Elasticsearch7.6.x学习笔记(超详细)
Elasticsearch和solr比较
- 当单纯的对已有的数据进行搜索时,solr更快
- 当实时建立索引时,Solr会产生io阻塞,查询性能交叉,ElasticSearch具有明显优势
- 随着数量的增加,Solr的搜索效率会变得更低,而ElasticSearch却没有明显的变化
ElasticSearch和Solr的比较总结
- es基本是开箱即用(解压就可以使用) 非常简单 Solr安装略微复杂一丢丢
- Solr利用Zookeeper进行分布式管理,而ElasticSearch 自身带有分布式协调管理功能
- Solr支持更多格式的数据,比如JSON、XML、CSV,而ElasticSearch仅支持json文件格式
- Solr光放提供的功能更多,而ElasticSearch本身更注重于核心功能,高级功能多有第三方插件提供,例如图形化界面需要kibana友好支撑
- Solr 查询快,但更新索引慢(插入删除慢),用于电商等查询多的应用
- ES建立索引快(查询慢),即实时性查询快,用于facebook、新浪等搜索
- Solr是传统搜索应用的有力解决方案,但ElasticSearch更适用于新兴的实时搜索应用
- Solr比较成熟,有一个更大,更成熟的用户,开发和贡献者社区,而ElasticSearch相对开发维护者较少,更新太快,学习使用成本较高(趋势)。
了解ELK
ELK是Elasticsearch、Logstash、Kibana三大开源框架首字母大写简称。市面上也被成为Elastic Stack。其中Elasticsearch是一个基于Lucene、分布式、通过Restful方式进行交互的近实时搜索平台框架。像类似百度、谷歌这种大数据全文搜索引擎的场景都可以使用Elasticsearch作为底层支持框架,可见Elasticsearch提供的搜索能力确实强大,市面上很多时候我们简称Elasticsearch为es.Logstash是ELK的中央数据流引擎,用于从不同目标(文俐数据存储/MQ)收集的不同格式数据,经过过滤后支持输出到不同目的地(文件/MQ/redis/elasticsearch/kafka等)。Kibana可以将elasticsearch的数据通过友好的页面展示出来,提供实时分析的功能。
市面上很多开发只要提到ELK能够一致说出它是一个日志分析架构技术栈总称,但实际上ELK不仅仅适用于日志分析,它还可以支持其它任何数据分析和收集的场景,日志分析和收集只是更具有代表性。并非唯一性。
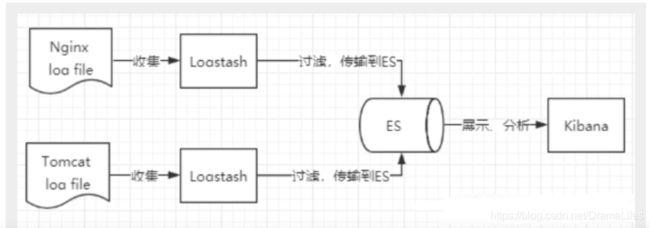
Kibana
Kibana是一个针对Elasticsearch的开源分析及可视化平台,用来搜索、查看交互存诸在Elasticsearch索引中的数据。使用Kibana ,可以通过各种图表进行高级数据分析及展示。Kibana让海量数据更容易理解。它操作简单,基于浏览器的用户界面可以快速创建仪表板( dashboard )实时显示Elasticsearch查询动态。设置Kibana非常简单。无需编码或者额外的基础架构,几分钟内就可以完成Kibana安装并启动Elasticsearch索引监测。
官网: https://www.elastic.co/cn/kibana
kibana版本要和ES版本一致
IK分词器插件
什么是IK分词器?
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,比如“我爱狂神”会被分为"我"“爱"狂”“神””,这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
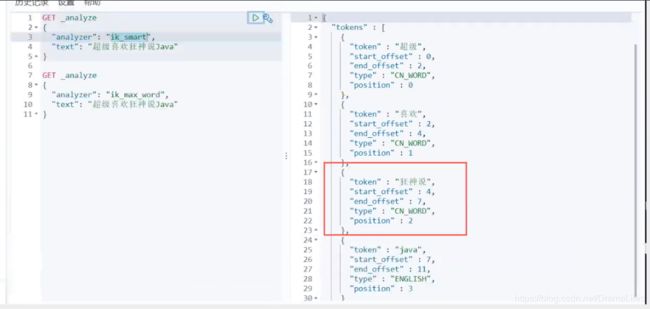
IK提供了两个分词算法: ik_smart和ik_max_word,其中
- ik_smart为最少切分,
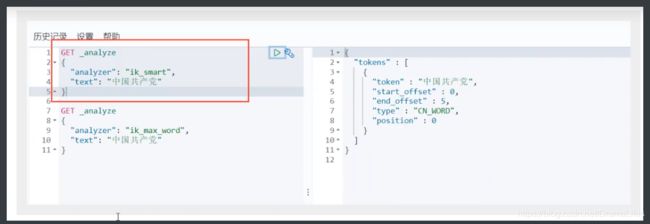
- ik_max_word为最细粒度划分!
