本文前提:
代码MySQL 8.0.13
只整理Repeatable Read当前读。Read Committed简单很多,另外快照读是基于MVCC不用加锁,所以不在本文讨论范畴。
1. Lock 与 Latch
InnoDB 中的lock是事务中对访问/修改的record加的锁,它一般是在事务提交或回滚时释放。latch是在BTree上定位record的时候对Btree pages加的锁,它一般是在对page中对应record加上lock并且完成访问/修改后就释放,latch的锁区间比lock小很多。在具体的实现中,一个大的transaction会被拆成若干小的mini transaction(mtr),如下图所示:有一个transaction,依次做了insert,select…for update及update操作,这3个操作分别对应3个mtr,每个mtr完成:
- 在btree查找目标
record,加相关page latch; - 加目标
record lock,修改对应record - 释放
page latch
为什么要这么做呢?是为了并发,事务中的每一个操作,在步骤二完成之后,相应的record已经加上了lock保护起来,确保其他并发事务无法修改,所以这时候没必要还占着record所在的page latch,否则其他事务 访问/修改 相同page的不同record时,这本来是可以并行做的事情,在这里会被page latch会被卡住。

lock是存在lock_sys->rec_hash中,每个record lock在rec_hash中通过 page_no, heap_no>来标识
latch是存在bufferpool对应page的block中,对应block->lock
本文只关注lock相关的东西,latch后面单独搞一篇整理
2. Repeatable Read
具体每个隔离级别就不展开说了,这里主要说下RR,从名字上也能看出来,RR支持可重复度,也就是在一个事务中,多次执行相同的SELECT…FOR UPDATE应该看到相同的结果集(除本事务修改外),这个就要求SELECT的区间里不能有其他事务插入新的record,所以SELECT除了对满足条件的record加lock之外,对相应区间也要加lock来保护起来。在InnoDB的实现中,并没有一个一下锁住某个指定区间的锁,而是把一个大的区间锁拆分放在区间中已有的多个record上来完成。所以引入了Gap lock和Next-key lock的概念,它们加再一个具体的record上
Gap lock保护这个record与其前一个record之间的开区间Next-key lock保护包含这个record与其前一个record之间的左开右闭区间
它们都是为了保护这个区间不能被别的事务插入新的record,实现RR。
接下来从源码实现上来分别看下Insert和Select是如何加lock的,结合着看也就知道InnoDB的RR是如何实现的了。Insert的加锁分布在Insert操作的过程中,遍布在多个相关的函数里,Select的加锁则比较集中,就在row_search_mvcc里。
3. Insert加锁流程
3.1 lock mode
lock的mode主要有Share(S)和Exclusive(X)【代码中对应LOCK_S和LOCK_X】
lock的gap mode主要有Record lock, Gap lock, Next-key lock【代码中对应LOCK_REC_NOT_GAP, LOCK_GAP, LOCK_ORDINARY】
在具体使用中将 mode|gap_mode 之后就是一个lock的实际类型,Record lock是作用在单个record上的记录锁,Gap lock/Next-key lock虽然也是加在某个具体record上,但作用是为了确保record前面的gap不要有其他并发事务插入,这个具体是怎么实现呢,InnoDB引入了一个插入意向锁,他的实际类型是
(LOCK_X | LOCK_GAP | LOCK_INSERT_INTENTION)
与Gap lock/Next-key lock互斥,如果要插入前检测到插入位置的next record上有lock,则会尝试对这个next record加一个插入意向锁,代表本事务打算给这个gap里插一个新record,看行不行?如果已经有别的事务给这里上了Gap/Next-key lock,代表它想保护这里,所以当前插入意向锁需要等待相关事务提交才行。这个检测只是单向的,即插入意向锁需等待Gap/Next-key lock释放,而任何锁不用等待插入意向锁释放,否则严重影响这个gap中不冲突的Insert操作并发。
