计算机视觉&深度学习
计算机视觉
计算机视觉定义
1.人们希望它能够模仿人类的视觉系统
2.作为人工智能的基石
3.从视频、图像中提取信息
主要应用
1.图像分类
2.目标检测
2.目标追踪
3.风格迁移
4.超像素
5.图像拼接
6.语义分割
7.人脸识别
8…
c++ and opencv 下计算机视觉基本实现
1.利用摄像头采集图像并实时对图像中物体进行边缘提取
程序实现:
#include
#include
#include
#include
using namespace cv;
using namespace std;
void trackBar(int, void*);
int s1 = 0, s2 = 0;
Mat src, dst,frame;
int main(){// 读入一张图片(demo)
Mat img = imread("D:\\software\\m\\ConsoleApplication1\\ConsoleApplication1\\1.jpg");// 创建一个名为 "demo"窗口 ?
cvNamedWindow("baby");// 在窗口中显示
//imshow("baby", img);// 等待6000 ms后窗口自动关闭 ?
//waitKey(6000);
//Mat frame;
VideoCapture cap(0);
if (!cap.isOpened()){
cout << "can't open camera\n" << endl;
return 0;
}
while (1)
{
cap >> frame;
imshow("baby", frame);
Canny(frame, dst, 300, 100, 3);
imshow("canny", dst);
//waitKey(60);
if (waitKey(20) > 0)//按下任意键退出摄像头 因电脑环境而异,有的电脑可能会出现一闪而过的情况
break;
}
cap.release();
cv::destroyAllWindows();//关闭所有窗口
}
代码解析:前面半段是利用opencv读取图像并将其显示到界面(显示时间设置为6秒)用于测试。后面利用打开摄像头设备,将摄像头读取图像实时的显示到“baby"窗口中,,然后利用canny对其进行边缘提取并显示,每隔20ms显示窗口刷新依次,如果遇到按下任意按键即可退出。最后关闭摄像头和所有窗口。
2.图像的拼接
代码实现
#include
#include
#include
#include
#include
using namespace std;
using namespace cv;
bool try_use_gpu = true;
vector imgs;
string result_name = "D:\\a\\j.jpg";
int main(int argc, char * argv[])
{
Mat img1 = imread("D:\\a\\z.jpg");
Mat img2 = imread("D:\\a\\x.jpg");
Mat img3 = imread("D:\\a\\q.jpg");
imshow("p1", img1);
imshow("p2", img2);
imshow("p3", img3);
if (img1.empty() || img2.empty())
{
cout << "Can't read image" << endl;
return -1;
}
imgs.push_back(img1);
imgs.push_back(img2);
imgs.push_back(img3);
Stitcher stitcher = Stitcher::createDefault(try_use_gpu);
//使用stitch函数进行拼接
Mat pano;
Stitcher::Status status = stitcher.stitch(imgs, pano);
if (status != Stitcher::OK)
{
cout << "Can't stitch images, error code = " << int(status) << endl;
return -1;
}
imwrite(result_name, pano);
Mat pano2 = pano.clone();
// 显示源图像,和结果图像
imshow("全景图像", pano);
if (waitKey() == 27)
return 0;
}
代码解析:读取所要拼接的图片,将要拼接的图片放入到一个vector容器中,switcher这个类可以实现gpu的加速,并利用switch函数完成图像的拼接,并将其写到定义的文件中。
利用其他算法完成图像的拼接
#include "opencv2/opencv.hpp"
#include
#include //SIFT
#include //BFMatch暴力匹配
#include
#include
#include
#include
#include
#include
#include
using namespace std;
using namespace cv;
void OptimizeSeam(Mat& img1, Mat& trans, Mat& dst);
typedef struct
{
Point2f left_top;
Point2f left_bottom;
Point2f right_top;
Point2f right_bottom;
}four_corners_t;
four_corners_t corners;
void CalcCorners(const Mat& H, const Mat& src)
{
double v2[] = { 0, 0, 1 };//左上角
double v1[3];//变换后的坐标值
Mat V2 = Mat(3, 1, CV_64FC1, v2); //列向量
Mat V1 = Mat(3, 1, CV_64FC1, v1); //列向量
V1 = H * V2;
//左上角(0,0,1)
cout << "V2: " << V2 << endl;
cout << "V1: " << V1 << endl;
corners.left_top.x = v1[0] / v1[2];
corners.left_top.y = v1[1] / v1[2];
//左下角(0,src.rows,1)
v2[0] = 0;
v2[1] = src.rows;
v2[2] = 1;
V2 = Mat(3, 1, CV_64FC1, v2); //列向量
V1 = Mat(3, 1, CV_64FC1, v1); //列向量
V1 = H * V2;
corners.left_bottom.x = v1[0] / v1[2];
corners.left_bottom.y = v1[1] / v1[2];
//右上角(src.cols,0,1)
v2[0] = src.cols;
v2[1] = 0;
v2[2] = 1;
V2 = Mat(3, 1, CV_64FC1, v2); //列向量
V1 = Mat(3, 1, CV_64FC1, v1); //列向量
V1 = H * V2;
corners.right_top.x = v1[0] / v1[2];
corners.right_top.y = v1[1] / v1[2];
//右下角(src.cols,src.rows,1)
v2[0] = src.cols;
v2[1] = src.rows;
v2[2] = 1;
V2 = Mat(3, 1, CV_64FC1, v2); //列向量
V1 = Mat(3, 1, CV_64FC1, v1); //列向量
V1 = H * V2;
corners.right_bottom.x = v1[0] / v1[2];
corners.right_bottom.y = v1[1] / v1[2];
}
void OptimizeSeam(Mat& img1, Mat& trans, Mat& dst)
{
int start = MIN(corners.left_top.x, corners.left_bottom.x);//开始位置,即重叠区域的左边界
double processWidth = img1.cols - start;//重叠区域的宽度
int rows = dst.rows;
int cols = img1.cols; //注意,是列数*通道数
double alpha = 1;//img1中像素的权重
for (int i = 0; i < rows; i++)
{
uchar* p = img1.ptr(i); //获取第i行的首地址
uchar* t = trans.ptr(i);
uchar* d = dst.ptr(i);
for (int j = start; j < cols; j++)
{
//如果遇到图像trans中无像素的黑点,则完全拷贝img1中的数据
if (t[j * 3] == 0 && t[j * 3 + 1] == 0 && t[j * 3 + 2] == 0)
{
alpha = 1;
}
else
{
//img1中像素的权重,与当前处理点距重叠区域左边界的距离成正比,实验证明,这种方法确实好
alpha = (processWidth - (j - start)) / processWidth;
}
d[j * 3] = p[j * 3] * alpha + t[j * 3] * (1 - alpha);
d[j * 3 + 1] = p[j * 3 + 1] * alpha + t[j * 3 + 1] * (1 - alpha);
d[j * 3 + 2] = p[j * 3 + 2] * alpha + t[j * 3 + 2] * (1 - alpha);
}
}
}
int main()
{
Mat srcImg11 = imread("D:\\a\\x.jpg", 1); //Sift surf
Mat srcImg21 = imread("D:\\a\\z.jpg", 1);
//定义SIFT特征检测类对象
Mat srcImg1, srcImg2;
cvtColor(srcImg11, srcImg1, CV_RGB2GRAY);
cvtColor(srcImg21, srcImg2, CV_RGB2GRAY);
SiftFeatureDetector Detector(2000);
vector keyPoints1, keyPoints2;
Detector.detect(srcImg1, keyPoints1);
Detector.detect(srcImg2, keyPoints2);
//cout << 2 << endl;
//绘制特征点(关键点)
Mat feature_pic1, feature_pic2;
drawKeypoints(srcImg11, keyPoints1, feature_pic1, Scalar::all(-1));
drawKeypoints(srcImg21, keyPoints2, feature_pic2, Scalar::all(-1));
imshow("p1", feature_pic1);
cout << keyPoints1.size();
//计算特征点描述符 / 特征向量提取
SiftDescriptorExtractor Descriptor;
Mat description1, description2;
Descriptor.compute(srcImg1, keyPoints1, description1);
Descriptor.compute(srcImg2, keyPoints2, description2);
FlannBasedMatcher matcher;
vector > matchePoints;
vector GoodMatchePoints;
vector imagePoints1, imagePoints2;
vector train_desc(1, description1);
matcher.add(train_desc);
matcher.train();
matcher.knnMatch(description2, matchePoints, 2);
cout << "total match points: " << matchePoints.size() << endl;
// Lowe's algorithm,获取优秀匹配点
for (int i = 0; i < matchePoints.size(); i++)
{
if (matchePoints[i][0].distance < 0.4 * matchePoints[i][1].distance)
{
GoodMatchePoints.push_back(matchePoints[i][0]);
}
}
cout << GoodMatchePoints.size() << endl;
Mat result;
drawMatches(srcImg21, keyPoints2, srcImg11, keyPoints1, GoodMatchePoints, result, Scalar(0, 255, 0), Scalar::all(-1));//匹配特征点绿色,单一特征点颜色随机
imwrite("romasiftmatchpoints.jpg", result);
imshow("Match_Result", result);
for (int i = 0; i 代码解析:拼接的依据在于相邻两张图片的特征点,特征点的筛选可以用SIFF,SURF,以及ORB等算法找两张图像的特征点。首先将图片转化为灰度图,然后选取好的特征点,然后计算转换矩阵,然后利用直接透视变换,实现两张图的拼接,拼接后需要将图像融合,去掉缝隙。
3.人脸检测
#include "opencv2/opencv.hpp"
#include
using namespace std;
using namespace cv;
//#define DETECT_BUFFER_SIZE 0x20000
int main()
{
int * pResults = NULL;
//在检测函数中使用了pBuffer。
//如果你调用多个线程中的函数,请为每个线程创建一个缓冲区!
unsigned char * pBuffer = (unsigned char *)malloc(0x20000);
if (!pBuffer)
{
fprintf(stderr, "Can not alloc buffer.\n");
return -1;
}
Mat src = imread("m.jpg");
Mat gray;
cvtColor(src, gray, CV_BGR2GRAY);
int doLandmark = 1;// do landmark detection
pResults = facedetect_multiview_reinforce(pBuffer, (unsigned char*)(gray.ptr(0)), gray.cols, gray.rows, (int)gray.step,
1.2f, 2, 48, 0, doLandmark);
//打印检测结果
for (int i = 0; i < (pResults ? *pResults : 0); i++)
{
short * p = ((short*)(pResults + 1)) + 142 * i;
rectangle(src, Rect(p[0], p[1], p[2], p[3]), Scalar(0, 255, 0), 2);
if (doLandmark)
{
for (int j = 0; j < 68; j++)
circle(src, Point((int)p[6 + 2 * j], (int)p[6 + 2 * j + 1]), 1, Scalar(0, 0, 255), 2);
}
}
imshow("Show", src);
imwrite("3d.jpg", src);
waitKey(0);
}
代码解析:将输入的图像或可以利用摄像头采集图像,然后检测人脸,并将其框出。
4.在目标图的指定位置放入某一大小的原图
#include
using namespace cv;
using namespace std;
struct userdata{
Mat im;
vector points;
};
void mouseHandler(int event, int x, int y, int flags, void* data_ptr)
{
if (event == EVENT_LBUTTONDOWN)
{
userdata *data = ((userdata *)data_ptr);
circle(data->im, Point(x, y), 3, Scalar(0, 255, 255), 5, CV_AA);
imshow("Image", data->im);
if (data->points.size() < 4)
{
data->points.push_back(Point2f(x, y));
}
}
}
int main(int argc, char** argv)
{
// Read in the image.
Mat im_src = imread("D:\\a\\o.jpg");
Size size = im_src.size();
// Create a vector of points.
vector pts_src;
pts_src.push_back(Point2f(0, 0));
pts_src.push_back(Point2f(size.width - 1, 0));
pts_src.push_back(Point2f(size.width - 1, size.height - 1));
pts_src.push_back(Point2f(0, size.height - 1));
// Destination image
Mat im_dst = imread("D:\\a\\p.jpg");
// Set data for mouse handler
Mat im_temp = im_dst.clone();
userdata data;
data.im = im_temp;
//show the image
imshow("Image", im_temp);
cout << "Click on four corners of a billboard and then press ENTER" << endl;
//set the callback function for any mouse event
setMouseCallback("Image", mouseHandler, &data);
waitKey(0);
// Calculate Homography between source and destination points
Mat h = findHomography(pts_src, data.points);
// Warp source image
warpPerspective(im_src, im_temp, h, im_temp.size());
// Extract four points from mouse data
Point pts_dst[4];
for (int i = 0; i < 4; i++)
{
pts_dst[i] = data.points[i];
}
// Black out polygonal area in destination image.
fillConvexPoly(im_dst, pts_dst, 4, Scalar(0), CV_AA);
imshow("Image1",im_dst);
// Add warped source image to destination image.
im_dst = im_dst + im_temp;
// Display image.