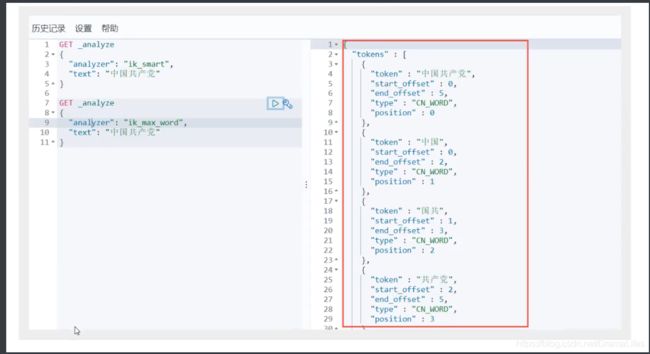
我们输入 超级喜欢狂神说Java
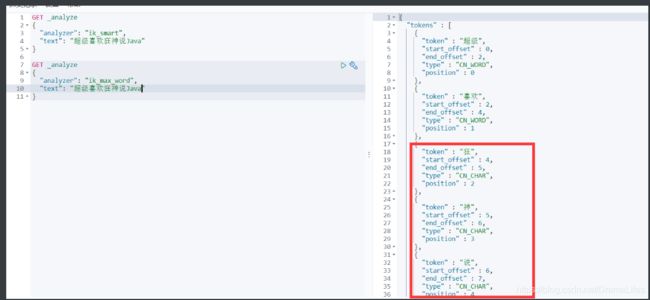
发现问题: 狂神说被拆开了
这种自己需要的词,需要自己加入到我们的分词器的字典中
ik 分词器增加自己的配置
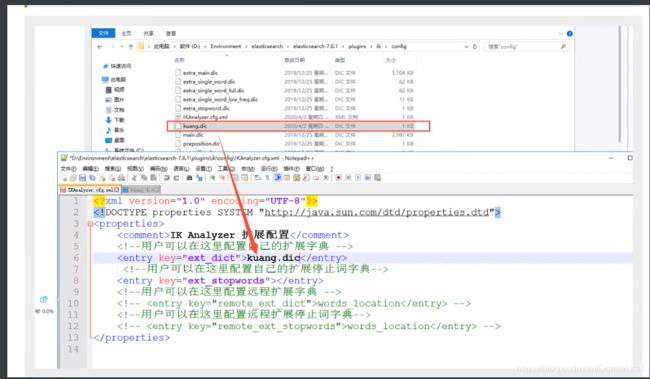
以后我们需要自己配置分词 就在自己定义的dic文件中进行配置即可!
ElasticSearch的核心概念
- 索引
- 字段类型(mapping)
- 文档(documents)
- 分片(倒排索引)
概述
在前面的学习中,我们已经掌握了es是什么,同时也把es的服务安装启动,那么es是如何去存储数据,数据结构是什么,又是如何实现搜索的呢?我们先来聊聊ElasticSearch的相关概念
集群,节点,索引,文档,分片,映射是什么?
elasticsearch是面向文档,关系行数据库和elasticsearch客观的对比 一切都是JSON
| Relational DB | ElasticSearch |
|---|---|
| 数据库(database) | 索引(indices) |
| 表(tables) | types |
| 行(row) | documents |
| 字段(columns) | fields |
elasticsearch(集群)中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又包含多个文档(行),每个文档中又包含多个字段(列)。
物理设计:
elasticsearch在后台把每个索引划分成多个分片,每分分片可以在集群中的不同服务器之间迁移
一个人就是一个集群!默认的集群名称就是elasticsearch
逻辑设计:
一个索引类型中,包含多个文档,比如说文档1,文档2.当我们索引一篇文档时,可以通过这样的一个顺序找到它:索引 –> 类型
–> 文档ID,通过这个组合我们就能索引到某个具体的文档。 注意:ID不必是整数,实际上它是个字符串
文档
之前说elasticsearch是面向文档的,那么就意味着索引和搜索数据的最小单位是文档,elasticsearch中,文档有几个重要的属性:
- 自我包含,一篇文档同时包含字段和对应的值,也就是同时包含key:value
- 可以使层次性的,一个文档中包含自文档,复杂的逻辑实体就是这么来的
- 灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在elasticsearch中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段
尽管我们可以随意的新增或者忽略某个字段,但是,每个字段的类型非常重要,比如一个年龄字段类型,可以是字符串也可以是整型,因为elasticsearch或保存字段和类型之间的映射及其他的设置。这种映射具体到每个映射的每种类型,这也是为什么在elasticsearch中,类型有时候也称为映射类型。
类型
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。类型中对于字段的定义称为映射,比如name映射为字符串类型。我们说文档是无模式的,它们不需要拥有映射中所定义的所有字段,比如新增一个字段,那么elasticsearch是怎么做的呢?elasticsearch会自动的将新字段加入映射,但是这个字段的不确定它是什么类型,elasticsearch就开始猜,如果这个值是18,那么elasticsearch会认为它是整形。但是elasticsearch也可能猜不对,所以最安全的方式就是提前定义好所需要的映射,这点跟关系型数据库殊途同归了,先定义好字段,然后再使用,别整什么幺蛾子。
索引
就是数据库!
索引是映射类型的容器,elasticsearch中的索引是一个非常大的文档集合。索引存储了映射类型的字段和其他设置。然后它们被存储到了各个分片上了。我们来研究下分片是如何工作的。
物理设计:节点和分片如何工作
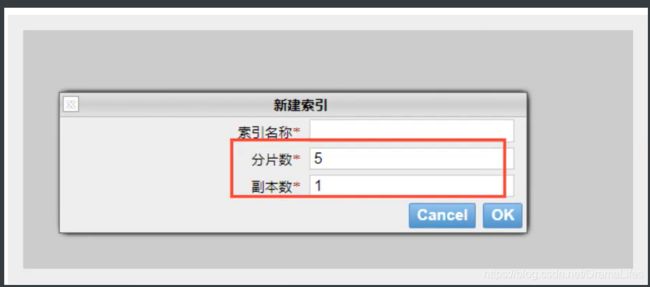
一个集群至少有一个节点,而一个节点就是一个elasricsearch进程,节点可以有多个索引默认的,一个集群至少有一个节点,而一个节点就是一个elasricsearch进程,节点可以有多个索引默认的有个5个分片( primary shard ,又称主分片)构成的,每一个主分片会有一个副本( replica shard ,又称复制分片)
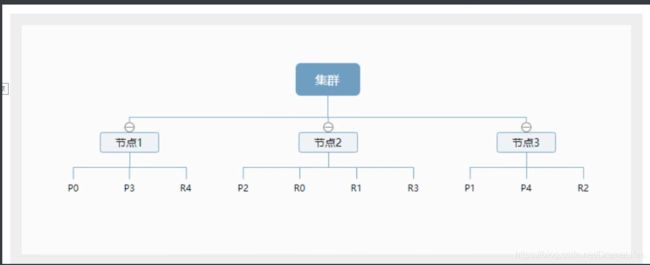
上图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉了,数据也不至于丢失。实际上,一个分片是一个Lucene索引,一个包含倒排索引的文件目录,倒排索引的结构使得elasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字。不过,等等,倒排索引是什么鬼?
