作者:翁智华
出处:https://www.cnblogs.com/wzh2010/
概述
我们所说的缓存分为进程内部缓存(系统内部缓存)和 缓存服务(如redis/memcache)。
计算机服务从原来的单体结构,到多实例,到现在流行的微服务,缓存服务变得原来越流行了。
进程缓存
先说说进程缓存,它将数据存储在站点、服务的进程内。在Web的发展历史上,这样的方式备受欢迎。比如早期常用的.Net的 System.Web.Caching.
这种实现载体很简单,比如一个带锁的HasTable,或者一个List对象。 使用简单便捷,能存储数据、html页面片段、文件,甚至任何对象。
在单体结构的Web模式下,进程内缓存被开发到极致,大概流程如下图:

与原先没有缓存相比,进程内缓存的好处是,数据读取不再直接访问数据库,先判断缓存中是否存在,如果存在,则直接读取,不存在则再去数据库中取,同时写入缓存。
这样避免了每次的请求都走数据库,减少网络开销和数据请求次数,提高了数据获取效率,基本等同在内存中执行。
缓存的目的是为了冷热数据的隔离,对于频繁被修改的数据,缓存的意义不是很大,比如微信用户的实时步数。比较有价值的是那些不被频繁修改且数据量较大的内容,比如系统字典、配置数据。
判断是否需要创建缓存需要一定的依据,以下是我的团队的策略,不一定适用,可以参考:
缓存的必要性:数据的变更是否过于频繁,过于频繁则可能导致缓存不断重建,反而降低效率。 评估方式:缓存的过期时间内没被主动更新的量值应该超过60%。
假设缓存时间:3600s
假设同一种类型缓存数据基数:6000个
6000 * 60% = 3600 的数据在一个小时内事务未更新,这样的缓存价值更大。
进程缓存的问题
在互联网大潮下,随着用户量的激增,原来单体结构逐渐的向Web服务集群发展,在多实例目标下,进程缓存的弊端越来越明显。
比如缓存无法统一的问题。
如果站点和服务中的多个节点访问统一的缓存服务(比如redis 或者 memerche),数据统一存储,数据的一致性就比较容易保障。
但如果是进程缓存,数据存储在站点和服务的多个节点内,每个节点一个缓存,存储多份,一致性就比较难保障。
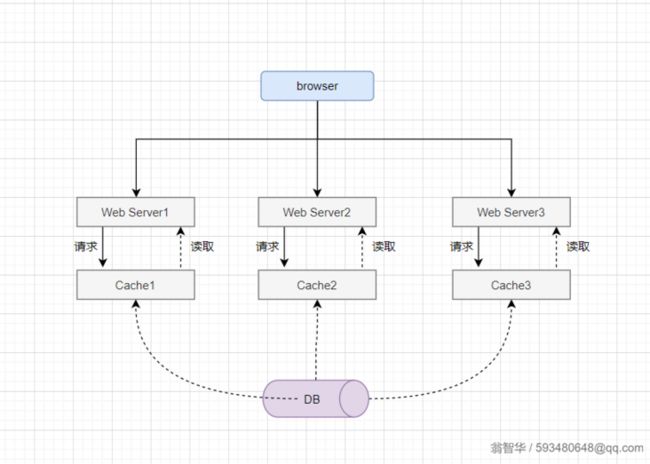
如上图,但是有个问题,Cache1、Cache1、Cache3一致性难以保障,如果想保持缓存的一致性时,该怎么办呢?
