3.8 图像分类领域经典模型-AlexNet(百度架构师手把手带你零基础实践深度学习原版笔记系列)
3.8 图像分类领域经典模型-AlexNet(百度架构师手把手带你零基础实践深度学习原版笔记系列)
AlexNet
通过上面的实际训练可以看到,虽然LeNet在手写数字识别数据集上取得了很好的结果,但在更大的数据集上表现却并不好。自从1998年LeNet问世以来,接下来十几年的时间里,神经网络并没有在计算机视觉领域取得很好的结果,反而一度被其它算法所超越。原因主要有两方面,一是神经网络的计算比较复杂,对当时计算机的算力来说,训练神经网络是件非常耗时的事情;另一方面,当时还没有专门针对神经网络做算法和训练技巧的优化,神经网络的收敛是件非常困难的事情。
随着技术的进步和发展,计算机的算力越来越强大,尤其是在GPU并行计算能力的推动下,复杂神经网络的计算也变得更加容易实施。另一方面,互联网上涌现出越来越多的数据,极大的丰富了数据库。同时也有越来越多的研究人员开始专门针对神经网络做算法和模型的优化,Alex Krizhevsky等人提出的AlexNet以很大优势获得了2012年ImageNet比赛的冠军。这一成果极大的激发了产业界对神经网络的兴趣,开创了使用深度神经网络解决图像问题的途径,随后也在这一领域涌现出越来越多的优秀成果。
AlexNet与LeNet相比,具有更深的网络结构,包含5层卷积和3层全连接,同时使用了如下三种方法改进模型的训练过程:
(这三个改进模型及其重要,到目前深度学习领域还在使用这三种改进算法,不愧大佬,思想开阔)
-
数据增广:深度学习中常用的一种处理方式,通过对训练随机加一些变化,比如平移、缩放、裁剪、旋转、翻转或者增减亮度等,产生一系列跟原始图片相似但又不完全相同的样本,从而扩大训练数据集。通过这种方式,可以随机改变训练样本,避免模型过度依赖于某些属性,能从一定程度上抑制过拟合。
-
使用Dropout抑制过拟合
-
使用ReLU激活函数减少梯度消失现象
说明:
下一节详细介绍数据增广的具体实现方式。
AlexNet的具体结构如 图2 所示:
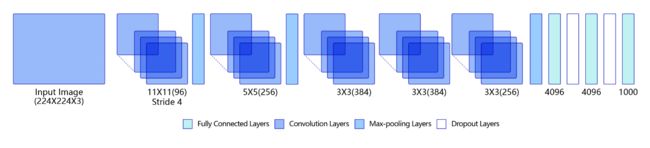
图2:AlexNet模型网络结构示意图
AlexNet在眼疾筛查数据集iChallenge-PM上具体实现的代码如下所示:
# -*- coding:utf-8 -*-
# 导入需要的包
import paddle
import paddle.fluid as fluid
import numpy as np
from paddle.fluid.dygraph.nn import Conv2D, Pool2D, Linear
# 定义 AlexNet 网络结构
class AlexNet(fluid.dygraph.Layer):
def __init__(self, num_classes=1):
super(AlexNet, self).__init__()
# AlexNet与LeNet一样也会同时使用卷积和池化层提取图像特征
# 与LeNet不同的是激活函数换成了‘relu’
self.conv1 = Conv2D(num_channels=3, num_filters=96, filter_size=11, stride=4, padding=5, act='relu')
self.pool1 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
self.conv2 = Conv2D(num_channels=96, num_filters=256, filter_size=5, stride=1, padding=2, act='relu')
self.pool2 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
self.conv3 = Conv2D(num_channels=256, num_filters=384, filter_size=3, stride=1, padding=1, act='relu')
self.conv4 = Conv2D(num_channels=384, num_filters=384, filter_size=3, stride=1, padding=1, act='relu')
self.conv5 = Conv2D(num_channels=384, num_filters=256, filter_size=3, stride=1, padding=1, act='relu')
self.pool5 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
self.fc1 = Linear(input_dim=12544, output_dim=4096, act='relu')
self.drop_ratio1 = 0.5
self.fc2 = Linear(input_dim=4096, output_dim=4096, act='relu')
self.drop_ratio2 = 0.5
self.fc3 = Linear(input_dim=4096, output_dim=num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.pool1(x)
x = self.conv2(x)
x = self.pool2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.pool5(x)
x = fluid.layers.reshape(x, [x.shape[0], -1])
x = self.fc1(x)
# 在全连接之后使用dropout抑制过拟合
x= fluid.layers.dropout(x, self.drop_ratio1)
x = self.fc2(x)
# 在全连接之后使用dropout抑制过拟合
x = fluid.layers.dropout(x, self.drop_ratio2)
x = self.fc3(x)
return x
本部分代码--数据读取,具体训练方式和上文一样,只是模型的区别。这里没有列出数据处理相关代码,需要的小伙伴请查看
3.7 图像分类领域经典模型-概述&LeNet(百度架构师手把手带你零基础实践深度学习原版笔记系列)
# -*- coding: utf-8 -*-
import os
import random
import paddle
import paddle.fluid as fluid
import numpy as np
DATADIR = '/home/aistudio/work/palm/PALM-Training400/PALM-Training400'
DATADIR2 = '/home/aistudio/work/palm/PALM-Validation400'
CSVFILE = '/home/aistudio/labels.csv'
# 定义训练过程
def train(model):
with fluid.dygraph.guard():
