aggregator组件负责聚合,即根据定义的指标表达式,聚合该组下所有host的指标值,生成新的指标发送到agent。
agent会将数据发送给transfer,transfer发送给graph,最终由graph存入TSDB。
值得注意的是,aggregator实例对分布式部署的支持有限,因为它每个实例都执行所有的聚合任务,没有进行聚合任务在不同节点的均分,也没有锁机制保障执行1个实例运行。
当然,部署多份实例也不会出现逻辑错误,只是运行了多份相同的任务而已。
1. aggregator的聚合表达式
指标表达式分为分子和分母两部分,每部分都是1个表达式,分别计算出2部分的值,做商即得结果。
# 计算cpu.used.percent的平均值
分子:$(cpu.used.percent)
分母:$#
# 计算磁盘吞吐量的总量
分子:$(disk.io.read_bytes)
分母:1此外,还能进行更复杂的集合语义:
# 计算disk.io.util大于等于40%的机器个数
分子:$(disk.io.util)>=40
分母:1
# 计算集群diso.io.util大于40%的比率
分子:$(disk.io.util)>40
分母:$#2. aggregator的聚合模型
聚合模型体现在Cluster结构中:
type Cluster struct {
.....
GroupId int64 //聚合组id
Numerator string //分子表达式
Denominator string //分母表达式
Endpoint string //目标endpoint
Metric string //目标metric
Tags string //目标tags
DsType string //目标metric类型
Step int //目标metric的step大小
....
}其中:
- GroupId: 聚合组id,根据该id可以查询得到该组下所有host;
- Numberator: 分子表达式,比如$(cpu.used.percent);
- Denominator: 分母表达式,比如$#;
- Endpoint: 聚合后的endpoint;
- Metric: 聚合后的metric;
- Tags: 聚合后的tags;
- DsType: 聚合后的metric类型,GAUGE或COUNTER;
- Step: 聚合后的metric的step大小;
以聚合组内所有host的cpu.used.percent平均值为例:
GroupId = 900
Numerator = $(cpu.used.percent)
Denominator = $#
Endpoint = 84aba056-6e6c-4c53-bfed-4de0729421ef
Metric = cpu.used.percent
Tags = null
DsType = GAUGE
Step = 60聚合组内所有host的cpu.used.percent,计算平均值,然后生成endpoint=84aba056-6e6c-4c53-bfed-4de0729421ef,metric=cpu.used.percent, dsType=GAUGE, Step=60的指标。
3. aggregator的聚合流程
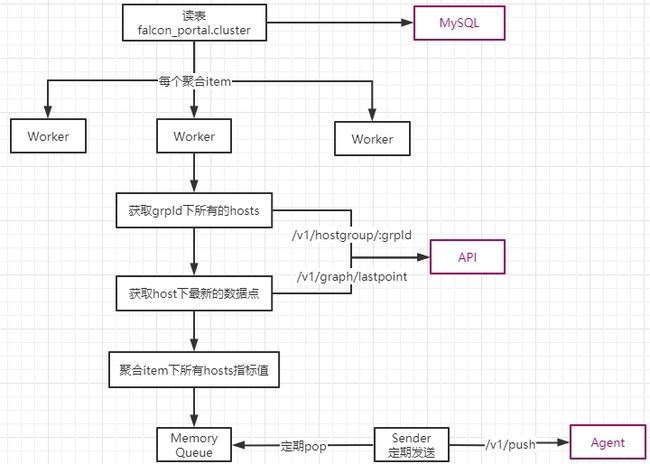
- 所有要聚合的信息存储在db中,每条记录就是上面的一个cluster结构;
对每个聚合记录,启动1个goroutine定期进行聚合;
- 聚合时,先查询聚合组下所有的host列表
- 再查询每个host,表达式内相关指标的的最新数据点,比如要聚合cpu.used.percent,就查询所有host最新的cpu.used.percent的最新数据点;
- 利用最新的数据点,分别计算分子表达式和分母表达式的值,做商得到最终的指标值;
- 聚合的指标值存储在本地Queue中,有1个goroutine默默的pop出来,HTTP发送给agent;
聚合的入口代码:定期检查新monitorItem和删除老的monitorItem
// modules/aggregator/cron/updater.go
func UpdateItems() {
for {
updateItems()
d := time.Duration(g.Config().Database.Interval) * time.Second
time.Sleep(d)
}
}
func updateItems() {
items, err := db.ReadClusterMonitorItems()
if err != nil {
return
}
deleteNoUseWorker(items)
createWorkerIfNeed(items)
}对于新的monitorItem,会给它启动一个worker:
//modules/aggregator/cron/worker.go
func createWorkerIfNeed(m map[string]*g.Cluster) {
for key, item := range m {
//若是新的monitorItem
if _, ok := Workers[key]; !ok {
if item.Step <= 0 {
log.Println("[W] invalid cluster(step <= 0):", item)
continue
}
worker := NewWorker(item)
Workers[key] = worker