一般有以下几种方法:
1、单一服务节点通知其他服务节点,如果我们只是Web Service1 在执行业务操作的时候修改数据库,更新缓存,同时通知其他Web Service
服务,其他Web Service 接收到信息的时候,进行缓存更新。
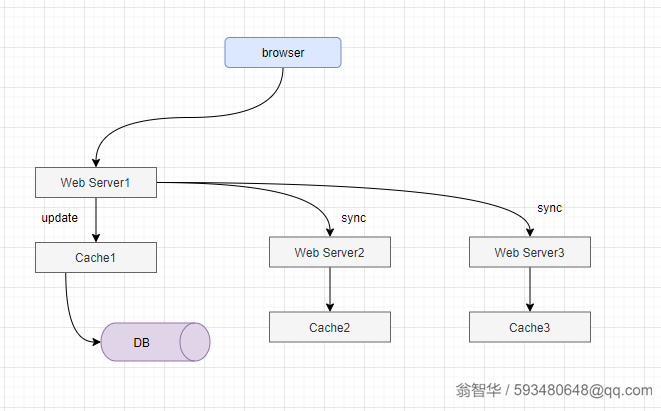
2、 启动MQ通知其他节点:如下图,可以通过MQ通知其他节点。写请求发生在server1,在修改完自己缓存数据与数据库中的数据之后,给MQ生产数据变化通知,
server2和server1订阅MQ消息,当消费到MQ信息的时候,也修改缓存数据。
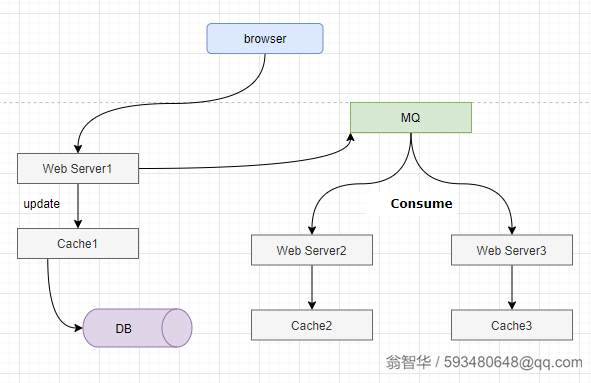
3、有一种简单的方式,也可以解耦与Web Server的关系,就是直接放弃了“实时一致性”,启动一个独立的进程服务,定时从后端拉取最新的数据,更新内存缓存。
上述的几种方法为了保持数据的一致性,增加了一定的开销,一方面缓存数据同步过程中会有出错的风险;
另一方面实际上违背了缓存的原则:冷热数据隔绝,有效的利用冷数据,减轻数据库压力,提升效率。如果缓存被频繁修改或者同步,那缓存的价值就不大了。
补充:1、2 两种方式,实例越多,缓存冗余越多,各缓存节点数据同步的原子性越难保证,一致性也就越难保证。
第3种方式:采用定时拉取本身已经放弃了数据的实时一致性。
所以我们在以下这几种情况下抛弃进程缓存,选用缓存服务:
1、Web集群下,包含多个实例,并且不允许业务数据的不一致性(我相信大部分业务不允许)
2、进程内缓存数据量较大,缓存内存空间不足,影响Web性能,可以考虑走缓存服务(缓存服务如redis,一般独立服务甚至集群配置,支持超大量级)。
3、评估value大小、缓存内存空间、峰值QPS、过期时间、缓存命中率、读写更新策略、key值分布路由策略、过期策略以及数据一致性方案,根据实际需要判断是否走缓存服务。
缓存服务
在互联网分层架构中,最常用的kv结构的缓存是redis。他有如下特点:

1、它支持复杂数据结构
value是字符串、哈希,列表,集合,有序集合这类复杂的数据结构。支持各种场景,如客户订单信息列表,用户消息,帖子评论等。
2、支持持久化
首先,redis的所有数据都是保存在内存中,然后不定期的通过异步方式保存到磁盘上(这称为“半持久化模式”);
也可以把每一次数据变化都写入到一个append only file(aof)里面(这称为“全持久化模式”,效率会低一点)。
但是我们尽量不要把redis当作数据库用,如果真的需要持久化数据,建议可以走MySQL:
2.1、redis的定期快照不能保证数据不丢失
2.2、redis的AOF会降低效率,并且不能支持太大的数据量
3、具备高可用特性
redis天然支持集群功能,可以实现主动复制,读写分离。 官方也提供了sentinel集群管理工具,能够实现主从服务监控,故障自动转移。
4、存储的内容比较大
String类型:一个String类型的value最大可以存储512M,List、Set、Hash类型:list的元素个数最多为2^32-1个,也就是4294967295个。
5、 支持事务
操作都是原子性,对数据的更改要么全部执行,要么全部不执行。避免业务数据的不一致性。
缓存使用注意
1、Web服务 单体模式转为多实例之后,我们将进程缓存升级为缓存服务(redis),清清理了所有的缓存使用,都改成了对接redis。但是有一些地方漏掉,因为我们有3个实例,所以漏掉的那几个地方,一旦修改某个数据之后,一会儿是新值,一会儿旧值,很神奇。
2、谨防缓存击穿、雪崩的产生,这个我们有惨痛的教训,后续来一篇专门分析下。
近期热文推荐:
1.1,000+ 道 Java面试题及答案整理(2021最新版)
2.终于靠开源项目弄到 IntelliJ IDEA 激活码了,真香!
3.阿里 Mock 工具正式开源,干掉市面上所有 Mock 工具!
4.Spring Cloud 2020.0.0 正式发布,全新颠覆性版本!
觉得不错,别忘了随手点赞+转发哦!