❤️《画解数据结构》三张动图,画解哈希❤️
零、前言
「 数据结构 」 和 「 算法 」 是密不可分的,两者往往是「 相辅相成 」的存在,所以,在学习 「 数据结构 」 的过程中,不免会遇到各种「 算法 」。
数据结构 常用的操作一般为:「 增 」「 删 」「 改 」「 查 」。基本上所有的数据结构都是围绕这几个操作进行展开的。
那么这篇文章,作者将用 「 三张动图 」 来阐述一种 「 均摊 O(1) 」 的数据结构
「 哈希表 」

饭不食,水不饮,题必须刷
C语言免费动漫教程,和我一起打卡! 《光天化日学C语言》
LeetCode 太难?先看简单题! 《C语言入门100例》
数据结构难?不存在的! 《画解数据结构》
闭关刷 LeetCode,剑指大厂Offer! 《LeetCode 刷题指引》
LeetCode 太简单?算法学起来! 《夜深人静写算法》
哈希表常用的方法是 开放定址法 和 链地址法:开放定址法
链地址法
看不懂没有关系,我会把它拆开来一个一个讲,首先来看一下今天要学习的内容目录。
文章目录
- 零、前言
- 一、哈希表的概念
-
- 1、查找算法
- 2、哈希表
- 2、哈希数组
- 3、关键字
- 4、哈希函数
- 5、哈希冲突
- 6、哈希地址
- 二、常用哈希函数
-
- 1、直接定址法
- 2、平方取中法
- 3、折叠法
- 4、除留余数法
- 5、位与法
- 三、常见哈希冲突解决方案
-
- 1、开放定址法
-
- 1)原理讲解
- 2)动画演示
- 2、再散列函数法
-
- 1)原理讲解
- 2)动画演示
- 3、链地址法
-
- 1)原理讲解
- 2)动画演示
- 4、公共溢出区法
-
- 1)原理讲解
- 2)动画演示
- 四、哈希表的实现
-
- 1、数据结构定义
- 2、哈希表初始化
- 3、哈希函数计算
- 4、哈希表查找
- 5、哈希表插入
- 6、哈希表删除
- 7、哈希表完整实现
- 五、哈希表的入门
-
- 1、哈希偏移
- 2、字符哈希
- 3、整数哈希
- 六、哈希表的进阶
-
- 1、双指针
- 2、等式转换
- 3、O(1) 数据结构的构造
一、哈希表的概念
1、查找算法
当我们在一个 链表 或者 顺序表 中 查找 一个数据元素 是否存在 的时候,唯一的方法就是遍历整个表,这种方法称为 线性枚举。

如果这时候,顺序表是有序的情况下,我们可以采用折半的方式去查找,这种方法称为 二分枚举。
线性枚举 的时间复杂度为 O ( n ) O(n) O(n)。二分枚举 的时间复杂度为 O ( l o g 2 n ) O(log_2n) O(log2n)。是否存在更快速的查找方式呢?这就是本要介绍的一种新的数据结构 —— 哈希表。
2、哈希表
由于它不是顺序结构,所以很多数据结构书上称之为 散列表,下文会统一采用 哈希表 的形式来说明,作为读者,只需要知道这两者是同一种数据结构即可。
我们把需要查找的数据,通过一个 函数映射,找到 存储数据的位置 的过程称为 哈希。这里涉及到几个概念:
a)需要 查找的数据 本身被称为 关键字;
b)通过 函数映射 将 关键字 变成一个 哈希值 的过程中,这里的 函数 被称为 哈希函数;
c)生成 哈希值 的过程过程可能产生冲突,需要进行 冲突解决;
d)解决完冲突以后,实际 存储数据的位置 被称为 哈希地址,通俗的说,它就是一个数组下标;
e)存储所有这些数据的数据结构就是 哈希表,程序实现上一般采用数组实现,所以又叫 哈希数组。整个过程如下图所示:
2、哈希数组
为了方便下标索引,哈希表 的底层实现结构是一个数组,数组类型可以是任意类型,每个位置被称为一个槽。如下图所示,它代表的是一个长度为 8 的 哈希表,又叫 哈希数组。
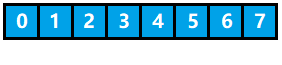
3、关键字
关键字 是哈希数组中的元素,可以是任意类型的,它可以是整型、浮点型、字符型、字符串,甚至是结构体或者类。如下的 A、C、M 都可以是关键字;
int A = 5;
char C[100] = "Hello World!";
struct Obj {
};
Obj M;
哈希表的实现过程中,我们需要通过一些手段,将一个非整型的 关键字 转换成 数组下标,也就是 哈希值,从而通过 O ( 1 ) O(1) O(1) 的时间快速索引到它所对应的位置。
而将一个非整型的 关键字 转换成 整型 的手段就是 哈希函数。
4、哈希函数