倒排索引
elasticsearch使用的是一种称为倒排索引的结构,采用Lucene倒排索作为底层。这种结构适用于快速的全文搜索,一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表。例如,现在有两个文档,每个文档包含如下内容:
study every day,good good up to forever #文档1包含的内容
To forever,study every day,good good up #文档2包含的内容
为了创建倒排索引,我们首先要将每个文档拆分成独立的词(或称为词条或者tokens),然后创建一个包含所有不重复的词条的排序列表,然后列出每个词条出现在哪个文档:
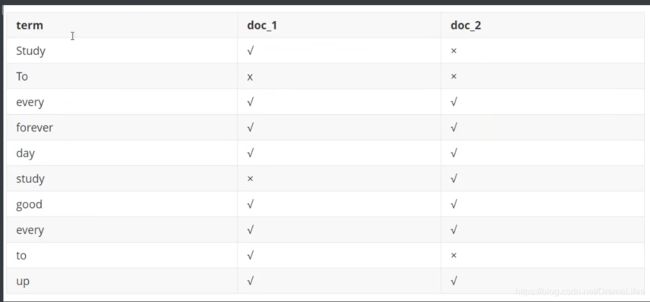
现在,我们试图搜索to forever,只需要查看包含每个词条的文档

两个文档都匹配,但是第一个文档比第二个匹配程度更高。如果没有别的条件,现在,这两个包含关键字的文档都将返回。再来看一个示例,比如我们通过博客标签来搜索博客文章。那么倒排索引列表就是这样的一个结构:
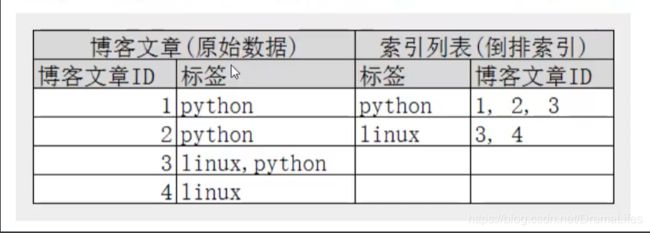
如果要搜索含有python标签的文章,那相对于查找所有原始数据而言,查找倒排索引后的数据将会快的多。只需要-查看标签这一栏,然后获取相关的文章ID即可。完全过滤掉无关的数据,提高效率!
elasticsearch的索引和Lucene的索引对比
在elasticsearch中,索引这个词被频繁使用,这就是术语的使用。在elasticsearch中,索引被分为多个分片,每份分片是一个Lucene的索引。所以一个elasticsearch索引是由多个Lucene索引组成的。别问为什么,谁让elasticsearch使用Lucene作为底层呢!如无特指,说起索引都是指elasticsearch的索引。
接下来的一切操作都在kibana中Dev Tools下的Console里完成。基础操作!
Rest风格说明
一种软件架构风格,而不是标准,只是提供了一组设计原则和约束条件。它主要用于客户端和服务器交互类的软件。基于这个风格
设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
基本Rest命令说明∶
| method | url地址 | 描述 |
|---|---|---|
| PUT | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档id ) |
| POST | localhost:9200/索引名称/类型名称 | 创建文档(随机文档id ) |
| POST | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档 |
| DELETE | localhost:9200/索引名称/类型名称/文档id | 删除文档 |
| GET | localhost:9200/索引名称/类型名称/文档id | 查询文档通过文档id |
| POST | localhost:9200/索引名称/类型名称/search | 查询所有数据 |
关于索引的基本操作
基础测试
- 创建一个索引
PUT /索引名/~类型名~/文档id
{请求体}
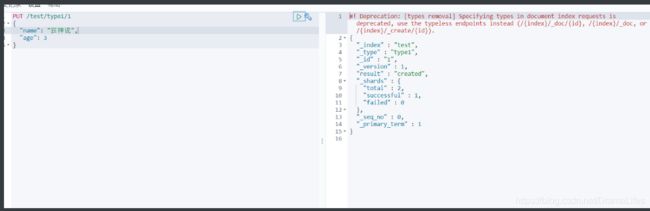
完成自动增加索引 数据也成功添加了
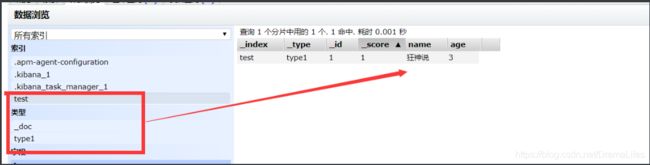
那么name 字段用不用指定类型呢。毕竟我们关系型数据库,是需要指定类型的啊
-
字符串类型
text、keyword
-
数值类型
long、integer、short、byte、double、float、half float、scaled float
-
日期类型
date
-
te布尔类型
boolean
-
二进制类型
binary
-
等等…
- 指定字段的类型
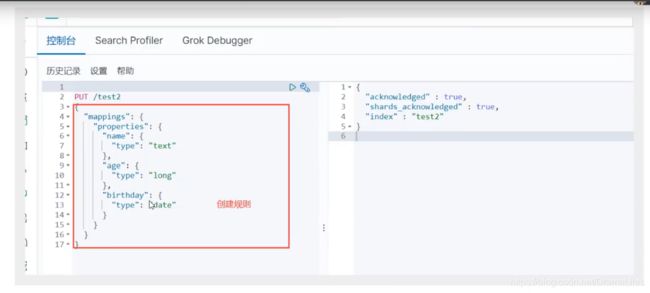
获得这个规则,可以通过 GET请求获取具体的信息
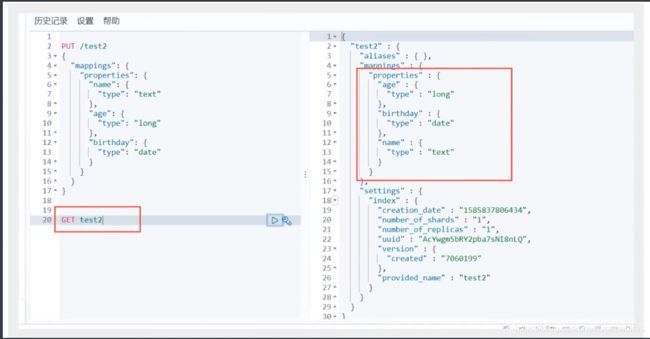
5. 查看默认的信息
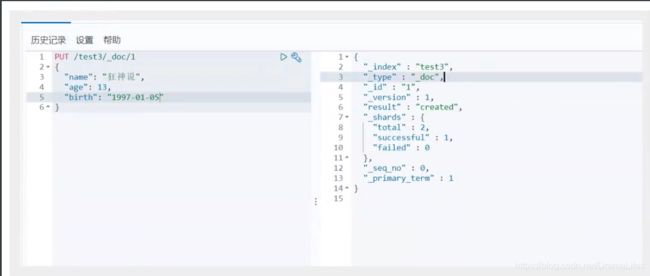
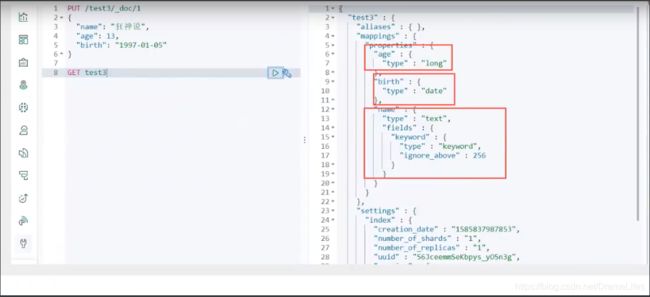
如果自己的文档字段没有指定,那么es就会给我们默认配置字段类型
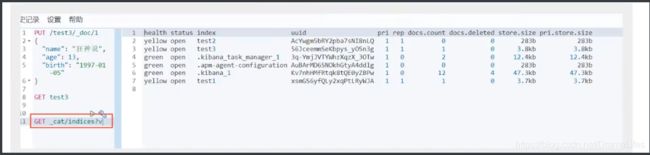
扩展: 通过命令 elasticsearch 索引情况!通过get _cat/ 可以获得es的当前的很多信息
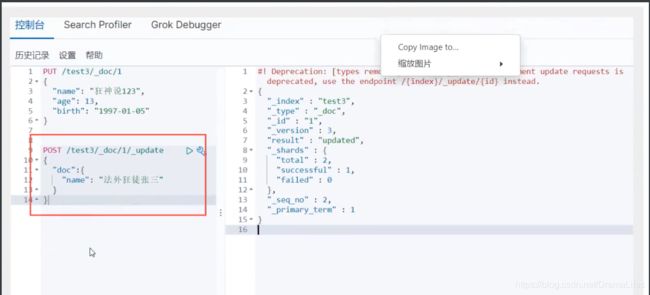
