多线程并发的一些解决思路
一、利用不变性解决并发问题
不变性(Immutability)模式。所谓不变性,简单来讲,就是对象一旦被创建之后,状态就不再发生变化。换句话说,就是变量一旦被赋值,就不允许修改了(没有写操作);没有修改操作,也就是保持了不变性。
可以将一个类所有的属性都设置成 final 的,并且只允许存在只读方法,那么这个类基本上就具备不可变性了。
Java SDK 里很多类都具备不可变性,例如经常用到的 String 和 Long、Integer、Double 等基础类型的包装类都具备不可变性,这些对象的线程安全性都是靠不可变性来保证的。他们都遵守不可变类的三点要求:类和属性都是 final 的,所有方法均是只读的。
**享元模式(Flyweight Pattern)。利用享元模式可以减少创建对象的数量,从而减少内存占用。**Java 语言里面 Long、Integer、Short、Byte 等这些基本数据类型的包装类都用到了享元模式。
享元模式本质上其实就是一个对象池,利用享元模式创建对象的逻辑也很简单:创建之前,首先去对象池里看看是不是存在;如果已经存在,就利用对象池里的对象;如果不存在,就会新创建一个对象,并且把这个新创建出来的对象放进对象池里。
Long 这个类并没有照搬享元模式,Long 内部维护了一个静态的对象池,仅缓存了 [-128,127] 之间的数字,这个对象池在 JVM 启动的时候就创建好了,而且这个对象池一直都不会变化,也就是说它是静态的。是因为 Long 这个对象的状态种类,实在太多,不宜全部缓存,而 [-128,127] 之间的数字利用率最高。
“Integer 和 String 类型的对象不适合做锁”,其实基本上所有的基础类型的包装类都不适合做锁,因为它们内部用到了享元模式,这会导致看上去私有的锁,其实是共有的。
在使用 Immutability 来解决并发问题的时候,需要注意以下两点:
- 对象的所有属性都是 final 的,并不能保证不可变性;
- 不可变对象也需要正确发布。
final 修饰的属性一旦被赋值,就不可以再修改,但是如果属性的类型是普通对象,那么这个普通对象的属性是可以被修改的。所以,在使用 Immutability 模式的时候一定要确认保持不变性的边界在哪里,是否要求属性对象也具备不可变性。
在多线程领域,无状态对象(无状态对象内部没有属性,只有方法)没有线程安全问题,无需同步处理,自然性能很好;在分布式领域,无状态意味着可以无限地水平扩展,所以分布式领域里面性能的瓶颈一定不是出在无状态的服务节点上。
二、利用copy-on-write来解决并发问题
Java 里 String 这个类在实现 replace() 方法的时候,并没有更改原字符串里面 value[] 数组的内容,而是创建了一个新字符串,这种方法在解决不可变对象的修改问题时经常用到,就是Coyp-On-Write 即写时复制。
CopyOnWriteArrayList 和 CopyOnWriteArraySet 这两个 Copy-on-Write 容器,它们背后的设计思想就是 Copy-on-Write;通过 Copy-on-Write 这两个容器实现的读操作是无锁的,由于无锁,所以将读操作的性能发挥到了极致。
Copy-on-Write 是一项非常通用的技术方案,在很多领域都有着广泛的应用。不过,它也有缺点的,那就是消耗内存,每次修改都需要复制一个新的对象出来,好在随着自动垃圾回收(GC)算法的成熟以及硬件的发展,这种内存消耗已经渐渐可以接受了。所以在实际工作中,如果写操作非常少,那你就可以尝试用一下 Copy-on-Write,效果还是不错的。
三、利用线程本地存储解决并发问题
多个线程同时读写同一共享变量存在并发问题。如果没有共享写操作自然没有并发问题了。其实还可以突破共享变量,没有共享变量也不会有并发问题,正所谓是没有共享,就没有伤害。Java 语言提供的线程本地存储(ThreadLocal)通过线程封闭就能够做到局部变量的避免共享。
static class SafeDateFormat {
// 定义 ThreadLocal 变量
