⭐openGauss数据库源码解析系列文章—— AI查询时间预测⭐
上一篇介绍了“8.5 指标采集、预测与异常检测”的相关内容,本篇我们介绍“8.6 AI查询时间预测”的相关精彩内容介绍。
8.6 AI查询时间预测
在前面介绍过“慢SQL发现”特性,该特性的典型场景是新业务上线前的检查,输入源是提前采集到的SQL流水数据。慢SQL发现功能主要主要应用在多条SQL语句的批量检查上,要求之前执行过SQL语句,因此给出的结果主要是定性的,在某些场景下可能难以满足用户对于评估精度的要求。
因此,为了弥补上述场景的不足,满足用户更精确的SQL时间预测需求,同时为AI优化器做铺垫,实现了本章所述的功能。
由于实际业务场景具有复杂的特质,现有的数据库静态代价估计模型往往统计结果失准,从而选择了一些执行计划较差的路径。因此,针对上述复杂场景,需要数据库的代价估计模型具备自我更新的能力。本特性主要功能为基于查询语句的历史数据,对当前执行的SQL语句进行查询耗时和基数的估算。
8.6.1 使用场景
AI查询分析的前提是需要获取执行计划。首先需要根据用户需求在查询执行时收集复杂查询实际查询计划(包括计划结构、算子类型、相关数据源、过滤条件等)、各算子节点实际执行时间、优化器估算代价、实际返回行数、优化器估算行数、SMP并发线程数、等信息。将其记录在数据表中,并进行持久化管理包括定期进行数据失效清理。
本功能主要分为两个方面,一个是行数估算,一个是查询预测,前者是后者预测好坏的前提。目前openGauss基于在线学习对执行计划各层的结果集大小进行估算,仅起到展示作用,并未影响到执行计划的生成。后续可帮助优化器更准确地进行结果集估算,从而获取更优的执行计划。
当前阶段本需求会提供系统函数来进行预测,并加入到explain中进行实际比较验证。
8.6.2 现有技术
当前学术界在AI4DB领域,对基于机器学习的行数估算和查询时延预测有许多尝试。
1. 传统方法
正如数据库优化器专家Guy Lohman在博客Is query optimization a “solved” problem中所说,传统数据库查询性能预测的“阿喀琉斯之踵”便是中间结果集大小的估算。对于行数估算传统基于统计信息行数估算方法主要基于三类假设。
(1) 数据独立分布假设。
(2) 均匀分布假设。
(3) 主外键假设。
而实际场景中数据往往存在一定的相关性和倾斜性,此时上述假设可能会被打破,导致传统数据库优化器在多表连接中间结果集大小估算中可能会存在数个数量级的误差。
2000年以来,以基于采样的估算、基于采样的核密度函数估算、基于多列直方图为代表的统计学方法被提出,用于解决数据相关性带来的估算问题。然而这些方法都存在一个共性问题,就是模型无法进行增量维护,而收集这些额外的统计信息会增加巨大的数据库维护开销,虽然在一些特定的问题场景(如多列Range条件选择率)取得了很大的准确率提升,但并没有被各大数据库厂商广泛采用。
传统性能预测方法主要依赖代价模型,在以下几个方面存在明显劣势。
(1) 准确性:随着底层硬件架构和优化技术不断演进,实际性能预测模型的复杂度远不可以用线性模型来建模。
(2) 可扩展性:代价模型的开发成本较高,不能面面俱到地对用户具体场景进行优化。
(3) 可校准性:代价模型灵活性仅局限于各资源维度线性相加时使用的系数,以及部分惩罚代价,灵活性较差,用户实际使用时难以校准。
(4) 时效性:代价模型依赖统计信息的收集和使用,目前缺乏增量维护方法,导致数据流动性较大的场景下统计信息长期处于失效状态。
2. 机器学习方法
机器学习模型在模型复杂度、可校准性、可增量维护性几个维度的优势能够弥补传统优化器代价模型的不足,基于机器学习的查询性能预测逐渐成为数据库学术界和产业界的主流研究方向之一。
除前文8.3节慢SQL发现部分介绍过相关方法外,清华大学的Learned Cost Estimator模型基于Multi-task Learning和字符条件的Word-Embedding方法进一步提升了预测准确率。
至此,机器学习方法虽然从实验效果上看达到了较高的准确率,但现实业务场景持续性的数据分布变化对模型的在线学习能力提出了要求。openGauss采用了数据驱动的在线学习模式,通过内核不断收集历史作业性能信息,并在AI Engine侧使用了R-LSTM(recursive long short term memory,递归长短期记忆网络)模型对算子级查询时延和中间结果集大小进行预测。
8.6.3 实现原理

总体而言,查询性能预测由数据库内核侧和AI Engine侧两个部分组成,如图8-15所示。
