在学习本系列的文章之前,建议看看本篇的前作《杂感(一)》,该篇讨论了如何进行学习,以及学习策略,相信会对数据结构系列的学习会有所帮助。
前言
在写本篇的时候,我想起大学里面,我刚学数据结构这门课程的时候,我当时对这门课是下定决心去听,但是我忽略的有几点,大学课程是承前启后的,学习数据结构则需要对一门高级语言比较熟悉还需要有一定的编码量,学习数据结构这门课程,障碍才不那么的大,但是我对我当时唯一学过的C语言还不那么熟悉还没有一定的编码量,导致我学习这门课程的时候处于一种朦胧的状态,对数据结构这门课程处于一种似懂非懂的状态,后来代码量飞速增长之后,学习数据结构才感觉得心应手一点。所以我的建议是在学习本系列的文章之前,也建议对一门高级语言有大致的了解。
再聊聊文风吧,我不大喜欢写那种书籍的笔记,将书中核心的概念记下来,我更喜欢的是以我自己的方式将这些概念组合起来,加入我自己的理解。
日常生活中的"线性表"
排队是我们日常生活中比较常见的场景,除了队头和队尾的人,每个人的前后相邻者都只有一个,一个人可以看成一个结点,则称这样的结点之间的关系是一对一,即除了第一个和最后一个数据元素之外,其他数据元素都是首尾相接的。由此我们就引出了数据结构中的线性表, 在数据结构中,把这种数据元素之间是一对一关系的结构成为线性表,线性表除了第一个和最后一个数据元素之外,其他元素都是首尾相接的。
照之前我们所讨论的,讨论数据结构一般是讨论逻辑结构、存储结构、基于该结构的运算。
我们首先来讨论线性表的逻辑结构,其实在介绍上面的逻辑结构上面已经介绍过了,我们这里来讨论一下线性表的逻辑特征:
- 存在唯一的一个被称为"第一个"的结点,即开始结点,队头。
- 存在唯一的一个被称为"最后一个"的结点,即终端结点,队尾。
- 除第一个之外,集合中的每个结点均只有一个前驱,每个排队的人前面只有一个人
除最后一个之外,集合中的每个结点均只有一个后继。从日常生活中的排队来是的话,就是每个排队的人,后面就有一个人
你看我们将这些抽象的数据结构和现实对应的场景做对照,这些相对抽象的东西是不是也不是那么难以理解了。
再议数据结构的三要素
我们这里回忆一下《数据结构与算法分析(一)》中我们提到的数据结构的基本概念中的数据结构三要素:
- 数据的逻辑结构
- 数据的存储结构
- 数据的运算
数据的逻辑结构描述的是数据之前的联系,是独立于计算机的,我们上面讨论的线性表的逻辑结构属于线性逻辑结构,属于"一对一"的,这里所说的一对一指的就是上面所提到的逻辑特征所描述的。数据结构从逻辑结构上划分大致上就可以分成线性结构和非线性结构,其实还可以做更为细致的划分,像下面这样: 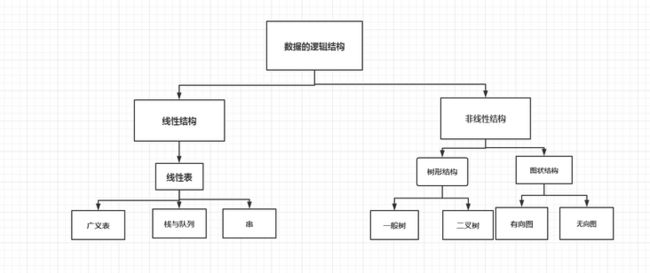
那看来当我们谈起数据结构的时候,主要说的还是数据结构的逻辑结构呀。
接下来我们来讨论一下数据的存储结构,数据的存储结构又称物理结构,是数据及其逻辑结构在计算机中的表示方式,指数据该如何在计算机中存放,事实上是内存单元分配,在具体实现时用计算机语言中的数据类型来描述。
我们思考一下存储数据应该存些什么? 怎样去存,存数据不仅仅要保存数据本身的值,还要保存数据间的联系,这样才能把相关问题的所有信息都存储完整。保存数据间联系的目的,是可以通过这种联系找到与之相连的元素。其次我们在计算机存储数据的目的是为了对它们进行处理,如果存进机器了但要用的时候找不到,数据的存储就失去了意义,这里"找到"的含义是一个是能够找到能与之相连的数据元素,所以,数据结构的存储结构的设计应该基于下面两个原则:
- 存数值,存联系
- 存的进,取的出
众所周知,我们的程序在运行之后,是被加载进入内存的,大多数情况下程序运行时的数据都驻留在内存中,那么我们该如何审视内存呢,我的想法是我们应该对内存进行抽象,可以将内存理解为一个数组,数组的下标是该内存的地址,有的高级语言一开始就像操作系统申请了一大份内存空间(像Java、C#),而有的语言则是需要了再向操作系统所申请像(C,C++)。