imshow("Image", im_dst);
waitKey(0);
return 0;
}
代码解析:实现利用鼠标,点中目标图的四个点,这四个点的构成的区域由原图来填充到此处。实现的过程包括,点击事件,对应图像的坐标变换,通过投射变换,然后将两者叠起来,就形成变换以后的图。
计算机视觉一些基础以及Opencv使用(python)
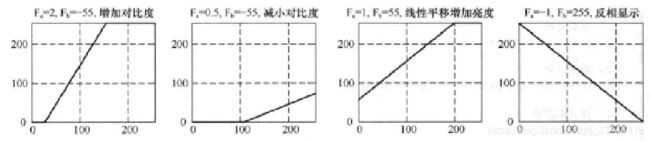
1.图像的线性变换与灰度直方图
import cv2
import numpy as np
from matplotlib import pyplot as plt
from matplotlib import pyplot as plt
img = cv2.imread("D:\\software\\m\\ConsoleApplication1\\ConsoleApplication1\\1.jpg",0) # 不加0默认是彩色,否则是灰度
print(img.shape)
cv2.imshow("original",img)
#img1 = np.dot(2,img) +3
img1 = [[]]
plt.hist(img.ravel() , 256, [0, 256])
plt.show()
for i in range(len(img)):
for j in range(len(img[i])):
img[i][j] = img[i][j]*(100)+3; # img[i][j][0]
if(img[i][j]>255):
img[i][j]=255
elif(img[i][j] <= 0):
img[i][j] = 0
cv2.imshow("a",img)
plt.hist(img.ravel() , 256, [0, 256])
plt.show()
print(type(img))
cv2.waitKey(1000000000)
代码解析:实现图像的灰度增强(系数为3 ),增强图像对比度(系数为100)。限定范围防止溢出范围。
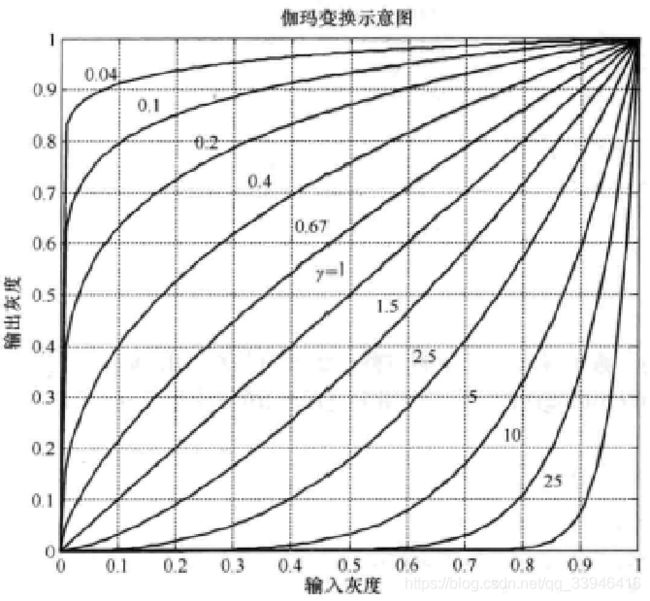
2.图像的gama变换

import cv2
import numpy as np
from matplotlib import pyplot as plt
from matplotlib import pyplot as plt
img = cv2.imread("D:\\software\\m\\ConsoleApplication1\\ConsoleApplication1\\1.jpg",0) # 不加0默认是彩色,否则是灰度
print(img.shape)
cv2.imshow("original",img)
#img1 = np.dot(2,img) +3
img1 = [[]]
plt.hist(img.ravel() , 256, [0, 256])
plt.show()
def gamma_trans(img,gamma):
#具体做法先归一化到1,然后gamma作为指数值求出新的像素值再还原
gamma_table = [np.power(x/255.0,gamma)*255.0 for x in range(256)]
gamma_table = np.round(np.array(gamma_table)).astype(np.uint8)
return cv2.LUT(img, gamma_table)
dst = gamma_trans(img,3)
cv2.imshow("a",dst)
plt.hist(dst.ravel() , 256, [0, 256])
plt.show()
print(type(img))
3.图像的灰度阈值变换函数


import cv2
import numpy as np
from matplotlib import pyplot as plt
from matplotlib import pyplot as plt
img = cv2.imread("D:\\software\\m\\ConsoleApplication1\\ConsoleApplication1\\1.jpg",0) # 不加0默认是彩色,否则是灰度
print(img.shape)
cv2.imshow("original",img)
#img1 = np.dot(2,img) +3
img1 = [[]]
plt.hist(img.ravel() , 256, [0, 256])
plt.show()
th1,dst = cv2.threshold(img,127,255,cv2.THRESH_BINARY)
cv2.imshow("a",dst)
plt.hist(dst.ravel() , 256, [0, 256])
plt.show()
print(type(img))
th2 = cv2.adaptiveThreshold(img,255,cv2.ADAPTIVE_THRESH_MEAN_C,\
cv2.THRESH_BINARY,3,5)
th3 = cv2.adaptiveThreshold(img,255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C,\
cv2.THRESH_BINARY,3,5)
cv2.imshow("b",th2)
plt.hist(th2.ravel() , 256, [0, 256])
plt.show()
print(type(img))
cv2.imshow("c",th3)
plt.hist(th3.ravel() , 256, [0, 256])
plt.show()
print(type(img))
cv2.waitKey(1000000000)
#cv2.imwrite
代码解析:分别利用opencv自带的二值化函数,展现了人为设定的阈值以及利用自适应方法设定的阈值进行二值化以后图像处理后的不同结果。

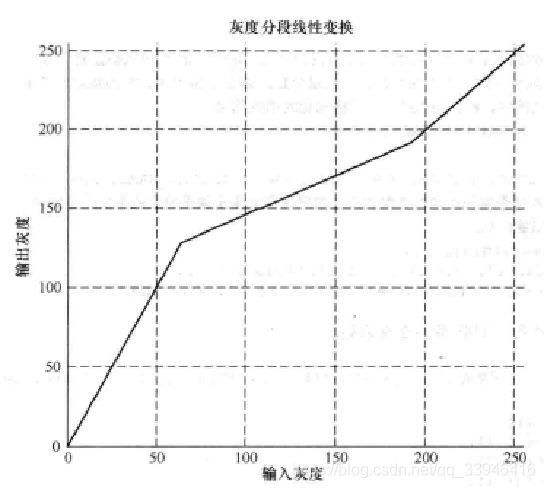
import cv2
import numpy as np
from matplotlib import pyplot as plt
from matplotlib import pyplot as plt
img = cv2.imread("D:\\software\\m\\ConsoleApplication1\\ConsoleApplication1\\1.jpg",0) # 不加0默认是彩色,否则是灰度
print(img.shape)
cv2.imshow("original",img)
#img1 = np.dot(2,img) +3
img1 = [[]]
plt.hist(img.ravel() , 256, [0, 256])
plt.show()
for i in range(len(img)):
for j in range(len(img[i])):
if(img[i][j]<200):
img[i][j] = img[i][j]*0.2; # img[i][j][0]
elif(img[i][j]>=200 and img[i][j]<=220):
img[i][j]= img[i][j]*0.5+3
elif(img[i][j] >220):
img[i][j] = img[i][j]+5
if (img[i][j] > 255):
img[i][j] = 255
elif (img[i][j] <= 0):
img[i][j] = 0
cv2.imshow("a",img)
plt.hist(img.ravel() , 256, [0, 256])
plt.show()
print(type(img))
cv2.waitKey(1000000000)
代码解析:根据阈值,分三段对图像进行不同程度的加强
4.图像的均衡化


import cv2
import numpy as np
from matplotlib import pyplot as plt
from matplotlib import pyplot as plt
img = cv2.imread("D:\\software\\m\\ConsoleApplication1\\ConsoleApplication1\\1.jpg",0) # 不加0默认是彩色,否则是灰度
print(img.shape)
cv2.imshow("original",img)
#img1 = np.dot(2,img) +3
img1 = [[]]
plt.hist(img.ravel() , 256, [0, 256])
plt.show()
dst = cv2.equalizeHist(img)
cv2.imshow("a",dst)
plt.hist(dst.ravel() , 256, [0, 256])
plt.show()
print(type(img))
cv2.waitKey(1000000000)
#cv2.imwrite
直方图均衡化
dst = cv2.equalizeHist(img)
图像的几何变换

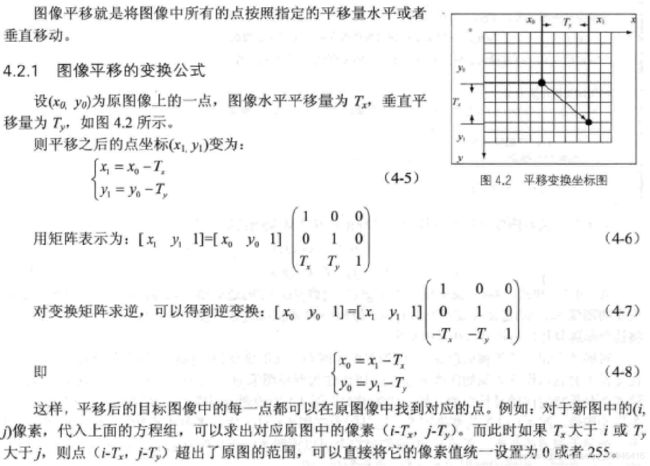
1.图像的平移
import cv2
import numpy as np
from matplotlib import pyplot as plt
from matplotlib import pyplot as plt
img = cv2.imread("D:\\software\\m\\ConsoleApplication1\\ConsoleApplication1\\1.jpg") # 不加0默认是彩色,否则是灰度
print(img.shape)
cv2.imshow("original",img)
rows, cols, channel = img.shape
matrix=np.array([[1,0,20],[0,1,20],[0,0,1]],np.float32)
dst=cv2.warpPerspective(img,matrix,(int(cols+500/2),int(rows+500/2)))
cv2.imshow("a",dst)
plt.hist(dst.ravel() , 256, [0, 256])
plt.show()
print(type(img))
rows, cols, channel = img.shape
matrix=np.array([[-1,0,cols],[0,1,0],[0,0,1]],np.float32)
dst1=cv2.warpPerspective(img,matrix,(int(cols+500/2),int(rows+500/2)))
cv2.imshow("b",dst1)
plt.hist(dst1.ravel() , 256, [0, 256])
plt.show()
print(type(img))
rows, cols, channel = img.shape
matrix=np.array([[1,0,0],[0,-1,rows],[0,0,1]],np.float32)
dst2=cv2.warpPerspective(img,matrix,(int(cols+500/2),int(rows+500/2)))
cv2.imshow("c",dst2)
plt.hist(dst2.ravel() , 256, [0, 256])
plt.show()
print(type(img))
cv2.waitKey(1000000000)
#cv2.imwrite
代码解析:注意透视变换里warpPerspective,变换矩阵是右乘坐标矩阵(或图像矩阵)。第一段代码表示向右向下平移20.
第二三段分别表示水平镜像和垂直镜像。

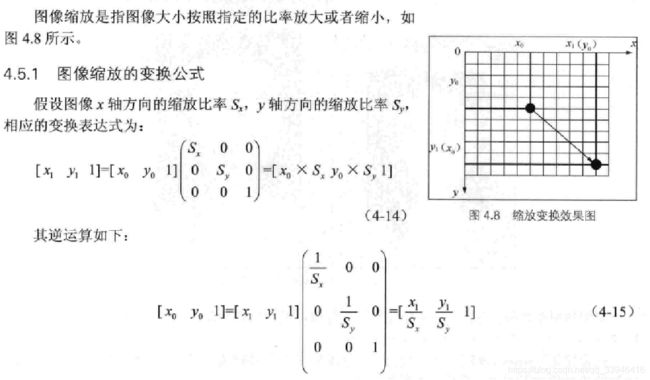
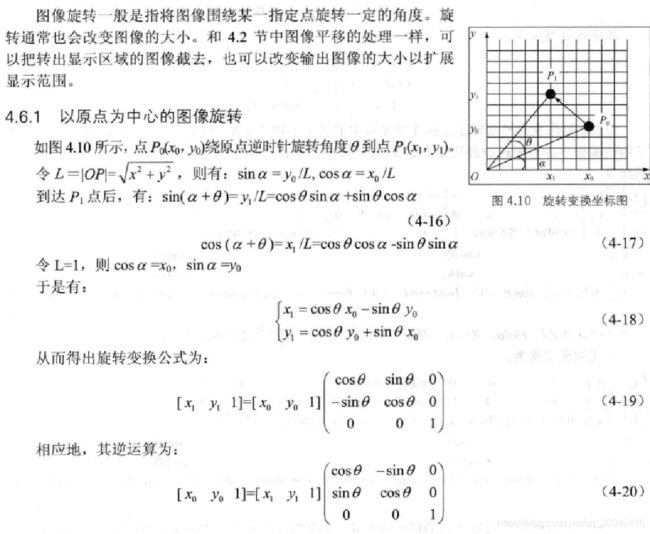


import cv2
import numpy as np
from matplotlib import pyplot as plt
from matplotlib import pyplot as plt
img = cv2.imread("D:\\a\\m.jpg") # 不加0默认是彩色,否则是灰度
print(img.shape)
cv2.imshow("original",img)
#img1 = np.dot(2,img) +3
img1 = [[]]
#plt.hist(img.ravel() , 256, [0, 256])
#plt.show()
rows, cols, channel = img.shape #rows是height cols 是width
centerx=rows*0.5
centery=cols*0.5
x =( np.pi)
a = np.cos(x)
b = np.sin(x)
#c = (np.cos(x))*centerx*(-1)+(np.sin(x))*centery+centerx
#d = -(np.sin(x))*centerx+(np.cos(x))*centery+centery
n1=np.mat([[1,0,0],[0,-1,0],[-centery,centerx,1]],np.float32)
n2=np.mat([[a,-b,0],[b,a,0],[0,0,1]],np.float32)
n3=np.mat([[1,0,0],[0,-1,0],[centery,centerx,1]],np.float32)
n4=np.matmul(n1,n2)
n=np.matmul(n4,n3)
n=n.T
#matrix=np.array([[a,-b,c],[b,a,d],[0,0,1]],np.float32)
dst=cv2.warpPerspective(img,n,(cols,rows))
print(dst.shape)
cv2.imshow("a",dst)
#plt.hist(dst.ravel() , 256, [0, 256])
#plt.show()
print(type(img))
cv2.waitKey(1000000000)
#cv2.imwrite
实现了图像绕任意中心旋转任意角度
代码解析:在python中图像的坐标原点在左上角,向右和向下表示其x,y的正方向。在c++中坐标原点在图像的左下角,向上和向右表示其正方向。注意透视变换里warpPerspective,变换矩阵是右乘坐标矩阵(或图像矩阵)。平移坐标系时左正右负,平移坐标时左负右正。坐标轴反转时乘(-1).一定注意旋转矩阵,平移矩阵坐标轴方向一致再乘
5.图像的插值
最邻近插值,双线性插值
import cv2
import numpy as np
from matplotlib import pyplot as plt
from matplotlib import pyplot as plt
img = cv2.imread("D:\\software\\m\\ConsoleApplication1\\ConsoleApplication1\\1.jpg") # 不加0默认是彩色,否则是灰度
print(img.shape)
cv2.imshow("original",img)
#img1 = np.dot(2,img) +3
#图像插值:INTER_NEAREST最邻近插值,INTER_LINEAR 双线性插值,INTER_AREA 使用像素区域关系进行重采样,INTER_CUBIC 4x4像素邻域的双三次插值,INTER_LANCZOS4 8x8像素邻域的Lanczos插值
rows, cols, channel = img.shape
dst=cv2.resize(img, (int(cols*2),int(rows*2)), interpolation=cv2.INTER_AREA)
cv2.imshow("a",img)
print(type(img))
cv2.waitKey(1000000000)
#cv2.imwrite
6.图像的配准
提取图像的某一目标到另一张图像的指定位置;例如车牌

代码实现:
import cv2
import numpy as np
from matplotlib import pyplot as plt
from matplotlib import pyplot as plt
img = cv2.imread("D:\\a\\m.jpg") # 不加0默认是彩色,否则是灰度
print(img.shape)
cv2.imshow("original",img)
x1 = 108
y1 = 134
x2=156
y2=249
x3=274
y3 =52
x4 =296
y4 =118
points1 = np.float32([[x1,y1],[x2,y2],[x3,y3],[x4,y4]])
points2 = np.float32([[0,0],[0,300],[300,0],[300,300]])
matrix = cv2.getPerspectiveTransform(points1,points2)
dst=cv2.warpPerspective(img,matrix,(300,300))
print(dst.shape)
cv2.imshow("a",dst)
print(type(img))
cv2.waitKey(1000000000)
#cv2.imwrite
代码解析:获取原图中对应车牌四个点对应的像素坐标,设定变换以后的四个点的坐标,利用变换矩阵实现变换,然后经过透视变换就好 。得到车牌正面显示。
7.图像的平滑




1)
import cv2
import numpy as np
from matplotlib import pyplot as plt
from matplotlib import pyplot as plt
img = cv2.imread("D:\\software\\m\\ConsoleApplication1\\ConsoleApplication1\\1.jpg") # 不加0默认是彩色,否则是灰度
print(img.shape)
cv2.imshow("original",img)
#img1 = np.dot(2,img) +3
dst1=cv2.blur(img,(5,5))
dst2=cv2.GaussianBlur(img,(5,5),2)
dst3=cv2.medianBlur(img,5)
cv2.imshow("a",dst1)
cv2.imshow("b",dst2)
cv2.imshow("c",dst3)
print(type(img))
cv2.waitKey(1000000000)
#cv2.imwrite
代码解析:dst1=cv2.blur(img,(5,5)) 平均滤波 块的大小是55
dst2=cv2.GaussianBlur(img,(5,5),2) 高斯平均滤波,块大小55,标准差是2
dst3=cv2.medianBlur(img,5) 中值滤波。块的大小是5
2)加入随机噪声后改进的中值滤波程序
import cv2
import numpy as np
from matplotlib import pyplot as plt
from matplotlib import pyplot as plt
import random
img = cv2.imread("D:\\software\\m\\ConsoleApplication1\\ConsoleApplication1\\1.jpg",0)
img2 =img
print(img.shape)
#print(img)
cv2.imshow("original",img)
huakuai = 7
t = int((huakuai-3)/2 +1)
#图像转化为灰度值在0-1之间
#img2 = cv2.copyMakeBorder(img,1,1,1,1,cv2.BORDER_CONSTANT, value=255)
rows, cols = img2.shape
# 加入噪声
for i in range(rows):
for j in range(cols):
a = random.random()
if(a>0.8):
img2[i][j] = 255
else:
img2[i][j] = img2[i][j]
cv2.imshow("addnoise",img2)
#中值滤波
img3 = cv2.copyMakeBorder(img2,t,t,t,t,cv2.BORDER_CONSTANT, value=255)
img4 = cv2.copyMakeBorder(img2,t,t,t,t,cv2.BORDER_CONSTANT, value=255)
rows, cols = img3.shape
for i in range(rows-huakuai+1):
for j in range(cols-huakuai+1):
if(huakuai == 3):
b = np.array([img3[i][j], img3[i + 1][j], img3[i + 2][j],
img3[i][j + 1], img3[i + 1][j + 1], img3[i + 2][j + 1],
img3[i][j + 2], img3[i + 1][j + 2], img3[i + 2][j + 2]])