哈希函数可以简单的理解为就是小学课本上那个函数,即 y = f ( x ) y = f(x) y=f(x),这里的 f ( x ) f(x) f(x) 就是哈希函数, x x x 是关键字, y y y 是哈希值。好的哈希函数应该具备以下两个特质:
a)单射;
b)雪崩效应:输入值 x x x 的 1 1 1 比特的变化,能够造成输出值 y y y 至少一半比特的变化;
单射很容易理解,图 ( a ) (a) (a) 中已知哈希值 y y y 时,键 x x x 可能有两种情况,不是一个单射;而图 ( b ) (b) (b) 中已知哈希值 y y y 时,键 x x x 一定是唯一确定的,所以它是单射。由于 x x x 和 y y y 一一对应,这样就从本原上减少了冲突。
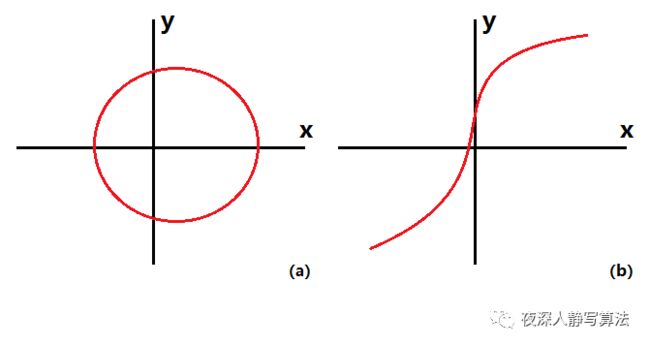 雪崩效应是为了让哈希值更加符合随机分布的原则,哈希表中的键分布的越随机,利用率越高,效率也越高。
雪崩效应是为了让哈希值更加符合随机分布的原则,哈希表中的键分布的越随机,利用率越高,效率也越高。
常用的哈希函数有:直接定址法、除留余数法、数字分析法、平方取中法、折叠法、随机数法 等等。有关哈希函数的内容,下文会进行详细讲解。
5、哈希冲突
哈希函数在生成 哈希值 的过程中,如果产生 不同的关键字得到相同的哈希值 的情况,就被称为 哈希冲突。
即对于哈希函数 y = f ( x ) y = f(x) y=f(x),当关键字 x 1 ≠ x 2 x_1 \neq x_2 x1=x2,但是却有 f ( x 1 ) = f ( x 2 ) f(x_1) = f(x_2) f(x1)=f(x2),这时候,我们需要进行冲突解决。
冲突解决方法有很多,主要有:开放定址法、再散列函数法、链地址法、公共溢出区法 等等。有关解决冲突的内容,下文会进行详细讲解。
6、哈希地址
哈希地址 就是一个 数组下标 ,即哈希数组的下标。通过下标获得数据,被称为 索引。通过数据获得下标,被称为 哈希。平时工作的时候,和同事交流时用到的一个词 反查 就是说的 哈希。
二、常用哈希函数
1、直接定址法
直接定址法 就是 关键字 本身就是 哈希值,表示成函数值就是 f ( x ) = x f(x) = x f(x)=x 例如,我们需要统计一个字符串中每个字符的出现次数,就可以通过这种方法。任何一个字符的范围都是 [ 0 , 255 ] [0, 255] [0,255],所以只要用一个长度为 256 的哈希数组就可以存储每个字符对应的出现次数,利用一次遍历枚举就可以解决这个问题。C代码实现如下:
int i, hash[256];
for(i = 0; str[i]; ++i) {
++hash[ str[i] ];
}
这个就是最基础的直接定址法的实现。hash[c]代表字符c在这个字符串str中的出现次数。
2、平方取中法
平方取中法 就是对 关键字 进行平方,再取中间的某几位作为 哈希值。
例如,对于关键字 1314 1314 1314,得到平方为 1726596 1726596 1726596,取中间三位作为哈希值,即 265 265 265。
平方取中法 比较适用于 不清楚关键字的分布,且位数也不是很大 的情况。
3、折叠法
折叠法 是将关键字分割成位数相等的几部分(注意最后一部分位数不够可以短一些),然后再进行求和,得到一个 哈希值。
例如,对于关键字 5201314 5201314 5201314,将它分为四组,并且相加得到: 52 + 01 + 31 + 4 = 88 52+01+31+4 = 88 52+01+31+4=88,这就是哈希值。
折叠法 比较适用于 不清楚关键字的分布,但是关键字位数较多 的情况。
4、除留余数法
除留余数法 就是 关键字 模上 哈希表 长度,表示成函数值就是 f ( x ) = x m o d m f(x) = x \ mod \ m f(x)=x mod m 其中 m m m 代表了哈希表的长度,这种方法,不仅可以对关键字直接取模,也可以在 平方取中法、折叠法 之后再取模。
例如,对于一个长度为 4 的哈希数组,我们可以将关键字 模 4 得到哈希值,如图所示:
5、位与法
哈希数组的长度一般选择 2 的幂,因为我们知道取模运算是比较耗时的,而位运算相对较为高效。
选择 2 的幂作为数组长度,可以将 取模运算 转换成 二进制位与。