所以我们可以理解为操作系统向我们提供的最初的就是顺序存储结构,在这个基础上衍生了链式存储结构、索引存储结构、散列存储结构等。 - 顺序存储结构: 连续顺序地存放数据元素,物理内存结构上,数据之间是相邻的。若数据的逻辑结构也是顺序(线性的),则逻辑结构和存储结构完全统一了。连续存放的数据元素可以很容易地在内存中找到。
- 链式存储结构: 链式存储结构很像火车,将每节车厢视作一个数据元素,那每节车厢还持有指针项(即铁索)。元素在内存中不一定连续存放,在元素中附加指针项,通过指针可以找到与之逻辑相连的数据元素的实际位置。
- 索引存储结构: 索引存储方法是存储结点信息的同时,建立一个附加的索引表。索引表中的每一个索引项,索引项的一般形式是: (关键字,地址)
- 散列存储结构: 散列处处方式,以结点的关键字做自变量,通过函数关系F,直接算出该结点的存储地址: 结点地址 = F(关键字),这个有的时候也被称为散列算法。
线性表的存储结构—顺序表
将线性表中的元素依次放在放在一个连续的存储空间中,这样的线性表叫顺序表(Sequential List)。连续的存储空间,想到了什么,就是数组,数组中的元素就是在一个连续的存储空间中,因此可以采用一维数组来存储线性表的各个结点。根据"存结点存联系"的存储原则,顺序表的存储方式虽然并没有直接存储结点之间的逻辑关系,但是结点通过物理地址即存储相邻体现了逻辑相邻。
C语言的话,通常是借助于结构体来体现线性表,实现数据结构的各种运算,比如初始化、插入、删除遍历等。但对于面向对象系的高级语言我们通常可以借助类来表达。如果你熟悉Java中的ArrayList的话,Java中的ArrayList的就是一个实现即好的线性表,存储结构是线性表是数组,所以我们看源码也是能够增进我们对数据结构的理解,学习别人是如何设计的。在顺序表上的操作通常有:
- 初始化: 给线性表一些默认参数,一些高级语言会内置一些已经写好了的数据结构,我们在学习数据结构的时候可以去参考。
- 求长度: 求线性表元素的个数
- 取元素: 取给定位置的元素值
- 定位: 查找给定元素值的位置
- 插入: 在指定的位置插入给定的值
- 删除: 在指定的位置删除值,删除给定的值
线性表的英文是SequenceList,我们建个类来实现以下:
/**
* @author XingKe
* @date 2021-07-24 15:04
*/
public class SequenceList{
private int[] elementData;
/**
* 定义一个变量来返回给调用者
*/
private int size;
/**
* 默认数组大小
*/
private int DEFAULT_SIZE = 15;
/**
* 我们要不仅仅满足于实现一个简单的数据结构
* 还要设计一个良好的接口、函数。给调用者一个良好的使用体验。
* 发现Java泛型不能直接初始化,这里就直接用int举例了。
* @param initSize
*/
public SequenceList(int initSize) {
if (initSize > 0){
elementData = new int[initSize];
}else {
// 抛一个异常出来 或者拒绝执行初始化
}
}
/**
* 这里我们也给出一个无参的,不强制要求调用者一定给定出初始大小
*/
public SequenceList() {
elementData = new int[DEFAULT_SIZE];
}
/**
* 该方法默认将元素添加至数组已添加的最后一个元素之后
* @param data
*/
public void add(int data){
// 首先我们判断元素是否放满了,如果放满了,再放就放不下了
// 我们执行就需要对数组进行扩容,但是我们知道数组一开始就要执行初始化.
