FAQ问答机器人
FAQ问答机器人
- 0.Abstract
- 1.任务介绍
-
-
-
- 数据集
- 评估方法
- 测试集
-
-
- 2.使用ELMo预训练模型
- 3.使用BERT预训练模型
- 4.针对基线模型的分析思考以及可能的提升方向
- 5.BERT训练模型
-
-
-
- 1) 损失函数
- 2) 数据集构造
-
- 同义句(正例)的构造:
- 非同义句(负例)的构造:
- 3) 对于如何计算分数的探讨
-
-
- 6. 结论以及原因分析
- 7. 另外一些还没有实现的想法/可能的方向
-
-
-
- 1.模型本身结构的改进方向
- 2.采用静态Embedding
-
-
- 8. 上线优化问题
0.Abstract
本文实现了一个解决用户信息获取类的问答机器人, 通过问题匹配来寻找可能的最佳答案. 评估方法使用Mean Reciprocal Rank.
项目代码github地址: https://github.com/neesetifa/FAQbot
1.任务介绍
FAQ问答机器人通常有两种(闲聊类的机器人,比如微软小冰,n年前小黄鸡这种暂不讨论)
第一种, 任务驱动型. 此类问答机器人通常用于完成一些指定任务,比如订餐,订票,订单处理等(比如Macy’s的客服电话,打过的朋友会发现拨通后都是该类型的问答机器人帮你处理一些简单的订单问题)
第二种, 解决用户信息获取类的问题. 该类型机器人通过用户提出的问题/关键字, 寻找潜在的最佳答案返回给用户. 此类型是本文实现的问答机器人.
本文的基本思路是, 根据用户提出的问题,在已有的问题库里寻找和当前问题可能最相关的问题,将该问题的答案作为当前问题的答案提供给用户.
本项目中, 首先实验两个基线模型查看效果,分别是ELMo和BERT. 然后对BERT进行各种finetune(微调)尝试提高模型效果.
数据集
项目的数据集使用ChineseNLPCorpus提供的"法律知道"
https://github.com/SophonPlus/ChineseNlpCorpus
评估方法
本项目使用的评估方法是Mean Reciprocal Rank.
它的计算方式是根据当前结果在所有结果中的排名的倒数求和做平均.
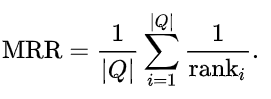
它的最大值是1. 即每个结果都在排名中被排在首位. 所以MRR值越大代表效果越好.
测试集
我自己造了一个数量为50条的测试数据集.
question为测试用问题(我提出的问题), title为对应匹配的问题(我认为应该匹配的问题).

2.使用ELMo预训练模型
尝试使用ELMo作为基线模型(base model)
(1)分词
使用ELMo模型,首先需要进行分词操作, 这里分词使用北大的分词工具pkuseg
import pkuseg
seg=pkuseg.pkuseg()
sents = ["今天天气真好啊", "潮水退了就知道谁没穿裤子"]
sents = [seg.cut(sent) for sent in sents]
print(sents)
# [['今天', '天气', '真', '好', '啊'], ['潮水', '退', '了', '就', '知道', '谁', '没', '穿', '裤子']]
(2) ELMo环境
使用ELMo需要安装allennlp环境. 不过因为allennlp提供的ELMo只支持英文,所以…
使用中文的话,需要额外安装这个库Pre-trained ELMo Representations for Many Languages
https://github.com/HIT-SCIR/ELMoForManyLangs
然后我们就可以使用了
from elmoformanylangs import Embedder #只需要用到Embedder
这个repository里还提供了预训练好的EMLo简体中文模型,可以直接下载使用.
如何加载预训练好的模型
e=Embedder('./zhs.model') #加载模型
# sents=[['今天', '天气', '真', '好', '啊'], ['潮水', '退', '了', '就', '知道', '谁', '没', '穿', '裤子']]
embeddings=e.sents2elmo(sents) #将句子embedding成向量,变量类型为numpy.ndarray
print(len(embeddings)) # 2 两个句子
print(embeddings[0].shape) # (5,1024) 句子1里有5个词,每个词是1024维的向量
(3) 将数据集里的每个问题全部都做embedding
然后将 “问题,问题的embedding,问题的答案” 存入一个文件
这里为了节省空间,对每句话的embedding做了平均
未做平均: 文件大小约800MB, 做完平均: 约89MB
实际效果: 两者区别不大
(4) 将输入的问题做embedding,然后和所有问题的embedding作对比, 对比方式使用cosine similarity, 取出相似度最高的5条问答,打印出来. 可以看到,在5条候选答案中,较为相关的回答还是很多的.