worker.Start()
}
}
}新的worker启动了1个goroutine,定期进行聚合:
// modules/aggregator/cron/worker.go
func (this Worker) Start() {
go func() {
for {
select {
case <-this.Ticker.C:
WorkerRun(this.ClusterItem)
case <-this.Quit:
this.Ticker.Stop()
return
}
}
}()
}具体的聚合过程比较复杂,结合注释分析一下:
- 首先分别解析分子表达式和分母表达式,得到所有相关的metric及其计算方式;
- 然后查看聚合组下所有的hosts列表;
- 然后查询hosts列所有相关metric的最近的指标点,存储在valueMap;
对所有hosts分别计算分子和分母的数值,分子/分母即是最终的聚合值;
- 中间有一个特殊处理,比如$#是算平均值,1是算sum;
// modules/aggregator/cron/run.go
func WorkerRun(item *g.Cluster) {
.....
// 解析分子表达式
//比如 numberatorStr=$(cpu.used.percent)
//返回 [cpu.used.percent], [], ''
numeratorOperands, numeratorOperators, numeratorComputeMode := parse(numeratorStr, needComputeNumerator)
// 解析分母表达式
// 比如 $#
// 返回 [], [], ''
denominatorOperands, denominatorOperators, denominatorComputeMode := parse(denominatorStr, needComputeDenominator)
// 查询GroupId内的所有hosts
hostnames, err := sdk.HostnamesByID(item.GroupId)
// 查询hosts所有相关指标的最近指标点
valueMap, err := queryCounterLast(numeratorOperands, denominatorOperands, hostnames, now-int64(item.Step*2), now)
var numerator, denominator float64
var validCount int
for _, hostname := range hostnames {
var numeratorVal, denominatorVal float64
var err error
//计算分子的聚合值
if needComputeNumerator {
numeratorVal, err = compute(numeratorOperands, numeratorOperators, numeratorComputeMode, hostname, valueMap)
....
}
//计算分母的聚合值
if needComputeDenominator {
denominatorVal, err = compute(denominatorOperands, denominatorOperators, denominatorComputeMode, hostname, valueMap)
.....
}
numerator += numeratorVal
denominator += denominatorVal
validCount += 1
}
// $#是算平均值,1是算sum
if !needComputeDenominator {
if denominatorStr == "$#" {
denominator = float64(validCount)
} else {
denominator, err = strconv.ParseFloat(denominatorStr, 64)
}
}
// 最终指标值=分子/分母,放入本地Queue
sender.Push(item.Endpoint, item.Metric, item.Tags, numerator/denominator, item.DsType, int64(item.Step))
}sender.Push()将聚合结果放入本地Queue:
// common/sdk/sender/make.go
func Push(endpoint, metric, tags string, val interface{}, counterType string, step_and_ts ...int64) {
md := MakeMetaData(endpoint, metric, tags, val, counterType, step_and_ts...)
MetaDataQueue.PushFront(md)
}后端有1个goroutine默默的pop Queue,然后HTTP发送给agent:
// common/sdk/sender/sender.go
func startSender() {
for {
L := MetaDataQueue.PopBack(LIMIT)
if len(L) == 0 {
time.Sleep(time.Millisecond * 200)
continue
}
err := PostPush(L)
...
}
}