返回主页
本节讨论四个内容:
1、线性回归
2、多重共线性问题
3、岭回归
4、局部加权线性回归
线性回归(Linear Regression)是机器学习中解决 回归问题 的基本算法,往往作为回归任务的基线模型使用,“线性”是因为未知数的最高次幂为1次。

1、定义数据集与特征空间

2、定义假设空间
3、定义目标函数(平方误差)

4、优化算法
因目标函数为凸函数,对目标数求一阶导并令其为零,得到 w 的解析解表达式(xTx的行列式不能为0):
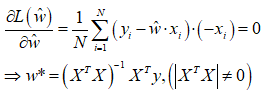
5、多重共线性问题
概念:多重共线性是指线性回归模型中的 自变量 之间由于存在 高度相关性 而使模型估计失真或难以估计准确。具体而言,多重共线性会导致参数的 方差 变大,从而使预测不稳定,即自变量微小的变化将导致预测值巨大的波动。
检测:利用矩阵条件数检测

证明:为什么多重共线性会导致参数 方差 变大

6、岭回归(带二范数约束的回归模型)
L0 范数是指向量中非0的元素的个数
L1 范数是指向量中各个元素绝对值之和,也叫“稀疏规则算子”(Lasso regularization),它是L0范数的最优凸近似,但是不可导
L2 范数是指向量中各个元素的平方和然后求平方根,且可导
岭回归通过引入 L2 正则化项对参数 w 施加惩罚,缓解过拟合和多重共线性风险。

7、局部加权回归
局部加权是一种 非参数(non-parametric)思想,上文提到的线性回归是参数方法,因为它的参数经过学习是 固定 的,一旦将参数保存下来,不需要再保留训练集即可进行预测。而局部加权线性回归需要保留整个的训练集,在预测时需要利用已知训练集信息计算每个预测样本与训练集的相似度并赋予一定的权重,预测点离训练点越近权重越大,反之则越小,因此每个预测点对应的参数不同。
因此,它的目标函数需要加入一个权重参数,权重大小的衡量依据借鉴正态分布性质,样本越靠近权重越接近 1,反之越接近 0,(相似度的衡量能否设计其他的算法,待探索):