令 m = 2 k m = 2^k m=2k,那么它的二进制表示就是: m = ( 1 000...000 ⏟ k ) 2 m = (1\underbrace{000...000}_{\rm k})_2 m=(1k 000...000)2,任何一个数模上 m m m,就相当于取了 m m m 的二进制低 k k k 位,而 m − 1 = ( 111...111 ⏟ k ) 2 m-1 = (\underbrace{111...111}_{\rm k})_2 m−1=(k 111...111)2 ,所以和 位与 m − 1 m-1 m−1 的效果是一样的。即: x % S = = x & ( S − 1 ) x \ \% \ S == x \ \& \ (S - 1) x % S==x & (S−1) 除了直接定址法,其它三种方法都有可能导致哈希冲突,接下来,我们就来讨论下常用的一些哈希冲突的解决方案。
三、常见哈希冲突解决方案
1、开放定址法
1)原理讲解
开放定址法 就是一旦发生冲突,就去寻找下一个空的地址,只要哈希表足够大,总能找到一个空的位置,并且记录下来作为它的 哈希地址。公式如下: f i ( x ) = ( f ( x ) + d i ) m o d m f_i(x) = (f(x)+d_i) \ mod \ m fi(x)=(f(x)+di) mod m
这里的 d i d_i di 是一个数列,可以是常数列 ( 1 , 1 , 1 , . . . , 1 ) (1, 1, 1, ...,1) (1,1,1,...,1),也可以是等差数列 ( 1 , 2 , 3 , . . . , m − 1 ) (1,2,3,...,m-1) (1,2,3,...,m−1)。
2)动画演示
上图中,采用的是哈希函数算法是 除留余数法,采用的哈希冲突解决方案是 开放定址法,哈希表的每个数据就是一个关键字,插入之前需要先进行查找,如果找到的位置未被插入,则执行插入;否则,找到下一个未被插入的位置进行插入;总共插入了 6 个数据,分别为:11、12、13、20、19、28。
这种方法需要注意的是,当插入数据超过哈希表长度时,不能再执行插入。
本文在第四章讲解 哈希表的现实 时采用的就是常数列的开放定址法。
2、再散列函数法
1)原理讲解
再散列函数法 就是一旦发生冲突,就采用另一个哈希函数,可以是 平方取中法、折叠法、除留余数法 等等的组合,一般用两个哈希函数,产生冲突的概率已经微乎其微了。
再散列函数法 能够使关键字不产生聚集,当然,也会增加不少哈希函数的计算时间。
2)动画演示
待补充
3、链地址法
1)原理讲解
当然,产生冲突后,我们也可以选择不换位置,还是在原来的位置,只是把 哈希值 相同的用链表串联起来。这种方法被称为 链地址法。
2)动画演示
上图中,采用的是哈希函数算法是 除留余数法,采用的哈希冲突解决方案是 链地址法,哈希表的每个数据保留了一个 链表头结点 和 尾结点,插入之前需要先进行查找,如果找到的位置,链表非空,则插入尾结点并且更新尾结点;否则,生成一个新的链表头结点和尾结点;总共插入了 6 个数据,分别为:11、12、13、20、19、28。
4、公共溢出区法
1)原理讲解
一旦产生冲突的数据,统一放到另外一个顺序表中,每次查找数据,在哈希数组中到的关键字和给定关键字相等,则认为查找成功;否则,就去公共溢出区顺序查找,这种方法被称为 公共溢出区法。
这种方法适合冲突较少的情况。
2)动画演示
待补充
四、哈希表的实现
1、数据结构定义
由于哈希表的底层存储还是数组,所以我们可以定义一个结构体,结构体中定义一个数组类型的成员,如果需要记录哈希表元素的个数,还可以记录一个 size字段。
C语言实现如下:
#define maxn (1<<17) // (1)
#define mask (maxn-1) // (2)
#define DataType int // (3)
#define Boolean int // (4)
#define NULLKEY (maxn+2) // (5)
typedef struct {
DataType data[maxn];
}HashTable;
- ( 1 ) (1) (1) 利用位运算计算哈希函数进行加速,哈希表的长度为 2 的幂;
- ( 2 ) (2) (2) 利用上文提到的 位与法 作为哈希函数,进行位与的掩码必须是二进制表示都是1的,所以等于 2 的幂减一;
- ( 3 ) (3) (3) 定义关键字类型为整型