(5) 评估
ELMo模型的MRR约为 0.198
![]()
3.使用BERT预训练模型
尝试使用BERT作为基线模型(base model)
(1) BERT的中文预训练模型使用Cui Yimin提供的
https://github.com/ymcui/Chinese-BERT-wwm
(2)为了使用BERT对句子进行编码,这里借用并且修改了hugging face提供的代码.
https://github.com/huggingface/transformers/blob/master/examples/run_glue.py
我只使用了一个句子作为输入,即 [CLS]问题[SEP]None[SEP] 然后提取pooled_output来代表句子的向量, 使用cosine similarity作为评测分数
(3) 评估
BERT模型的MRR约为 0.183
![]()
BERT分数略低于ELMo
之后又测试了另一组数据,ELMo约为 0.203, BERT约为0.265.
4.针对基线模型的分析思考以及可能的提升方向
- 我发现构造测试数据集时, 问题的问法很有讲究,换一种问法模型可能就无法找到正确的答案. 模型在相同的句式以及较高的关键字匹配的情况下可以获得较高的分数, 而变化一种句型,比如原问题是"民事纠纷有哪些类型", 我提出的是"民事纠纷如何分类”, 模型便有可能无法匹配到正确答案.
- 同时我还发现, 在向模型提出毫不相关的问题时,模型给出的答案也会有非常高的分数:

这样也引出了一个提升方向: 增大和正例(同义句)的分数,减小和负例(非同义句)的分数.
下面我将从这个方向对BERT模型结构进行微调(fine-tune),从而使得它能够更加准确的判断两个句子的相似度.
5.BERT训练模型
这里需要先提一下,在思考的时候,看到的一篇对我有很大启发的论文: ParaNMT-50M
这篇论文是2018年4月写的,那时BERT尚未提出.下面是我对这篇论文的概述:
该论文提出了一个数据集, 由5000万条(50 million)英语-英语句子释义对(sentential paraphrase pairs)或者说同义句子对组成. 作者生成这个数据集的方法是,将英语翻译成捷克语,再把捷克语翻译回英语.
作者希望这个成为一个比较好的释义生成资源(释义生成,paraphrase generation, 是文本生成text generation的一个子任务). 并认为这么训练可以获得更好的句子表示(sentence embedding).
原论文里作者使用了WORD AVERAGING,TRIGRAM,LSTM三种模型. 我这里使用BERT代替.
1) 损失函数
下面这个式子是原论文里用的损失函数hinge loss/margin loss, cos()是计算cosine similarity
l o s s = m a x ( 0 , δ − c o s ( g s , g s ′ ) + c o s ( g s , g t ) ) loss=max(0, \delta-cos(g_s,g_{s'})+cos(g_s,g_{t})) loss=max(0,δ−cos(gs,gs′)+cos(gs,gt))
其中δ是margin,一个超参数,需要自己调整,不宜过大(模型不好训练),不宜过小(导致同义句和非同义句太接近).
gs是原句子的embedding, gs’是同义句(正例)的embedding, gt是非同义句(负例)的embedding. 我们希望cos(gs,gs’)越大越好, cos(gs,gt)越小越好
我同时也看了另一篇论文Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks,作者认为直接使用CLS token作为句子的表示并不是一个非常好的做法(其实没有关系,可以在这一步拿它作为sentence embedding输出到后一层, 因为我即将对这些句子做fine tune,但是我当时没有想到)
于是对于分数的计算,我进行了改动,采用BERT for sequence classification做法, 将输入的问题和已有的问题拼在一起,即 [CLS]输入问题[SEP]已有问题[SEP], 同样获取pooled_output, 过一个linear层得到一个分数,这里我称它为logits,把这个结果作为分数,于是损失函数变成:
l o s s = m a x ( 0 , δ − l o g i t s ( s , s ′ ) + l o g i t s ( s , t ) ) loss=max(0, \delta-logits(s,{s'})+logits(s,t)) loss=max(0,δ−logits(s,s′)+logits(s,t))
2) 数据集构造
数据集没有变. 但是由于损失函数里提出了正例和负例, 所以除了原本数据,我还需要构造这两项.
同义句(正例)的构造:
使用机翻, 中文翻译成英文,再翻译回中文,从而获得同义句.
由于此处没有其他较好的,我单独一个人能实践的方法, 所以同义句的构造方式始终没有变动.
非同义句(负例)的构造:
由于负例句有多种构造方式,以下每一条都是我的尝试和实验:
1.每一个epoch开始时,随机选择一个句子(只要不等同于当前句子)作为负例,和原句组成一对,送入模型.