if(img3[i+1][j+1] == b.max() or img3[i+1][j+1] == b.min() ):
img4[i+1][j+1]=np.median(b)
elif (huakuai == 5):
b = np.array([img3[i][j] , img3[i + 1][j], img3[i + 2][j], img3[i+3][j], img3[i+4][j],
img3[i][j + 1], img3[i + 1][j + 1], img3[i + 2][j + 1],img3[i + 3][j + 1], img3[i + 4][j + 1],
img3[i][j + 2], img3[i + 1][j + 2], img3[i + 2][j + 2],img3[i + 3][j + 2], img3[i + 4][j + 2],
img3[i][j + 3], img3[i + 1][j + 3], img3[i + 2][j + 3], img3[i + 3][j + 3],img3[i + 4][j + 3],
img3[i][j + 4], img3[i + 1][j + 4], img3[i + 2][j + 4], img3[i + 3][j + 4], img3[i + 4][j + 4]])
if (img3[i + 2][j + 2] == b.max() or img3[i + 2][j + 2] == b.min()):
img4[i + 2][j + 2] = np.median(b)
elif (huakuai == 7):
b = np.array([img3[i][j] , img3[i + 1][j], img3[i + 2][j], img3[i+3][j], img3[i+4][j], img3[i+5][j] , img3[i + 6][j],
img3[i][j + 1], img3[i + 1][j + 1], img3[i + 2][j + 1],img3[i + 3][j + 1], img3[i + 4][j + 1], img3[i+5][j+1] , img3[i + 6][j+1],
img3[i][j + 2], img3[i + 1][j + 2], img3[i + 2][j + 2],img3[i + 3][j + 2], img3[i + 4][j + 2], img3[i+5][j+2] , img3[i + 6][j+2],
img3[i][j + 3], img3[i + 1][j + 3], img3[i + 2][j + 3], img3[i + 3][j + 3],img3[i + 4][j + 3], img3[i+5][j+3] , img3[i + 6][j+3],
img3[i][j + 4], img3[i + 1][j + 4], img3[i + 2][j + 4], img3[i + 3][j + 4], img3[i + 4][j + 4], img3[i+5][j+4] , img3[i + 6][j+4],
img3[i][j + 5], img3[i + 1][j + 5], img3[i + 2][j + 5], img3[i + 3][j + 5],img3[i + 4][j + 5], img3[i + 5][j + 5], img3[i + 6][j + 5],
img3[i][j + 6], img3[i + 1][j + 6], img3[i + 2][j + 6], img3[i + 3][j + 6],img3[i + 4][j + 6], img3[i + 5][j + 6], img3[i + 6][j + 6]])
if (img3[i + 3][j + 3] == b.max() or img3[i + 3][j + 3] == b.min()):
img4[i + 3][j + 3] = np.median(b)
elif (huakuai == 9):
b = np.array([img3[i][j] , img3[i + 1][j], img3[i + 2][j], img3[i+3][j], img3[i+4][j], img3[i+5][j] , img3[i + 6][j], img3[i + 7][j], img3[i + 8][j],
img3[i][j + 1], img3[i + 1][j + 1], img3[i + 2][j + 1],img3[i + 3][j + 1], img3[i + 4][j + 1], img3[i+5][j+1] , img3[i + 6][j+1], img3[i + 7][j+1], img3[i + 8][j+1],
img3[i][j + 2], img3[i + 1][j + 2], img3[i + 2][j + 2],img3[i + 3][j + 2], img3[i + 4][j + 2], img3[i+5][j+2] , img3[i + 6][j+2],img3[i + 7][j+2], img3[i + 8][j+2],
img3[i][j + 3], img3[i + 1][j + 3], img3[i + 2][j + 3], img3[i + 3][j + 3],img3[i + 4][j + 3], img3[i+5][j+3] , img3[i + 6][j+3],img3[i + 7][j+3], img3[i + 8][j+3],
img3[i][j + 4], img3[i + 1][j + 4], img3[i + 2][j + 4], img3[i + 3][j + 4], img3[i + 4][j + 4], img3[i+5][j+4] , img3[i + 6][j+4],img3[i + 7][j+4], img3[i + 8][j+4],
img3[i][j + 5], img3[i + 1][j + 5], img3[i + 2][j + 5], img3[i + 3][j + 5],img3[i + 4][j + 5], img3[i + 5][j + 5], img3[i + 6][j + 5],img3[i + 7][j+5], img3[i + 8][j+5],
img3[i][j + 6], img3[i + 1][j + 6], img3[i + 2][j + 6], img3[i + 3][j + 6],img3[i + 4][j + 6], img3[i + 5][j + 6], img3[i + 6][j + 6],img3[i + 7][j+6], img3[i + 8][j+6],
img3[i][j + 7], img3[i + 1][j + 7], img3[i + 2][j + 7], img3[i + 3][j + 7], img3[i + 4][j + 7], img3[i + 5][j + 7], img3[i + 6][j + 7], img3[i + 7][j + 7], img3[i + 8][j + 7],
img3[i][j + 8], img3[i + 1][j + 8], img3[i + 2][j + 8], img3[i + 3][j + 8],img3[i + 4][j + 8], img3[i + 5][j + 8], img3[i + 6][j + 8], img3[i + 7][j + 8],img3[i + 8][j + 8]])
if (img3[i + 4][j + 4] == b.max() or img3[i + 4][j + 4] == b.min() ):
img4[i + 4][j + 4] = np.median(b)
cv2.imshow('filter',img4)
cv2.waitKey(1000000000)
代码解析:读取图片,产生0-1的随机数,遍历整张图像,如果随机数大于某一设定值*(即以一定的概率)则改变改点的像素值为0或255。这样就将图像中加入了随机噪声。然后设定滑块的大小。利用图像和滑块的卷积运算实现中值滤波。如果是噪点,判断的依据是该点的灰度值是整个区域里的最大或最小值,就对其进行中值滤波,否则保留原像素点在此处的位置,减小图像模糊程度。这就是实现对中值滤波的改进,减小图像的模糊程度又能极大限度滤除噪声。
8.图像的锐化




代码实现:
import cv2
import numpy as np
from matplotlib import pyplot as plt
from matplotlib import pyplot as plt
img = cv2.imread("D:",0)
print(img.shape)
#print(img)
cv2.imshow("original",img)
a=np.mat([[1,4,1],[4,-20,4],[1,4,1]])
img2 = cv2.copyMakeBorder(img,1,1,1,1,cv2.BORDER_CONSTANT, value=255)
img2 = np.float32(img2)
img3 = cv2.copyMakeBorder(img,1,1,1,1,cv2.BORDER_CONSTANT, value=255)
rows, cols = img2.shape
#for i in range(rows-2):
#for j in range(cols-2):
for i in range(rows-2):
for j in range(cols-2):
b=np.mat([ [img3[i][j],img3[i+1][j],img3[i+2][j]],
[img3[i][j+1],img3[i+1][j+1],img3[i+2][j+1]],
[img3[i][j+2],img3[i+1][j+2],img3[i+2][j+2]] ])
img2[i+1][j+1] = (np.dot(b,a).sum())/9
cv2.imshow("a",img2)
print(img2)
#img4=(img2+img3)
#print(img4.max())
#img5=((img2+img3)/img4)*255
#cv2.imshow("b",img5)
img4=(-img2+img3).max()
img5=(-img2+img3).min()
img6=(((-img2+img3)-img5)/(img4-img5))
#img5=(img2+img3)/img4*255
cv2.imshow("b",img6)
cv2.waitKey(1000000000)
代码解析:利用高斯拉普拉斯模板,利用3*3的卷积块,将图像进行锐化,并将锐化后的图像与原图按一定比例相加。得到增强后的图像。注意灰度值范围,0-1或0-255,以及不要超出其范围。
神经网络
1.介绍
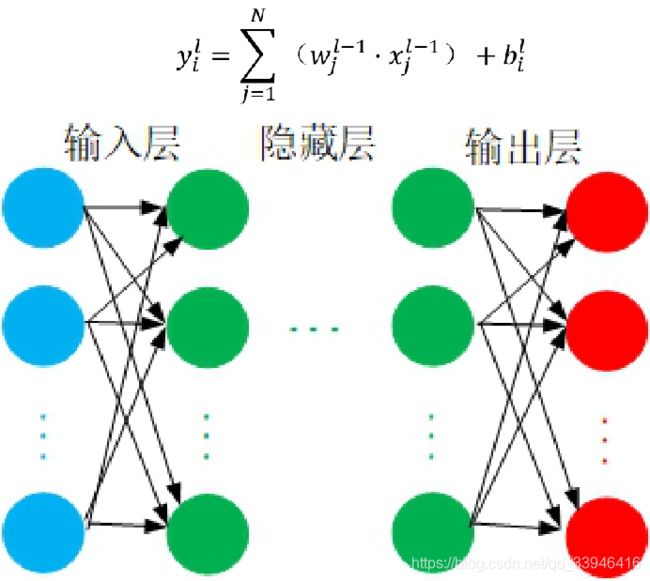
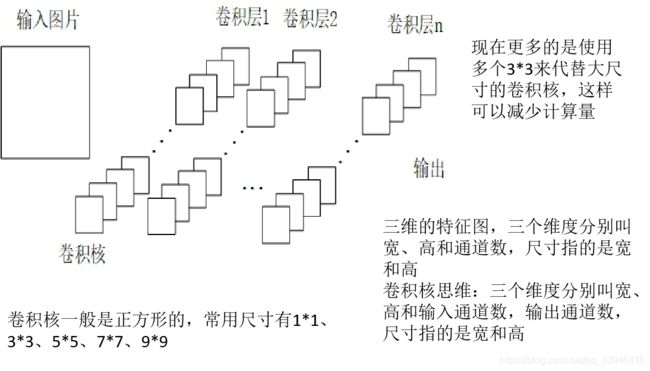

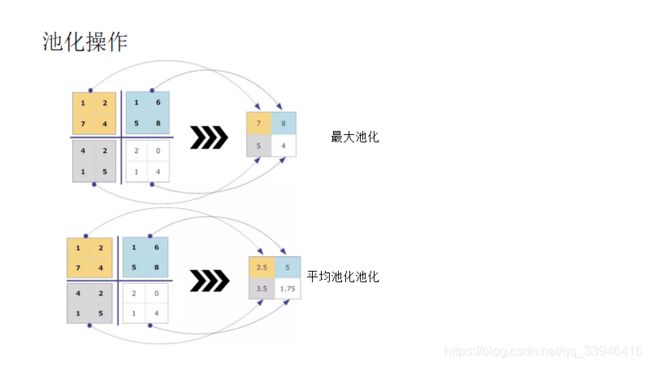


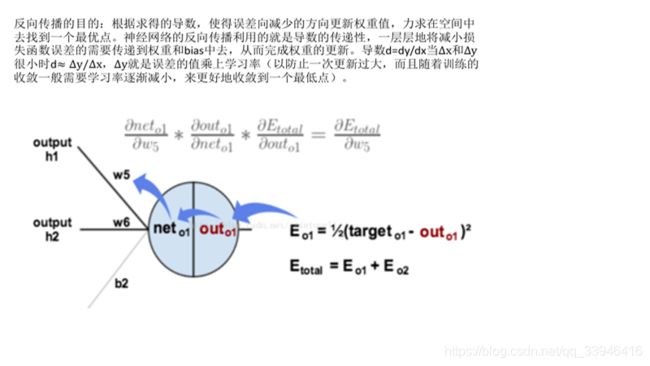


1)代码1;
import tensorflow as tf
"""
mat1 = tf.constant([[1,2]])
mat2 = tf.constant([[2],[2]])
product = tf.matmul(mat1,mat2)
print(product)
"""
state =tf.Variable(0,name ="counter")
one = tf.constant(1)
newvalue = tf.add(state,one)
update = tf.assign(state,newvalue)
init_cp = tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(init_cp)
print(sess.run(state))
sess.run(update)
print(sess.run(state))
#i=10
#while(i):
sess.run(update)
print(sess.run(state))
# i=i-1
"""
sess = tf.Session()
print(sess.run(product))
print(sess.run([product]))
sess.close()
"""
#or
"""
with tf.Session() as sess:
result = sess.run(product)
print(result)
print([result])
"""
"""
input1 = tf.placeholder(tf.float32)
input2 = tf.placeholder(tf.float32)
output = tf.multiply(input1,input2)
with tf.Session() as sess:
print(sess.run(output,feed_dict={input1:[7,],input2:[2]}))
print(sess.run(input1,feed_dict={input1:[7,]}))
"""
代码解析:tensorflow框架的一些命令的简单使用
2)在tensorflow下实现 训练生成任意函数的权重,系数
import tensorflow as tf
import numpy as np
input1 = tf.placeholder(tf.float32,[None,1])
ystandrad = tf.placeholder(tf.float32,[None,1])
w =tf.Variable(np.float32(np.array([2.0])),name ="counter1")
b =tf.Variable(1.0,name ="counter2")
y = input1*w + b
m =tf.abs(tf.subtract(y,ystandrad))
loss = tf.reduce_mean(m)
optimizer = tf.train.GradientDescentOptimizer(0.3)
train = optimizer.minimize(loss)
init_cp = tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(init_cp)
i = 1
while(i<1001):
x = np.random.rand(20,1)
y = 3 * x + 4
sess.run(train, feed_dict={input1: x, ystandrad: y})
#print(sess.run(output, feed_dict={input1: [[7], [3],[4],[ 6]], ybiao: [[2], [3], [4], [5]]}))
#outputm=np.sqrt(output**2)
if(i%20 == 0):
print(i/20,sess.run(w), sess.run(b))
i=i+1
#tf.nn.sigmoid 激活 relu
#tf.multiply
代码解析:利用随机梯度下降算法。实现目标函数,利用随机数,进行训练最终实现所要的权值,系数与目标函数的系数相对应。
利用神经网络以及卷积神经网络在tensorflow的框架下实现手写数字识别



1.利用全连接神经网络实现
代码实现:
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
import numpy as np
import cv2
import matplotlib.pyplot as plt
batchx = tf.placeholder(tf.float32,[None,784])
batchy = tf.placeholder(tf.float32,[None,10])
#input1 = tf.placeholder(tf.float32, [None, 1])
w = tf.Variable(tf.random_uniform([784, 100], -10.0, 10.0),name = 'weight')
b = tf.Variable(tf.random_uniform([100], -10.0, 10.0),name = 'bias')
w1 = tf.Variable(tf.random_uniform([100, 10], -1.0, 1.0),name = 'weight1')
b1 = tf.Variable(tf.random_uniform([10], -1.0, 1.0),name = 'bias1')
y0 = tf.nn.sigmoid((tf.matmul(batchx,w)+b))
y = tf.nn.softmax(tf.matmul(y0,w1)+b1)
qqq = tf.argmax(y,1)
cross_entropy = -tf.reduce_sum(batchy*tf.log(y))
optimizer = tf.train.GradientDescentOptimizer(0.001)
train = optimizer.minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(batchy,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
saver =tf.train.Saver()
init_cp = tf.initialize_all_variables()
with tf.Session() as sess:
sess.run(init_cp)
#saver = tf.train.import_meta_graph("model1\\model.ckpt.meta")
#saver.restore(sess, tf.train.latest_checkpoint("model1"))
# mnist = input_data.read_data_sets("D:\\a\\sss.jpg", one_hot=True)
#kkk=cv2.imread("D:\\a\\qqq.png",0)
#print(kkk)
#print(np.size(kkk))
#mm=kkk.reshape(1,784)
#print(mm)
#batch_xs, batch_ys = rrr.train.next_batch(1)
#print(sess.run(qqq, feed_dict={batchx: mm}))
axis=[]
train_acys=[]
test=[]
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
batch_xs, batch_ys = mnist.train.next_batch(1000)
i=1
while (i < 10000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train,feed_dict={batchx:batch_xs,batchy:batch_ys})
print(sess.run(accuracy,feed_dict={batchx:batch_xs,batchy:batch_ys}))
i=i+1
axis.append(i)
train_acys.append(sess.run(accuracy,feed_dict={batchx:batch_xs,batchy:batch_ys}))
test.append(sess.run(accuracy, feed_dict={batchx: mnist.test.images, batchy: mnist.test.labels}))
#saver.save(sess,"model1\\model.ckpt")
"""
plt.title('Result Analysis')
plt.plot(axis, train_acys, color='green', label='training accuracy')
plt.plot(axis, test, color='red', label='testing accuracy')
plt.legend() # 显示图例
plt.xlabel('iteration times')
plt.ylabel('rate')
plt.show()
"""
代码解析:利用交叉熵损失函数,首先读取minist数据集的训练集部分。每次读取100张图。这100张图的大小是2828像素。每一张图对应0-9这十个数字中的一个。然后搭建两层全连接神经网络,将输入的图片进行训练,并于标准图对应的标签进行比较,并求出比较这100张的平均准确率,然后通过训练减小交叉熵损失。然后使准确率上升。训练10000次,然后将训练的权值保存。然后输入一张手写的0-9任意一个以黑为底色,白为字,2828的图,来测试其数字。训练和测试过程的准确率可以通过画图的方式显现。看是否出现过拟合或者欠拟合的现象。
2.利用卷积神经网络和全连接神经网络实现
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
import numpy as np
import cv2