// 所谓的扩容就是产生一个新数组
// 这里我们先按扩容两倍来处理,事实上这也是一种权衡
ensureCapacity(size + 1);
if (size + 1 > elementData.length){
// 说明当前需要扩容
elementData = new int[elementData.length * 2];
}else{
elementData[size++] = data;
}
}
/**
* 取指定位置的元素
* @param index
*/
public int get(int index){
rangeCheck(index);
return elementData[index];
}
/**
* 取给定元素的位置,默认返回第一个,不存在则返回-1
* @param data
* @return
*/
public int indexOf(int data){
for (int i = 0; i < elementData.length; i++) {
if (data == elementData[i]){
return i;
}
}
return -1;
}
/**
* 向指定位置插入元素
* @param index
* @param data
*/
public void add(int index, int data){
// 先检查位置,有这么多检查位置的,事实上我们可以做一个通用的方法出来
// 这里我就不做了
// 范围检查,如果数组元素不够 执行扩容
rangeCheck(index);
ensureCapacity(size + 1);
// index 到 size - 1 这个位置上的元素都向后平移一位
for (int i = size - 1; i >= index; i--) {
elementData[ i + 1 ] = elementData[i];
}
elementData[index] = data;
++size;
}
/**
* 查看是否超出了数组的容纳
* 超出了执行扩容
* @param minCapacity
*/
private void ensureCapacity(int minCapacity) {
if (minCapacity > elementData.length){
elementData = new int[elementData.length * 2];
}
}
private void rangeCheck(int index) {
if (index < 0 || index > elementData.length){
throw new IndexOutOfBoundsException();
}
}
/**
* 移除指定元素的位置
* @return
*/
public int remove(int index){
// 先检查位置
rangeCheck(index);
int data = elementData[index];
// index+1到size - 1 往前移动一个位置
for (int i = index + 1; i < size ; i++) {
elementData[i] = elementData[++index];
}
// 移除后长度--
size--;
return data;
}
/**
* 求长度这里,我们有两种思路,一种是每次都遍历一下,算出长度
* 第二个就是在添加的时候,就对size变量进行++
* 综合上来看,第一种思路更为优秀,所以size方法直接返回
* @return
*/
public int size(){
return size;
}
}在末尾插入和删除末尾的时间复杂度,我们不再分析,我们仅来分析在中间插入的时间复杂度,事实上在末尾插入也可以包含在中间插入这种情况中。这里的问题规模是结点的个数,也就是元素的数量,插入新元素后,结点数变为n+1。
该算法的时间主要花费在结点循环后移上语句上,该语句的执行次数是结点移动次数为n-k(k为插入位置)。由此可以看出,所需移动结点的次数不仅依赖于表的长度,而且还需要插入位置有关,不失一般性,假设在表中任何位置(0<=k<=n)上插入结点的机会是均等的:
| 插入下标位置K | 0 | 1 | 2 | .... | n |
|---|---|---|---|---|---|
| 移动次数 | n | n-1 | n-2 | 0 | |
| 可能的概率 | 1/n+1 | 1/n+1 | 1/n+1 | 1/n+1 | 1/n+1 |
最好情况下: 当k=n时,也就是仅仅需要在最后也就是相当于队尾添加元素,不需要移动,其时间复杂度为O(1)。
最坏情况下: 当k=0时,结点的移动次数为n次,就是说要移动表中的所有结点。
平均情况: 在长度为n的线性表在第k个位置上插入一个结点,移动次数为n-k。平均移动次数为: (1/n+1)* (n(n+1))/2 = n/2。
由此可见在线性表上做插入运算,要平均移动表上一半元素,算法的平均时间复杂度为: O(n)。
线性表的删除运算也是需要移动结点,以填补删除操作造成的空缺,从而保证删除后的元素间依然通过物理地址相邻而体现逻辑相邻的关系。若删除位置刚好是最后一个元素,则只是需要删除终端结点,无须移动结点: 若0=< i <= n-1,则必须将表中的位置i+1,i+2...,n-1的结点移动到i,i+1,...,n-2上,则需要将i+1至n共n-i个元素前移。
设结点数为n,同插入元素一样,删除算法的时间主要花费是在结点循环前移语句上,设移动位置为k,则该语句的移动次数为n-k-1,因此所需的移动次数不仅依赖于表的长度,而且还与删除位置有关:
| 删除下标位置K | 0 | 1 | 2 | .... | n-1 |
|---|---|---|---|---|---|
| 移动次数 | n - 1 | n-2 | n-3 | 0 | |
| 可能的概率 | 1/n | 1/n | 1/n | 1/n | 1/n |
最好情况: 当k = n - 1,结点前移语句不再进行,其时间复杂度为O(1).