这是最简单的方法.
def create_neg_examples(lines):
"""制作非同义句(负例),loss里的(s,t)"""
# 方法1:随机选择一个句子作为非同义句(只要不是原句即可))
examples = []
for (i, line_s) in enumerate(zip(lines)):
line_t = random.sample(lines, 1)[0]
while line_t == line_s:
line_t = random.sample(1)[0]
examples.append(InputExample(guid=0, text_a=line_s, text_b=line_t, label=1))
return examples
(在Tesla K80上运行, 每个epoch训练需要大约12~13分钟,我训练了10个epoch)
结果:比基线模型还要差,并且差的很多. 找到的答案完全牛头不对马嘴.
该模型的MRR:
mean reciprocal rank: 0.015638295060734434321
这样的结果等于模型完全找不到正确答案.
2.采用和原句分数最高的非同义句作为负例.
这样理论上负例句的质量更加高, 因为我们希望同义句分数越接近,并且和非同义句拉卡分数差距.
1 ) 查看数据集发现样本本身里有很多同义句, 比如有很多问题都类似是"聘请律师多少钱”, “单位拖欠工资怎么办”. 故尝试使用另外一个主题的数据集(这里采用"农行知道”)作为负例,以保证不会匹配到同义句.
def create_neg_examples_new(self,lines,neg_lines,args,model):
"""制作非同义句(负例),loss里的(s,t)"""
# 方法2:通过计算选择分数最接近的句子
neg_examples=[]
for (i,line_s) in enumerate(zip(lines)):
#这里有省略代码.
#最终目的是把原句和候选负例句配对构造成BERT的输入格式,然后进行分数计算
examples = [InputExample(guid=0, text_a=line_s, text_b=c, label=1) for c in neg_lines]
features = convert_examples_to_features(
examples)
dataset = TensorDataset(all_input_ids, all_attention_mask, all_token_type_ids)
#有单独的evaluate函数计算
scores = evaluate(self.args, self.model, dataset)
#对分数排序,选择最高的
index=scores.argsort()[::-1][0]
line_t=self.neg_candidate_title[index]
neg_examples.append(InputExample(guid=guid, text_a=line_s, text_b=line_t, label=1))
return neg_examples
产生问题: 训练速度过慢
直接拿每个句子比对18K条最符合的负例句,速度太慢.
比对一条就约需2分30秒, 每一条数据都需要和18K条负例比较.
即: 仅每条数据生成一个负例就需要45000分钟. 此方案不可行.
![]()
2) 尝试改进:
不使用额外数据, 只使用原数据,在每个batch里(32条)产生一个分数最高的非同义句(当然也存在一个batch里有同义句的风险), 产生一对正负例仍然需要约80分钟. 这个方法并没有解决训练速度太慢的缺点. 因此这个方案依旧不可行.
def create_neg_examples_new_2(self,lines,args,model):
"""制作非同义句(负例),loss里的(s,t)"""
# 方法3:通过计算选择分数最接近的句子, 但是只在每个batch里选择一个
neg_examples=[]
for (i,line_s) in enumerate(zip(lines)):
# 每次打乱顺序
neg_lines=np.array(lines.copy())
np.random.shuffle(neg_lines)
neg_lines=neg_lines[:self.args["batch_size"]]
examples = [InputExample(guid=0, text_a=line_s, text_b=c, label=1) for c in neg_lines]
features = convert_examples_to_features(
examples)
dataset = TensorDataset(all_input_ids, all_attention_mask, all_token_type_ids)
scores = evaluate(self.args, self.model, dataset)
#找到第一个不为原句的句子
line_t=None
for index in scores.argsort()[::-1]:
if self.candidate_title[index]!=line_s:
line_t=self.candidate_title[index]
break
neg_examples.append(InputExample(guid=guid, text_a=line_s, text_b=line_t, label=1))
return neg_examples
由于这个方法训练模型时间过长, 我没有训练完,因此也无法测试实际效果以及查看MRR.
3) 对于如何计算分数的探讨
我们先来分析下上述模型的缺点. 如果要使用最高分数作为产生负例的方法,同时又不降低训练速度, 我仍然需要使用cosine similarity作为分数.
同时由于寻找负例其实就是一个evaluate的过程, 使用这个方法在进行评估(比如MRR)时, 耗时会非常的长. 这样的响应速度完全不利于生产上线.
因此,仍然使用单句子送入BERT模型,即 [CLS]问题[SEP]None[SEP] (当然实际上是 [CLS]问题[SEP],因为如果是None的话,后面一个[SEP]实际上也没有了)
我们假设hidden_size是768
这里尝试了三种做法
- 直接使用CLS token的输出作为sentence embedding,这样一个句子表示的size是 1*hidden_size
- 在sequence output上做平均. 即 batch_size* seq_len* hidden_size, 在seq_len上做平均, 则变成 batch_size* hidden_size,这样每个句子的sentence embedding的size仍然为 1*hidden_size.