修改 提交还是使用PUT 即可 ! 然后覆盖 ! 最新办法
现在的方法
删除索引
通过DELETE命令实现删除,根据的请求来判断是删除索引还是删除文档记录
使用RESTFUL 分割使我们ES推荐给大家使用的

关于文档的基本操作(重点)
- 创建数据
PUT /kuangshen/user/1
{
"name" : "狂神说",
"age" : 23,
"desc" : "一顿操作猛如虎,一看工资2500",
"tags" : [
"技术宅","温暖","直男"
]
}
- 获取数据GET
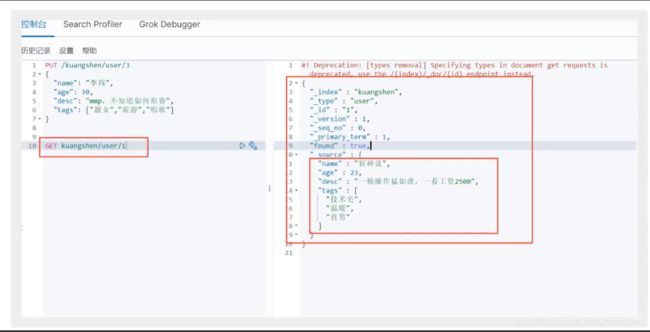
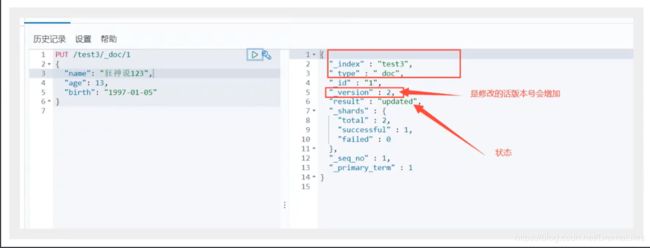
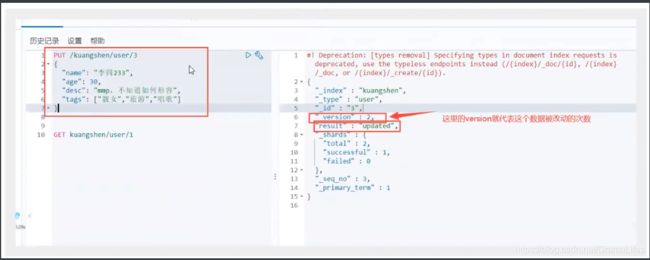
- 更新数据 PUT
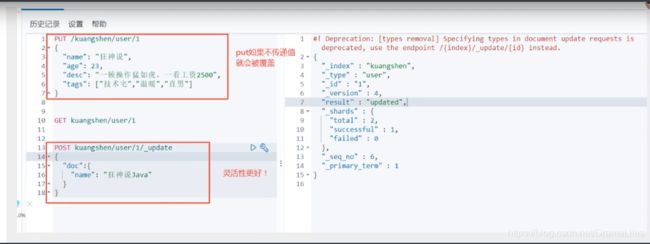
- Post _update,推荐视同这种更新方式
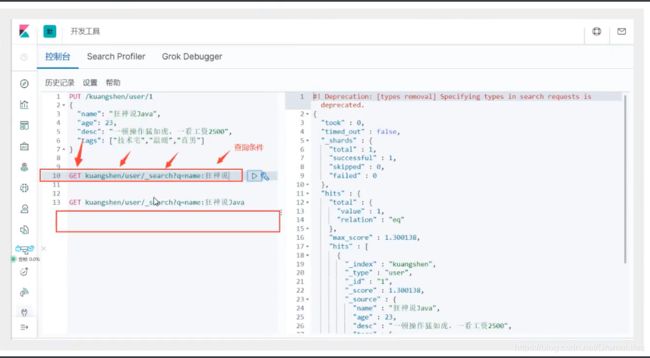
简单的搜索
GET kuangshen/user/1
简单的条件查询,可以根据默认的映射规则,产生基本的查询
复杂操作搜索(select(排序,分页,高亮,模糊查询,精准查询))
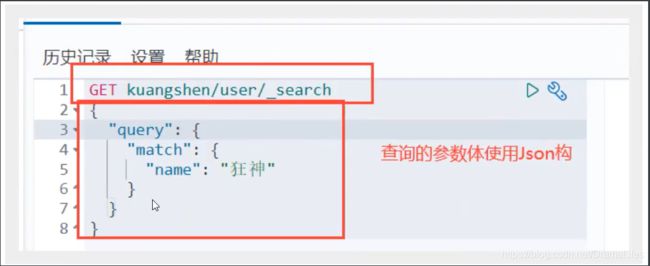
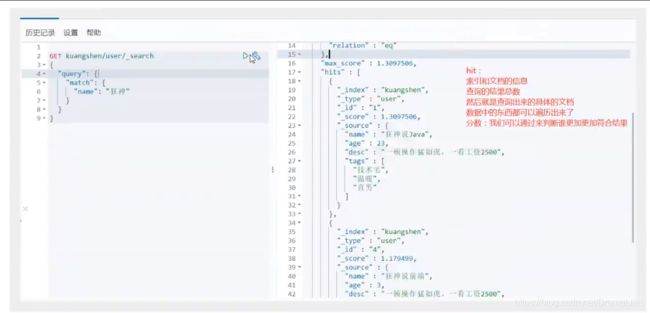
输出结果,不想要那么多,
我们之后使用java操作es,所有的方法和对象就是这里面的key
排序
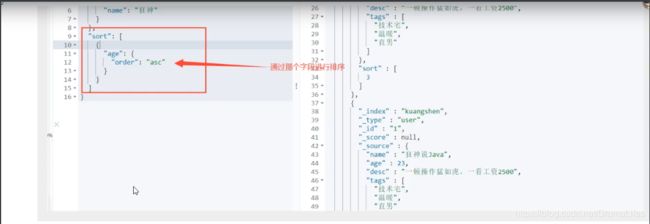
分页查询
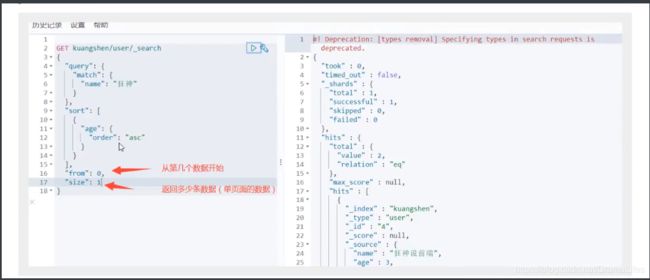
数据下标还是从0开始,和学的所有数据结构是一样的
/search/{current}/{pagesize}
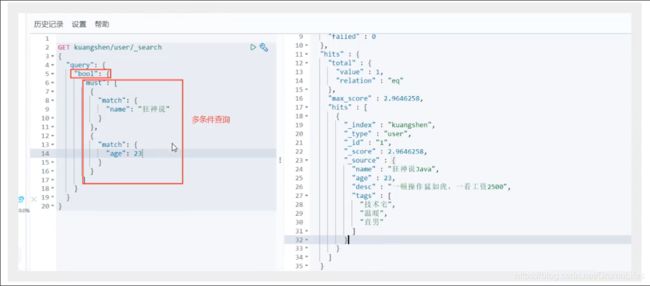
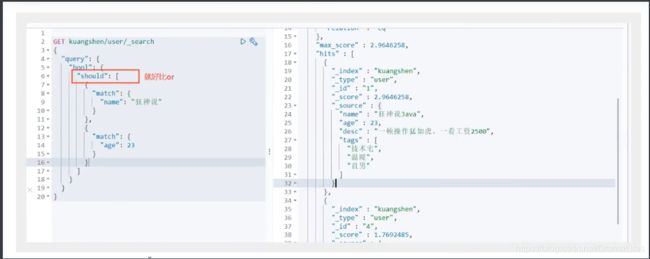
布尔值查询
must(and),所有的条件都要符合,where id = 1 and name = xxx
should(or),所有的条件都要符合,where id = 1 or name = xxx
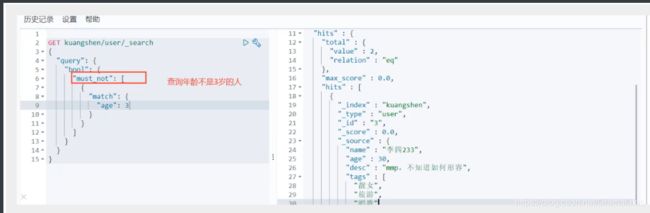
must_not(not)
过滤器
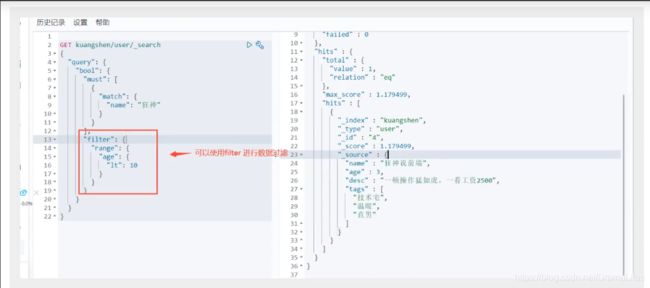
- gt 大于
- gte 大于等于
- lt 小于
- lte 小于等于
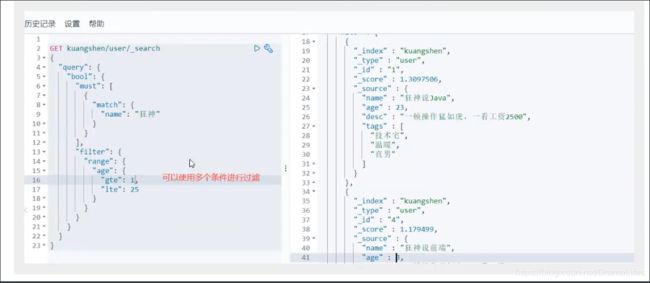
匹配多个条件
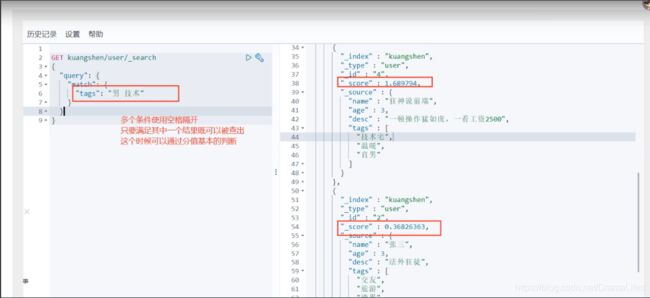
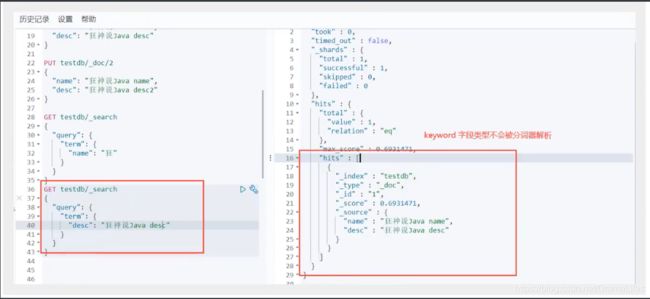
精确查询
term 查询是直接通过倒排索引指定的词条进行精确查找的
关于分词
- term 直接查询精确值
- match,会使用分词器解析! (先分析文档,然后在通过分析的文档进行查询)
两个类型 text keyword
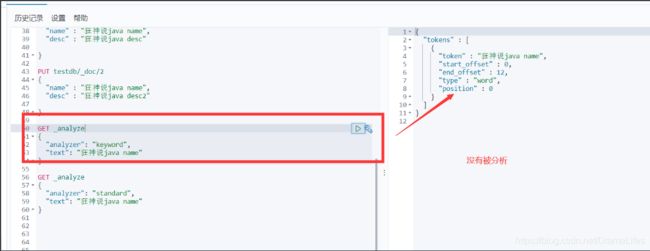
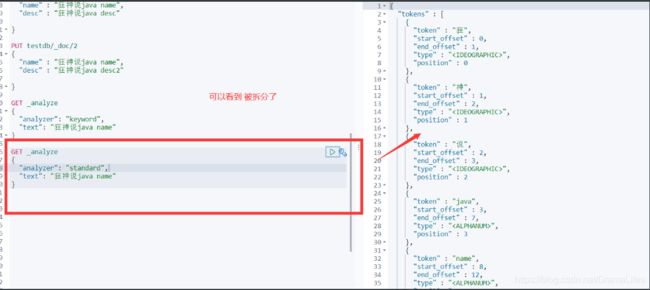
keyword字段类型不会被分词器解析
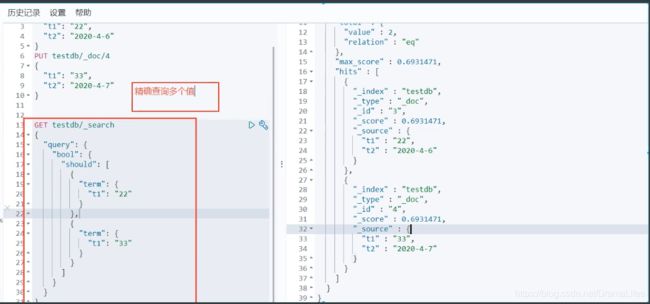
多个值匹配的精确查询
高亮查询
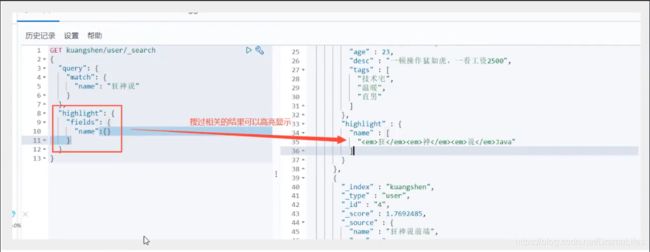
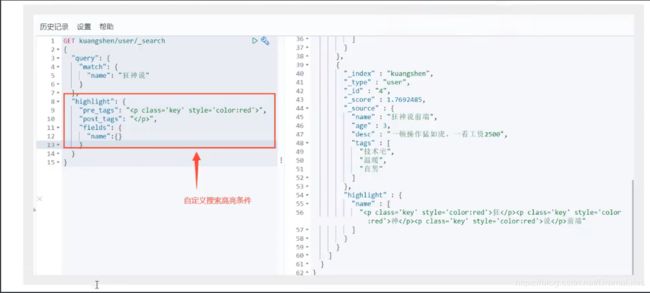
这些其实Mysql 也可以做 ,知识MySQL的效率较低
- 匹配
- 按照条件匹配
- 精确匹配
- 区间范围匹配
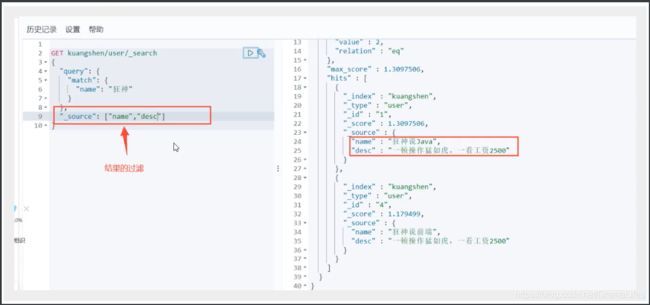
- 匹配字段过滤
- 多条件查询
- 高亮查询
集成SpringBoot
找官方文档
- 找到原生的依赖
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>elasticsearch-rest-high-level-clientartifactId>
<version>7.6.2version>
dependency>
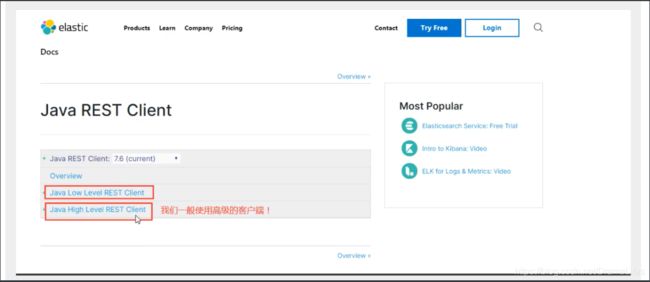
- 找对象
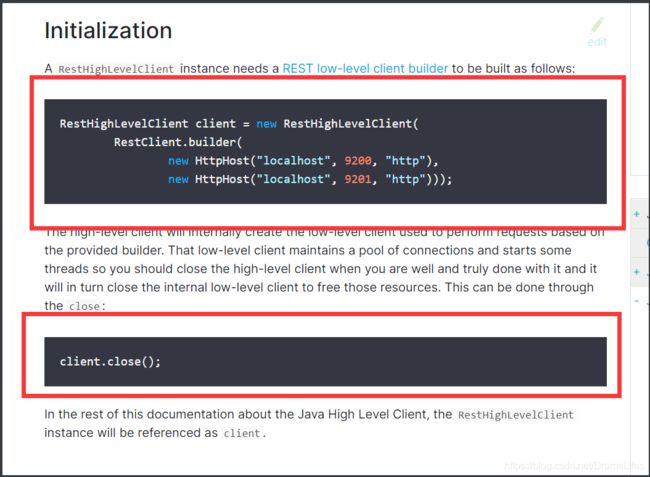
- 分析这个类中的方法
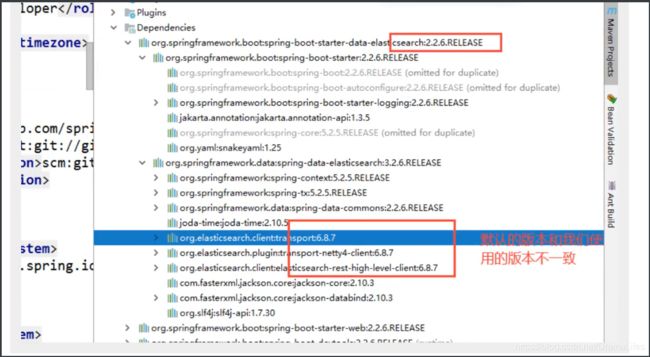
