神经网络学习小记录59——Pytorch搭建常见分类网络平台(VGG16、MobileNetV2、ResNet50)
神经网络学习小记录59——Pytorch搭建常见分类网络平台(VGG16、MobileNetV2、ResNet50)
- 学习前言
- 源码下载
- 分类网络的常见形式
- 分类网络介绍
-
- 1、VGG16网络介绍
- 2、MobilenetV2网络介绍
- 3、ResNet50网络介绍
-
- a、什么是残差网络
- b、什么是ResNet50模型
- 分类网络的训练
-
- 1、LOSS介绍
- 2、利用分类网络进行训练
学习前言
才发现做了这么多的博客和视频,居然从来没有系统地做过分类网络,做一个科学的分类网络,对身体好。

源码下载
https://github.com/bubbliiiing/classification-pytorch
喜欢的可以点个star噢。
分类网络的常见形式
常见的分类网络都可以分为两部分,一部分是特征提取部分,另一部分是分类部分。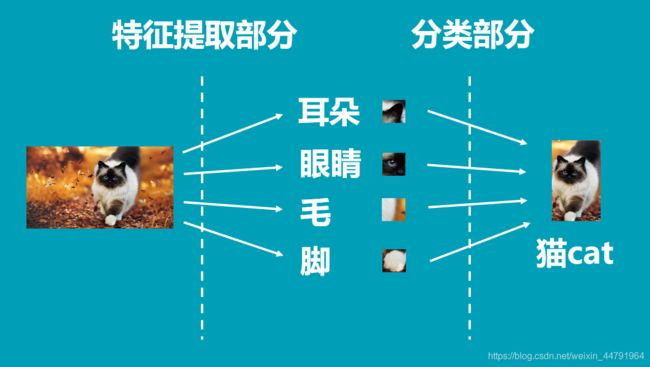
特征提取部分的功能是对输入进来的图片进行特征提取,优秀的特征可以帮助更容易区分目标,所以特征提取部分一般由各类卷积组成,卷积拥有强大的特征提取能力;
分类部分会利用特征提取部分获取到的特征进行分类,分类部分一般由全连接组成,特征提取部分获取到的特征一般是一维向量,可以直接进行全连接分类。
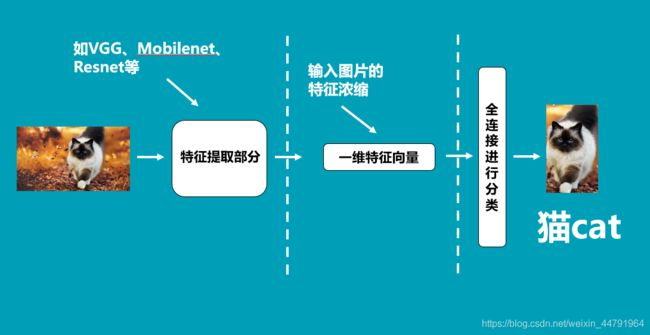
通常情况下,特征提取部分就是我们平常了解到的各种神经网络,比如VGG、Mobilenet、Resnet等等;而分类部分就是一次或者几次的全连接,最终我们会获得一个长度为num_classes的一维向量。
分类网络介绍
1、VGG16网络介绍
VGG是由Simonyan 和Zisserman在文献《Very Deep Convolutional Networks for Large Scale Image Recognition》中提出卷积神经网络模型,其名称来源于作者所在的牛津大学视觉几何组(Visual Geometry Group)的缩写。
该模型参加2014年的 ImageNet图像分类与定位挑战赛,取得了优异成绩:在分类任务上排名第二,在定位任务上排名第一。
它的结构如下图所示:
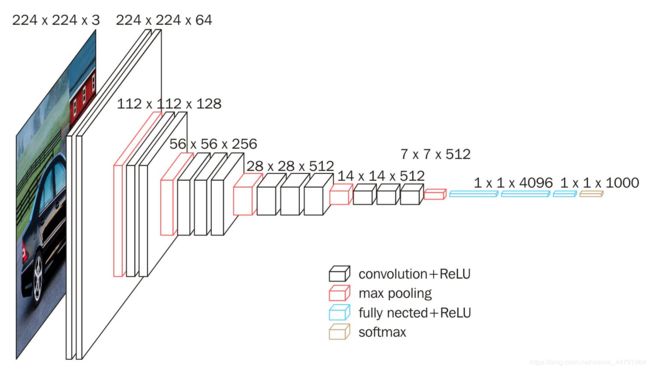
这是一个VGG16被用到烂的图,但确实很好的反应了VGG16的结构,整个VGG16由三种不同的层组成,分别是卷积层、最大池化层、全连接层。
VGG16的具体执行方式如下:
1、一张原始图片被resize到(224,224,3)。
2、conv1:进行两次[3,3]卷积网络,输出的特征层为64,输出为(224,224,64),再进行2X2最大池化,输出net为(112,112,64)。
3、conv2:进行两次[3,3]卷积网络,输出的特征层为128,输出net为(112,112,128),再进行2X2最大池化,输出net为(56,56,128)。
4、conv3:进行三次[3,3]卷积网络,输出的特征层为256,输出net为(56,56,256),再进行2X2最大池化,输出net为(28,28,256)。