因为要为每个预测点计算相似度,算法的时间复杂度为 O(N^2)
手写算法并与 Sklearn 进行对比
# -*- coding: utf-8 -*-
import os
import copy
import numpy as np
import pandas as pd
from sklearn.utils import shuffle
from sklearn.model_selection import train_test_split
from sklearn.linear_model import (LinearRegression, Ridge)
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
class LinearReg(object):
def __init__(self, lamb):
self.lamb = lamb
def z_scale(self, x_train):
'''z标准化,在动用距离度量的算法中,必须先进行标准化以消除数据量纲的影响'''
mu = np.mean(x_train, axis=0)
std = np.std(x_train, axis=0)
return mu, std
def data_transform(self, mu, std, x_train, x_test):
'''
数据变换
1、执行标准化操作
2、插入截距项
'''
x_train_scale = (x_train - mu) / std
x_test_scale = (x_test - mu) / std
intercept_train = np.ones(x_train_scale.shape[0]).reshape(-1, 1)
intercept_test = np.ones(x_test_scale.shape[0]).reshape(-1, 1)
x_train_scale = np.concatenate([intercept_train, x_train_scale], axis=1)
x_test_scale = np.concatenate([intercept_test, x_test_scale], axis=1)
return x_train_scale, x_test_scale
def get_loss(self, x_train_scale, y_train, w):
'''计算损失函数值'''
y_hat = x_train_scale.dot(w)
loss = 0.5 * np.mean((y_train - y_hat)**2) + 0.5 * self.lamb * np.mean(w**2)
return loss
def fit(self, x_train_scale, y_train):
'''模型训练, lambda = 0即为普通线性回归'''
A = x_train_scale.T.dot(x_train_scale)
M = np.eye(A.shape[0]) * self.lamb
w = np.linalg.inv(A + M).dot(x_train_scale.T).dot(y_train)
return w
def predict(self, x_test_scale, w):
'''模型预测'''
y_pred = x_test_scale.dot(w)
return y_pred
class LocallyWeightedReg(LinearReg):
def __init__(self, k, lamb):
self.k = k
super(LocallyWeightedReg, self).__init__(lamb)
def predict(self, x_train_scale, x_test_scale, y_train, y_test):
'''模型预测'''
# theta矩阵:预测集和训练集元素距离矩阵
Theta = np.exp(-0.5 * dist.cdist(x_test_scale, x_train_scale)**2 / self.k**2)
# 预测值保存
y_pred = np.array([])
# 对每个预测点进行循环
for i in range(len(Theta)):
theta_sample = np.eye(x_train_scale.shape[0]) * Theta[i, :] # 每个预测点与训练集的距离对角阵
A = x_train_scale.T.dot(theta_sample).dot(x_train_scale)
w_sample = np.linalg.inv(A).dot(x_train_scale.T).dot(theta_sample).dot(y_train)
print(f"sample: {i}; w: {w_sample}")
y_pred_sample = x_test_scale[i, :].dot(w_sample)
y_pred = np.append(y_pred, y_pred_sample)
return y_pred
if __name__ == "__main__":
file_path = os.getcwd()
dataSet = pd.read_csv(file_path + "/swiss_linear.csv")
df = dataSet[["Fertility", "Agriculture", "Catholic", "InfantMortality"]]
x = df.iloc[:, 1: ]
y = df.iloc[:, 0]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=0)
# 手写模型
model = LinearReg(lamb=0.5)
mu, std = model.z_scale(x_train)
x_train_scale, x_test_scale = model.data_transform(mu, std, x_train, x_test)
w = model.fit(x_train_scale, y_train)
loss_train = model.get_loss(x_train_scale, y_train, w)
y_pred = model.predict(x_test_scale, w)
rmse = np.mean((y_test - y_pred)**2)
print(f"LinearReg RMSE: {rmse}")
# sklearn
scale = StandardScaler(with_mean=True, with_std=True)
scale.fit(x_train)
x_train_scale = scale.transform(x_train)
x_test_scale = scale.transform(x_test)
# reg = LinearRegression(fit_intercept=True)
reg = Ridge(alpha=0.5, fit_intercept=True)
reg.fit(x_train_scale, y_train)
w = reg.coef_
b = reg.intercept_
y_pred = reg.predict(x_test_scale)
rmse = np.mean((y_test - y_pred)**2)
print(f"sklearn RMSE: {rmse}")
# 画图
# plt.figure(figsize=(8,6))
# n_alphas = 20
# alphas = np.logspace(-1,4,num=n_alphas)
# coefs = []
# for a in alphas:
# ridge = Ridge(alpha=a, fit_intercept=False)
# ridge.fit(X, y)
# coefs.append(ridge.coef_[0])
# ax = plt.gca()
# ax.plot(alphas, coefs)
# ax.set_xscale('log')
# handles, labels = ax.get_legend_handles_labels()
# plt.legend(labels=df.columns[1:-1])
# plt.xlabel('alpha')
# plt.ylabel('weights')
# plt.axis('tight')
# plt.show()
# statsmodels
# import statsmodels.api as sm #方法一
# import statsmodels.formula.api as smf #方法二
# est = sm.OLS(y, sm.add_constant(X)).fit() #方法一
# est = smf.ols(formula='sales ~ TV + radio', data=df).fit() #方法二
# y_pred = est.predict(X)
# print(est.summary()) #回归结果
# print(est.params) #系数
model = LocallyWeightedReg(k=50)
mu, std = model.z_scale(x_train)
x_train_scale, x_test_scale = model.data_transform(mu, std, x_train, x_test)
y_pred = model.predict(x_train_scale, x_test_scale, y_train, y_test)
rmse = np.mean((y_test - y_pred)**2)
print(f"LocallyWeightedReg RMSE: {rmse}")
LinearReg RMSE: 77.4638537052191
sklearn RMSE: 75.43038786488579
LocallyWeightedReg RMSE: 76.90550316746727
sample: 0; w: [70.44607336 3.92891665 4.27045562 4.66474541]
sample: 1; w: [70.44607321 3.92897979 4.27435879 4.66244306]
sample: 2; w: [70.44607258 3.93025749 4.27448647 4.66327313]
sample: 3; w: [70.4460735 3.92809796 4.27127147 4.66404582]
sample: 4; w: [70.44607662 3.93275617 4.26876574 4.6682018 ]
sample: 5; w: [70.44607404 3.9289215 4.2720904 4.6642848 ]
sample: 6; w: [70.44607343 3.92854954 4.27086921 4.66450444]
sample: 7; w: [70.44607319 3.92857968 4.27479848 4.66200071]
sample: 8; w: [70.44607402 3.92942195 4.27152206 4.66475568]
sample: 9; w: [70.44607426 3.92765904 4.27394164 4.66167854]
返回主页