毕业设计之 - 基于深度学习的银行卡识别算法设计
1 前言
Hi,大家好,这里是丹成学长,今天向大家介绍
基于深度学习的银行卡识别算法设计
大家可用于 毕业设计
银行卡字符定位
首先就是将整张银行卡号里面的银行卡号部分进行识别,且分出来,这一个环节学长用的技术就是faster-rcnn的方法
将目标识别部分的银行卡号部门且分出来,进行保存
主程序的代码如下(非完整代码):
# author:丹成学长 Q746976041
#!/usr/bin/env python
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import argparse
import os
import cv2
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from lib.config import config as cfg
from lib.utils.nms_wrapper import nms
from lib.utils.test import im_detect
from lib.nets.vgg16 import vgg16
from lib.utils.timer import Timer
os.environ["CUDA_VISIBLE_DEVICES"] = '0' #指定第一块GPU可用
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.8 # 程序最多只能占用指定gpu50%的显存
config.gpu_options.allow_growth = True #程序按需申请内存
sess = tf.Session(config = config)
CLASSES = ('__background__','lb')
NETS = {
'vgg16': ('vgg16_faster_rcnn_iter_70000.ckpt',), 'res101': ('res101_faster_rcnn_iter_110000.ckpt',)}
DATASETS = {
'pascal_voc': ('voc_2007_trainval',), 'pascal_voc_0712': ('voc_2007_trainval+voc_2012_trainval',)}
def vis_detections(im, class_name, dets, thresh=0.5):
"""Draw detected bounding boxes."""
inds = np.where(dets[:, -1] >= thresh)[0]
if len(inds) == 0:
return
im = im[:, :, (2, 1, 0)]
fig, ax = plt.subplots(figsize=(12, 12))
ax.imshow(im, aspect='equal')
sco=[]
for i in inds:
score = dets[i, -1]
sco.append(score)
maxscore=max(sco)
# print(maxscore)成绩最大值
for i in inds:
# print(i)
score = dets[i, -1]
if score==maxscore:
bbox = dets[i, :4]
# print(bbox)#目标框的4个坐标
img = cv2.imread("data/demo/"+filename)
# img = cv2.imread('data/demo/000002.jpg')
sp=img.shape
width = sp[1]
if bbox[0]>20 and bbox[2]+20<width:
cropped = img[int(bbox[1]):int(bbox[3]), int(bbox[0]-20):int(bbox[2])+20] # 裁剪坐标为[y0:y1, x0:x1]
if bbox[0]<20 and bbox[2]+20<width:
cropped = img[int(bbox[1]):int(bbox[3]), int(bbox[0]):int(bbox[2])+20] # 裁剪坐标为[y0:y1, x0:x1]
if bbox[0] > 20 and bbox[2] + 20 > width:
cropped = img[int(bbox[1]):int(bbox[3]), int(bbox[0] - 20):int(bbox[2])] # 裁剪坐标为[y0:y1, x0:x1]
path = 'cut1/'
# 重定义图片的大小
res = cv2.resize(cropped, (1000, 100), interpolation=cv2.INTER_CUBIC) # dsize=(2*width,2*height)
cv2.imwrite(path+str(i)+filename, res)
ax.add_patch(plt.Rectangle((bbox[0], bbox[1]),
bbox[2] - bbox[0],
bbox[3] - bbox[1], fill=False,
edgecolor='red', linewidth=3.5)
)
ax.text(bbox[0], bbox[1] - 2,
'{:s} {:.3f}'.format(class_name, score),
bbox=dict(facecolor='blue', alpha=0.5),
fontsize=14, color='white')
ax.set_title(('{} detections with '
'p({} | box) >= {:.1f}').format(class_name, class_name,thresh),
fontsize=14)
plt.axis('off')
plt.tight_layout()
plt.draw()
def demo(sess, net, image_name):
"""Detect object classes in an image using pre-computed object proposals."""