static final ThreadLocal tl=ThreadLocal.withInitial(
()-> new SimpleDateFormat( "yyyy-MM-dd HH:mm:ss"));
static DateFormat get(){
return tl.get();
}
}
// 不同线程执行下面代码
// 返回的 df 是不同的
DateFormat df = SafeDateFormat.get();
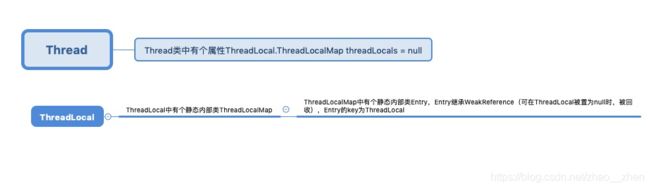
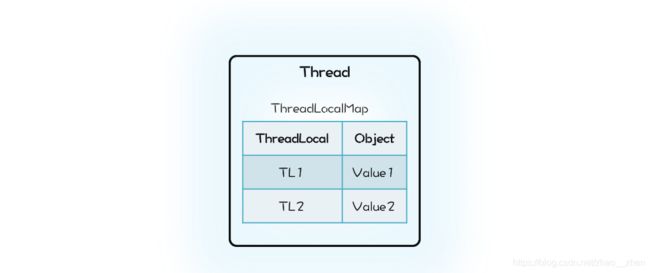
Java 的实现里面也有一个 Map,叫做 ThreadLocalMap,不过持有 ThreadLocalMap 的不是 ThreadLocal,而是 Thread。Thread 这个类内部有一个私有属性 threadLocals,其类型就是 ThreadLocalMap,ThreadLocalMap 的 Key 是 ThreadLocal。hreadLocal 仅仅是一个代理工具类,内部并不持有任何与线程相关的数据,所有和线程相关的数据都存储在 Thread 里面。而从数据的亲缘性上来讲,ThreadLocalMap 属于 Thread 也更加合理。
在使用的时候,其实每个线程内部都会维护一个ThreadLocalMap属性,每份线程独自的数据都存放在ThreadLocalMap中Entry[] table属性里,Entry对象的key就是ThreadLocal,value就是自己设置的值,如果程序里有多个ThreadLocal属性,每个线程在运行时会将用到ThreadLocal,生成Entry保存到table中,有点需要注意的是同一个Entry中value重新设置会被替换,如Entry
InheritableThreadLocal 与继承性
通过 ThreadLocal 创建的线程变量,其子线程是无法继承的。也就是说你在线程中通过 ThreadLocal 创建了线程变量 V,而后该线程创建了子线程,你在子线程中是无法通过 ThreadLocal 来访问父线程的线程变量 V 的。
如果你需要子线程继承父线程的线程变量,那该怎么办呢?其实很简单,Java 提供了 InheritableThreadLocal 来支持这种特性,InheritableThreadLocal 是 ThreadLocal 子类,所以用法和 ThreadLocal 相同.
四、Guarded Suspension模式:等待唤醒机制
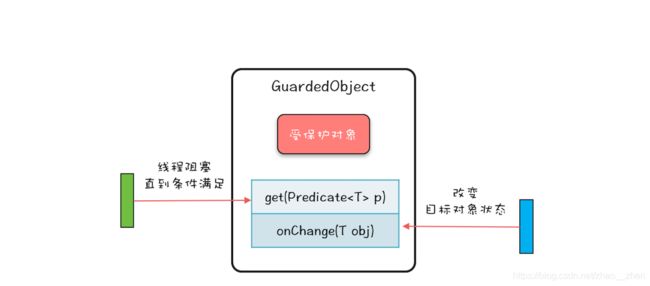
Guarded Suspension 模式本质上是一种等待唤醒机制的实现,只不过 Guarded Suspension 模式将其规范化了。规范化的好处是你无需重头思考如何实现,也无需担心实现程序的可理解性问题,同时也能避免一不小心写出个 Bug 来。但 Guarded Suspension 模式在解决实际问题的时候,往往还是需要扩展的。
五、Balking 模式
某个共享变量是一个状态变量,业务逻辑依赖于这个状态变量的状态:当状态满足某个条件时,执行某个业务逻辑,其本质其实不过就是一个 if 而已,放到多线程场景里,就是一种“多线程版本的 if”。这种“多线程版本的 if”的应用场景还是很多的,所以也有人把它总结成了一种设计模式,叫做Balking 模式。
使用 Balking 模式规范化之后的写法如下所示,你会发现仅仅是将 edit() 方法中对共享变量 changed 的赋值操作抽取到了 change() 中,这样的好处是将并发处理逻辑和业务逻辑分开。
boolean changed=false;
// 自动存盘操作
void autoSave(){
synchronized(this){
if (!changed) {
return;
}
changed = false;
}
// 执行存盘操作
// 省略且实现
this.execSave();
}
// 编辑操作
void edit(){
// 省略编辑逻辑
......