5、conv4:进行三次[3,3]卷积网络,输出的特征层为512,输出net为(28,28,512),再进行2X2最大池化,输出net为(14,14,512)。
6、conv5:进行三次[3,3]卷积网络,输出的特征层为512,输出net为(14,14,512),再进行2X2最大池化,输出net为(7,7,512)。
7、对结果进行平铺。
8、进行两次神经元为4096的全连接层。
8、全连接到1000维上,用于进行分类。
最后输出的就是每个类的预测。
实现代码如下:
import torchvision
import torch
import torch.nn as nn
from torchvision.models.utils import load_state_dict_from_url
model_urls = {
'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth',
}
class VGG(nn.Module):
def __init__(self, features, num_classes=1000, init_weights=True):
super(VGG, self).__init__()
self.features = features
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def make_layers(cfg, batch_norm=False):
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
cfgs = {
'D': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
}
def vgg16(pretrained=False, progress=True, num_classes=1000):
model = VGG(make_layers(cfgs['D']))
if pretrained:
state_dict = load_state_dict_from_url(model_urls['vgg16'], model_dir='./model_data',
progress=progress)
model.load_state_dict(state_dict,strict=False)
if num_classes!=1000:
model.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
return model
2、MobilenetV2网络介绍
MobileNetV2是MobileNet的升级版,它具有一个非常重要的特点就是使用了Inverted resblock,整个mobilenetv2都由Inverted resblock组成。
Inverted resblock可以分为两个部分:
左边是主干部分,首先利用1x1卷积进行升维,然后利用3x3深度可分离卷积进行特征提取,然后再利用1x1卷积降维。
右边是残差边部分,输入和输出直接相接。