# Load the demo image
im_file = os.path.join(cfg.FLAGS2["data_dir"], 'demo', image_name)
im = cv2.imread(im_file)
# Detect all object classes and regress object bounds
timer = Timer()
timer.tic()
scores, boxes = im_detect(sess, net, im)
timer.toc()
print('Detection took {:.3f}s for {:d} object proposals'.format(timer.total_time, boxes.shape[0]))
# Visualize detections for each class
CONF_THRESH = 0.1
NMS_THRESH = 0.1
for cls_ind, cls in enumerate(CLASSES[1:]):
cls_ind += 1 # because we skipped background
cls_boxes = boxes[:, 4 * cls_ind:4 * (cls_ind + 1)]
cls_scores = scores[:, cls_ind]
# print(cls_scores)#一个300个数的数组
#np.newaxis增加维度 np.hstack将数组拼接在一起
dets = np.hstack((cls_boxes,cls_scores[:, np.newaxis])).astype(np.float32)
keep = nms(dets, NMS_THRESH)
dets = dets[keep, :]
vis_detections(im, cls, dets, thresh=CONF_THRESH)
def parse_args():
"""Parse input arguments."""
parser = argparse.ArgumentParser(description='Tensorflow Faster R-CNN demo')
parser.add_argument('--net', dest='demo_net', help='Network to use [vgg16 res101]',
choices=NETS.keys(), default='vgg16')
parser.add_argument('--dataset', dest='dataset', help='Trained dataset [pascal_voc pascal_voc_0712]',
choices=DATASETS.keys(), default='pascal_voc')
args = parser.parse_args()
return args
if __name__ == '__main__':
args = parse_args()
# model path
demonet = args.demo_net
dataset = args.dataset
#tfmodel = os.path.join('output', demonet, DATASETS[dataset][0], 'default', NETS[demonet][0])
tfmodel = r'./default/voc_2007_trainval/cut1/vgg16_faster_rcnn_iter_8000.ckpt'
# 路径异常提醒
if not os.path.isfile(tfmodel + '.meta'):
print(tfmodel)
raise IOError(('{:s} not found.\nDid you download the proper networks from '
'our server and place them properly?').format(tfmodel + '.meta'))
# set config
tfconfig = tf.ConfigProto(allow_soft_placement=True)
tfconfig.gpu_options.allow_growth = True
# init session
sess = tf.Session(config=tfconfig)
# load network
if demonet == 'vgg16':
net = vgg16(batch_size=1)
# elif demonet == 'res101':
# net = resnetv1(batch_size=1, num_layers=101)
else:
raise NotImplementedError
net.create_architecture(sess, "TEST", 2,
tag='default', anchor_scales=[8, 16, 32])
saver = tf.train.Saver()
saver.restore(sess, tfmodel)
print('Loaded network {:s}'.format(tfmodel))
# # 文件夹下所有图片进行识别
# for filename in os.listdir(r'data/demo/'):
# im_names = [filename]
# for im_name in im_names:
# print('~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~')
# print('Demo for data/demo/{}'.format(im_name))
# demo(sess, net, im_name)
#
# plt.show()
# 单一图片进行识别
filename = '0001.jpg'
im_names = [filename]
for im_name in im_names:
print('~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~')
print('Demo for data/demo/{}'.format(im_name))
demo(sess, net, im_name)
plt.show()
效果如下:


字符分割
将切分出来的图片进行保存,然后就是将其进行切分:
主程序的代码和上面第一步的步骤原理是相同的,不同的就是训练集的不同设置
效果图如下:
![]()
银行卡数字识别
仅部分代码:
# author:丹成学长 Q746976041
import os