change();
}
// 改变状态
void change(){
synchronized(this){
changed = true;
}
}
六、Thread-Per-Message模式
并发编程领域的问题总结为三个核心问题:分工、同步和互斥。其中,同步和互斥相关问题更多地源自微观,而分工问题则是源自宏观。我们解决问题,往往都是从宏观入手,在编程领域,软件的设计过程也是先从概要设计开始,而后才进行详细设计。解决并发编程问题,首要问题也是解决宏观的分工问题。并发编程领域里,解决分工问题也有一系列的设计模式,比较常用的主要有 Thread-Per-Message 模式、Worker Thread 模式、生产者 - 消费者模式等等。今天我们重点介绍 Thread-Per-Message 模式。
这种委托他人办理的方式,在并发编程领域被总结为一种设计模式,叫做Thread-Per-Message 模式,简言之就是为每个任务分配一个独立的线程。这是一种最简单的分工方法,实现起来也非常简单。
final ServerSocketChannel ssc = ServerSocketChannel.open().bind(new InetSocketAddress(8080));
// 处理请求
try {
while (true) {
// 接收请求
SocketChannel sc = ssc.accept();
// 每个请求都创建一个线程
new Thread(()->{
try {
// 读 Socket
ByteBuffer rb = ByteBuffer .allocateDirect(1024);
sc.read(rb);
// 模拟处理请求
Thread.sleep(2000);
// 写 Socket
ByteBuffer wb = (ByteBuffer)rb.flip();
sc.write(wb);
// 关闭 Socket
sc.close();
}catch(Exception e){
throw new UncheckedIOException(e);
}
}).start();
}
} finally {
ssc.close();
}
Java 中的线程是一个重量级的对象,创建成本很高,一方面创建线程比较耗时,另一方面线程占用的内存也比较大。所以,为每个请求创建一个新的线程并不适合高并发场景。
七、 Worker Thread 模式
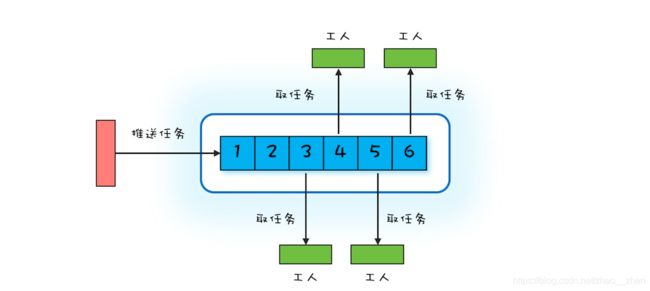
Worker Thread 模式中Worker Thread 对应到现实世界里,其实指的就是车间里的工人。可以用线程池来实现。
ExecutorService es = Executors.newFixedThreadPool(500);
final ServerSocketChannel ssc = ServerSocketChannel.open().bind(new InetSocketAddress(8080));
// 处理请求
try {
while (true) {
// 接收请求
SocketChannel sc = ssc.accept();
// 将请求处理任务提交给线程池
es.execute(()->{
try {
// 读 Socket
ByteBuffer rb = ByteBuffer.allocateDirect(1024);
sc.read(rb);
// 模拟处理请求
Thread.sleep(2000);
// 写 Socket
ByteBuffer wb = (ByteBuffer)rb.flip();
sc.write(wb);
// 关闭 Socket
sc.close();
}catch(Exception e){
throw new UncheckedIOException(e);
}
});
}
} finally {
ssc.close();
es.shutdown();
}
使用线程池过程中,还要注意一种线程死锁的场景。如果提交到相同线程池的任务不是相互独立的,而是有依赖关系的,那么就有可能导致线程死锁。当应用出现类似问题时,首选的诊断方法是查看线程栈。同时也可以用过保证相同线程池中的任务一定相互独立和为不同的任务创建不同的线程池来进行避免。
八、线程停止的两阶段终止策略
顾名思义,就是将终止过程分成两个阶段,其中第一个阶段主要是线程 T1 向线程 T2发送终止指令,而第二阶段则是线程 T2响应终止指令。
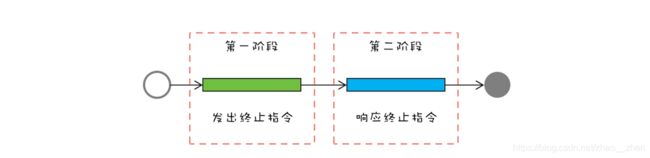