(1) 数据库内核侧除提供数据库基本功能外还需要对历史数据进行收集和持久化管理,并通过curl向AI Engine侧发送HTTPS请求。
(2) AI Engine提供模型训练、执行预测、模型管理等接口,基于Flask框架的服务端接受HTTPS请求,该流程如图8-16所示。
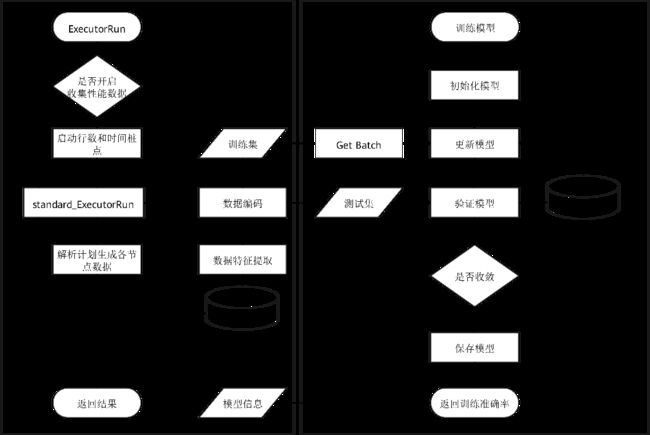
开启数据收集相关参数后(其对性能可能有5%左右的影响,取决于实际业务负载情况),历史性能数据被持久化收集在数据库的系统表中,用于模型的训练。
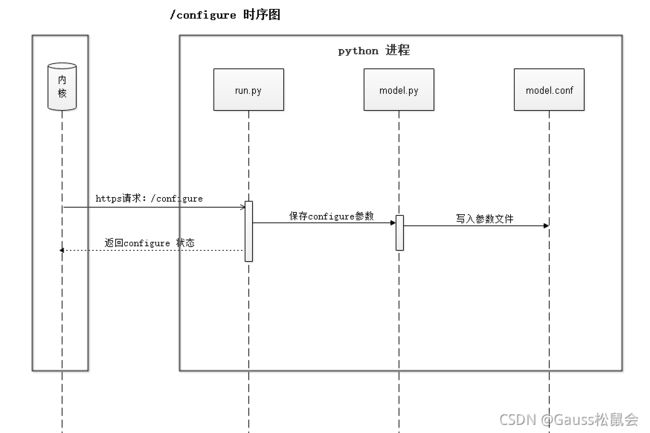
模型训练之前,用户需要对模型参数进行配置(详见8.6.5使用示例)。用户训练指令下发之后,内核进程会向AI Engine侧发送configure请求,用于初始化机器学习模型。configure流程时序如图8-17所示。
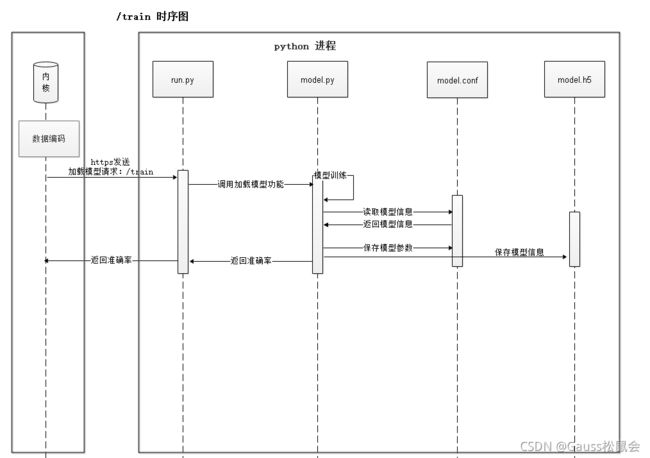
模型配置成功后,内核进程向AI Engine侧发送train请求,触发训练,该流程如图8-18所示。
![]()
![]()
其中,Хt是当前时序模块的输入,ht﹣₁是当前时序模块的输入,是前一个时序的输出信息,使用sigmoid(σ)函数得到当前细胞状态中将要输出的部分Οt;Ct表示所有历史时序保留的信息,通过tanh函数处理后与当前状态输出信息Οt相乘得到此状态的输出ht,将具有三个元素的一维向量 [startup time, total time, cardinality] 的预测结果同真实数据进行比较,使用ratio-error计算模型的损失函数。

8.6.4 关键源码解析
1. 项目结构
AI Engine侧涉及的主要文件路径为openGauss-server/src/gausskernel/dbmind/tools/predictor,其文件结构如表8-13所示。
文件结构 |
说明 |
install |
部署所需文件路径 |
install/ca_ext.txt |
证书配置文件 |
install/requirements-gpu.txt |
使用GPU(graphics processing unit,图形处理器)训练依赖库列表 |
install/requirements.txt |
使用CPU训练依赖库列表 |
install/ssl.sh |
证书生成脚本 |
python |
项目代码路径 |
python/certs.py |
加密通信 |
python/e_log |
系统日志路径 |
python/log |
模型训练日志路径 |
python/log.conf |
配置文件 |
python/model.py |
机器学习模型 |
python/run.py |
服务端主函数 |
python/saved_models |
模型训练checkpoint |
python/settings.py |
工程配置文件 |
python/uploads |
Curl传输的文件存放路径 |
内核侧主要涉及的文件路径为openGauss-server/src/gausskernel/optimizer/util/learn,其文件结构如表8-14所示。
文件结构 |
说明 |
comm.cpp |
通信层代码实现 |
encoding.cpp |
数据编码 |
ml_model.cpp |
通用模型调用接口 |
plan_tree_model.cpp |
树状模型调用接口 |
2. 训练流程
内核侧的模型训练接口通过ModelTrainInternal函数实现,该函数的关键部分如下:
static void ModelTrainInternal(const char* templateName, const char* modelName, ModelAccuracy** mAcc)
{
…
/* 对于树形模型调用对应的训练接口 */
char* trainResultJson = TreeModelTrain(modelinfo, labels);
/* 解析返回结果 */
…
ModelTrainInfo* info = GetModelTrainInfo(jsonObj);
cJSON_Delete(jsonObj);
/* 更新模型信息 */
Relation modelRel = heap_open(OptModelRelationId, RowExclusiveLock);
