图神经网络:方法与应用 | 一文展望,四大待解问题

在 AI Open 杂志 2020 年第一卷中,清华大学周杰等人发表了综述性论文《Graph neural networks: A review of methods and applications》,其他作者还包括知名学者孙茂松、刘知远等。
作者对现有的图神经网络模型进行了细致的总结,归纳出了设计 GNN 模型的一般流程,对其中各个组件的变体展开了讨论,系统地对 GNN 的应用进行了分类整理,并提出了 4 个有待解决的研究问题。本文对这篇论文做简略介绍。
撰文:熊宇轩
编校:贾 伟

论文链接:https://baai.org/l/ip7hD
文章目录
一、GNN是怎样诞生的?
二、GNN的设计流程
1、提取图结构
2、图的类别与规模
3、设计损失函数
4、使用计算模块构建图模型
5、计算模型举例
传播模块——卷积操作
-
谱域方法
基本的空域方法
基于注意力的空域方法
空域方法的通用框架
传播模块——循环操作
传播模块——跳跃连接
采样模块
池化模块
三、将GNN用于各种类别与guIMO的图
1、有向图
2、异构图
3、多重图
4、动态图
四、图神经网络的各种训练情况
1、图自编码机
2、对比学习
五、应用场景
六、未来的研究方向

图是一种在各种学习任务中广为使用的非欧数据结构,它包含元素之间丰富的关系信息。图学习重点关注节点分类、链接预测、聚类等任务。
具体而言,研究人员将图学习技术用于对物理系统建模、学习分子特征、预测蛋白质接口、疾病分类等场景。
当我们针对文本和图像等非结构化数据进行学习时,在提取出的结构(例如句子的依赖树和图像中的场景图)进行推理是十分重要的,这就要求我们构建图推理模型。图神经网络(GNN)通过图的节点之间的消息传递来获取图中的依赖关系。
近年来,图卷积网络(GCN)、图注意力网络(GAT)、图循环网络(GRN)等 GNN 的变体在许多深度学习任务上展示出了性能上的突破。
01
GNN是怎么诞生的?
GNN 的研究动机可以追溯到上世纪 90 年代的循环神经网络,此类方法的主要思想是在图上构建状态转移系统,迭代至收敛。尽管它们在诸多任务上取得了成功,但是这种工作机制限制了网络的可扩展性和表征能力。
以卷积神经网络(CNN)为代表的深度神经网络近年来的发展启发了 GNN 的研究人员。CNN 可以提取多尺度的局部空间特征,使用它们构建更好的表征。CNN 成功的关键之处在于局部连接、权值共享以及对多层网络的使用。这种思路对于解决图上的问题也十分重要。
然而,CNN 只能作用于常规的欧氏数据(例如,图像、文本),而这些数据也可以被构建为图的形式。因此,研究人员试图将 CNN 拓展到图领域。
如图 1 所示,我们很难定义局部的卷积滤波器和池化操作,从而难以将 CNN 从欧几里得域迁移到非欧的域中。将深度神经模型扩展到非欧域中的工作被称为几何深度学习,这一研究领域近年来得到了极大的关注。

图 1:欧氏空间中的图像(左)非欧空间中的图(右)
另一方面,图表征学习的发展也促进了人们对图神经网络的研究。
图表征学习旨在学习通过低维向量表征图的节点、边、子图。在图分析领域中,传统的机器学习方法往往依赖于手工设计的特征,这些方法灵活度较低且计算开销较大。
DeepWalk 是第一个基于表示学习的图嵌入方法,借鉴了表示学习的思想和词嵌入技术的成功之处,将 SkipGram 模型应用于生成的随机游走上。此后,node2vec、LINE、TADW 等类似的方法也取得了一定的突破。
然而,这些方法存在两个非常严重的缺点:(1)在编码器中,节点之间并不共享参数,参数量随着节点数的增长而线性增长,使得计算效率低下;(2)直接的嵌入方法缺乏泛化能力,无法处理动态图,无法泛化到新的图上。
在 CNN 和图嵌入的基础上,研究人员提出了各种 GNN,从图结构中聚合信息。GNN 可以对由元素及其自建的依赖组成的输入和输出建模。
02
GNN设计流程
针对特定的图上的任务,图模型的一般设计流程如下:(1)提取图结构(2)指定图的类别和规模(3)设计损失函数(4)使用计算模块构建模型。具体使用到的符号如表 1 所示:
表 1:构造图模型的相关数学符号一览表