import matplotlib.pyplot as plt
xx = tf.placeholder(tf.float32,[None,784])
yy = tf.placeholder(tf.float32,[None,10])
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME') #ksiza 中间两个表示滑块大小 strides表示扩充边缘
#第一层卷积
W_conv1 = weight_variable([5, 5, 1, 32]) #块大小 5*5 输入通道数 输出通道数
b_conv1 = bias_variable([32]) #32个数
x_image = tf.reshape(xx, [-1,28,28,1]) #-1表示任意张图像 宽高通道数
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) #卷积求和 加激活函数
h_pool1 = max_pool_2x2(h_conv1) #池化
#第二层卷积
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
#第一层全连接层
W_1 = weight_variable([7*7*64, 20]) #
b_1 = bias_variable([20])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
y0 = tf.nn.relu((tf.matmul(h_pool2_flat,W_1)+b_1))
keep_prob = tf.placeholder("float")
h_fc1_drop = tf.nn.dropout(y0, keep_prob)
#第二层全连接层
W_2 = weight_variable([20, 10])
b_2 = bias_variable([10])
#h_pool3_flat = tf.reshape(h_fc1_drop, [-1, 7*7*64])
y1 = tf.nn.softmax((tf.matmul(h_fc1_drop,W_2)+b_2))
cross_entropy = -tf.reduce_sum(yy*tf.log(y1))
optimizer = tf.train.GradientDescentOptimizer(0.0001)
train = optimizer.minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y1,1), tf.argmax(yy,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
qqq = tf.argmax(y1,1)
saver =tf.train.Saver()
axis=[]
train_acys=[]
test=[]
init_cp = tf.initialize_all_variables()
with tf.Session() as sess:
saver = tf.train.import_meta_graph("model1\\model.ckpt.meta")
saver.restore(sess, tf.train.latest_checkpoint("model2"))
kkk=cv2.imread("D:\\a\\qqq.png",0)
mm=kkk.reshape(1,784)
keep = 0.5
print(sess.run(qqq, feed_dict={xx: mm, keep_prob: keep}))
#sess.run(init_cp)
#mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
#batch_xs, batch_ys = mnist.train.next_batch(1000)
#keep = 0.5
#i = 1
#while (i < 10000):
#batch_xs, batch_ys = mnist.train.next_batch(100)
#sess.run(train, feed_dict={xx: batch_xs, yy: batch_ys,keep_prob:keep})
#print(i,sess.run(accuracy, feed_dict={xx: batch_xs, yy: batch_ys,keep_prob:keep}))
#if(i%50 == 0):
# print(i, sess.run(accuracy, feed_dict={xx: batch_xs, yy: batch_ys, keep_prob: keep}))
# i=i+1
#saver.save(sess, "model2\\model.ckpt")
"""
axis.append(i)
train_acys.append(sess.run(accuracy, feed_dict={xx: batch_xs,yy: batch_ys})) #训练值
test.append(sess.run(accuracy, feed_dict={xx: mnist.test.images, yy: mnist.test.labels})) #测试值
plt.title('Result Analysis')
plt.plot(axis, train_acys, color='green', label='training accuracy')
plt.plot(axis, test, color='red', label='testing accuracy')
plt.legend() # 显示图例
plt.xlabel('iteration times')
plt.ylabel('rate')
plt.show()
"""
代码解析:此次利用的是三层卷积神经网络和两层全连接神经网络实现。中间利用了池化。利用了dropout在训练工程中预防过拟合,保持某些点开关的概率。。最终实现和上面一样的功能。实现的结果准确性上,这个方法更准确。
VGG网络的搭建实现对目标图像的分类
实现的1000个分类
{0: ‘tench, Tinca tinca’,
1: ‘goldfish, Carassius auratus’,
2: ‘great white shark, white shark, man-eater, man-eating shark, Carcharodon carcharias’,
3: ‘tiger shark, Galeocerdo cuvieri’,
4: ‘hammerhead, hammerhead shark’,
5: ‘electric ray, crampfish, numbfish, torpedo’,
6: ‘stingray’,
7: ‘cock’,
8: ‘hen’,
9: ‘ostrich, Struthio camelus’,
10: ‘brambling, Fringilla montifringilla’,
11: ‘goldfinch, Carduelis carduelis’,
12: ‘house finch, linnet, Carpodacus mexicanus’,
13: ‘junco, snowbird’,
14: ‘indigo bunting, indigo finch, indigo bird, Passerina cyanea’,
15: ‘robin, American robin, Turdus migratorius’,
16: ‘bulbul’,
17: ‘jay’,
18: ‘magpie’,
19: ‘chickadee’,
20: ‘water ouzel, dipper’,
21: ‘kite’,
22: ‘bald eagle, American eagle, Haliaeetus leucocephalus’,
23: ‘vulture’,
24: ‘great grey owl, great gray owl, Strix nebulosa’,
25: ‘European fire salamander, Salamandra salamandra’,
26: ‘common newt, Triturus vulgaris’,
27: ‘eft’,
28: ‘spotted salamander, Ambystoma maculatum’,
29: ‘axolotl, mud puppy, Ambystoma mexicanum’,
30: ‘bullfrog, Rana catesbeiana’,
31: ‘tree frog, tree-frog’,
32: ‘tailed frog, bell toad, ribbed toad, tailed toad, Ascaphus trui’,
33: ‘loggerhead, loggerhead turtle, Caretta caretta’,
34: ‘leatherback turtle, leatherback, leathery turtle, Dermochelys coriacea’,
35: ‘mud turtle’,
36: ‘terrapin’,
37: ‘box turtle, box tortoise’,
38: ‘banded gecko’,
39: ‘common iguana, iguana, Iguana iguana’,
40: ‘American chameleon, anole, Anolis carolinensis’,
41: ‘whiptail, whiptail lizard’,
42: ‘agama’,
43: ‘frilled lizard, Chlamydosaurus kingi’,
44: ‘alligator lizard’,
45: ‘Gila monster, Heloderma suspectum’,
46: ‘green lizard, Lacerta viridis’,
47: ‘African chameleon, Chamaeleo chamaeleon’,
48: ‘Komodo dragon, Komodo lizard, dragon lizard, giant lizard, Varanus komodoensis’,
49: ‘African crocodile, Nile crocodile, Crocodylus niloticus’,
50: ‘American alligator, Alligator mississipiensis’,
51: ‘triceratops’,
52: ‘thunder snake, worm snake, Carphophis amoenus’,
53: ‘ringneck snake, ring-necked snake, ring snake’,
54: ‘hognose snake, puff adder, sand viper’,
55: ‘green snake, grass snake’,
56: ‘king snake, kingsnake’,
57: ‘garter snake, grass snake’,
58: ‘water snake’,
59: ‘vine snake’,
60: ‘night snake, Hypsiglena torquata’,
61: ‘boa constrictor, Constrictor constrictor’,
62: ‘rock python, rock snake, Python sebae’,
63: ‘Indian cobra, Naja naja’,
64: ‘green mamba’,
65: ‘sea snake’,
66: ‘horned viper, cerastes, sand viper, horned asp, Cerastes cornutus’,
67: ‘diamondback, diamondback rattlesnake, Crotalus adamanteus’,
68: ‘sidewinder, horned rattlesnake, Crotalus cerastes’,
69: ‘trilobite’,
70: ‘harvestman, daddy longlegs, Phalangium opilio’,
71: ‘scorpion’,
72: ‘black and gold garden spider, Argiope aurantia’,
73: ‘barn spider, Araneus cavaticus’,
74: ‘garden spider, Aranea diademata’,
75: ‘black widow, Latrodectus mactans’,
76: ‘tarantula’,
77: ‘wolf spider, hunting spider’,
78: ‘tick’,
79: ‘centipede’,
80: ‘black grouse’,
81: ‘ptarmigan’,
82: ‘ruffed grouse, partridge, Bonasa umbellus’,
83: ‘prairie chicken, prairie grouse, prairie fowl’,
84: ‘peacock’,
85: ‘quail’,
86: ‘partridge’,
87: ‘African grey, African gray, Psittacus erithacus’,
88: ‘macaw’,
89: ‘sulphur-crested cockatoo, Kakatoe galerita, Cacatua galerita’,
90: ‘lorikeet’,
91: ‘coucal’,
92: ‘bee eater’,
93: ‘hornbill’,
94: ‘hummingbird’,
95: ‘jacamar’,
96: ‘toucan’,
97: ‘drake’,
98: ‘red-breasted merganser, Mergus serrator’,
99: ‘goose’,
100: ‘black swan, Cygnus atratus’,
101: ‘tusker’,
102: ‘echidna, spiny anteater, anteater’,
103: ‘platypus, duckbill, duckbilled platypus, duck-billed platypus, Ornithorhynchus anatinus’,
104: ‘wallaby, brush kangaroo’,
105: ‘koala, koala bear, kangaroo bear, native bear, Phascolarctos cinereus’,
106: ‘wombat’,
107: ‘jellyfish’,
108: ‘sea anemone, anemone’,
109: ‘brain coral’,
110: ‘flatworm, platyhelminth’,
111: ‘nematode, nematode worm, roundworm’,
112: ‘conch’,
113: ‘snail’,
114: ‘slug’,
115: ‘sea slug, nudibranch’,
116: ‘chiton, coat-of-mail shell, sea cradle, polyplacophore’,
117: ‘chambered nautilus, pearly nautilus, nautilus’,
118: ‘Dungeness crab, Cancer magister’,
119: ‘rock crab, Cancer irroratus’,
120: ‘fiddler crab’,
121: ‘king crab, Alaska crab, Alaskan king crab, Alaska king crab, Paralithodes camtschatica’,
122: ‘American lobster, Northern lobster, Maine lobster, Homarus americanus’,
123: ‘spiny lobster, langouste, rock lobster, crawfish, crayfish, sea crawfish’,
124: ‘crayfish, crawfish, crawdad, crawdaddy’,
125: ‘hermit crab’,
126: ‘isopod’,
127: ‘white stork, Ciconia ciconia’,
128: ‘black stork, Ciconia nigra’,
129: ‘spoonbill’,
130: ‘flamingo’,
131: ‘little blue heron, Egretta caerulea’,
132: ‘American egret, great white heron, Egretta albus’,
133: ‘bittern’,
134: ‘crane’,
135: ‘limpkin, Aramus pictus’,
136: ‘European gallinule, Porphyrio porphyrio’,
137: ‘American coot, marsh hen, mud hen, water hen, Fulica americana’,
138: ‘bustard’,
139: ‘ruddy turnstone, Arenaria interpres’,
140: ‘red-backed sandpiper, dunlin, Erolia alpina’,
141: ‘redshank, Tringa totanus’,
142: ‘dowitcher’,
143: ‘oystercatcher, oyster catcher’,
144: ‘pelican’,
145: ‘king penguin, Aptenodytes patagonica’,
146: ‘albatross, mollymawk’,
147: ‘grey whale, gray whale, devilfish, Eschrichtius gibbosus, Eschrichtius robustus’,
148: ‘killer whale, killer, orca, grampus, sea wolf, Orcinus orca’,
149: ‘dugong, Dugong dugon’,
150: ‘sea lion’,
151: ‘Chihuahua’,
152: ‘Japanese spaniel’,
153: ‘Maltese dog, Maltese terrier, Maltese’,
154: ‘Pekinese, Pekingese, Peke’,
155: ‘Shih-Tzu’,
156: ‘Blenheim spaniel’,
157: ‘papillon’,
158: ‘toy terrier’,
159: ‘Rhodesian ridgeback’,
160: ‘Afghan hound, Afghan’,
161: ‘basset, basset hound’,
162: ‘beagle’,
163: ‘bloodhound, sleuthhound’,
164: ‘bluetick’,
165: ‘black-and-tan coonhound’,
166: ‘Walker hound, Walker foxhound’,
167: ‘English foxhound’,
168: ‘redbone’,
169: ‘borzoi, Russian wolfhound’,
170: ‘Irish wolfhound’,
171: ‘Italian greyhound’,
172: ‘whippet’,
173: ‘Ibizan hound, Ibizan Podenco’,
174: ‘Norwegian elkhound, elkhound’,
175: ‘otterhound, otter hound’,
176: ‘Saluki, gazelle hound’,
177: ‘Scottish deerhound, deerhound’,
178: ‘Weimaraner’,
179: ‘Staffordshire bullterrier, Staffordshire bull terrier’,
180: ‘American Staffordshire terrier, Staffordshire terrier, American pit bull terrier, pit bull terrier’,
181: ‘Bedlington terrier’,
182: ‘Border terrier’,
183: ‘Kerry blue terrier’,
184: ‘Irish terrier’,
185: ‘Norfolk terrier’,
186: ‘Norwich terrier’,
187: ‘Yorkshire terrier’,
188: ‘wire-haired fox terrier’,
189: ‘Lakeland terrier’,
190: ‘Sealyham terrier, Sealyham’,
