模型部署的开源机器学习工具 MLflow | 每日工具推荐
今天要介绍的工具是 MLflow,该工具可分为 4 个模块,第一个是 MLflow Tracking,用于记录和查询实验结果,包含代码、数据、配置等,第二个是 MLflow Projects,用于打包代码以实现在任意平台上的重复运行,第三个是 MLflow Models,用于在各种各样的环境下部署机器学习模型,第四个是 Model Registry,用于存储、标记、探索、管理模型。
本篇文章不可能介绍完所有模块,所以大家就稍微简单看看吧,我写了什么就看什么吧。
首先我们来运行下面代码,简单体验下 Tracking API 的一些用法:
import os
from random import random, randint
from mlflow import log_metric, log_param, log_artifacts
if __name__ == "__main__":
# Log a parameter (key-value pair)
log_param("param1", randint(0, 100))
# Log a metric; metrics can be updated throughout the run
log_metric("foo", random())
log_metric("foo", random() + 1)
log_metric("foo", random() + 2)
# Log an artifact (output file)
if not os.path.exists("outputs"):
os.makedirs("outputs")
with open("outputs/test.txt", "w") as f:
f.write("hello world!")
log_artifacts("outputs")
下面的界面是运行 mlflow ui 之后,在浏览器输入: http://127.0.0.1:5000 之后展示的结果:

我们可以点击框出来的实验,进一步探查详细信息:
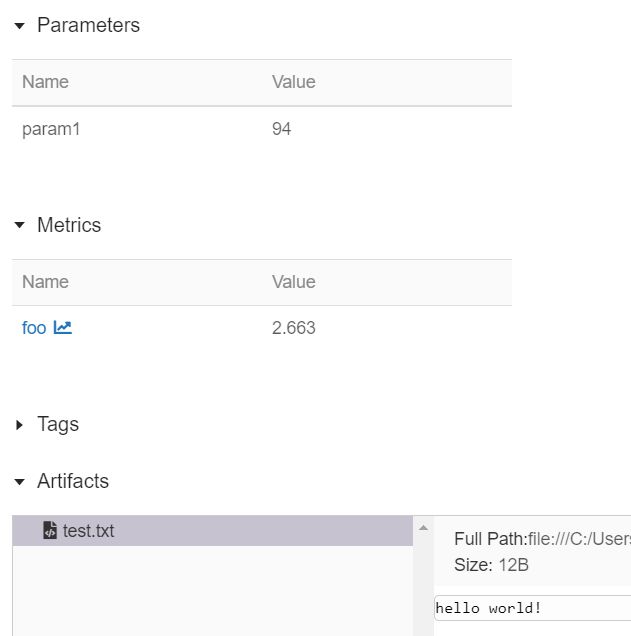
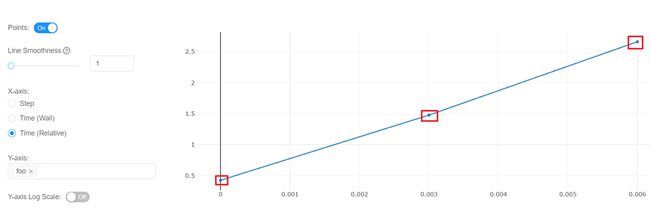
点击 foo 这个变量,我们可以看到如下所示的 3 个点,其实就是该变量的 3 次记录结果图:
接下来我们可以运行如下指令,体验一下 MLflow Projects:
mlflow run https://github.com/mlflow/mlflow-example.git -P alpha=5.0
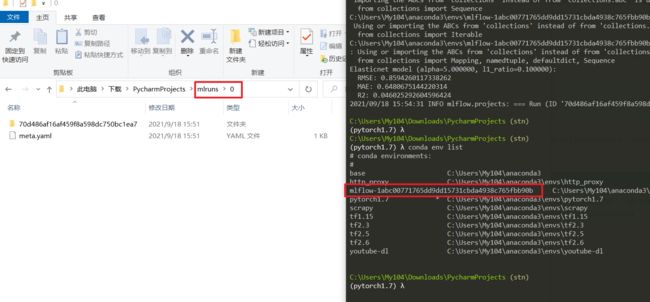
从下面的结果图可以发现,在运行的当前路劲下,保存了 mlruns,以及从终端可以发现,新创建了一个 conda env。
可以通过运行 mlflow ui 来查看上述的模型执行结果,下面的展示结果蛮有意思的,我就放上来了:

到这里为止,还差一个 Saving and Serving Models 没写。
首先我们需要克隆 mlflow 仓库:
git clone https://github.com/mlflow/mlflow
接下来进入 examples 目录里,执行如下指令:
python sklearn_logistic_regression/train.py
训练完之后,会保存模型,接下来可以执行如下指令,把模型进行 serving:
mlflow models serve -m runs:/1f211bb7aa67454882e017391126e6de/model
其中的 1f211bb7aa67454882e017391126e6de 是 RUN_ID,也就是下图框出来的地方。

最后一步就是预测了,执行如下指令:
curl -d '{"columns":["x"], "data":[[1], [-1]]}' -H 'Content-Type: application/json; format=pandas-split' -X POST localhost:5000/invocations
输出结果图,如下所示:
![]()
这里有个坑,我在 Windows 上执行 curl 进行预测会报错,但是 Linux 上就没问题,可能是我哪里设置不对了?先放着吧,反正平时搞代码都是 Linux。