1、提取图结构
首先,我们需要提取出具体应用中的图结构。我们将这些应用分为结构化场景和非结构化场景。
在结构化场景下,图结构显式地存在于分子、物理系统、知识图谱等应用中。
在非结构化场景下,图结构是隐式的,我们首先需要针对具体任务构图(例如,文本中单词的全连接图,图像的场景图)。
当我们得到图结构后,接下来就需要为其设计最优的 GNN 模型。
2、图的类别与规模
在得到图结构后,为了设计最优的 GNN 模型,我们需要考虑图的类型和规模。我们可以按照以下正交的标准对图进行分类,我们也可以将这些分类方法组合起来使用:
有向图/无向图:有向图中的边从某一个节点指向另一个节点,它能比无向图提供更多的信息。无向图中的边也可以被视为双向边。
同构图/异构图:同构图中的节点和边的类型都相同,而异构图中的节点和边则具有多种类型。
静态图/动态图:动态图的输入特征或拓扑结构会随时间变化,此时需要考虑时间信息。
就图的规模而言,目前并没有明确的将图分为「小型图」和「大型图」的标准,随着计算设备的发展,这一分类标准也将不断改变。我们通常认为,如果图的邻接矩阵或拉普拉斯矩阵无法在设备上存储、处理,则该图为大规模图,此时我们需要考虑使用某些采样方法。
3、设计损失函数
与大多数机器学习场景一样,在图学习场景下,我们需要根据任务类型和训练情况涉及损失函数。我们通常需要考虑三类图学习任务:
节点级别:此类任务包括节点的分类、回归、聚类等。
边级别:此类任务包括边分类和链接预测。边分类旨在确定图中存在的边的类别;链接预测旨在判断图中某两个节点之间是否存在一条边。
图级别:此类任务包括图的分类、回归、匹配等任务,它们要求模型学习图的表征。
从监督信号的角度而言,图学习任务涉及以下三种训练设定:
监督学习:训练使用有标签数据。
半监督学习:训练使用少量的有标签节点数据和大量的无标签节点数据。在测试时,转导学习要求模型预测出给定的已见过的无标签节点的标签,而归纳学习则要求模型预测出来自相同分布的无标签节点的标签。大多数节点和边的分类都是半监督学习任务。
无监督学习:模型只能利用无标签数据提取模式(例如,节点聚类)。
在明确了任务类型和训练设定后,我们可以为任务设计特定的损失函数。例如,我们可以将交叉熵损失用于节点级的半监督分类任务。
4、使用计算模块构建图模型
在完成了上述步骤之后,我们可以使用计算模块构建图模型。常用的计算模块包括:
传播模块:该模块被用于在节点之间传播信息,聚合得到的信息可以同时捕获特征和拓扑信息。传播模块通常使用卷积操作和循环操作从邻居节点聚合信息,同时也使用跳跃链接操作从历史表征中聚合信息并缓解过平滑问题。
采样模块:在处理大型图时,我们通常需要使用采样模块来组织图上的传播过程。
池化模块:在表征高层次子图或图的时候,我们需要使用池化模块从节点中提取信息。
如图 2 所示,我们可以使用上述计算模块构建 GNN 模型。其中,每一层网络中都可以使用卷积操作、循环操作、采样模块和跳跃链接,而池化操作则被用于提取高层次的信息。我们通常将这些网络层堆叠起来,从而获得更好的表征。