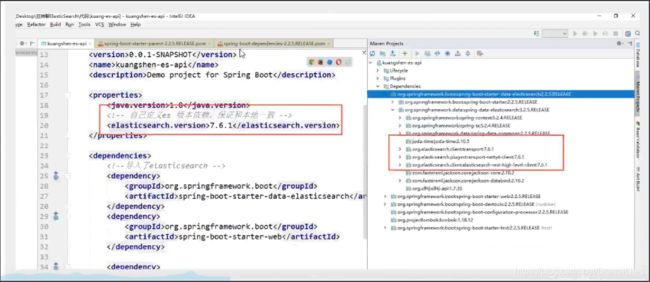
配置基本的项目
问题: 一定要保证我们导入的依赖和我们的es版本一致
源码中提供的对象
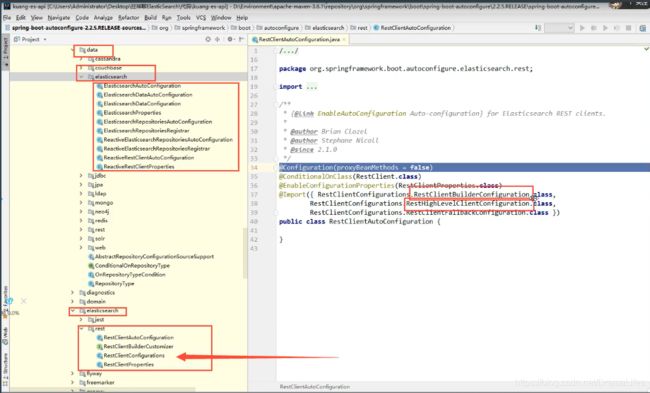
虽然这里导入3个类,静态内部类,核心类就是一个
/*
* Copyright 2012-2019 the original author or authors.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* https://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.springframework.boot.autoconfigure.elasticsearch.rest;
import java.time.Duration;
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.Credentials;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.ObjectProvider;
import org.springframework.boot.autoconfigure.condition.ConditionalOnClass;
import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean;
import org.springframework.boot.context.properties.PropertyMapper;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* Elasticsearch rest client infrastructure configurations.
*
* @author Brian Clozel
* @author Stephane Nicoll
*/
class RestClientConfigurations {
@Configuration(proxyBeanMethods = false)
static class RestClientBuilderConfiguration {
//RestClientBuilder
@Bean
@ConditionalOnMissingBean
RestClientBuilder elasticsearchRestClientBuilder(RestClientProperties properties,
ObjectProvider<RestClientBuilderCustomizer> builderCustomizers) {
HttpHost[] hosts = properties.getUris().stream().map(HttpHost::create).toArray(HttpHost[]::new);
RestClientBuilder builder = RestClient.builder(hosts);
PropertyMapper map = PropertyMapper.get();
map.from(properties::getUsername).whenHasText().to((username) -> {
CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
Credentials credentials = new UsernamePasswordCredentials(properties.getUsername(),
properties.getPassword());
credentialsProvider.setCredentials(AuthScope.ANY, credentials);
builder.setHttpClientConfigCallback(
(httpClientBuilder) -> httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider));
});
builder.setRequestConfigCallback((requestConfigBuilder) -> {
map.from(properties::getConnectionTimeout).whenNonNull().asInt(Duration::toMillis)
.to(requestConfigBuilder::setConnectTimeout);
map.from(properties::getReadTimeout).whenNonNull().asInt(Duration::toMillis)