- 在sequence output上取max(想法来源于max pooling), 在seq_len上取max, 每个句子的sentence embedding的size仍然为 1*hidden_size.
对于负例产生的方式,我们使用上一小节中提到的改进方法, 在每个batch里找到和当前句子分数最高的非同义句.
实际运行: 内存消耗较大.每次iteration结束时候,内存使用率会上升到10GB左右.
设定: batch size=32, epoch=10. 每个epoch有约555次iteration.
运行速度: 由于采用了cosine similarity, 训练速度提升很大,每个epoch平均仅需9分钟左右.
![]()
效果:


虽然仍没有达到基线模型的效果,但是可以看到,比起上一种做法,模型已经能在一定程度上找到一些比较相关的答案,亦或者和原问题里某些关键字相有所匹配.
MRR:
-
CLS token法:
0.049930782590571869327 -
Sequence output MEAN法:
0.055437012918689191881 -
Sequence output MAX法:
0.042313965893476251369
6. 结论以及原因分析
最佳的分数计算方法: 使用单句子送入模型, 句子的表示使用Sequence output MEAN, 并用cosine similarity计算句子之间相似度.
最佳的负例产生方法: 在每个batch里寻找一个和当前句子分数最高的非同义句.
以上两种方式结合可以较为明显的提高模型效果和运行速度. 但效果仍然远不如基线模型, 因此目前结论是直接使用预训练模型效果最好. 但是有改进方式, 在下一节里会提到.
针对fine-tune后的模型效果差, 分析下来可能有以下几点比较关键:
1.在ParaNMT-50M这篇论文使用的数据量很大, 50 million. 而且无论是在论文标题,亦或是论文里都有反复强调. 我的数据量很小,只有17k. 联想BERT训练时也采用了大量的预料, 所以17k的量级可能完全达不到预期效果.
2.机器翻译回传翻译效果很差.有相当一部分句子回译后牛头不对马嘴, 完全没有达到最初目的(获得同义句). 因此在正例中本身就有大量错误的数据存在.
3.原数据也有一定的噪声, 比如我在测试时发现的原数据里的错别字. 这样也会相当影响到模型,因为模型并不认识错别字.

4.损失函数可能不适合用Hinge Loss.
7. 另外一些还没有实现的想法/可能的方向
1.模型本身结构的改进方向
仔细研读了Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks这篇论文后, 发现对于句子的表示(即sentence的embedding), 该论文没有提出什么较为新颖的办法, 仍然是使用[CLS] token或者在Sequence output上做平均. 主要是在损失函数上有所调整.
作者实验了三种方式, 一个是类似于Hinge Loss:
m a x ( ∣ ∣ s a − s p ∣ ∣ − ∣ s a − s n ∣ ∣ + ϵ , 0 ) max(||s_{a}-s_{p}||-|s_{a}-s_{n}||+\epsilon,0) max(∣∣sa−sp∣∣−∣sa−sn∣∣+ϵ,0)
其中sa,sp,sn分别是原句, 正例,负例的sentence embedding.
第二个和我一样是计算cosine similarity,只是损失函数用MSE.
第三个也是效果最好的一个, 首先用下面式子对两句句子做处理:
o = s o f t m a x ( W t ( c o n c a t ( u , v , ∣ u − v ∣ ) ) ) o=softmax(W_{t}(concat(u,v,|u-v|))) o=softmax(Wt(concat(u,v,∣u−v∣)))
其中u,v是两句句子的sentence embedding过了一个pooling层之后的结果(即第一第二种方式里的sentence embedding再过一个额外的pooling层). Wt是一个可训练的参数. 然后用cross entropy作为损失函数做分类.
我认为朝着这个方向再修改可能可以使模型效果有明显提升. 当然同时作者的训练数据集也非常大, 有5.7M条数据.
2.采用静态Embedding
最近有幸在一次面试时和一位面试官老师讨论了一下我模型的问题. 老师指出在数据量不足的情况下, 采用静态embedding(即word2vec或者glove)比动态embedding(ELMo以及BERT等)效果要好很多. 下一步尝试用word2vec做一下.
8. 上线优化问题
做的东西最终目的都是要上线的.
在原始代码里, 我采用的方法是让用户的问题和数据库里的问题逐一比较, 显然和库里每个问题都要比较一次, 至少要全部都扫一遍, 时间复杂度为O(n). 目前问题数量比较少, 几万条, 逐一比较时间并不长, 如果有几十万条甚至上百万条怎么办?
答案: 采用ANN(Approximate Nearest Neighbor)
(ANN知识待更新)