…
UpdateTrainRes(values, datumsMax, datumsAcc, nLabel, mAcc, info, labels);
HeapTuple modelTuple = SearchSysCache1(OPTMODEL, CStringGetDatum(modelName));
…
HeapTuple newTuple = heap_modify_tuple(modelTuple, RelationGetDescr(modelRel), values, nulls, replaces);
simple_heap_update(modelRel, &newTuple->t_self, newTuple);
CatalogUpdateIndexes(modelRel, newTuple);
…
}
内核侧的树状模型训练接口通过TreeModelTrain函数实现,核心代码如下:
char* TreeModelTrain(Form_gs_opt_model modelinfo, char* labels)
{
char* filename = (char*)palloc0(sizeof(char) * MAX_LEN_TEXT);
char* buf = NULL;
/* configure阶段 */
ConfigureModel(modelinfo, labels, &filename);
/* 将编码好的数据写入临时文件 */
SaveDataToFile(filename);
/* Train阶段 */
buf = TrainModel(modelinfo, filename);
return buf;
}
AI Engine侧配置的Web服务的URI是/configure,训练阶段的URI是/train.下面的代码段展示了训练过程。
def fit(self, filename):
keras.backend.clear_session()
set_session(self.session)
with self.graph.as_default():
# 根据模型入参和出参维度变化情况,判断是否需要初始化模型
feature, label, need_init = self.parse(filename)
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
epsilon = self.model_info.make_epsilon()
if need_init: # 冷启动训练
epoch_start = 0
self.model = self._build_model(epsilon)
else: # 增量训练
epoch_start = int(self.model_info.last_epoch)
ratio_error = ratio_error_loss_wrapper(epsilon)
ratio_acc_2 = ratio_error_acc_wrapper(epsilon, 2)
self.model = load_model(self.model_info.model_path,
custom_objects={'ratio_error': ratio_error, 'ratio_acc': ratio_acc_2})
self.model_info.last_epoch = int(self.model_info.max_epoch) + epoch_start
self.model_info.dump_dict()
log_path = os.path.join(settings.PATH_LOG, self.model_info.model_name + '_log.json')
if not os.path.exists(log_path):
os.mknod(log_path, mode=0o600)
# 训练日志记录回调函数
json_logging_callback = LossHistory(log_path, self.model_info.model_name, self.model_info.last_epoch)
# 数据分割
X_train, X_val, y_train, y_val = \
train_test_split(feature, label, test_size=0.1)
