会很慢。 更糟糕的是,您需要大量的训练数据才能调整这么多的权重并避免过度拟合。 数百万的权重乘以数十亿的训练样本意味着训练这种模型将是"野兽"。
Word2Vec的作者在其第二篇论文中通过以下两项创新解决了这些问题
对常用单词进行二次采样以减少训练示例的数量。
他们使用称为“负采样”的技术来修改优化目标,该技术可使每个训练样本仅更新模型权重的一小部分。
值得注意的是,对频繁出现的单词进行二次采样并应用负采样不仅减轻了训练过程的计算负担,而且还改善了其产生的单词向量的质量。
下采样常见词
在本教程的第1部分中,我展示了如何从源文本创建训练样本,但我将在这里重复。下面的示例显示了我们将从句子“ The quick brown fox jumps over the lazy dog. ”中获取的一些训练样本(单词对)。我仅在示例中使用了2的小窗口大小。蓝色突出显示的单词是输入单词。

有两个“问题”,常见的词如“ the”:
在查看单词对时,(" fox"," the")并不能告诉我们有关" fox"的含义。 "the"出现在几乎每个单词的上下文中。
我们将有更多的(" the”,...)样本,而不是我们需要学习"the"的良好向量。
Word2Vec实现了“下采样”方案来解决此问题。 对于我们在训练文本时遇到的每个单词,我们都有可能将其从文本中有效删除。 我们剪切单词的可能性与单词的频率有关。
当我们训练剩余单词时," the"将不会出现在它们的任何上下文窗口中。
我们将减少10个训练样本,其中"the"是输入词。
请注意,这两种效果如何帮助解决上述两个问题。
采样率
word2vec 的C语言代码实现了一个公式,用于计算将给定单词保留在词汇表中的概率。
wiwi是单词,z(wi)是语料库中该单词占单词总数的比例。 例如,如果单词“花生”在10亿个单词的语料库中出现了1000次,则z(“花生”)= 1E-6。
代码中还有一个名为"sample"的参数,该参数控制要进行多少次采样,默认值为0.001。 较小的“样本”值表示保留单词的可能性较小。
P(wi)是保留单词的概率:

您可以在Google中快速绘制此图形以查看形状。
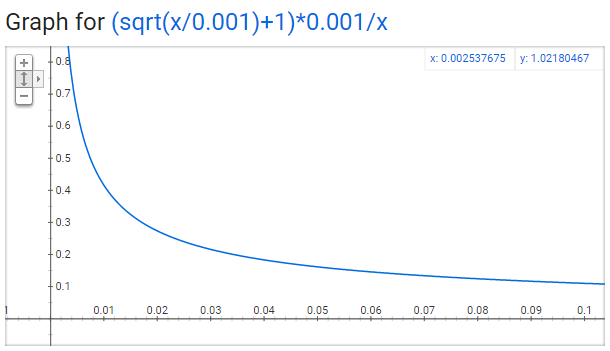
任何单词都不应该占语料库的很大一部分,因此我们希望在x轴上查看很小的值。
这是此函数中的一些有趣的要点(再次使用默认样本值0.001)。
当z(wi)<= 0.0026z(wi)<= 0.0026时,P(wi)= 1.0P(wi)= 1.0(被保留的机会为100%)。
这意味着将仅对代表总单词的0.26%以上的单词进行子采样。
当z(wi)= 0.00746z(wi)= 0.00746时,P(wi)= 0.5P(wi)= 0.5(被保留的机会为50%)。
当z(wi)= 1.0z(wi)= 1.0时,P(wi)= 0.033 P(wi)= 0.033(被保留的概率为3.3%)。
也就是说,如果语料库完全由wiwi词组成,那当然是荒谬的。
您可能会注意到,本文对该函数的定义与C代码中实现的定义略有不同,但是我认为C实现是更具权威性的版本。
负采样
训练神经网络意味着以训练为例,并稍微调整所有神经元的权重,以便预测训练样本更准确。 换句话说,每个训练样本将调整神经网络中的所有权重。
正如我们上面所讨论的,单词词汇量的大小意味着我们的skip-gram神经网络具有大量的权重,而数十亿的训练样本中的每一个都会对所有的权重进行轻微的更新!
负采样通过使每个训练样本仅修改一小部分权重而不是全部权重来解决这一问题。以下它的工作原理。
在对网络进行单词对(“fox”、“ick”)训练时,回想一下网络的“标签”或“正确输出”是一个one-hot向量。也就是说,对于目标“quick”的输出神经元输出1,而对于所有其他数千个输出神经元输出0。
对于负采样,我们将只随机选择少量的“负”词(比方说5个)来更新其权重。(在此上下文中,“负”词是我们希望网络为其输出0的字)。
我们还将更新“积极”词的权重(在我们当前的示例中是“quick”字词)。
这篇论文说,对于较小的数据集,选择5-20个单词效果很好,而对于大型数据集,只需选择2-5个单词就可以了。
回想一下,我们模型的输出层有一个300x10000的权重矩阵。因此,我们将只更新我们的正单词(“quick”)的权重,加上我们希望输出0的另外5个单词的权重。总共有6个输出神经元,总共1800个权重值。这只是输出层中3M权重的0.06%!