图 2:GNN 模型的一般设计流程
5、计算模型举例
根据使用的计算模块,我们可以将现有的 GNN 网络按照如图 3 所示的方法进行分类:

图 3:计算模块一览
5.1 传播模块——卷积操作
卷积操作是 GNN 模型使用最频繁的信息传播操作,它将其它域中的卷积操作泛化到了图域中。该领域的研究进展主要可以分为谱域方法和空域方法。
谱域方法
谱域方法需要使用图的谱表征。此类方法以图信号处理为基础,定义了谱域的卷积操作。在谱方法中,我们首先通过图傅里叶变换将图信号 x 变换到谱域中,然后进行图卷积。在卷积后,我们使用逆图傅里叶变换将信号变换回去。改变换可以定义为:

U 为归一化后的图拉普拉斯矩阵的特征向量矩阵。根据卷积理论,我们可以将卷积操作定义为:
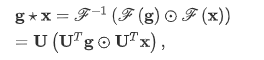
其中,为谱域中的卷积核。我们可以使用一个可学习的对角矩阵对卷积核进行简化,从而将谱方法的卷积操作写作,我们可以根据区分各种谱方法:
![]()
2014 年,Bruna 等人首次提出了 Spectral Network,它利用了一个可学习的对角矩阵作为卷积核。此后,为了提升计算效率并引入空间局部卷积核,Defferrard 等人利用截断的切比雪夫展开式提出了 ChebNet,其卷积核无需计算拉普拉斯矩阵的特征向量。
2017 年,Kipf 和 Welling 在 ChebNet 的基础上进一步提出了 GCN,简化了卷积操作,缓解了过拟合问题,作者还引入了重归一化技巧,解决了梯度爆炸/梯度消失问题。
上述方法都使用了原始的图结构表征节点之间的关系。然而,各个节点之间还存在一些隐式的关系。2018 年,Li 等人提出了自适应图卷积网络(AGCN),该模型学习了一个「残差」拉普拉斯矩阵,并将其与原始的拉普拉斯矩阵相加,可以有效学习节点间的底层关系。为了同时考虑图上的局部一致性和全局一致性,
Zhang 和 Ma 等人于 2018 年提出了对偶图卷积网络,它使用了两个卷积网络分别捕获局部一致性和全局一致性,并使用了一个无监督损失集成二者。
Xu 等人于 2019 年提出了图小波神经网络(GWNN),它使用小波变换代替傅里叶变换,将图数据变换到频域中。图小波变换无需使用矩阵分解,计算效率更高,其性能和可解释性也更强。
值得一提的是,大多数谱域方法使用的卷积核依赖于图结构,因此这些卷积核无法被用于变化后的图结构,即此类方法只适用于「转导学习」场景。
基本的空域方法
空域方法基于图的拓扑结构直接在图上定义卷积操作。对于此类方法而言,最主要的挑战时针对不同尺度的邻域定义卷积操作,并保持 CNN 的局部不变性。
空域方法的代表性工作有:Neural FP、DCNN、PATCHY-SAN、LGCN、GraphSAGE 等方法。
其中,Neural FP 根据节点的度为节点分配权值矩阵,然而它无法被应用于大规模的图。
DCNN 使用转移矩阵定义节点的领域,可以考虑 K 跳节点的信息。
PATCHY-SAN 为每个节点提取邻域中 k 个邻居节点的归一化信息,归一化后的邻域可以被视为传统卷积操作中的感受野。
LGCN 利用 CNN 作为聚合器,在节点的邻域矩阵中执行最大池化操作,得到 top-k 的特征元素,并使用一维 CNN 计算隐藏表征。
GraphSAGE 是目前广为使用的空域图神经网络,它是一种归纳学习框架,通过采样从固定大小的节点的局部邻域中聚合特征,从而生成嵌入:

其中为聚合函数。当聚合函数为平均聚合函数时,GraphSAGE 可以被视为 GCN 的归纳学习版本。
基于注意力的空域方法
注意力机制在许多基于序列的任务都取得了成功。一些研究工作试图将注意力操作扩展到图学习领域。基于注意力的图神经网络为邻居节点赋予不同的权值,从而减轻噪声的影响。此类方法的代表性工作主要包括 GAT 和 GaAN。
其中,图注意力网络(GAT)将注意力机制引入了信息传播过程中。它通过自注意力策略为邻居节点赋予注意力权值,计算出每个节点的隐藏状态。节点 v 的隐藏状态可以表征为:

此外,GAT 还使用了多头注意力机制使训练过程更加稳定。引入注意力机制的优势如下:
(1)并行计算节点对之间的注意力值,操作更加高效;
(2)为邻居节点指定权重,该机制可以被用于具有不同度的图节点;
(3)可以被用于归纳学习问题。
空域方法的通用框架
研究人员提出了一系列通用框架,旨在将各种空域方法统一到同一个框架下。
Monti 等人提出了混合模型网络 MoNet,它是一种将多种在图或流形上定义的空域方法统一起来的框架。
Gilmer 等人提出了消息传递神经网络(MPNN),它使用消息传递函数统一各种变体。
Wang 等人提出了非局部神经网络(NLNN)统一了多种基于自注意力的方法。
Battaglia 等人提出了图网络(GN)定义了一种用于学习节点级、边级、图级别表征的通用网络。
5.2 传播模块——循环操作
基于循环操作的方法是当下图神经网络研究的前沿问题之一。在卷积操作中,各个网络层使用不同的权值,而循环操作中的网络层则共享相同的权值。早期基于循环神经网络的方法主要侧重于处理有向无环图。
2005 年 Gori 等人提出了 GNN 的概念,将现有的神经网络拓展到处理更多类型的图数据上。目前,此类方法主要可以分为基于隐藏状态收敛的方法和基于门控机制的方法。
表 2 归纳了基于循环操作的 GNN:
表 2:基于循环操作的 GNN 变体

基于收敛的方法旨在为每个节点学习一种状态嵌入,并使用该嵌入得到某种输出(例如,预测节点标签的分布):
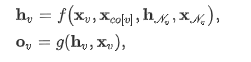
基于收敛的方法的代表性工作有:GraphESN、SSE、LP-GNN 等。
基于门控机制的方法试图将 GRU、LSTM 等模型用于传播步骤中,提升了计算效率和对图结构的长距离信息传播的表征效果。此类方法执行固定数量的训练步,而并不保证收敛。此类方法的代表性工作有 GGNN、Tree LSTM、Graph LSTM、S-LSTM 等。
5.3 传播模块——跳跃连接
为了得到更好的效果,许多应用会展开或堆叠图神经网络层,这是因为更深的网络可以为节点聚合更多的信息(例如,k 层网络可以聚合 k 跳邻居的信息)。
然而,许多实验证明,更深的模型不一定会具有更好的性能,其结果可能恰恰相反。这主要是因为更深的网络也可能从以指数形式增长的邻居向节点传播噪声信息。由于当模型更深时,通过局和操作会得到相似的节点表示,这可能会引起郭平华问题。
因此,许多方法试图向模型中添加「跳跃连接」,从而加深 GNN。此类方法的代表性工作有:Highway GCN、CLN、JKN、ResGCN、DenseGCN 等。以 Highway GCN 为例,Rahimi 等人于 2018 年借鉴 highway networks 的思想,使用层级别的门控机制提出了 Highway GCN。该网络中煤以曾将输入和输出通过门控权重加和:

5.4 采样模块
GNN 会聚合前一层中节点的邻域信息,从而生成节点的表征。如果我们回溯若干个 GNN 层,计算涉及的邻居节点数将会随着深度的增加而呈指数增长。
我们可以通过采样技术缓解这种「邻居爆炸」的问题。此外,在处理大规模图时,我们不能一直存储并处理每个节点所有邻居的信息,因此需要通过采样模块来保证信息传播的进行。一般来说,我们会采取节点采样、层采样、子图采样这三种层次上的采样技术。
其中,从节点的邻域中选取所有邻居节点的子集是最直观的缩小计算规模的方法,代表性的工作有 GraphSAGE、PinSage 等。层采样在每一层中保留了一个小的节点子集,为这些节点聚合信息,而不是为每个节点采样邻域,从而控制扩展系数,代表性的工作有 FastGCN、LADIES 等。
子图采样对图中的多个子图进行采样,并将邻域搜索限制在这些子图中,而不是在完整的图上进行节点采样或边采样,代表性的工作有 ClusterGCN、GraphSAINT 等。
5.5 池化模块
在计算机视觉领域中,我们往往会在卷积层后加入一个池化层,从而得到更通用的特征。复杂的大规模图通常具有丰富的层次结构,这对节点级和图级别的分类任务十分重要。
类似地,许多研究人员试图在图模型中设计层次化的池化层,池化模块主要可以分为两类:直接池化模块、层次化池化模块。
直接池化模块直接地使用不同的节点选择策略根据节点学习图级别的表征,此类模块也被成为读出函数,代表性的读出函数有:简单的节点级的最大/平均/求和/注意力操作,Set2set,SortPooling 等。
层次化的池化会考虑图结构的层次化属性,代表性的方法有 Graph Coarsening、ECC、DiffPool、gPool、EigenPooling、SAGPool 等。
03
将GNN用于各种类别与规模的图
现实世界中的图往往是复杂的。针对不同的场景,研究人员提出了针对有向图、异构图、动态图、超图、有符号图、大型图等场景的图神经网络模型。
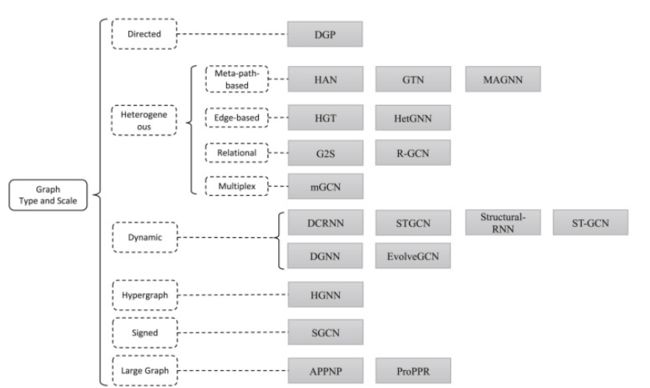
图 4:将 GNN 应用于各种类别与规模的图
1、有向图
有向边往往比无向边包含更多的信息。例如,在知识图谱中,若头实体是尾实体的父类,则边的方向会提供这种偏序关系的信息。我们还可以分别对边的两个方向建模,而不是简单地在卷积操作中使用不对称的邻接矩阵,代表性的工作有 DGP。
2、异构图
当节点和边具有多种类别,存在多种模态时,我们需要处理异构图。具体而言,在异构图中,每个节点都带有类型信息,每条边也带有类型信息。
最广为使用的异构图学习方法是基于元路径的方法。元路径指定了路径中每个位置的节点类型。在训练过程中,元路径被实例化为节点序列,我们通过链接一个元路径实例两端的节点来捕获两个可能并不直接相连的节点的相似度。这样一来,一个异构图可以被化简为若干个同构图,我们可以在这些同构图上应用图学习算法。
此外,还有一些工作提出了基于边的方法处理异构图,它们为不同的邻居节点和边使用不同的采样函数、聚合函数。代表性的工作有 HetGNN、HGT 等。
我们有时还需要处理关系图,这些图中的边可能包含类别以外的信息,或者边的类别数十分巨大,难以使用基于元路径或元关系的方法。针对关系图,研究人员提出了 G2S、GGNN、R-GCN 等模型。
3、多重图
在更复杂的情况下,图中的一对节点可以通过不同类型的多条边相关联。通过利用不同类型的边,我们可以组织起若干层图,每层代表一种类型的关系。因此,多重图也可以称为多视图图,代表性的工作有 mGCN 等。
4、动态图
在动态图中,节点和边等图结构中的元素会随时间而不断变化,我们需要同时对图结构数据与时序数据建模。代表性的工作有 DCRNN、STGCN、DGNN、EvolveGCN 等。
04
训练情况
在有监督学习和半监督学习情况下,数据带有标签,为这些任务设计损失函数较为容易。然而,在无监督学习问题中,样本并不带有标签,因此损失函数与图本身提供的信息(例如,输入的特征或图的拓扑结构)密切相关。如图 5 所示,针对无监督图学习任务,主流的解决方案包括自编码机或对比学习。