# 模型训练
self.model.fit(X_train, y_train, epochs=self.model_info.last_epoch,
batch_size=int(self.model_info.batch_size), validation_data=(X_val, y_val),
verbose=0, initial_epoch=epoch_start, callbacks=[json_logging_callback])
# 记录模型checkpoint
self.model.save(self.model_info.model_path)
val_pred = self.model.predict(X_val)
val_re = get_ratio_errors_general(val_pred, y_val, epsilon)
self.model_logger.debug(val_re)
del self.model
return val_re
3. 预测流程
内核侧的模型预测过程主要通过ModelPredictInternal函数实现。树状模型预测过程通过TreeModelPredict函数实现。内核侧的树状模型预测过程会占用一些与AI Engine进行通信的信令,该通信过程如下:
char* TreeModelPredict(const char* modelName, char* filepath, const char* ip, int port)
{
…
if (!TryConnectRemoteServer(conninfo, &buf)) {
DestroyConnInfo(conninfo);
ParseResBuf(buf, filepath, "AI engine connection failed.");
return buf;
}
switch (buf[0]) {
case '0': {
ereport(NOTICE, (errmodule(MOD_OPT_AI), errmsg("Model setup successfully.")));
break;
}
case 'M': {
ParseResBuf(buf, filepath, "Internal error: missing compulsory key.");
break;
}
…
}
/* Predict阶段 */
…
if (!TryConnectRemoteServer(conninfo, &buf)) {
ParseResBuf(buf, filepath, "AI engine connection failed.");
return buf;
}
switch (buf[0]) {
case 'M': {
ParseResBuf(buf, filepath, "Internal error: fail to load the file to predict.");
break;
}
case 'S': {
ParseResBuf(buf, filepath, "Internal error: session is not loaded, model setup required.");
break;
}
default: {
break;
}
}
return buf;
}
AI Engine侧的Setup过程的Web接口是/model_setup,预测阶段的Web接口是/predict,他们的协议都是Post。
4. 数据编码
数据编码分为以下两个维度。
(1) 算子维度:包括每个执行计划算子的属性,如表8-15所示。
属性名 |
含义 |
编码策略 |
Optname |
算子类型 |
One-hot |
Orientation |
返回元组存储格式 |
One-hot |
Strategy |
逻辑属性 |
One-hot |
Options |
物理属性 |
One-hot |
Quals |
谓词 |
hash |
Projection |
返回投影列 |
hash |
(2) 计划维度。
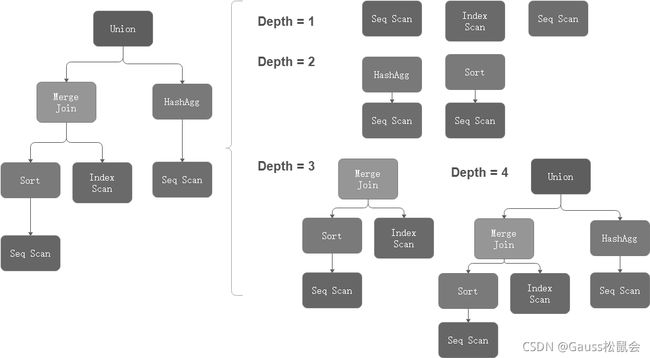
对于每个算子,在其固有属性之外,openGauss还对query id,plan node id和parent node id进行了记录,在训练/预测阶段,使用这些信息将算子信息重建为树状计划结构,且可以递归构建子计划树来进行数据增强,从而提升模型泛化能力。树状数据结构如图8-21所示。
5. 模型结构
AI Engine的模型解析、训练和预测见8.6.4章节,下面的代码展示了模型的结构。