通过我们对Java中线程状态的了解,让线程从Runnable状态才能进入terminated状态,如果线程处在休眠状态则需要将线程的状态从休眠转换到Runnable状态。上面这个过程可以通过interrupt()方法,它可以将休眠状态的线程转换到 RUNNABLE 状态。之后就是如何让Java 线程自己执行完 run() 方法,一般我们采用的方法是设置一个标志位,然后线程会在合适的时机检查这个标志位,如果发现符合终止条件,则自动退出 run() 方法。这个过程其实就是我们前面提到的第二阶段:响应终止指令。具体示例如下:
class Proxy {
// 线程终止标志位
volatile boolean terminated = false;
boolean started = false;
// 采集线程
Thread rptThread;
// 启动采集功能
synchronized void start(){
// 不允许同时启动多个采集线程
if (started) {
return;
}
started = true;
terminated = false;
rptThread = new Thread(()->{
while (!terminated){
// 省略采集、回传实现
report();
// 每隔两秒钟采集、回传一次数据
try {
Thread.sleep(2000);
} catch (InterruptedException e){
// 重新设置线程中断状态
Thread.currentThread().interrupt();
}
}
// 执行到此处说明线程马上终止
started = false;
});
rptThread.start();
}
// 终止采集功能
synchronized void stop(){
// 设置中断标志位
terminated = true;
// 中断线程 rptThread
rptThread.interrupt();
}
}
在线程池中的时候,可以使用**shutdown()和shutdownNow()**这两个方法来进行实现。
shutdown() 方法是一种很保守的关闭线程池的方法。线程池执行 shutdown() 后,就会拒绝接收新的任务,但是会等待线程池中正在执行的任务和已经进入阻塞队列的任务都执行完之后才最终关闭线程池。shutdown()调用后,还要再调用awaitTermination方法等待一点时间,线程池里的线程才会终止。
而 shutdownNow() 方法,相对就激进一些了,线程池执行 shutdownNow() 后,会拒绝接收新的任务,同时还会中断线程池中正在执行的任务,已经进入阻塞队列的任务也被剥夺了执行的机会,不过这些被剥夺执行机会的任务会作为shutdownNow() 方法的返回值返回。因为 shutdownNow() 方法会中断正在执行的线程,所以提交到线程池的任务,如果需要优雅地结束,就需要正确地处理线程中断。
使用毒丸对象也能够起到结束线程的作用。
生产者-消费者模式
生产者 - 消费者模式的核心是一个任务队列,生产者线程生产任务,并将任务添加到任务队列中,而消费者线程从任务队列中获取任务并执行。

从架构设计的角度来看,生产者 - 消费者模式有一个很重要的优点,就是解耦。解耦对于大型系统的设计非常重要,而解耦的一个关键就是组件之间的依赖关系和通信方式必须受限。在生产者 - 消费者模式中,生产者和消费者没有任何依赖关系,它们彼此之间的通信只能通过任务队列,所以生产者 - 消费者模式是一个不错的解耦方案。
生产者 - 消费者模式还有一个重要的优点就是支持异步,并且能够平衡生产者和消费者的速度差异。在生产者 - 消费者模式中,生产者线程只需要将任务添加到任务队列而无需等待任务被消费者线程执行完。
同时使用生产者 - 消费者模式还能够支持批量执行以提升性能。
而且支持分阶段提交。利用生产者 - 消费者模式还可以轻松地支持一种分阶段提交的应用场景。我们知道写文件如果同步刷盘性能会很慢,所以对于不是很重要的数据,我们往往采用异步刷盘的方式。
Java 语言提供的线程池本身就是一种生产者 - 消费者模式的实现,但是线程池中的线程每次只能从任务队列中消费一个任务来执行,对于大部分并发场景这种策略都没有问题。但是有些场景还是需要自己来实现,例如需要批量执行以及分阶段提交的场景。
在分布式场景下,可以借助分布式消息队列(MQ)来实现生产者 - 消费者模式。MQ 一般都会支持两种消息模型,一种是点对点模型,一种是发布订阅模型。这两种模型的区别在于,点对点模型里一个消息只会被一个消费者消费,和 Java 的线程池非常类似(Java 线程池的任务也只会被一个线程执行);而发布订阅模型里一个消息会被多个消费者消费,本质上是一种消息的广播,在多线程编程领域,可以结合观察者模式实现广播功能。