191: ‘Airedale, Airedale terrier’,
192: ‘cairn, cairn terrier’,
193: ‘Australian terrier’,
194: ‘Dandie Dinmont, Dandie Dinmont terrier’,
195: ‘Boston bull, Boston terrier’,
196: ‘miniature schnauzer’,
197: ‘giant schnauzer’,
198: ‘standard schnauzer’,
199: ‘Scotch terrier, Scottish terrier, Scottie’,
200: ‘Tibetan terrier, chrysanthemum dog’,
201: ‘silky terrier, Sydney silky’,
202: ‘soft-coated wheaten terrier’,
203: ‘West Highland white terrier’,
204: ‘Lhasa, Lhasa apso’,
205: ‘flat-coated retriever’,
206: ‘curly-coated retriever’,
207: ‘golden retriever’,
208: ‘Labrador retriever’,
209: ‘Chesapeake Bay retriever’,
210: ‘German short-haired pointer’,
211: ‘vizsla, Hungarian pointer’,
212: ‘English setter’,
213: ‘Irish setter, red setter’,
214: ‘Gordon setter’,
215: ‘Brittany spaniel’,
216: ‘clumber, clumber spaniel’,
217: ‘English springer, English springer spaniel’,
218: ‘Welsh springer spaniel’,
219: ‘cocker spaniel, English cocker spaniel, cocker’,
220: ‘Sussex spaniel’,
221: ‘Irish water spaniel’,
222: ‘kuvasz’,
223: ‘schipperke’,
224: ‘groenendael’,
225: ‘malinois’,
226: ‘briard’,
227: ‘kelpie’,
228: ‘komondor’,
229: ‘Old English sheepdog, bobtail’,
230: ‘Shetland sheepdog, Shetland sheep dog, Shetland’,
231: ‘collie’,
232: ‘Border collie’,
233: ‘Bouvier des Flandres, Bouviers des Flandres’,
234: ‘Rottweiler’,
235: ‘German shepherd, German shepherd dog, German police dog, alsatian’,
236: ‘Doberman, Doberman pinscher’,
237: ‘miniature pinscher’,
238: ‘Greater Swiss Mountain dog’,
239: ‘Bernese mountain dog’,
240: ‘Appenzeller’,
241: ‘EntleBucher’,
242: ‘boxer’,
243: ‘bull mastiff’,
244: ‘Tibetan mastiff’,
245: ‘French bulldog’,
246: ‘Great Dane’,
247: ‘Saint Bernard, St Bernard’,
248: ‘Eskimo dog, husky’,
249: ‘malamute, malemute, Alaskan malamute’,
250: ‘Siberian husky’,
251: ‘dalmatian, coach dog, carriage dog’,
252: ‘affenpinscher, monkey pinscher, monkey dog’,
253: ‘basenji’,
254: ‘pug, pug-dog’,
255: ‘Leonberg’,
256: ‘Newfoundland, Newfoundland dog’,
257: ‘Great Pyrenees’,
258: ‘Samoyed, Samoyede’,
259: ‘Pomeranian’,
260: ‘chow, chow chow’,
261: ‘keeshond’,
262: ‘Brabancon griffon’,
263: ‘Pembroke, Pembroke Welsh corgi’,
264: ‘Cardigan, Cardigan Welsh corgi’,
265: ‘toy poodle’,
266: ‘miniature poodle’,
267: ‘standard poodle’,
268: ‘Mexican hairless’,
269: ‘timber wolf, grey wolf, gray wolf, Canis lupus’,
270: ‘white wolf, Arctic wolf, Canis lupus tundrarum’,
271: ‘red wolf, maned wolf, Canis rufus, Canis niger’,
272: ‘coyote, prairie wolf, brush wolf, Canis latrans’,
273: ‘dingo, warrigal, warragal, Canis dingo’,
274: ‘dhole, Cuon alpinus’,
275: ‘African hunting dog, hyena dog, Cape hunting dog, Lycaon pictus’,
276: ‘hyena, hyaena’,
277: ‘red fox, Vulpes vulpes’,
278: ‘kit fox, Vulpes macrotis’,
279: ‘Arctic fox, white fox, Alopex lagopus’,
280: ‘grey fox, gray fox, Urocyon cinereoargenteus’,
281: ‘tabby, tabby cat’,
282: ‘tiger cat’,
283: ‘Persian cat’,
284: ‘Siamese cat, Siamese’,
285: ‘Egyptian cat’,
286: ‘cougar, puma, catamount, mountain lion, painter, panther, Felis concolor’,
287: ‘lynx, catamount’,
288: ‘leopard, Panthera pardus’,
289: ‘snow leopard, ounce, Panthera uncia’,
290: ‘jaguar, panther, Panthera onca, Felis onca’,
291: ‘lion, king of beasts, Panthera leo’,
292: ‘tiger, Panthera tigris’,
293: ‘cheetah, chetah, Acinonyx jubatus’,
294: ‘brown bear, bruin, Ursus arctos’,
295: ‘American black bear, black bear, Ursus americanus, Euarctos americanus’,
296: ‘ice bear, polar bear, Ursus Maritimus, Thalarctos maritimus’,
297: ‘sloth bear, Melursus ursinus, Ursus ursinus’,
298: ‘mongoose’,
299: ‘meerkat, mierkat’,
300: ‘tiger beetle’,
301: ‘ladybug, ladybeetle, lady beetle, ladybird, ladybird beetle’,
302: ‘ground beetle, carabid beetle’,
303: ‘long-horned beetle, longicorn, longicorn beetle’,
304: ‘leaf beetle, chrysomelid’,
305: ‘dung beetle’,
306: ‘rhinoceros beetle’,
307: ‘weevil’,
308: ‘fly’,
309: ‘bee’,
310: ‘ant, emmet, pismire’,
311: ‘grasshopper, hopper’,
312: ‘cricket’,
313: ‘walking stick, walkingstick, stick insect’,
314: ‘cockroach, roach’,
315: ‘mantis, mantid’,
316: ‘cicada, cicala’,
317: ‘leafhopper’,
318: ‘lacewing, lacewing fly’,
319: “dragonfly, darning needle, devil’s darning needle, sewing needle, snake feeder, snake doctor, mosquito hawk, skeeter hawk”,
320: ‘damselfly’,
321: ‘admiral’,
322: ‘ringlet, ringlet butterfly’,
323: ‘monarch, monarch butterfly, milkweed butterfly, Danaus plexippus’,
324: ‘cabbage butterfly’,
325: ‘sulphur butterfly, sulfur butterfly’,
326: ‘lycaenid, lycaenid butterfly’,
327: ‘starfish, sea star’,
328: ‘sea urchin’,
329: ‘sea cucumber, holothurian’,
330: ‘wood rabbit, cottontail, cottontail rabbit’,
331: ‘hare’,
332: ‘Angora, Angora rabbit’,
333: ‘hamster’,
334: ‘porcupine, hedgehog’,
335: ‘fox squirrel, eastern fox squirrel, Sciurus niger’,
336: ‘marmot’,
337: ‘beaver’,
338: ‘guinea pig, Cavia cobaya’,
339: ‘sorrel’,
340: ‘zebra’,
341: ‘hog, pig, grunter, squealer, Sus scrofa’,
342: ‘wild boar, boar, Sus scrofa’,
343: ‘warthog’,
344: ‘hippopotamus, hippo, river horse, Hippopotamus amphibius’,
345: ‘ox’,
346: ‘water buffalo, water ox, Asiatic buffalo, Bubalus bubalis’,
347: ‘bison’,
348: ‘ram, tup’,
349: ‘bighorn, bighorn sheep, cimarron, Rocky Mountain bighorn, Rocky Mountain sheep, Ovis canadensis’,
350: ‘ibex, Capra ibex’,
351: ‘hartebeest’,
352: ‘impala, Aepyceros melampus’,
353: ‘gazelle’,
354: ‘Arabian camel, dromedary, Camelus dromedarius’,
355: ‘llama’,
356: ‘weasel’,
357: ‘mink’,
358: ‘polecat, fitch, foulmart, foumart, Mustela putorius’,
359: ‘black-footed ferret, ferret, Mustela nigripes’,
360: ‘otter’,
361: ‘skunk, polecat, wood pussy’,
362: ‘badger’,
363: ‘armadillo’,
364: ‘three-toed sloth, ai, Bradypus tridactylus’,
365: ‘orangutan, orang, orangutang, Pongo pygmaeus’,
366: ‘gorilla, Gorilla gorilla’,
367: ‘chimpanzee, chimp, Pan troglodytes’,
368: ‘gibbon, Hylobates lar’,
369: ‘siamang, Hylobates syndactylus, Symphalangus syndactylus’,
370: ‘guenon, guenon monkey’,
371: ‘patas, hussar monkey, Erythrocebus patas’,
372: ‘baboon’,
373: ‘macaque’,
374: ‘langur’,
375: ‘colobus, colobus monkey’,
376: ‘proboscis monkey, Nasalis larvatus’,
377: ‘marmoset’,
378: ‘capuchin, ringtail, Cebus capucinus’,
379: ‘howler monkey, howler’,
380: ‘titi, titi monkey’,
381: ‘spider monkey, Ateles geoffroyi’,
382: ‘squirrel monkey, Saimiri sciureus’,
383: ‘Madagascar cat, ring-tailed lemur, Lemur catta’,
384: ‘indri, indris, Indri indri, Indri brevicaudatus’,
385: ‘Indian elephant, Elephas maximus’,
386: ‘African elephant, Loxodonta africana’,
387: ‘lesser panda, red panda, panda, bear cat, cat bear, Ailurus fulgens’,
388: ‘giant panda, panda, panda bear, coon bear, Ailuropoda melanoleuca’,
389: ‘barracouta, snoek’,
390: ‘eel’,
391: ‘coho, cohoe, coho salmon, blue jack, silver salmon, Oncorhynchus kisutch’,
392: ‘rock beauty, Holocanthus tricolor’,
393: ‘anemone fish’,
394: ‘sturgeon’,
395: ‘gar, garfish, garpike, billfish, Lepisosteus osseus’,
396: ‘lionfish’,
397: ‘puffer, pufferfish, blowfish, globefish’,
398: ‘abacus’,
399: ‘abaya’,
400: “academic gown, academic robe, judge’s robe”,
401: ‘accordion, piano accordion, squeeze box’,
402: ‘acoustic guitar’,
403: ‘aircraft carrier, carrier, flattop, attack aircraft carrier’,
404: ‘airliner’,
405: ‘airship, dirigible’,
406: ‘altar’,
407: ‘ambulance’,
408: ‘amphibian, amphibious vehicle’,
409: ‘analog clock’,
410: ‘apiary, bee house’,
411: ‘apron’,
412: ‘ashcan, trash can, garbage can, wastebin, ash bin, ash-bin, ashbin, dustbin, trash barrel, trash bin’,
413: ‘assault rifle, assault gun’,
414: ‘backpack, back pack, knapsack, packsack, rucksack, haversack’,
415: ‘bakery, bakeshop, bakehouse’,
416: ‘balance beam, beam’,
417: ‘balloon’,
418: ‘ballpoint, ballpoint pen, ballpen, Biro’,
419: ‘Band Aid’,
420: ‘banjo’,
421: ‘bannister, banister, balustrade, balusters, handrail’,
422: ‘barbell’,
423: ‘barber chair’,
424: ‘barbershop’,
425: ‘barn’,
426: ‘barometer’,
427: ‘barrel, cask’,
428: ‘barrow, garden cart, lawn cart, wheelbarrow’,
429: ‘baseball’,
430: ‘basketball’,
431: ‘bassinet’,
432: ‘bassoon’,
433: ‘bathing cap, swimming cap’,
434: ‘bath towel’,
435: ‘bathtub, bathing tub, bath, tub’,
436: ‘beach wagon, station wagon, wagon, estate car, beach waggon, station waggon, waggon’,
437: ‘beacon, lighthouse, beacon light, pharos’,
438: ‘beaker’,
439: ‘bearskin, busby, shako’,
440: ‘beer bottle’,
441: ‘beer glass’,
442: ‘bell cote, bell cot’,
443: ‘bib’,
444: ‘bicycle-built-for-two, tandem bicycle, tandem’,
445: ‘bikini, two-piece’,
446: ‘binder, ring-binder’,
447: ‘binoculars, field glasses, opera glasses’,
448: ‘birdhouse’,
449: ‘boathouse’,
450: ‘bobsled, bobsleigh, bob’,
451: ‘bolo tie, bolo, bola tie, bola’,
452: ‘bonnet, poke bonnet’,
453: ‘bookcase’,
454: ‘bookshop, bookstore, bookstall’,
455: ‘bottlecap’,
456: ‘bow’,
457: ‘bow tie, bow-tie, bowtie’,
458: ‘brass, memorial tablet, plaque’,
459: ‘brassiere, bra, bandeau’,
460: ‘breakwater, groin, groyne, mole, bulwark, seawall, jetty’,
461: ‘breastplate, aegis, egis’,
462: ‘broom’,
463: ‘bucket, pail’,
464: ‘buckle’,
465: ‘bulletproof vest’,
466: ‘bullet train, bullet’,
467: ‘butcher shop, meat market’,
468: ‘cab, hack, taxi, taxicab’,
469: ‘caldron, cauldron’,
470: ‘candle, taper, wax light’,
471: ‘cannon’,
472: ‘canoe’,
473: ‘can opener, tin opener’,
474: ‘cardigan’,
475: ‘car mirror’,