整体网络结构如下:(其中Inverted resblock进行的操作就是上述结构)

在利用特征提取部分完成输入图片的特征提取后,我们会利用全局平均池化将特征层调整成一个特征长条,我们可以将特征长条进行全连接,获得最终的分类结果。
实现代码如下:
from torch import nn
from torchvision.models.utils import load_state_dict_from_url
__all__ = ['MobileNetV2', 'mobilenet_v2']
model_urls = {
'mobilenet_v2': 'https://download.pytorch.org/models/mobilenet_v2-b0353104.pth',
}
def _make_divisible(v, divisor, min_value=None):
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
if new_v < 0.9 * v:
new_v += divisor
return new_v
class ConvBNReLU(nn.Sequential):
def __init__(self, in_planes, out_planes, kernel_size=3, stride=1, groups=1):
padding = (kernel_size - 1) // 2
super(ConvBNReLU, self).__init__(
nn.Conv2d(in_planes, out_planes, kernel_size, stride, padding, groups=groups, bias=False),
nn.BatchNorm2d(out_planes),
nn.ReLU6(inplace=True)
)
class InvertedResidual(nn.Module):
def __init__(self, inp, oup, stride, expand_ratio):
super(InvertedResidual, self).__init__()
self.stride = stride
assert stride in [1, 2]
hidden_dim = int(round(inp * expand_ratio))
self.use_res_connect = self.stride == 1 and inp == oup
layers = []
if expand_ratio != 1:
layers.append(ConvBNReLU(inp, hidden_dim, kernel_size=1))
layers.extend([
ConvBNReLU(hidden_dim, hidden_dim, stride=stride, groups=hidden_dim),
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
])
self.conv = nn.Sequential(*layers)
def forward(self, x):
if self.use_res_connect:
return x + self.conv(x)
else:
return self.conv(x)
class MobileNetV2(nn.Module):
def __init__(self, num_classes=1000, width_mult=1.0, inverted_residual_setting=None, round_nearest=8):
super(MobileNetV2, self).__init__()
block = InvertedResidual
input_channel = 32
last_channel = 1280
if inverted_residual_setting is None:
inverted_residual_setting = [
# t, c, n, s
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1],
]
if len(inverted_residual_setting) == 0 or len(inverted_residual_setting[0]) != 4:
raise ValueError("inverted_residual_setting should be non-empty "
"or a 4-element list, got {}".format(inverted_residual_setting))
input_channel = _make_divisible(input_channel * width_mult, round_nearest)
self.last_channel = _make_divisible(last_channel * max(1.0, width_mult), round_nearest)
features = [ConvBNReLU(3, input_channel, stride=2)]
for t, c, n, s in inverted_residual_setting:
output_channel = _make_divisible(c * width_mult, round_nearest)
for i in range(n):
stride = s if i == 0 else 1
features.append(block(input_channel, output_channel, stride, expand_ratio=t))
input_channel = output_channel
features.append(ConvBNReLU(input_channel, self.last_channel, kernel_size=1))
self.features = nn.Sequential(*features)
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(self.last_channel, num_classes),
)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def forward(self, x):
x = self.features(x)
x = x.mean([2, 3])
x = self.classifier(x)
return x
def mobilenet_v2(pretrained=False, progress=True, num_classes=1000):
model = MobileNetV2()
if pretrained:
state_dict = load_state_dict_from_url(model_urls['mobilenet_v2'], model_dir='./model_data',
progress=progress)
model.load_state_dict(state_dict)
if num_classes!=1000:
model.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(model.last_channel, num_classes),
)
return model
3、ResNet50网络介绍
a、什么是残差网络
Residual net(残差网络):
将靠前若干层的某一层数据输出直接跳过多层引入到后面数据层的输入部分。
意味着后面的特征层的内容会有一部分由其前面的某一层线性贡献。
其结构如下:
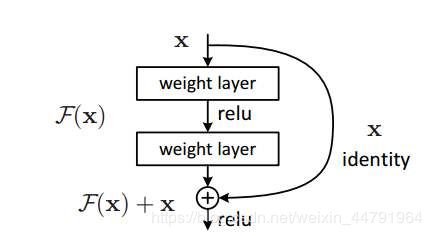
深度残差网络的设计是为了克服由于网络深度加深而产生的学习效率变低与准确率无法有效提升的问题。
b、什么是ResNet50模型
ResNet50有两个基本的块,分别名为Conv Block和Identity Block,其中Conv Block输入和输出的维度是不一样的,所以不能连续串联,它的作用是改变网络的维度;Identity Block输入维度和输出维度相同,可以串联,它的作用是加深网络的。
Conv Block的结构如下,由图可以看出,Conv Block可以分为两个部分,左边部分为主干部分,存在两次卷积、标准化、激活函数和一次卷积、标准化;右边部分为残差边部分,存在一次卷积、标准化,由于残差边部分存在卷积,所以我们可以利用Conv Block改变输出特征层的宽高和通道数:

Identity Block的结构如下,由图可以看出,Identity Block可以分为两个部分,左边部分为主干部分,存在两次卷积、标准化、激活函数和一次卷积、标准化;右边部分为残差边部分,直接与输出相接,由于残差边部分不存在卷积,所以Identity Block的输入特征层和输出特征层的shape是相同的,可用于加深网络:

Conv Block和Identity Block都是残差网络结构。
总的网络结构如下:

实现代码如下:
import torch
import torch.nn as nn
from torchvision.models.utils import load_state_dict_from_url
model_urls = {
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
}
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=False, dilation=dilation)
def conv1x1(in_planes, out_planes, stride=1):
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = conv3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000, zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None):
super(ResNet, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2,
dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], stride=2,
dilate=replace_stride_with_dilation[2])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def resnet50(pretrained=False, progress=True, num_classes=1000):
model = ResNet(Bottleneck, [3, 4, 6, 3])
if pretrained:
state_dict = load_state_dict_from_url(model_urls['resnet50'], model_dir='./model_data',
progress=progress)
model.load_state_dict(state_dict)
if num_classes!=1000:
model.fc = nn.Linear(512 * model.block.expansion, num_classes)
return model
分类网络的训练
1、LOSS介绍
一般而言,分类网络所使用的损失函数为交叉熵损失函数,英文名为Cross Entropy,实现公式如下。

其中:
- [ M M M] ——类别的数量;
- [ y i c y_{ic} yic] ——真实标签(0或1),当第i个样本属于c类时,值为1,否则为0;
- [ p i c p_{ic} pic] ——预测结果,第i个样本属于c类的预测概率;
- [ i i i] ——表示第几个样本。
2、利用分类网络进行训练
整个项目结构如下:
datasets文件夹下存放的是训练图片,分为两部分,train里面是训练图片,test里面是测试图片。
在训练之前需要首先准备好数据集,数据集格式为在train和test文件夹下分不同的文件夹,每个文件夹的名称为对应的类别名称,文件夹下面的图片为这个类的图片。

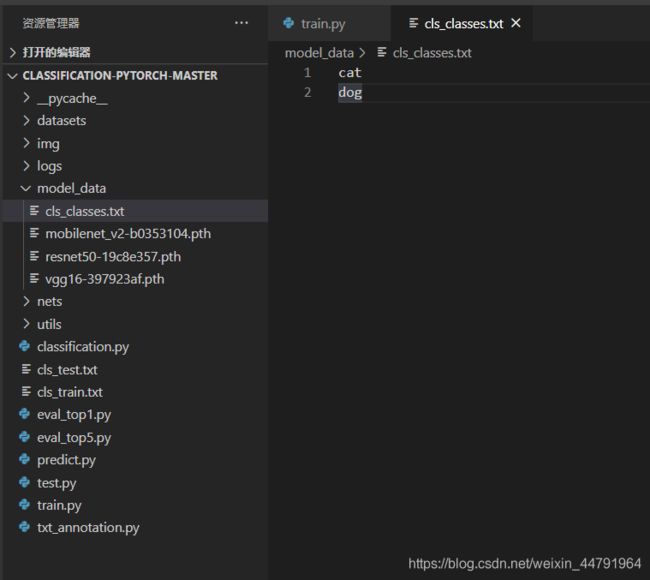
在准备好数据集后,需要在根目录运行txt_annotation.py生成训练所需的cls_train.txt,运行前需要修改其中的classes,将其修改成自己需要分的类。

之后修改model_data文件夹下的cls_classes.txt,使其也对应自己需要分的类。
在train.py里面调整自己要选择的网络和权重后,就可以开始训练了!