在隐藏层中,只更新输入单词的权重(无论您是否使用负采样,都是如此)。
选择负样本
“负样本”(即,我们将训练为输出0的5个输出单词)是使用“unigram 分布”选择的,其中频率越高的单词更有可能被选为负样本。
例如,假设您将整个训练语料库作为一个单词列表,并通过从列表中随机选择5个负样本。
在这种情况下,选择单词“couch”的概率将等于“couch”在语料库中出现的次数,除以语料库中单词occus的总数。
这由以下方程式表示:
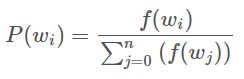
两位作者在论文中表示,他们尝试了这个等式的几种变体,其中表现最好的一种是将字数提高到3/4次方:
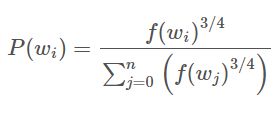
如果您使用一些样本值,您会发现,与更简单的公式相比,这个公式有增加出现频率较低的单词的概率和减少出现频率较高的单词的概率的趋势。
这个选择在C代码中的实现方式很有趣。他们有一个有100M元素的大型数组(他们称之为unigram表)。他们用词汇表中每个单词的索引多次填充该表,单词的索引在表中出现的次数由P(Wi)P(Wi)*table_size给出。然后,要实际选择一个负样本,您只需生成一个介于0和100M之间的随机整数,并在表中的该索引处使用该词。因为较高概率的单词在表格中出现的次数较多,所以您更有可能选择那些。
词对与“短语”
第二篇Word2vec论文还包含了另外一项值得讨论的创新。作者指出,像“Boston Globe”(一份报纸)这样的词对与单独的单词“Boston”和“Globe”的含义大不相同。因此,无论“ Boston Globe ”出现在文本中的哪个位置,将其视为具有自己的词向量表示的单个单词是有意义的。
你可以在他们发布的模型中看到结果,该模型是根据谷歌新闻数据集中的1000亿个单词进行训练的。在模型中添加短语后,词汇量增加到300万个单词!
如果您对他们由此产生的词汇感兴趣,我会仔细研究一下并在此处发表一篇文章。 您也可以在这里浏览他们的词汇。
短语检测在其论文的“学习短语”部分中介绍。 他们在word2phrase.c中共享了其实现。我在此处共享了此代码的带注释(但没有更改)的副本。
我认为他们的词组检测方法不是他们论文的主要贡献,但我还是会分享一些有关它的信息,因为它非常简单。
他们工具的每遍仅查看2个单词的组合,但是您可以多次运行以获取更长的短语。 因此,第一遍将选取短语“ New_York”,然后再次运行将选取“ New_York_City”,作为“ New_York”和“ City”的组合。
该工具会对两个单词的每个组合出现在训练文本中的次数进行计数,然后将这些计数用于方程式中,以确定将哪些单词组合转换为短语。 该方程式旨在从单词中选出短语,这些单词通常相对于单个出现的次数一起出现。 它还偏爱由不常用词组成的词组,以避免用常见词(例如“ and the”或“ this is”)构成词组。
您可以在此处的代码注释中查看有关其方程式的更多详细信息。
对于替代短语识别策略,我有一个想法是将所有Wikipedia文章的标题用作词汇。
其他资源
如果您熟悉C语言,我在这里发布了原始word2vec C代码的注释广泛(但未更改)的版本。
另外,您是否知道word2vec模型也可以应用于非文本数据以用于推荐系统和广告定位? 您可以从一系列用户操作中学习向量,而不是从一系列单词中学习向量。 在我的新文章中阅读有关此内容的更多信息。
电子书和示例代码
我认为word2vec是一种引人入胜(且功能强大!)的算法-在使它深入理解这一点上做得很棒!
不过,也许您还有一些疑问。
您是否正在寻找有关模型权重如何更新的更深入的解释?
您是否想了解更多有关word2vec的跳过表和连续词袋(CBOW)版本之间的技术和实际差异的信息?
您是否知道word2vec的主要作者米科洛夫以Facebook的fastText库的形式发布了有关word2vec的更多作品?
是否想查看在Python中从头实现的所有核心word2vec组件?
您可以在我的电子书“ word2vec的内部工作原理-专业版”的新专业版中找到以上所有内容。 看一看,我认为您会发现它非常有价值!
更多信息请查看原文:https://www.yanxishe.com/TextTranslation/2484?from=jianshu0325