int; - ( 4 ) (4) (4) 定义一个布尔变量类型;
- ( 5 ) (5) (5)
NULLKEY作为哈希表对应位置为空时的标记,必须是一个非关键字能取到的值;
2、哈希表初始化
哈希表初始化要做的事情,就是把哈希表的每个位置都置空。C语言代码实现如下:
void HashInit(HashTable *ht) {
int i;
for(i = 0; i < maxn; ++i) {
ht->data[i] = NULLKEY; // (1)
}
}
- ( 1 ) (1) (1) 将哈希表的每个位置都置空;
3、哈希函数计算
哈希函数计算采用 除留余数法 的优化版本 位与法。C语言代码实现如下:
int HashGetAddr(DataType key) {
return key & mask;
}
4、哈希表查找
查找需要采用和插入时相同的哈希冲突方案,即开放寻址法。C语言代码实现如下:
Boolean HashSearchKey(HashTable *ht, DataType key, int *addr) {
int startaddr = HashGetAddr(key); // (1)
*addr = startaddr; // (2)
while(ht->data[*addr] != key) {
// (3)
*addr = HashGetAddr(*addr + 1); // (4)
if(ht->data[*addr] == NULLKEY) // (5)
return 0;
if(*addr == startaddr) // (6)
return 0;
}
return 1; // (7)
}
- ( 1 ) (1) (1) 根据 哈希函数
HashGetAddr计算得到一个哈希值startaddr; - ( 2 ) (2) (2)
addr是需要作为返回值的,所以要用解引用; - ( 3 ) (3) (3) 在哈希表的
addr对应查找,如果不是空位,则继续 ( 4 ) (4) (4);否则,跳出循环; - ( 4 ) (4) (4) 往后找一个位置;
- ( 5 ) (5) (5) 如果发现一个空位,说明这个关键字在哈希表中没有对应数据,直接返回 0,代表查找失败;
- ( 6 ) (6) (6) 代表整个 哈希表 都已经遍历完毕,都没有找到合适的关键字,直接返回 0,代表查找失败;
- ( 7 ) (7) (7) 否则,返回 1 代表查找成功;
5、哈希表插入
哈希冲突时(即当没有合适位置),就找下一相邻位置,即寻址数列为常数列 ( 1 , 1 , 1 , . . . , 1 ) (1,1,1,...,1) (1,1,1,...,1)。插入需要注意当哈希表慢时,不能再执行插入操作。C语言代码实现如下:
int HashInsert(HashTable *ht, DataType key) {
int addr = HashGetAddr(key); // (1)
int retaddr;
if ( HashSearchKey(ht, key, &retaddr ) ) {
// (2)
return retaddr;
}
while(ht->data[addr] != NULLKEY) // (3)
addr = HashGetAddr(addr + 1); // (4)
ht->data[addr] = key; // (5)
return addr; // (6)
}
- ( 1 ) (1) (1) 根据 哈希函数
HashGetAddr计算得到一个哈希值addr; - ( 2 ) (2) (2) 插入前需要先查找是否存在,如果已经存在,则不执行插入;
- ( 3 ) (3) (3) 在哈希表的
addr对应查找,如果不是空位,则继续 ( 3 ) (3) (3);否则,跳出循环; - ( 4 ) (4) (4) 往后找一个位置,继续判断是否为空;
- ( 5 ) (5) (5) 跳出循环则代表当前哈希表的
addr位置没有其它元素占据,则可以作为当前key的位置进行插入; - ( 6 ) (6) (6) 返回
addr作为key的哈希地址;
6、哈希表删除
有了查找的基础,删除操作就比较简单了,如果不能找到一个关键字的位置,则不对哈希表进行任何操作,返回空关键字;否则,将找到的位置赋为空关键字,并且返回删除的位置;
int HashRemove(HashTable *ht, DataType key) {
