基因组共线性工具MCScanX使用说明
简介
MCScanX工具集对MCScan算法进行了调整,用于检测共线性和同线性区域,还增加了可视化和下游分析。。MCscanX有三个核心工具,以及12个下游分析工具
实际使用
第一步: BLASTP比对
根据"MCScanX: a toolkit for detection and evolutionary analysis of gene synteny and collinearity",在使用BLASTP时需要注意如下事项:
- 如果一个基因有多个转录本,只选择注释中的第一条
- 寻找同源序列时,每个基因都要和自身以及其他基因组比较
- BLASTP的输出格式为Tabular(
-outfmt 6) - 保留前5条最佳比对序列(
num_alignments 5) - E值的阈值设置为1e-5(
-evalue 1e-5)
注:上面的选项基于NCBI BLAST+
以拟南芥和水稻为例,拟南芥和水稻的基因组和注释文件都可以在EnsemblPlants上
# arabidopsis thaliana
wget ftp://ftp.ensemblgenomes.org/pub/plants/release-41/fasta/arabidopsis_thaliana/pep/Arabidopsis_thaliana.TAIR10.pep.all.fa.gz
wget ftp://ftp.ensemblgenomes.org/pub/plants/release-41/gff3/arabidopsis_thaliana/Arabidopsis_thaliana.TAIR10.41.gff3.gz
# rice
wget ftp://ftp.ensemblgenomes.org/pub/plants/release-41/fasta/oryza_sativa/pep/Oryza_sativa.IRGSP-1.0.pep.all.fa.gz
wget ftp://ftp.ensemblgenomes.org/pub/plants/release-41/gff3/oryza_sativa/Oryza_sativa.IRGSP-1.0.41.gff3.gz
在建立BLAST的索引之前,我们需要对序列进行预处理,仅保留每个基因中的一个转录本。由于不同物种的基因命名方法不同,所以得先用less查看GFF文件,对其有一个总体的了解。
例如拟南芥的编号都是ATXGXXXXX.Y, 并且后面".Y"都是从1开始, 而水稻的是OsXXgXXXXXX表示基因,OsXXtXXXXXX-0Y表示转录本, 而"0Y",一些转录本是只有00,而另一些则是从01开始,有02,03等。我写了一个脚本用于提取每个基因对应的最长转录本以及它的位置
我在提取的同时删除了一些不需要的字符串
zcat Arabidopsis_thaliana.TAIR10.41.gff3.gz| python get_the_longest_transcripts.py | sed -e 's/gene://' -e 's/transcript://'> at_lst_gene.txt
zcat Oryza_sativa.IRGSP-1.0.41.gff3.gz | python get_the_longest_transcripts.py | sed -e 's/gene://' -e 's/transcript://' > os_lst_gene.txt
同时考虑到我们也不一定需要叶绿体和线粒体的信息,所以还可以进一步删掉这些数据
sed -i -e '/Mt/d' -e '/Pt/d' at_lst_gene.txt
sed -i -e '/Mt/d' -e '/Pt/d' os_lst_gene.txt
使用seqkit grep提取蛋白质序列.
seqkit grep -j 20 -f <(cut -f 2 at_lst_gene.txt ) Arabidopsis_thaliana.TAIR10.pep.all.fa.gz | sed 's/\..*//' > at.fa
seqkit grep -j 20 -f <(cut -f 2 os_lst_gene.txt) Oryza_sativa.IRGSP-1.0.pep.all.fa.gz | sed 's/-.*//'> os.fa
随后用makeblastdb建立索引
makeblastdb -in at.fa -dbtype prot -out index/at -parse_seqids
最后进行蛋白比对
blastp -query os.fa -db index/at -out at_rice.blast -evalue 1e-5 -num_threads 100 -outfmt 6 -num_alignments 5
注: 如果要做基因组组内和组间的共线性,那么就要将这两个基因组先进行合并,
cat at.fa rice.fa > all.fa, 然后用all.fa建索引,用all.fa进行比对
第二步:构建gff
MCscanX要求的gff文件和标准的gff文件不一样,它只有四列, 其中"sp#"的sp意味着你要用2个字母代表物种,#则表示是哪条染色体。而"gene"则要是你蛋白序列的基因名