class RnnModel():
def _build_model(self, epsilon):
model = Sequential()
model.add(LSTM(units=int(self.model_info.hidden_units), return_sequences=True, input_shape=(None, int(self.model_info.feature_length))))
model.add(LSTM(units=int(self.model_info.hidden_units), return_sequences=False))
model.add(Dense(units=int(self.model_info.hidden_units), activation='relu'))
model.add(Dense(units=int(self.model_info.hidden_units), activation='relu'))
model.add(Dense(units=int(self.model_info.label_length), activation='sigmoid'))
optimizer = keras.optimizers.Adadelta(lr=float(self.model_info.learning_rate), rho=0.95)
ratio_error = ratio_error_loss_wrapper(epsilon)
ratio_acc_2 = ratio_error_acc_wrapper(epsilon, 2)
model.compile(loss=ratio_error, metrics=[ratio_acc_2], optimizer=optimizer)
return model
AI Engine的损失函数使用ratio error(部分文献中使用qerror代称),该损失函数相较于MRE和MSE的优势在于其能够等价地惩罚高估和低估两种情况,公式为:
![]()
ε声明为性能预测值的无穷小值,防止分母为0的情况发生。
8.6.5 使用示例
AI查询时间预测功能使用示例如下。
① 定义性能预测模型,代码如下:
INSERT INTO gs_opt_model VALUES(‘rlstm’, ‘model_name’, ‘host_ip’, ‘port’);
② 通过GUC参数开启数据收集,配置的参数列表,代码如下:
enable_resource_track = on;
enable_resource_record = on;
③ 编码训练数据,代码如下:
SELECT gather_encoding_info('db_name');
④ 校准模型,代码如下:
SELECT model_train_opt('template_name', 'model_name');
⑤ 监控训练状态,代码如下:
SELECT track_train_process('host_ip', 'port');
⑥ 通过explain + SQL语句来预测SQL查询的性能,代码如下:
EXPLAIN (..., predictor 'model_name') SELECT ...
获得结果,其中,“p-time”列为标签预测值。
Row Adapter (cost=110481.35..110481.35 rows=100 p-time=99..182 width=100) (actual time=375.158..375.160 rows=2 loops=1)
8.6.6 演进路线
目前模型的泛化能力不足,依赖外置的AI Engine组件,且深度学习网络比较重,这会为部署造成困难;模型需要数据进行训练,冷启动阶段的衔接不够顺畅,后续从以下几个方面演进。
(1) 加入不同复杂度模型,并支持多模型融合分析,提供更健壮的模型预测结果和置信度。
(2) AI Engine考虑加入任务队列,目前仅支持单并发预测/训练,可以考虑建立多个服务端进行并发业务。
(3) 基于在线学习/迁移学习的增强,考虑对损失函数加入锚定惩罚代价来避免灾难遗忘问题,同时优化数据管理模式,考虑data score机制,根据数据时效性赋权。
(4) 将本功能与优化器深度结合,探索基于AI的路径选择方法。
感谢大家学习第8章 AI技术中“8.6 AI查询时间预测”的精彩内容,下一篇我们开启“8.7 DeepSQL”的相关内容的介绍。
敬请期待。