.to(requestConfigBuilder::setSocketTimeout);
return requestConfigBuilder;
});
builderCustomizers.orderedStream().forEach((customizer) -> customizer.customize(builder));
return builder;
}
}
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass(RestHighLevelClient.class)
static class RestHighLevelClientConfiguration {
//RestHighLevelClient 高级客户端, 也是我们这里要讲,后面项目中会用到的高级客户端
@Bean
@ConditionalOnMissingBean
RestHighLevelClient elasticsearchRestHighLevelClient(RestClientBuilder restClientBuilder) {
return new RestHighLevelClient(restClientBuilder);
}
@Bean
@ConditionalOnMissingBean
RestClient elasticsearchRestClient(RestClientBuilder builder,
ObjectProvider<RestHighLevelClient> restHighLevelClient) {
RestHighLevelClient client = restHighLevelClient.getIfUnique();
if (client != null) {
return client.getLowLevelClient();
}
return builder.build();
}
}
@Configuration(proxyBeanMethods = false)
static class RestClientFallbackConfiguration {
//RestClient 普通的客户端
@Bean
@ConditionalOnMissingBean
RestClient elasticsearchRestClient(RestClientBuilder builder) {
return builder.build();
}
}
}
具体的api 测试
- 创建索引
//测试索引的创建 Request PUT kuang_index
@Test
void testCreateIndex() throws IOException {
//1. 创建索引请求
CreateIndexRequest request = new CreateIndexRequest("kuang_index");
//2. 客户端执行创建请求 IndicesClient 请求后获得响应
CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);
System.out.println(createIndexResponse);
}
- 判断索引是否存在
//测试获取索引 判断其是否存在
@Test
void testExists() throws IOException {
GetIndexRequest request = new GetIndexRequest("kuang_index");
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
- 删除索引
//测试删除索引
@Test
void testDeleteIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("kuang_index");
//删除
AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);
System.out.println(delete.isAcknowledged());
}
- 创建文档
//测试添加文档
@Test
void testAddDocument() throws IOException {
//创建对象
User user = new User("狂神说", 3);
//创建请求
IndexRequest request = new IndexRequest("kuang_index");
//规则 put /kuang_index/_doc/1
request.id("1");
request.timeout(TimeValue.timeValueSeconds(1));