import tensorflow as tf
from PIL import Image
from nets2 import nets_factory
import numpy as np
import matplotlib.pyplot as plt
# 不同字符数量
CHAR_SET_LEN = 10
# 图片高度
IMAGE_HEIGHT = 60
# 图片宽度
IMAGE_WIDTH = 160
# 批次
BATCH_SIZE = 1
# tfrecord文件存放路径
TFRECORD_FILE = r"C:\workspace\Python\Bank_Card_OCR\demo\test_result\tfrecords/1.tfrecords"
# placeholder
x = tf.placeholder(tf.float32, [None, 224, 224])
os.environ["CUDA_VISIBLE_DEVICES"] = '0' #指定第一块GPU可用
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.5 # 程序最多只能占用指定gpu50%的显存
config.gpu_options.allow_growth = True #程序按需申请内存
sess = tf.Session(config = config)
# 从tfrecord读出数据
def read_and_decode(filename):
# 根据文件名生成一个队列
filename_queue = tf.train.string_input_producer([filename])
reader = tf.TFRecordReader()
# 返回文件名和文件
_, serialized_example = reader.read(filename_queue)
features = tf.parse_single_example(serialized_example,
features={
'image' : tf.FixedLenFeature([], tf.string),
'label0': tf.FixedLenFeature([], tf.int64),
})
# 获取图片数据
image = tf.decode_raw(features['image'], tf.uint8)
# 没有经过预处理的灰度图
image_raw = tf.reshape(image, [224, 224])
# tf.train.shuffle_batch必须确定shape
image = tf.reshape(image, [224, 224])
# 图片预处理
image = tf.cast(image, tf.float32) / 255.0
image = tf.subtract(image, 0.5)
image = tf.multiply(image, 2.0)
# 获取label
label0 = tf.cast(features['label0'], tf.int32)
return image, image_raw, label0
# 获取图片数据和标签
image, image_raw, label0 = read_and_decode(TFRECORD_FILE)
# 使用shuffle_batch可以随机打乱
image_batch, image_raw_batch, label_batch0 = tf.train.shuffle_batch(
[image, image_raw, label0], batch_size=BATCH_SIZE,
capacity=50000, min_after_dequeue=10000, num_threads=1)
# 定义网络结构
train_network_fn = nets_factory.get_network_fn(
'alexnet_v2',
num_classes=CHAR_SET_LEN * 1,
weight_decay=0.0005,
is_training=False)
with tf.Session() as sess:
# inputs: a tensor of size [batch_size, height, width, channels]
X = tf.reshape(x, [BATCH_SIZE, 224, 224, 1])
# 数据输入网络得到输出值
logits, end_points = train_network_fn(X)
# 预测值
logits0 = tf.slice(logits, [0, 0], [-1, 10])
predict0 = tf.argmax(logits0, 1)
# 初始化
sess.run(tf.global_variables_initializer())
# 载入训练好的模型
saver = tf.train.Saver()
saver.restore(sess, '../Cmodels/model/crack_captcha1.model-6000')
# saver.restore(sess, '../1/crack_captcha1.model-2500')
# 创建一个协调器,管理线程
coord = tf.train.Coordinator()
# 启动QueueRunner, 此时文件名队列已经进队
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
for i in range(6):
# 获取一个批次的数据和标签
b_image, b_image_raw, b_label0 = sess.run([image_batch,image_raw_batch,label_batch0])
# 显示图片
img = Image.fromarray(b_image_raw[0], 'L')
plt.imshow(img)
plt.axis('off')
plt.show()
# 打印标签
print('label:', b_label0)
# 预测
label0 = sess.run([predict0], feed_dict={
x: b_image})
# 打印预测值
print('predict:', label0[0])
# 通知其他线程关闭
coord.request_stop()
# 其他所有线程关闭之后,这一函数才能返回
coord.join(threads)
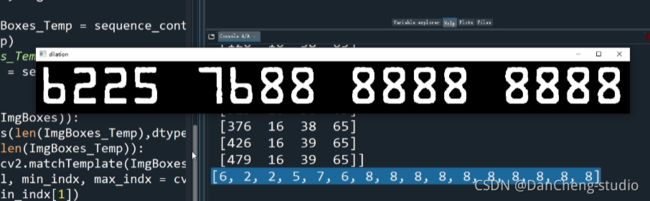
最终实现效果:
最后 - 毕设帮助
print("毕设帮助、指导、有问必答")
print("丹成学长Q:746876041")