最坏情况: 当k = 0,所有结点都需要移动。
平均情况: 同样的不失一般性,我们假定删除位置在0到n-1的各个位置上出现的概率是均等的,则结点需要移动的平均移动次数为: 1/n (n-1)n / 2 = (n-1)/2. 概率乘以移动次数然后累加。由此可见,在顺序表上做删除运算,平均约需要移动一半元素,算法的平均时间复杂度为O(n). 数组根据下标访问的元素,不依赖于位置,时间复杂度为O(1).
线性表的存储结构—链表
链式存储结构或者说链式结构在现实生活中时比较常见的,比较为人所熟知的就是火车,像下面这样: 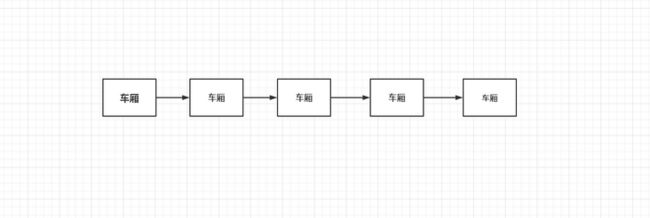
车厢在并没有直接联系,而是通过车厢间的链条建立联系。如果你和你的朋友一起坐火车去旅行,如果你俩刚好在买的相邻的座票,那如果你想找她说话,那么因为相邻,你直接说就可以了。但是如果很不凑巧你的朋友在另外一个车厢,但是你知道你朋友在哪座车厢你就可以找到他,这在某种意义上就是链式结构。
如果你的所坐的火车在找人的时候只能从前面的车厢找到后面的车厢,后面的车厢无法到达前面的车厢,我们就称这样的火车为单向火车,用数据结构的术语来称呼的话就是单向链表。
假如你所坐的火车在找人的时候虽然只能从前面的车厢找后面的车厢,但是最后一节车厢可以到达第一节车厢,像这样的存储结构在数据结构中我们称之为循环链表。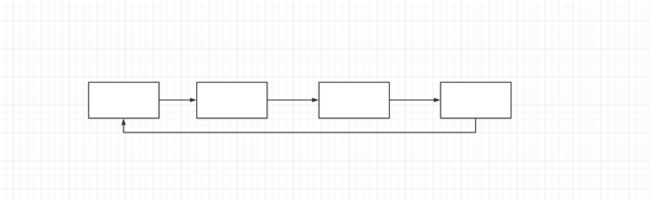
如果你坐的火车后面的人能够到达他前面的车厢,前面的人也能到达他后面的车厢,那么像这样的存储结构我们就称之为双向链表。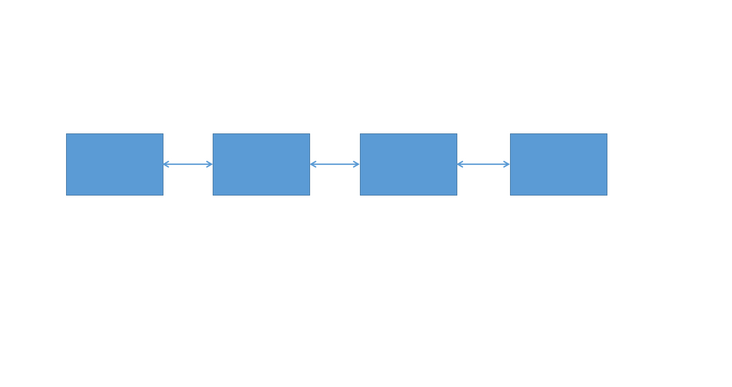
从上面的讨论我们应该可以得出链表结点的结构设计,像每个车厢自己装载乘客一样,也持有了下一个车厢的位置(也就是车厢之间的链条)。链表也和车厢相似,每个结点存储本身的信息之外还存储相邻结点的位置。
单链表
基于上面的讨论,单链表只能从前往后,每个结点不仅存储自己本身信息之外还存储下一个结点的存储地址,我们可以大致给出结点的数据结构:
public class SingleLinkedListNode {
// 存储结点本身的信息
private int data;
// 存储下一个结点的信息
private SingleLinkedListNode next;
public int getData() {
return data;
}
public void setData(int data) {
this.data = data;
}
public SingleLinkedListNode getNext() {
return next;
}
public void setNext(SingleLinkedListNode next) {
this.next = next;
}
}事实上我们也可以将这个结点放在我们设计的内部类中,阅读和使用起来更为简单。建立单链表通常有两种基本方式:
尾插法
尾插法更加简单一点,符合直觉,我们还是用火车车厢这个例子来解释尾插法,我们可以将火车头理解为头结点,新来一个车厢我们称之为a1吧,要挂就挂在火车头后面,再来一节车厢我们称之为a2吧,这个就挂在a1后面。这个我们就称之为尾插法。新来的结点都挂在最后一个结点的后面的,这也就是尾插法的来由。
头插法
尾插法像是排队一样,新的人排在队列的后面,那么头插法则与尾插法相反,他是插队。刚开始只有一个头结点,我们称之为a1,再来一个结点我们称之为a2,我们将其放在a1之前。
在讨论存储结构和初始化方式之后,我们开始讨论一下单链表的相关运算,这也是我们后面介绍数据结构的基本思路,先是引入,再是介绍其存储结构,最后讨论基于该数据结构的运算。我们这里只讨论单链表的几种核心运算:- 初始化
查找
查找又可以分为两种: 按值查找和按序号查找(类似于数组的按下标查找)
- 插入
删除