476: ‘carousel, carrousel, merry-go-round, roundabout, whirligig’,
477: “carpenter’s kit, tool kit”,
478: ‘carton’,
479: ‘car wheel’,
480: ‘cash machine, cash dispenser, automated teller machine, automatic teller machine, automated teller, automatic teller, ATM’,
481: ‘cassette’,
482: ‘cassette player’,
483: ‘castle’,
484: ‘catamaran’,
485: ‘CD player’,
486: ‘cello, violoncello’,
487: ‘cellular telephone, cellular phone, cellphone, cell, mobile phone’,
488: ‘chain’,
489: ‘chainlink fence’,
490: ‘chain mail, ring mail, mail, chain armor, chain armour, ring armor, ring armour’,
491: ‘chain saw, chainsaw’,
492: ‘chest’,
493: ‘chiffonier, commode’,
494: ‘chime, bell, gong’,
495: ‘china cabinet, china closet’,
496: ‘Christmas stocking’,
497: ‘church, church building’,
498: ‘cinema, movie theater, movie theatre, movie house, picture palace’,
499: ‘cleaver, meat cleaver, chopper’,
500: ‘cliff dwelling’,
501: ‘cloak’,
502: ‘clog, geta, patten, sabot’,
503: ‘cocktail shaker’,
504: ‘coffee mug’,
505: ‘coffeepot’,
506: ‘coil, spiral, volute, whorl, helix’,
507: ‘combination lock’,
508: ‘computer keyboard, keypad’,
509: ‘confectionery, confectionary, candy store’,
510: ‘container ship, containership, container vessel’,
511: ‘convertible’,
512: ‘corkscrew, bottle screw’,
513: ‘cornet, horn, trumpet, trump’,
514: ‘cowboy boot’,
515: ‘cowboy hat, ten-gallon hat’,
516: ‘cradle’,
517: ‘crane’,
518: ‘crash helmet’,
519: ‘crate’,
520: ‘crib, cot’,
521: ‘Crock Pot’,
522: ‘croquet ball’,
523: ‘crutch’,
524: ‘cuirass’,
525: ‘dam, dike, dyke’,
526: ‘desk’,
527: ‘desktop computer’,
528: ‘dial telephone, dial phone’,
529: ‘diaper, nappy, napkin’,
530: ‘digital clock’,
531: ‘digital watch’,
532: ‘dining table, board’,
533: ‘dishrag, dishcloth’,
534: ‘dishwasher, dish washer, dishwashing machine’,
535: ‘disk brake, disc brake’,
536: ‘dock, dockage, docking facility’,
537: ‘dogsled, dog sled, dog sleigh’,
538: ‘dome’,
539: ‘doormat, welcome mat’,
540: ‘drilling platform, offshore rig’,
541: ‘drum, membranophone, tympan’,
542: ‘drumstick’,
543: ‘dumbbell’,
544: ‘Dutch oven’,
545: ‘electric fan, blower’,
546: ‘electric guitar’,
547: ‘electric locomotive’,
548: ‘entertainment center’,
549: ‘envelope’,
550: ‘espresso maker’,
551: ‘face powder’,
552: ‘feather boa, boa’,
553: ‘file, file cabinet, filing cabinet’,
554: ‘fireboat’,
555: ‘fire engine, fire truck’,
556: ‘fire screen, fireguard’,
557: ‘flagpole, flagstaff’,
558: ‘flute, transverse flute’,
559: ‘folding chair’,
560: ‘football helmet’,
561: ‘forklift’,
562: ‘fountain’,
563: ‘fountain pen’,
564: ‘four-poster’,
565: ‘freight car’,
566: ‘French horn, horn’,
567: ‘frying pan, frypan, skillet’,
568: ‘fur coat’,
569: ‘garbage truck, dustcart’,
570: ‘gasmask, respirator, gas helmet’,
571: ‘gas pump, gasoline pump, petrol pump, island dispenser’,
572: ‘goblet’,
573: ‘go-kart’,
574: ‘golf ball’,
575: ‘golfcart, golf cart’,
576: ‘gondola’,
577: ‘gong, tam-tam’,
578: ‘gown’,
579: ‘grand piano, grand’,
580: ‘greenhouse, nursery, glasshouse’,
581: ‘grille, radiator grille’,
582: ‘grocery store, grocery, food market, market’,
583: ‘guillotine’,
584: ‘hair slide’,
585: ‘hair spray’,
586: ‘half track’,
587: ‘hammer’,
588: ‘hamper’,
589: ‘hand blower, blow dryer, blow drier, hair dryer, hair drier’,
590: ‘hand-held computer, hand-held microcomputer’,
591: ‘handkerchief, hankie, hanky, hankey’,
592: ‘hard disc, hard disk, fixed disk’,
593: ‘harmonica, mouth organ, harp, mouth harp’,
594: ‘harp’,
595: ‘harvester, reaper’,
596: ‘hatchet’,
597: ‘holster’,
598: ‘home theater, home theatre’,
599: ‘honeycomb’,
600: ‘hook, claw’,
601: ‘hoopskirt, crinoline’,
602: ‘horizontal bar, high bar’,
603: ‘horse cart, horse-cart’,
604: ‘hourglass’,
605: ‘iPod’,
606: ‘iron, smoothing iron’,
607: “jack-o’-lantern”,
608: ‘jean, blue jean, denim’,
609: ‘jeep, landrover’,
610: ‘jersey, T-shirt, tee shirt’,
611: ‘jigsaw puzzle’,
612: ‘jinrikisha, ricksha, rickshaw’,
613: ‘joystick’,
614: ‘kimono’,
615: ‘knee pad’,
616: ‘knot’,
617: ‘lab coat, laboratory coat’,
618: ‘ladle’,
619: ‘lampshade, lamp shade’,
620: ‘laptop, laptop computer’,
621: ‘lawn mower, mower’,
622: ‘lens cap, lens cover’,
623: ‘letter opener, paper knife, paperknife’,
624: ‘library’,
625: ‘lifeboat’,
626: ‘lighter, light, igniter, ignitor’,
627: ‘limousine, limo’,
628: ‘liner, ocean liner’,
629: ‘lipstick, lip rouge’,
630: ‘Loafer’,
631: ‘lotion’,
632: ‘loudspeaker, speaker, speaker unit, loudspeaker system, speaker system’,
633: “loupe, jeweler’s loupe”,
634: ‘lumbermill, sawmill’,
635: ‘magnetic compass’,
636: ‘mailbag, postbag’,
637: ‘mailbox, letter box’,
638: ‘maillot’,
639: ‘maillot, tank suit’,
640: ‘manhole cover’,
641: ‘maraca’,
642: ‘marimba, xylophone’,
643: ‘mask’,
644: ‘matchstick’,
645: ‘maypole’,
646: ‘maze, labyrinth’,
647: ‘measuring cup’,
648: ‘medicine chest, medicine cabinet’,
649: ‘megalith, megalithic structure’,
650: ‘microphone, mike’,
651: ‘microwave, microwave oven’,
652: ‘military uniform’,
653: ‘milk can’,
654: ‘minibus’,
655: ‘miniskirt, mini’,
656: ‘minivan’,
657: ‘missile’,
658: ‘mitten’,
659: ‘mixing bowl’,
660: ‘mobile home, manufactured home’,
661: ‘Model T’,
662: ‘modem’,
663: ‘monastery’,
664: ‘monitor’,
665: ‘moped’,
666: ‘mortar’,
667: ‘mortarboard’,
668: ‘mosque’,
669: ‘mosquito net’,
670: ‘motor scooter, scooter’,
671: ‘mountain bike, all-terrain bike, off-roader’,
672: ‘mountain tent’,
673: ‘mouse, computer mouse’,
674: ‘mousetrap’,
675: ‘moving van’,
676: ‘muzzle’,
677: ‘nail’,
678: ‘neck brace’,
679: ‘necklace’,
680: ‘nipple’,
681: ‘notebook, notebook computer’,
682: ‘obelisk’,
683: ‘oboe, hautboy, hautbois’,
684: ‘ocarina, sweet potato’,
685: ‘odometer, hodometer, mileometer, milometer’,
686: ‘oil filter’,
687: ‘organ, pipe organ’,
688: ‘oscilloscope, scope, cathode-ray oscilloscope, CRO’,
689: ‘overskirt’,
690: ‘oxcart’,
691: ‘oxygen mask’,
692: ‘packet’,
693: ‘paddle, boat paddle’,
694: ‘paddlewheel, paddle wheel’,
695: ‘padlock’,
696: ‘paintbrush’,
697: “pajama, pyjama, pj’s, jammies”,
698: ‘palace’,
699: ‘panpipe, pandean pipe, syrinx’,
700: ‘paper towel’,
701: ‘parachute, chute’,
702: ‘parallel bars, bars’,
703: ‘park bench’,
704: ‘parking meter’,
705: ‘passenger car, coach, carriage’,
706: ‘patio, terrace’,
707: ‘pay-phone, pay-station’,
708: ‘pedestal, plinth, footstall’,
709: ‘pencil box, pencil case’,
710: ‘pencil sharpener’,
711: ‘perfume, essence’,
712: ‘Petri dish’,
713: ‘photocopier’,
714: ‘pick, plectrum, plectron’,
715: ‘pickelhaube’,
716: ‘picket fence, paling’,
717: ‘pickup, pickup truck’,
718: ‘pier’,
719: ‘piggy bank, penny bank’,
720: ‘pill bottle’,
721: ‘pillow’,
722: ‘ping-pong ball’,
723: ‘pinwheel’,
724: ‘pirate, pirate ship’,
725: ‘pitcher, ewer’,
726: “plane, carpenter’s plane, woodworking plane”,
727: ‘planetarium’,
728: ‘plastic bag’,
729: ‘plate rack’,
730: ‘plow, plough’,
731: “plunger, plumber’s helper”,
732: ‘Polaroid camera, Polaroid Land camera’,
733: ‘pole’,
734: ‘police van, police wagon, paddy wagon, patrol wagon, wagon, black Maria’,
735: ‘poncho’,
736: ‘pool table, billiard table, snooker table’,
737: ‘pop bottle, soda bottle’,
738: ‘pot, flowerpot’,
739: “potter’s wheel”,
740: ‘power drill’,
741: ‘prayer rug, prayer mat’,
742: ‘printer’,
743: ‘prison, prison house’,
744: ‘projectile, missile’,
745: ‘projector’,
746: ‘puck, hockey puck’,
747: ‘punching bag, punch bag, punching ball, punchball’,
748: ‘purse’,
749: ‘quill, quill pen’,
750: ‘quilt, comforter, comfort, puff’,
751: ‘racer, race car, racing car’,
752: ‘racket, racquet’,
753: ‘radiator’,
754: ‘radio, wireless’,
755: ‘radio telescope, radio reflector’,
756: ‘rain barrel’,
757: ‘recreational vehicle, RV, R.V.’,
758: ‘reel’,
759: ‘reflex camera’,
760: ‘refrigerator, icebox’,
761: ‘remote control, remote’,
762: ‘restaurant, eating house, eating place, eatery’,
763: ‘revolver, six-gun, six-shooter’,
764: ‘rifle’,
765: ‘rocking chair, rocker’,
766: ‘rotisserie’,
767: ‘rubber eraser, rubber, pencil eraser’,
768: ‘rugby ball’,
769: ‘rule, ruler’,
770: ‘running shoe’,
771: ‘safe’,
772: ‘safety pin’,
773: ‘saltshaker, salt shaker’,
774: ‘sandal’,
775: ‘sarong’,
776: ‘sax, saxophone’,
777: ‘scabbard’,
778: ‘scale, weighing machine’,
779: ‘school bus’,
780: ‘schooner’,
781: ‘scoreboard’,
782: ‘screen, CRT screen’,
783: ‘screw’,
784: ‘screwdriver’,
785: ‘seat belt, seatbelt’,
786: ‘sewing machine’,
787: ‘shield, buckler’,
788: ‘shoe shop, shoe-shop, shoe store’,
789: ‘shoji’,
790: ‘shopping basket’,
791: ‘shopping cart’,
792: ‘shovel’,
793: ‘shower cap’,
794: ‘shower curtain’,
795: ‘ski’,
796: ‘ski mask’,
797: ‘sleeping bag’,
798: ‘slide rule, slipstick’,
799: ‘sliding door’,
800: ‘slot, one-armed bandit’,
801: ‘snorkel’,
802: ‘snowmobile’,
803: ‘snowplow, snowplough’,
804: ‘soap dispenser’,
805: ‘soccer ball’,
806: ‘sock’,
807: ‘solar dish, solar collector, solar furnace’,
808: ‘sombrero’,
809: ‘soup bowl’,
810: ‘space bar’,
811: ‘space heater’,
812: ‘space shuttle’,
813: ‘spatula’,
814: ‘speedboat’,
815: “spider web, spider’s web”,
816: ‘spindle’,
817: ‘sports car, sport car’,
818: ‘spotlight, spot’,
819: ‘stage’,
820: ‘steam locomotive’,
821: ‘steel arch bridge’,
822: ‘steel drum’,
823: ‘stethoscope’,
824: ‘stole’,
825: ‘stone wall’,
826: ‘stopwatch, stop watch’,
827: ‘stove’,
828: ‘strainer’,
829: ‘streetcar, tram, tramcar, trolley, trolley car’,