具体的锁冲突检测在lock_rec_has_to_wait函数中,大体原则就是:判断两个lock兼容还是不兼容,首先先做mode的冲突检测

如果不冲突,则代表锁兼容,无需等待,如果冲突,则接着做gap mode的冲突例外检测,整理如下:
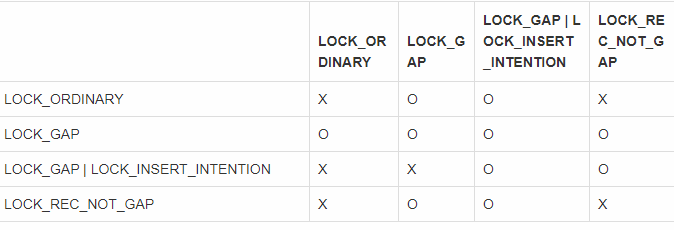
如果gap mode不冲突,则作为例外情况可以认为锁兼容,无需等待。可以看到:
- 插入意向锁需要等待
Gap lock及Next-key lock - 任何锁不用等待插入意向锁
Gap lock无需等待任何锁Next-key lock需要等待其他Next-key lock及Record Lock,反之亦然
了解了这些锁兼容原则,接下来就可以看在实际Insert流程中是如何使用它们的。
3.2 加锁流程
Insert的顺序是先插入主键索引,再依次插入二级索引。以下是从代码中整理出来的流程,插入某个entry的操作,
【对于主键索引】:
(1)先在查找Btree,加相关page latch,定位到entry对应插入位置的record (<= entry)
(2)如果要插入的entry已经存在,即entry = record,此时接着判断:
- 如果是
INSERT ON DUPLICATE KEY UPDATE,则对record加X Next-key lock - 如果是普通
INSERT,则对record加S Next-key lock
之后接着判断record是否是deleted mark:
- 如果不是delete mark,说明的确有duplicate,返回
DB_DUPLICATE_KEY到上层,然后上层通过看是INSERT ON DUPLICATE KEY UPDATE还是普通INSERT来决定是转成update操作继续还是给用户报错duplicate - 如果是deleted mark,则说明实际没有
duplicate record,接着往下走
(3)判断record的下一个record上当前有没有锁,如果有的话,则给其加插入意向锁,确保要插入entry的区间没有其他Gap lock/Next-key lock保护
(4)插入entry
(5)释放page latch,此时依旧占有lock
【对于二级索引】
(1)先在查找Btree,加相关page latch,定位到entry对应插入位置的record (<= entry)
(2)如果要插入的entry已经存在,即entry = record,并且当前index是unique:
- 如果是
INSERT ON DUPLICATE KEY UPDATE,则对record加X Next-key lock - 如果是普通INSERT,则对
record2加S Next-key lock
判断record与entry是否相等:
如果相等 并且 是普通INSERT,则接着判断record是否是deleted mark:
- 如果不是delete mark,说明的确有duplicate,返回
DB_DUPLICATE_KEY到上层,然后上层通过看是INSERT ON DUPLICATE KEY UPDATE还是普通INSERT来决定是转成update操作继续还是给用户报错duplicate - 如果是delete mark,则实际没有duplicate,接着往下走
(3)如果是INSERT ON DUPLICATE KEY UPDATE 并且 当前index是unique,则给其下一个record X Gap lock,保护不会被其他事务插入相同的entry
(4)判断record的下一个record上当前有没有锁,如果有的话,则给其加插入意向锁
(LOCK_X | LOCK_GAP | LOCK_INSERT_INTENTION)
确保要插入entry的区间没有其他Gap lock/Next-key lock保护
(5)插入entry
(6)释放page latch
注:【二级索引】的步骤3似乎有些多余,因为即使有其他并发事务使用INSERT ON DUPLICATE KEY UPDATE来插入相同record的话,和【主键索引】流程一样,步骤1也只能串行进入,第一个线程没有找到与entry相同的record,走步骤4插入,直到步骤6结束释放page latch之后,第二个线程才能进到步骤1里,此时在步骤2中会中卡在加record的X Next-key lock上,直到线程一事务提交之后才能接着进行,所以看起来不会冲突?