/** * @author XingKe * @date 2021-07-31 10:39 * 这里我们从用尾插法的方式来建立单链表 */ public class SingleLinkedList { private Node head; /** * 结点数量 */ private int size; private class Node{ private int data; private Node next; public Node(int data, Node next) { this.data = data; this.next = next; } public Node(int data) { this(data,null); } @Override public String toString() { return "Node{" + "data=" + data + '}'; } } public SingleLinkedList(int data) { head = new Node(data,null); size++; } /** * 直接添加在末尾 */ public void add(int data){ Node lastNode = head; while (lastNode.next != null){ lastNode = lastNode.next; } Node newNode = new Node(data); lastNode.next = newNode; size++; } /** * 检查位置是否合法,我们将其抽象出来做成一个方法 * @param index */ public void checkPosition(int index){ if (index < 0 || index >= size){ throw new RuntimeException("下标越界"); } } /** * 单链表的插入,我们只需要将插入位置的元素的next指向要添加元素,要添加的元素的next指向插入位置原先的next * @param data * @param index */ public void add(int data, int index){ checkPosition(index); Node indexNode = get(index); Node afterNode = indexNode.next; Node insertNode = new Node(data,afterNode); indexNode.next = insertNode; size++; } /** * 按数据查找 * @param data * @return */ public int indexOf(int data){ Node indexNode = head; int index = - 1; while (indexNode.data != data){ indexNode = indexNode.next; index++; } return index; } /** * 按下标查找 * @param index * @return */ public Node get(int index){ checkPosition(index); Node indexNode = head; for (int i = 0; i < index; i++) { indexNode = indexNode.next; } return indexNode; } /** * 如果是队尾直接移除即可 * 如果是中间,移除位置的前一个位置和后一个位置相连即可 * @param index */ public void remove(int index){ checkPosition(index); // 获取需要移除位置的前一个结点 // 即移除头结点,那么头结点的下一个结点称为头结点 if (index == 0){ head = head.next; return; } Node indexNode = get(index - 1); Node afterNode = indexNode.next.next; indexNode.next = afterNode; } }
接下来我们来分析一下查找,删除,插入的复杂度。这些都跟位置有关系,以查找为例,假设查找的元素刚好处于头结点,那只需要一次查找就可以了。
| 查找位置 | 0 | 1 | 2 | n |
|---|---|---|---|---|
| 查找次数 | 0 | 1 | 2 | n |
| 概率 | 1/n | 1/n | 1/n | 1/n |
各个位置的查找次数乘以对应概率累加即为平均查找次数,最(n(n+1)/2) * (1 / n),时间复杂度为O(n).