图 5:无监督图学习损失函数
1、图自编码机
图自编码机(GAE)首先利用 GCN 对图中节点进行编码,然后使用简单的解码器重建邻接矩阵并根据原始邻接矩阵和重建邻接矩阵之间的相似度计算损失函数:
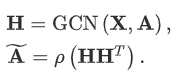
针对各种不同的场景,研究人员提出了 ARGA、VGAE、GALA、MGAE 等 GAE 的变体。
2、对比学习
对比学习为无监督图表征学习开辟了另一条道路。其中,
DGI 最大化了节点表征和图表征之间的互信息;
Infograph 通过最大化图级别表征和不同尺度上的子结构级别的表征之间的互信息进行对比学习;
Hassani 等人通过多视图对比了一阶邻接矩和图传播的表征,在多图学习任务上实现了目前最有的性能。
05
应用场景
目前,图神经网络已经被广泛地应用于各种有监督、半监督、无监督和强化学习场景。这些应用场景可以被分为结构化场景和非结构化场景:
在结构化场景下,数据具有显式的关系结构。一些科学研究中的问题涉及此类场景,例如,图挖掘、对物理系统和化学系统建模。此外,知识图谱、交通网络、推荐系统等工业应用场景也是结构化的。
在非结构化的场景下,数据具有隐式的关系结构,或者不存在关系结构。非结构化数据通常包括图像(计算机视觉)和文本(自然语言处理)。
图 6 列举出了一些图神经网络的应用场景:

图 6:GNN 的应用场景示意图
06
四大方向
尽管 GNN 近年来在诸多领域取得了巨大的成功,但是现在的 GNN 模型仍然存在以下不足:
鲁棒性:GNN 对于对抗性攻击也十分脆弱。与图像和文本上的对抗性攻击相比,防御图上的对抗性攻击不仅仅需要关注特征,还需要考虑结构信息。
可解释性:对于神经模型而言,可解释性是一个重要的研究方向。GNN 也是一种缺乏可解释性的黑盒模型。近年来,只有少数工作为 GNN 提出了示例级的解释。
图预训练:基于神经网络的方法需要大量的有标签数据,而获取海量人工标注数据的成本非常高。研究人员提出了自监督学习方法引导模型利用无标签数据进行学习,我们可以很容易地从该网络或知识库中获取这些无标签数据。人们通过预训练技术在 CV 和 NLP 领域实现了自监督学习。图上的预训练任务仍然面临着一些挑战,例如:如何设计与训练任务,现有的 GNN 模型在学习结构或特征信息方面的有效性等。
复杂图结构:在现实应用场景下,图结构往往是灵活多变且复杂的。人们提出了多种方法处理复杂的图结构,例如:动态图、异构图。随着社交网络的迅速发展,会涌现出更多的问题、挑战和应用场景,需要更加强大的图模型。
扫描下方二维码,申请加入「图神经网络兴趣群」