上述流程在row_ins_index_entry函数中,具体入口如下:
mysql_parse->mysql_execute_command->Sql_cmd_dml::execute-> Sql_cmd_insert_values::execute_inner->write_record->handler::ha_write_row-> ha_innobase::write_row->row_insert_for_mysql->row_insert_for_mysql_using_ins_graph-> row_ins_step->row_ins->row_ins_index_entry_step->row_ins_index_entry
其中插入意向锁是在lock_rec_insert_check_and_lock函数里加的,入口如下:
row_ins_index_entry->row_ins_clust_index_entry/row_ins_sec_index_entry-> btr_cur_optimistic_insert/btr_cur_pessimistic_insert->btr_cur_ins_lock_and_undo-> lock_rec_insert_check_and_lock
3.3 隐式锁
另外要提的一点就是,Insert操作不会显式的加锁,每一条Insert的record上都默认有一个隐式锁,它是通过record的隐藏字段trx_id来检测的,对于主键索引,如果要插入的record在Btree中找到,那么只需要通过比较已有record的trx_id,如果这个trx_id对应的事务还是活跃事务,那么说明这个record的插入事务还未提交,隐式代表这个record上有锁,那么此时就才会将其转成显式锁放进lock_sys中并wait,这样做是为了提高性能,尽量减少对lock_sys的操作。对于二级索引的隐式锁检测就没有主键索引这么容易了,因为二级索引record没有记录trx_id,只能首先通过其所在page上的max_trx_id与当前活跃事务列表的最小trx_id来比较,小于它的话代表最后一次修改这个page的事务都已经提交,所以record上没有隐式锁,如果大于或等于它的话,就需要回主键找到对应的主键record并遍历undo历史版本来确认是否有隐式锁,具体实现在row_vers_impl_x_locked_low中,
4. Select 加锁流程
SELECT做当前读的加锁流程就在row_search_mvcc当中,一条SELECT语句会多次进入这个函数,第一次是通过index_read->row_search_mvcc进来,一般是首次访问index,取找WHERE里的exact record,之后每次再通过general_fetch->row_search_mvcc进来,根据具体条件遍历prev/next record,直到把满足WHRER条件的record都取出来。具体的加锁也就是在访问和遍历record的过程中进行,row_search_mvcc代码很长,这里我只提炼总结下加锁相关的流程:
- 在index上查找search_tuple对应的record。(这里的record可能是上面说的index_read进来首次通过index Btree查找
search_tuple对应的record,也有可能是之后多次general_fetch进来通过之前保存的cursor来恢复出来的上一次访问位置,然后拿到的prev/next record) - 如果是index_read 并且 mode是
PAGE_CUR_L或着PAGE_CUR_LE,给定位到的record的next record加 GAP LOCK - 如果record是infimum,跳转步骤9 next_rec,如果是supremum,加Next-key Lock,跳转步骤9 next_rec
- 如果是index_read,record与search_tuple不相等,给
record加GAP LOCK,返回 NOT FOUND - 到这里说明record与search_tuple相等,给record加Next-key Lock,两个例外,只加Rec Lock:
- 对于index_read,如果当前index是主键索引 并且
mode是PAGE_CUR_GE并且search_tuple的fields个数等于index的unique fields个数 - 看是否是unique_search,即search_tuple的fields个数等于当前index的unique fields个数 并且 当前index是主键索引或者(是二级索引且search_tuple不包含NULL字段)并且 record不是deleted mark
- 到这里说明加锁成功了,然后处理record是deleted mark的情况:
- 当前index是主键索引 并且 是
unique_search,返回NOT FOUND - 否则,跳转步骤9 next_rec
- 如果当前index是二级索引 并且 需要回查主键索引,去主键索引里找对应的
primary record并加Rec Lock,如果primary record是deleted mark,则当前二级索引接着跳转步骤9 next_rec - 成功,返回
DB_SUCCESS - next_rec: 根据mode来取对应的
prev/next record,跳转 步骤3 继续
重点说一下步骤3,这里一般record是infimum或者supremum的情况都是多次genera_fetch对某个page取prev/next record之后走到page边缘,对于infimum,不会加任何lock,直接继续访问前一个prev record(即prev page的supremum),对于supremum的话,会加上Gap lock,它保护当前page最后一个user record和next page第一个user record之间的Gap。
其他的流程也就没什么了:
- 对于遍历到的满足条件的record,基本默认都是加Next-key lock
- 二级索引回表时只会对主键加Rec lock
- 对于某些特殊的场景,会将某些
Next-key lock降级成Rec lock(步骤5) - 还有一些特殊场景,会只加Gap lock(步骤2、4)
总结:
以上基本就是InnoDB加事务锁的相关流程,Insert和Select的加锁流程配合着看,事务锁的原则及实现基本也就出来了。
到此这篇关于MySQL InnoDB 事务锁源码分析的文章就介绍到这了,更多相关MySQL InnoDB 事务锁源码分析内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!