删除和查找相似时间主要都花在查找上了,因此时间复杂度也为O(n)
相对于单向链表,循环链表的最后一个结点指向头结点,这是循环链表与单向链表不同的一点。
双向链表
在顺序表中我们总是可以根据下标可以很方便的找到表元素的前驱和后继,但单链表只能找后继,若需要对某个结点的直接前驱进行操作,则必须从头结点找起。因为单链表的结点只记录了后继结点的位置,而没有前驱结点的信息。那么能不能在其结点结构中增加记录前驱接地的数据项呢? 当然是可以的,基于这种思想设计出来的,我们就称之为双向链表。
/**
* @author XingKe
* @date 2021-07-31 12:36
*/
public class DoubleLinkedList {
private Node head;
// 指向第一个元素
private Node last;
private int size;
private class Node{
private Node before;
private int data;
private Node next;
public Node(int data, Node next, Node before) {
this.data = data;
this.next = next;
}
public Node(int data) {
this(data,null, null);
}
@Override
public String toString() {
return "Node{" +
"data=" + data +
'}';
}
}
public DoubleLinkedList(int data) {
Node node = new Node(1);
head = node;
last = node;
size = 0;
size++;
}
public void add(int data){
last.next = new Node(data,null,last);
size++;
}
public void add(int data,int index){
// 定位该下标的位置
Node indexNode = node(index);
size++;
}
public void checkPosition(int index){
if (index < 0 || index >= size){
throw new RuntimeException("下标越界");
}
}
// 有了前驱结点,我们就不必从头找到尾了,我们可以根据下标判断
// 如果比较靠厚我们就从最后一个结点找,如果比较靠前我们就从头结点开始找
// index < size / 2 那说明比较靠前,我们从头遍历,
// 如果index > size / 2 , 那说明比较靠后,我们就从后往前找即可。
// 我们最多只需要查找一半的次数就可以了
private Node node(int index) {
checkPosition(index);
if (index < size / 2){
Node indexNode = head;
for (int i = 0; i < index ; i++) {
indexNode = head.next;
}
return indexNode;
}else{
Node indexNode = last;
for (int i = size ; i > index ; i--) {
indexNode = indexNode.before;
}
return indexNode;
}
}
}删除和添加的操作也都花在查找元素上,我们这里分析一下查找的时间复杂度:
| 查找位置 | 0 | 1 | 2 | index - 1 |
|---|---|---|---|---|
| 查找次数 | 0 | 1 | 2 | index - 1 |
| 概率 | 1/n | 1/n | 1/n | 1/n |
相对单链表来是我们可以直观的感受到双向链表最差只用查找一半的范围就可以了,index越向中间靠,查找的次数越多.
查找的时间复杂度为O(n),这里可能有同学会问了,这不跟单链表差不多了吗? 注意这个是渐进上界, n /2 和 n/4 都小于n,我们可以理解为这个n就是大O符号标记的,逼近的不够紧凑,我们表示的时间复杂度的时候可以选取尽量紧凑的上界,如果上界选的过大,那么就可能违背知觉。这个式子累加起来较为紧凑的上界为O(n/4),而单链表的查找速度为O(n/2).
设计一种数据结构,我们要想的灵活一点,思考如何基于原有的数据结构进行加强,我参考的书籍所构造的双向链表只有一个头结点,但是我参考了Java中的LinkedList(JDK官方实现的双向链表),但是为了寻址方便这里又增加了size和last。所以在设计数据结构的时候,也可以参考所使用的高级语言的类库。
总结一下
本篇属于《数据结构与算法分析系列》中的一篇,算是重修数据结构与算法分析了。这本来是将近一章的内容,我并入一篇文章里,大概写了将近两个周末,以后尽量敏捷一点,做到不堆积太多内容。