sp# gene starting_position ending_position
基于我的get_the_longest_transcripts.py脚本,很容易用awk进行创建该信息
awk 'BEGIN{OFS="\t"} {print "at"$3,$1,$4,$5}' at_lst_gene.txt > at_os.gff
awk 'BEGIN{OFS="\t"} {print "at"$3,$1,$4,$5}' os_lst_gene.txt >> at_os.gff
第三步: MCScanX寻找共线性区块
在经过上面两步后,后续的MCScanX基本上是瞬间完成
MCScanX ./at_rice
如果你在输出信息中发现 0 matches imported (xxxxx discarded), 那么一定是你的GFF文件里的基因名和blast结果的基因名不对应导致
输出文件分为两个:
第一个是at_rice.collinearity, 记录着共线性区块(collinear blocks)
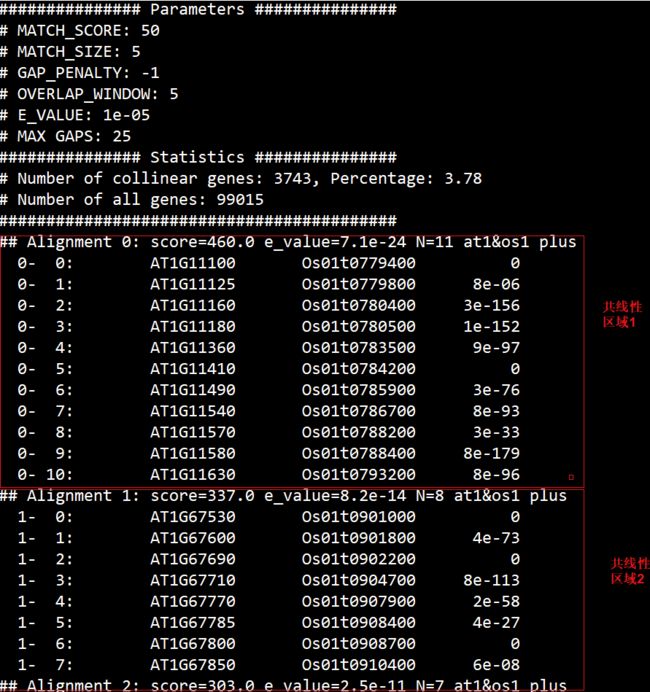
第二个则是以网页的形式展示共线性情况。
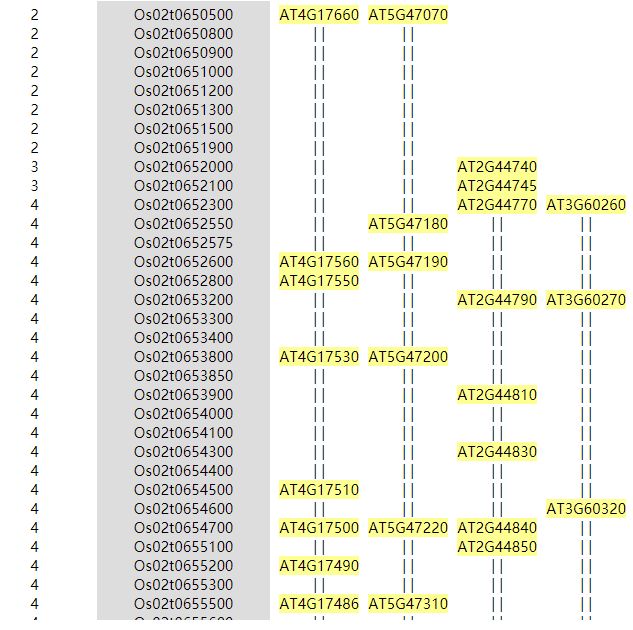
说明:第一列是每个基因座位的重复深度,第二列是参考基因(串联重复以红色标注,仅在序列既用于建立索引又用于搜索时才出现),之后的每一列都是匹配的共线性区块
下游分析
MCSCANX提供了一些列Java程序和Perl脚本用于下游分析,建议在Perl脚本的开头加入#!/usr/bin/env perl,此外部分软件需要安装bioPerl。
- group_collinear_genes.pl
- add_ka_and_ks_to_collinearity.pl
- detect_collinearity_within_gene_families.pl
- origin_enrichment_analysis.pl
- detect_collinear_tandem_arrays
- dissect_multiple_alignment
MCSCANX自带了一些结果可视化相关的工具(如下),可以快速做图了解大致情况,但是画的图不好看,后续会尝试自己用R语言实现作图。
- dot_plotter.java
- dual_synteny_plotter.java
- circle_plotter.java
- bar_plotter.java
- family_circle_plotter.java
- family_tree_plotter.java
软件安装
一般而言,按照下面的方法就能顺利安装。显然我的过程并没有那么顺利,所以我得多说几句
wget http://chibba.pgml.uga.edu/mcscan2/MCScanX.zip
unzip MCScanX.zip
cd MCScanx
make
# 在.bashrc添加下有分析java类的路径, /path/to 一定要替换成自己的实际路径
CLASSPATH=/path/to/MCScanx/downstream_analyses
报错1: "msa.cc:289:22: error: ‘chdir’ was not declared in this scope"
解决方案: 打开msa.cc,在顶部加上#include
报错2: "dissect_multiple_alignment.cc:252:44: error: ‘getopt’ was not declared in this scope"
解决方案: 打开"dissect_multiple_alignment.cc",在顶部加上#include
报错3: "detect_collinear_tandem_arrays.cc:286:46: error: ‘getopt’ was not declared in this scope"
解决方案: 打开"detect_collinear_tandem_arrays.cc",在顶部加上#include
报错4: "make[1]: javac: Command not found"
解决方案: 在https://www.oracle.com/technetwork/java/javase/downloads/index.html下载JDK,安装Java环境
经历了以上挫折后终于编译成功,下一步就是测试软件能否顺利运行。在MCScanx文件夹下有一个data目录, 里面准备了一些测试数据
./MCScanx data/at
duplicate_gene_classifier data/at
detect_collinear_tandem_arrays -g data/at.gff -b data/at.blast -c data/at.collinearity -o data/at.syn
脚本:get_the_longest_transcripts.py, 输出文件分为: 基因ID, 最长的转录本ID,染色体编号,start, end, strand