int addr;
if ( !HashSearchKey(ht, key, &addr ) ) {
// (1)
return NULLKEY;
}
ht->data[addr] = NULLKEY; // (2)
return addr;
}
- ( 1 ) (1) (1) 首先执行查找;
- ( 2 ) (2) (2) 对找到的位置,将找到位置关键字清空;
7、哈希表完整实现
最后,给出一个 开放定址法 的哈希表的完整实现,如下:
/******************** 哈希表 开放定址法 ********************/
#define maxn (1<<17)
#define mask (maxn-1)
#define DataType int
#define Boolean int
#define NULLKEY (1<<30)
typedef struct {
DataType data[maxn];
}HashTable;
void HashInit(HashTable *ht) {
int i;
for(i = 0; i < maxn; ++i) {
ht->data[i] = NULLKEY;
}
}
int HashGetAddr(DataType key) {
return key & mask;
}
Boolean HashSearchKey(HashTable *ht, DataType key, int *addr) {
int startaddr = HashGetAddr(key);
*addr = startaddr;
while(ht->data[*addr] != key) {
*addr = HashGetAddr(*addr + 1);
if(ht->data[*addr] == NULLKEY) {
return 0;
}
if(*addr == startaddr) {
return 0;
}
}
return 1;
}
int HashInsert(HashTable *ht, DataType key) {
int addr = HashGetAddr(key);
int retaddr;
if ( HashSearchKey(ht, key, &retaddr ) ) {
return retaddr;
}
while(ht->data[addr] != NULLKEY)
addr = HashGetAddr(addr + 1);
ht->data[addr] = key;
return addr;
}
int HashRemove(HashTable *ht, DataType key) {
int addr;
if ( !HashSearchKey(ht, key, &addr ) ) {
return NULLKEY;
}
ht->data[addr] = NULLKEY;
return addr;
}
/******************** 哈希表 开放定址法 ********************/
本文介绍的哈希表,是最简单的哈希表,对于刷 LeetCode 已经绰绰有余了,但是如果需要更深入的哈希表相关知识,可以参考以下这篇文章:夜深人静写算法(九)- 哈希表。
五、哈希表的入门
1、哈希偏移
LeetCode 525. 连续数组
2、字符哈希
LeetCode 387. 字符串中的第一个唯一字符
3、整数哈希
LeetCode 41. 缺失的第一个正数
六、哈希表的进阶
1、双指针
LeetCode 76. 最小覆盖子串
LeetCode 3. 无重复字符的最长子串
2、等式转换
LeetCode 560. 和为K的子数组
3、O(1) 数据结构的构造
LeetCode 380. O(1) 时间插入、删除和获取随机元素
关于 「 哈希表 」 的内容到这里就结束了。
如果还有不懂的问题,可以 「 通过主页 」找到作者的「 联系方式 」 ,线上沟通交流。
有关《画解数据结构》 的源码均开源,链接如下:《画解数据结构》
饭不食,水不饮,题必须刷
C语言免费动漫教程,和我一起打卡! 《光天化日学C语言》
LeetCode 太难?先看简单题! 《C语言入门100例》
数据结构难?不存在的! 《画解数据结构》
闭关刷 LeetCode,剑指大厂Offer! 《LeetCode 刷题指引》
LeetCode 太简单?算法学起来! 《夜深人静写算法》