request.timeout("1s");
//将我们的数据放入请求 json
request.source(JSON.toJSONString(user), XContentType.JSON);
//客户端发送请求,获取响应的结果
IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);
System.out.println(indexResponse.toString());
//对应我们命令返回的状态 CREATED
System.out.println(indexResponse.status());
}
- crud文档
//获取文档,判断是否存在
@Test
void testIsExists() throws IOException {
GetRequest request = new GetRequest("kuang_index", "1");
//不获取返回的 _source 的上下文了
request.fetchSourceContext(new FetchSourceContext(false));
request.storedFields("_none_");
boolean exists = client.exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
//获得文档的信息
@Test
void testGetDocument() throws IOException {
GetRequest request = new GetRequest("kuang_index", "1");
GetResponse response = client.get(request, RequestOptions.DEFAULT);
//打印文档的内容
System.out.println(response.getSourceAsString());
//返回的全部内容和命令是一样的
System.out.println(response);
}
//更新文档的信息
@Test
void testUpdateDocument() throws IOException {
UpdateRequest request = new UpdateRequest("kuang_index", "1");
request.timeout("1s");
User user = new User("狂神说Java", 18);
request.doc(JSON.toJSONString(user), XContentType.JSON);
UpdateResponse updateResponse = client.update(request, RequestOptions.DEFAULT);
System.out.println(updateResponse.status());
}
//删除文档的记录
@Test
void testdeleteDocument() throws IOException {
DeleteRequest request = new DeleteRequest("kuang_index", "1");
request.timeout("1s");
DeleteResponse deleteResponse = client.delete(request, RequestOptions.DEFAULT);
System.out.println(deleteResponse.status());
}
//特殊的,真实项目一般都会批量插入数据
@Test
void testBulkRequest() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("10s");
List<User> list = new ArrayList<>();
list.add(new User("kuangshen1", 3));
list.add(new User("kuangshen2", 3));
list.add(new User("kuangshen3", 3));
list.add(new User("qinjiang1", 3));
list.add(new User("qinjiang2", 3));
list.add(new User("qinjiang3", 3));
//批处理请求
for (int i = 0; i < list.size(); i++) {
// 批量更新和批量删除,就在这里修改对应请求就可以了
bulkRequest.add(new IndexRequest("kuang_index")
.id("" + (i + 1))
.source(JSON.toJSONString(list.get(i)), XContentType.JSON)