print('start training ... ')
model.train()
epoch_num = 1
# 定义优化器
opt = fluid.optimizer.Momentum(learning_rate=0.001, momentum=0.9, parameter_list=model.parameters())
# 定义数据读取器,训练数据读取器和验证数据读取器
train_loader = data_loader(DATADIR, batch_size=10, mode='train')
valid_loader = valid_data_loader(DATADIR2, CSVFILE)
for epoch in range(epoch_num):
for batch_id, data in enumerate(train_loader()):
x_data, y_data = data
img = fluid.dygraph.to_variable(x_data)
label = fluid.dygraph.to_variable(y_data)
# 运行模型前向计算,得到预测值
logits = model(img)
# 进行loss计算
loss = fluid.layers.sigmoid_cross_entropy_with_logits(logits, label)
avg_loss = fluid.layers.mean(loss)
if batch_id % 10 == 0:
print("epoch: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, avg_loss.numpy()))
# 反向传播,更新权重,清除梯度
avg_loss.backward()
opt.minimize(avg_loss)
model.clear_gradients()
model.eval()
accuracies = []
losses = []
for batch_id, data in enumerate(valid_loader()):
x_data, y_data = data
img = fluid.dygraph.to_variable(x_data)
label = fluid.dygraph.to_variable(y_data)
# 运行模型前向计算,得到预测值
logits = model(img)
# 二分类,sigmoid计算后的结果以0.5为阈值分两个类别
# 计算sigmoid后的预测概率,进行loss计算
pred = fluid.layers.sigmoid(logits)
loss = fluid.layers.sigmoid_cross_entropy_with_logits(logits, label)
# 计算预测概率小于0.5的类别
pred2 = pred * (-1.0) + 1.0
# 得到两个类别的预测概率,并沿第一个维度级联
pred = fluid.layers.concat([pred2, pred], axis=1)
acc = fluid.layers.accuracy(pred, fluid.layers.cast(label, dtype='int64'))
accuracies.append(acc.numpy())
losses.append(loss.numpy())
print("[validation] accuracy/loss: {}/{}".format(np.mean(accuracies), np.mean(losses)))
model.train()
# save params of model
fluid.save_dygraph(model.state_dict(), 'palm')
# save optimizer state
fluid.save_dygraph(opt.state_dict(), 'palm')
# 定义评估过程
def evaluation(model, params_file_path):
with fluid.dygraph.guard():
print('start evaluation .......')
#加载模型参数
model_state_dict, _ = fluid.load_dygraph(params_file_path)
model.load_dict(model_state_dict)
model.eval()
eval_loader = data_loader(DATADIR,
batch_size=10, mode='eval')
acc_set = []
avg_loss_set = []
for batch_id, data in enumerate(eval_loader()):
x_data, y_data = data
img = fluid.dygraph.to_variable(x_data)
label = fluid.dygraph.to_variable(y_data)
y_data = y_data.astype(np.int64)
label_64 = fluid.dygraph.to_variable(y_data)
# 计算预测和精度
prediction, acc = model(img, label_64)
# 计算损失函数值
loss = fluid.layers.sigmoid_cross_entropy_with_logits(prediction, label)
avg_loss = fluid.layers.mean(loss)
acc_set.append(float(acc.numpy()))
avg_loss_set.append(float(avg_loss.numpy()))
# 求平均精度
acc_val_mean = np.array(acc_set).mean()
avg_loss_val_mean = np.array(avg_loss_set).mean()
print('loss={}, acc={}'.format(avg_loss_val_mean, acc_val_mean))
start training ... with fluid.dygraph.guard():
model = AlexNet()
train(model)start training ...
epoch: 0, batch_id: 0, loss is: [0.68645483]
epoch: 0, batch_id: 10, loss is: [0.6189264]
epoch: 0, batch_id: 20, loss is: [0.6271447]
epoch: 0, batch_id: 30, loss is: [0.70667064]
[validation] accuracy/loss: 0.5300000309944153/0.5705490112304688
通过运行结果可以发现,在眼疾筛查数据集iChallenge-PM上使用AlexNet,loss能有效下降,经过5个epoch的训练,在验证集上的准确率可以达到94%左右。