830: ‘stretcher’,
831: ‘studio couch, day bed’,
832: ‘stupa, tope’,
833: ‘submarine, pigboat, sub, U-boat’,
834: ‘suit, suit of clothes’,
835: ‘sundial’,
836: ‘sunglass’,
837: ‘sunglasses, dark glasses, shades’,
838: ‘sunscreen, sunblock, sun blocker’,
839: ‘suspension bridge’,
840: ‘swab, swob, mop’,
841: ‘sweatshirt’,
842: ‘swimming trunks, bathing trunks’,
843: ‘swing’,
844: ‘switch, electric switch, electrical switch’,
845: ‘syringe’,
846: ‘table lamp’,
847: ‘tank, army tank, armored combat vehicle, armoured combat vehicle’,
848: ‘tape player’,
849: ‘teapot’,
850: ‘teddy, teddy bear’,
851: ‘television, television system’,
852: ‘tennis ball’,
853: ‘thatch, thatched roof’,
854: ‘theater curtain, theatre curtain’,
855: ‘thimble’,
856: ‘thresher, thrasher, threshing machine’,
857: ‘throne’,
858: ‘tile roof’,
859: ‘toaster’,
860: ‘tobacco shop, tobacconist shop, tobacconist’,
861: ‘toilet seat’,
862: ‘torch’,
863: ‘totem pole’,
864: ‘tow truck, tow car, wrecker’,
865: ‘toyshop’,
866: ‘tractor’,
867: ‘trailer truck, tractor trailer, trucking rig, rig, articulated lorry, semi’,
868: ‘tray’,
869: ‘trench coat’,
870: ‘tricycle, trike, velocipede’,
871: ‘trimaran’,
872: ‘tripod’,
873: ‘triumphal arch’,
874: ‘trolleybus, trolley coach, trackless trolley’,
875: ‘trombone’,
876: ‘tub, vat’,
877: ‘turnstile’,
878: ‘typewriter keyboard’,
879: ‘umbrella’,
880: ‘unicycle, monocycle’,
881: ‘upright, upright piano’,
882: ‘vacuum, vacuum cleaner’,
883: ‘vase’,
884: ‘vault’,
885: ‘velvet’,
886: ‘vending machine’,
887: ‘vestment’,
888: ‘viaduct’,
889: ‘violin, fiddle’,
890: ‘volleyball’,
891: ‘waffle iron’,
892: ‘wall clock’,
893: ‘wallet, billfold, notecase, pocketbook’,
894: ‘wardrobe, closet, press’,
895: ‘warplane, military plane’,
896: ‘washbasin, handbasin, washbowl, lavabo, wash-hand basin’,
897: ‘washer, automatic washer, washing machine’,
898: ‘water bottle’,
899: ‘water jug’,
900: ‘water tower’,
901: ‘whiskey jug’,
902: ‘whistle’,
903: ‘wig’,
904: ‘window screen’,
905: ‘window shade’,
906: ‘Windsor tie’,
907: ‘wine bottle’,
908: ‘wing’,
909: ‘wok’,
910: ‘wooden spoon’,
911: ‘wool, woolen, woollen’,
912: ‘worm fence, snake fence, snake-rail fence, Virginia fence’,
913: ‘wreck’,
914: ‘yawl’,
915: ‘yurt’,
916: ‘web site, website, internet site, site’,
917: ‘comic book’,
918: ‘crossword puzzle, crossword’,
919: ‘street sign’,
920: ‘traffic light, traffic signal, stoplight’,
921: ‘book jacket, dust cover, dust jacket, dust wrapper’,
922: ‘menu’,
923: ‘plate’,
924: ‘guacamole’,
925: ‘consomme’,
926: ‘hot pot, hotpot’,
927: ‘trifle’,
928: ‘ice cream, icecream’,
929: ‘ice lolly, lolly, lollipop, popsicle’,
930: ‘French loaf’,
931: ‘bagel, beigel’,
932: ‘pretzel’,
933: ‘cheeseburger’,
934: ‘hotdog, hot dog, red hot’,
935: ‘mashed potato’,
936: ‘head cabbage’,
937: ‘broccoli’,
938: ‘cauliflower’,
939: ‘zucchini, courgette’,
940: ‘spaghetti squash’,
941: ‘acorn squash’,
942: ‘butternut squash’,
943: ‘cucumber, cuke’,
944: ‘artichoke, globe artichoke’,
945: ‘bell pepper’,
946: ‘cardoon’,
947: ‘mushroom’,
948: ‘Granny Smith’,
949: ‘strawberry’,
950: ‘orange’,
951: ‘lemon’,
952: ‘fig’,
953: ‘pineapple, ananas’,
954: ‘banana’,
955: ‘jackfruit, jak, jack’,
956: ‘custard apple’,
957: ‘pomegranate’,
958: ‘hay’,
959: ‘carbonara’,
960: ‘chocolate sauce, chocolate syrup’,
961: ‘dough’,
962: ‘meat loaf, meatloaf’,
963: ‘pizza, pizza pie’,
964: ‘potpie’,
965: ‘burrito’,
966: ‘red wine’,
967: ‘espresso’,
968: ‘cup’,
969: ‘eggnog’,
970: ‘alp’,
971: ‘bubble’,
972: ‘cliff, drop, drop-off’,
973: ‘coral reef’,
974: ‘geyser’,
975: ‘lakeside, lakeshore’,
976: ‘promontory, headland, head, foreland’,
977: ‘sandbar, sand bar’,
978: ‘seashore, coast, seacoast, sea-coast’,
979: ‘valley, vale’,
980: ‘volcano’,
981: ‘ballplayer, baseball player’,
982: ‘groom, bridegroom’,
983: ‘scuba diver’,
984: ‘rapeseed’,
985: ‘daisy’,
986: “yellow lady’s slipper, yellow lady-slipper, Cypripedium calceolus, Cypripedium parviflorum”,
987: ‘corn’,
988: ‘acorn’,
989: ‘hip, rose hip, rosehip’,
990: ‘buckeye, horse chestnut, conker’,
991: ‘coral fungus’,
992: ‘agaric’,
993: ‘gyromitra’,
994: ‘stinkhorn, carrion fungus’,
995: ‘earthstar’,
996: ‘hen-of-the-woods, hen of the woods, Polyporus frondosus, Grifola frondosa’,
997: ‘bolete’,
998: ‘ear, spike, capitulum’,
999: ‘toilet tissue, toilet paper, bathroom tissue’}
实现代码
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
import numpy as np
import cv2
import matplotlib.pyplot as plt
from PIL import Image
xx = tf.placeholder(tf.float32,[None,224,224,3])
yy = tf.placeholder(tf.float32,[None,1000])
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME') #ksiza 中间两个表示滑块大小 strides表示扩充边缘
#第一组卷积
#第一层卷积
W_conv1 = weight_variable([3, 3, 3, 64]) #块大小 5*5 输入通道数 输出通道数
b_conv1 = bias_variable([64]) #32个数
x_image = tf.reshape(xx, [-1,224,224,3]) #-1表示任意张图像 宽高通道数
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) #卷积求和 加激活函数 #池化
#第二层卷积
W_conv2 = weight_variable([3, 3, 64, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_conv1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
#第二组卷积
W_conv3 = weight_variable([3, 3, 64, 128])
b_conv3 = bias_variable([128])
h_conv3 = tf.nn.relu(conv2d(h_pool2, W_conv3) + b_conv3)
#h_pool3 = max_pool_2x2(h_conv3)
W_conv4 = weight_variable([3, 3, 128, 128])
b_conv4 = bias_variable([128])
h_conv4 = tf.nn.relu(conv2d(h_conv3, W_conv4) + b_conv4)
h_pool4 = max_pool_2x2(h_conv4)
#第三组卷积
W_conv5 = weight_variable([3, 3, 128, 256])
b_conv5 = bias_variable([256])
h_conv5 = tf.nn.relu(conv2d(h_pool4, W_conv5) + b_conv5)
W_conv6 = weight_variable([3, 3, 256,256])
b_conv6 = bias_variable([256])
h_conv6 = tf.nn.relu(conv2d(h_conv5, W_conv6) + b_conv6)
W_conv7 = weight_variable([3, 3, 256, 256])
b_conv7 = bias_variable([256])
h_conv7 = tf.nn.relu(conv2d(h_conv6, W_conv7) + b_conv7)
h_pool7 = max_pool_2x2(h_conv7)
#第四组卷积
W_conv8 = weight_variable([3, 3, 256,512])
b_conv8 = bias_variable([512])
h_conv8 = tf.nn.relu(conv2d(h_pool7, W_conv8) + b_conv8)
#h_pool7 = max_pool_2x2(h_conv6)
W_conv9 = weight_variable([3, 3, 512,512])
b_conv9 = bias_variable([512])
h_conv9 = tf.nn.relu(conv2d(h_conv8, W_conv9) + b_conv9)
#h_pool8 = max_pool_2x2(h_conv6)
W_conv10 = weight_variable([3, 3, 512,512])
b_conv10 = bias_variable([512])
h_conv10 = tf.nn.relu(conv2d(h_conv9, W_conv10) + b_conv10)
h_pool10 = max_pool_2x2(h_conv10)
#第五组卷积
W_conv11 = weight_variable([3, 3, 512,512])
b_conv11 = bias_variable([512])
h_conv11 = tf.nn.relu(conv2d(h_pool10, W_conv11) + b_conv11)
W_conv12 = weight_variable([3, 3, 512,512])
b_conv12 = bias_variable([512])
h_conv12 = tf.nn.relu(conv2d(h_conv11, W_conv12) + b_conv12)
W_conv13 = weight_variable([3, 3, 512,512])
b_conv13 = bias_variable([512])
h_conv13 = tf.nn.relu(conv2d(h_conv12, W_conv13) + b_conv13)
h_pool13 = max_pool_2x2(h_conv13)
#第一层全连接层
W_1 = weight_variable([7*7*512, 4096]) #
b_1 = bias_variable([4096])
h_pool2_flat = tf.reshape(h_pool13, [-1, 7*7*512])
y0 = tf.nn.relu((tf.matmul(h_pool2_flat,W_1)+b_1))
#keep_prob = tf.placeholder("float")
#h_fc1_drop = tf.nn.dropout(y0, keep_prob)
#第二层全连接层
W_2 = weight_variable([4096, 4096])
b_2 = bias_variable([4096])
#h_pool3_flat = tf.reshape(h_fc1_drop, [-1, 7*7*64])
y1 = tf.nn.relu((tf.matmul(y0,W_2)+b_2))
#三
W_3 = weight_variable([4096, 1000])
b_3 = bias_variable([1000])
#h_pool3_flat = tf.reshape(h_fc1_drop, [-1, 7*7*64])
y2 = tf.nn.relu((tf.matmul(y1,W_3)+b_3))
cross_entropy = -tf.reduce_sum(yy*tf.log(y2))
optimizer = tf.train.GradientDescentOptimizer(0.0001)
train = optimizer.minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y2,1), tf.argmax(yy,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
qqq = tf.argmax(y2,1)
parameters = []
parameters += [W_conv1,b_conv1,W_conv2,b_conv2,W_conv3,b_conv3,W_conv4,b_conv4,W_conv5,b_conv5,W_conv6,b_conv6,
W_conv7, b_conv7, W_conv8, b_conv8, W_conv9, b_conv9, W_conv10, b_conv10, W_conv11, b_conv11, W_conv12, b_conv12, W_conv13, b_conv13,
W_1,b_1,W_2,b_2,W_3,b_3]
mean = tf.constant([123.68, 116.779, 103.939], dtype=tf.float32, shape=[1, 1, 1, 3], name='img_mean')
ss = xx-mean
with tf.Session() as sess:
# 读取文件
fr = open("D:\\a\\ImageNet1000.txt", 'r+')
content = fr.read()
dic = eval(content)
print((dic))
weights = np.load("D:\\a\\vgg16_weights.npz")
keys = np.sort(weights.files)
for i, k in enumerate(keys):
print(i, k, np.shape(weights[k]))
sess.run(parameters[i].assign(weights[k]))
im = np.asarray(Image.open("D:\\a\\9.jpg").resize((224, 224)))
im1 = np.asarray(Image.open("D:\\a\\9.jpg"))
print(im.shape)
#im = im-sess.run(mean)
im = np.expand_dims(im, axis=0) #扩展第0维表示图片数 向外扩一圈
print(im.shape)
print([sess.run(qqq, feed_dict={xx: im})[0]]) #表示第一张图片的最大索引 因为是二维的
print("the finale class is {}".format(dic[sess.run(qqq, feed_dict={xx: im})[0]]))
plt.title(dic[sess.run(qqq, feed_dict={xx: im})[0]])
plt.imshow(im[0]) #第0维表示图片数 第一二三维表示宽 高 通道数
plt.show() #压缩以后的图
plt.imshow(im1) #原图
plt.show()
#b.tofile("....bin")
#import struct
#filename="F:\\hyj\\ICTA2019\\dataSIFT\\" + str(j+1) + "lable.bin"
"""
f=open(filename,"rb")
z=[]
for i in range(2):
data=f.read(4)
data_float=struct.unpack("f",data)[0]
z.append(data_float)
"""
代码解析:实现了利用VGG网络实现对图片的分类。1000类。该网络由五组卷积神经网络和三层全连接层构成。然后将训练好的权重数据导入。输入图片,返回对应的分类,并将其显示出来。一定要将输入的图调整为大小224*224。
利用opencv自带的算法实现目标跟踪
1)
import cv2
import sys
(major_ver, minor_ver, subminor_ver) = (cv2.__version__).split('.')