);
}
BulkResponse bulkResponse = client.bulk(bulkRequest, RequestOptions.DEFAULT);
//是否失败 ,返回 false 表示成功
System.out.println(bulkResponse.hasFailures());
}
//查询
//SearchRequest 搜索请求
//SearchSourceBuilder 条件构造
//HighlightBuilder 构建高亮
//TermQueryBuilder 精确查询
//MatchAllQueryBuilder
//xxx QueryBuilder 对应我们刚才看到的命令
@Test
void testSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest(ESconst.ES_INDEX);
//构建搜索的条件
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//查询条件,我们可以使用QueryBuilders工具类来实现
//QueryBuilders.termQuery 精确
//QueryBuilders.matchAllQuery() 匹配所有
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", "qinjiang1");
// MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
sourceBuilder.query(termQueryBuilder);
sourceBuilder.from();
sourceBuilder.size();
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(JSON.toJSONString(searchResponse.getHits()));
System.out.println("===================");
for (SearchHit searchHit : searchResponse.getHits().getHits()) {
System.out.println(searchHit.getSourceAsMap());
}
}
//查询
//SearchRequest 搜索请求
//SearchSourceBuilder 条件构造
//HighlightBuilder 构建高亮
//TermQueryBuilder 精确查询
//MatchAllQueryBuilder
//xxx QueryBuilder 对应我们刚才看到的命令
@Test
void testSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest(ESconst.ES_INDEX);
//构建搜索的条件
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//查询条件,我们可以使用QueryBuilders工具类来实现
//QueryBuilders.termQuery 精确
//QueryBuilders.matchAllQuery() 匹配所有
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", "qinjiang1");
// MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
sourceBuilder.query(termQueryBuilder);
sourceBuilder.from();
sourceBuilder.size();
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(JSON.toJSONString(searchResponse.getHits()));
System.out.println("===================");
for (SearchHit searchHit : searchResponse.getHits().getHits()) {
System.out.println(searchHit.getSourceAsMap());
}
}
大家有好的想法和思路欢迎和博主一起探讨,欢迎大家指出博主有不足的地方,欢迎评论,点赞,收藏!
我们大家共同进步!
博主的github 中整理了相关的JDK1.8的源码浅析
JDK 1.8源码浅析
以及博主所刷过的算法的解析,有兴趣可以去踩踩。
算法解析
另外附上博主的 github链接,还有一个人脸识别项目可供借鉴
人脸识别项目