if __name__ == '__main__':
# Set up tracker.
# Instead of MIL, you can also use
tracker_types = ['BOOSTING', 'MIL', 'KCF', 'TLD', 'MEDIANFLOW', 'GOTURN', 'MOSSE', 'CSRT']
tracker_type = tracker_types[3]
if int( minor_ver) < 3:
tracker = cv2.Tracker_create(tracker_type)
else:
if tracker_type == 'BOOSTING':
tracker = cv2.TrackerBoosting_create()
if tracker_type == 'MIL':
tracker = cv2.TrackerMIL_create()
if tracker_type == 'KCF':
tracker = cv2.TrackerKCF_create()
if tracker_type == 'TLD':
tracker = cv2.TrackerTLD_create()
if tracker_type == 'MEDIANFLOW':
tracker = cv2.TrackerMedianFlow_create()
if tracker_type == 'GOTURN':
tracker = cv2.TrackerGOTURN_create()
if tracker_type == 'MOSSE':
tracker = cv2.TrackerMOSSE_create()
if tracker_type == "CSRT":
tracker = cv2.TrackerCSRT_create()
# Read video
video = cv2.VideoCapture(0)
# Exit if video not opened.
if not video.isOpened():
print
"Could not open video"
sys.exit()
# Read first frame.
#ok, frame = video.read()
ok, frame=video.read()
if not ok:
print("Cannot read video file")
sys.exit()
writer = cv2.VideoWriter()
fourcc = cv2.VideoWriter_fourcc(*'MP4V')
writer.open('D:\\a\\3.mp4', fourcc,30, (int(video.get(cv2.CAP_PROP_FRAME_WIDTH)),int(video.get(cv2.CAP_PROP_FRAME_HEIGHT))),True)
bbox = cv2.selectROI(frame, False)
# Initialize tracker with first frame and bounding box
ok = tracker.init(frame, bbox)
while True:
# Read a new frame
ok, frame = video.read()
#ok, frame = cap.read()
if not ok:
break
# Start timer
timer = cv2.getTickCount()
# Update tracker
ok, bbox = tracker.update(frame)
# Calculate Frames per second (FPS) GetTickcount函数:它返回从操作系统启动到当前所经的计时周期数。getTickFrequency函数:返回每秒的计时周期数。
fps = cv2.getTickFrequency() / (cv2.getTickCount() - timer);
# Draw bounding box
if ok:
# Tracking success
p1 = (int(bbox[0]), int(bbox[1]))
p2 = (int(bbox[0] + bbox[2]), int(bbox[1] + bbox[3]))
cv2.rectangle(frame, p1, p2, (255, 0, 0), 2, 1)
else:
# Tracking failure
cv2.putText(frame, "Tracking failure detected", (100, 80), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 0, 255), 2)
# Display tracker type on frame
cv2.putText(frame, tracker_type + " Tracker", (100, 20), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (50, 170, 50), 2);
# Display FPS on frame
cv2.putText(frame, "FPS : " + str(int(fps)), (100, 50), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (50, 170, 50), 2);
# Display result
cv2.imshow("Tracking", frame)
# Exit if ESC pressed
k = cv2.waitKey(1) & 0xff
if k == 27: break
writer.write(frame)
代码解析:通过摄像头采集图像,框选追踪的物体,利用选取追踪算法实现目标最终,并将其结果写入到一个视频文件当中。
在DEIBAN10 上实现风格迁移(利用神经网络,VGG网络)
代码实现:
train.py
# coding = utf-8
import tensorflow as tf
import numpy as np
slim = tf.contrib.slim
def arg_scope(weight_decay=0.0005):
with slim.arg_scope([slim.conv2d, slim.fully_connected, slim.conv2d_transpose],
activation_fn=None,
weights_regularizer=slim.l2_regularizer(weight_decay),
biases_initializer=tf.zeros_initializer()):
with slim.arg_scope([slim.conv2d, slim.conv2d_transpose], padding='SAME') as arg_sc:
return arg_sc
def img_scale(x, scale):
weight = x.get_shape()[1].value
height = x.get_shape()[2].value
try:
out = tf.image.resize_nearest_neighbor(x, size=(weight*scale, height*scale))
except:
out = tf.image.resize_images(x, size=[weight*scale, height*scale])
return out
# net = slim.conv2d(net, 4096, [1, 1], scope='fc7')
def res_module(x, outchannel, name):
with tf.variable_scope(name_or_scope=name):
out1 = slim.conv2d(x, outchannel, [3, 3], stride=1, scope='conv1')
out1 = relu(out1)
out2 = slim.conv2d(out1, outchannel, [3, 3], stride=1, scope='conv2')
out2 = relu(out2)
return x+out2
def instance_norm(x):
epsilon = 1e-9
mean, var = tf.nn.moments(x, [1, 2], keep_dims=True)
return tf.div(tf.subtract(x, mean), tf.sqrt(tf.add(var, epsilon)))
def relu(x):
return tf.nn.relu(x)
def gen_net(imgs, reuse, name, is_train=True):
imgs_shape = tf.shape(imgs)
imgs = tf.pad(imgs, [[0, 0], [10, 10], [10, 10], [0, 0]], mode='REFLECT')
with tf.variable_scope(name, reuse=reuse) as vs:
# encoder : three convs layers
out1 = slim.conv2d(imgs, 32, [9, 9], scope='conv1')
out1 = relu(instance_norm(out1))
out2 = slim.conv2d(out1, 64, [3, 3], stride=2, scope='conv2')
out2 = instance_norm(out2)
# out2 = relu(img_scale(out2, 0.5))
out2 = slim.conv2d(out2, 128, [3, 3], stride=2, scope='conv3')
out2 = instance_norm(out2)
# out2 = relu(img_scale(out2, 0.5))
# transform
out3 = res_module(out2, 128, name='residual1')
out3 = res_module(out3, 128, name='residual2')
out3 = res_module(out3, 128, name='residual3')
out3 = res_module(out3, 128, name='residual4')
# decoder
out4 = img_scale(out3, 2)
out4 = slim.conv2d(out4, 64, [3, 3], stride=1, scope='conv4')
out4 = relu(instance_norm(out4))
# out4 = img_scale(out4, 128)
out4 = img_scale(out4, 2)
out4 = slim.conv2d(out4, 32, [3, 3], stride=1, scope='conv5')
out4 = relu(instance_norm(out4))
# out4 = img_scale(out4, 256)
out = slim.conv2d(out4, 3, [9, 9], scope='conv6')
out = tf.nn.tanh(instance_norm(out))
variables = tf.contrib.framework.get_variables(vs)
out = (out + 1) * 127.5
height = out.get_shape()[1].value # if is_train else tf.shape(out)[0]
width = out.get_shape()[2].value # if is_train else tf.shape(out)[1]
# out = tf.slice(out, [0, 10, 10, 0], tf.stack([-1, height - 20, width - 20, -1]))
out = tf.image.crop_to_bounding_box(out, 10, 10, height-20, width-20)
# out = tf.reshape(out, imgs_shape)
return out, variables
"""caculate the loss"""
import vgg_simple as vgg
import os
def styleloss(f1, f2, f3, f4):
gen_f, _, style_f = tf.split(f1, 3, 0)
size = tf.size(gen_f)
style_loss = tf.nn.l2_loss(gram(gen_f) - gram(style_f))*2 / tf.to_float(size)
gen_f, _, style_f = tf.split(f2, 3, 0)
size = tf.size(gen_f)
style_loss += tf.nn.l2_loss(gram(gen_f) - gram(style_f)) * 2 / tf.to_float(size)
gen_f, _, style_f = tf.split(f3, 3, 0)
size = tf.size(gen_f)
style_loss += tf.nn.l2_loss(gram(gen_f) - gram(style_f)) * 2 / tf.to_float(size)
gen_f, _, style_f = tf.split(f4, 3, 0)
size = tf.size(gen_f)
style_loss += tf.nn.l2_loss(gram(gen_f) - gram(style_f)) * 2 / tf.to_float(size)
return style_loss
def gram(layer):
shape = tf.shape(layer)
num_images = shape[0]
width = shape[1]
height = shape[2]
num_filters = shape[3]
filters = tf.reshape(layer, tf.stack([num_images, -1, num_filters]))
grams = tf.matmul(filters, filters, transpose_a=True) / tf.to_float(width * height * num_filters)
return grams
if __name__ == '__main__':
with tf.device('/cpu:0'):
a = [[1., 2.], [3., 4.], [5, 6]]
b, c, e = tf.split(a, 3, 0)
with tf.Session() as sess:
c, d, g = sess.run([b, c, e])
print c
print d
print g
model.py
# coding = utf-8
import tensorflow as tf
import numpy as np
slim = tf.contrib.slim
def arg_scope(weight_decay=0.0005):
with slim.arg_scope([slim.conv2d, slim.fully_connected, slim.conv2d_transpose],
activation_fn=None,
weights_regularizer=slim.l2_regularizer(weight_decay),
biases_initializer=tf.zeros_initializer()):
with slim.arg_scope([slim.conv2d, slim.conv2d_transpose], padding='SAME') as arg_sc:
return arg_sc
def img_scale(x, scale):
weight = x.get_shape()[1].value
height = x.get_shape()[2].value
try:
out = tf.image.resize_nearest_neighbor(x, size=(weight*scale, height*scale))
except:
out = tf.image.resize_images(x, size=[weight*scale, height*scale])
return out
# net = slim.conv2d(net, 4096, [1, 1], scope='fc7')
def res_module(x, outchannel, name):
with tf.variable_scope(name_or_scope=name):
out1 = slim.conv2d(x, outchannel, [3, 3], stride=1, scope='conv1')
out1 = relu(out1)
out2 = slim.conv2d(out1, outchannel, [3, 3], stride=1, scope='conv2')
out2 = relu(out2)
return x+out2
def instance_norm(x):
epsilon = 1e-9
mean, var = tf.nn.moments(x, [1, 2], keep_dims=True)
return tf.div(tf.subtract(x, mean), tf.sqrt(tf.add(var, epsilon)))
def relu(x):
return tf.nn.relu(x)
def gen_net(imgs, reuse, name, is_train=True):
imgs_shape = tf.shape(imgs)
imgs = tf.pad(imgs, [[0, 0], [10, 10], [10, 10], [0, 0]], mode='REFLECT')
with tf.variable_scope(name, reuse=reuse) as vs:
# encoder : three convs layers
out1 = slim.conv2d(imgs, 32, [9, 9], scope='conv1')
out1 = relu(instance_norm(out1))
out2 = slim.conv2d(out1, 64, [3, 3], stride=2, scope='conv2')
out2 = instance_norm(out2)
# out2 = relu(img_scale(out2, 0.5))
out2 = slim.conv2d(out2, 128, [3, 3], stride=2, scope='conv3')
out2 = instance_norm(out2)
# out2 = relu(img_scale(out2, 0.5))
# transform
out3 = res_module(out2, 128, name='residual1') #残差网络
out3 = res_module(out3, 128, name='residual2')
out3 = res_module(out3, 128, name='residual3')
out3 = res_module(out3, 128, name='residual4')
# decoder
out4 = img_scale(out3, 2)
out4 = slim.conv2d(out4, 64, [3, 3], stride=1, scope='conv4')
out4 = relu(instance_norm(out4))
# out4 = img_scale(out4, 128)
out4 = img_scale(out4, 2)
out4 = slim.conv2d(out4, 32, [3, 3], stride=1, scope='conv5')
out4 = relu(instance_norm(out4))
# out4 = img_scale(out4, 256)
out = slim.conv2d(out4, 3, [9, 9], scope='conv6')
out = tf.nn.tanh(instance_norm(out))
variables = tf.contrib.framework.get_variables(vs)
out = (out + 1) * 127.5
height = out.get_shape()[1].value # if is_train else tf.shape(out)[0]
width = out.get_shape()[2].value # if is_train else tf.shape(out)[1]
# out = tf.slice(out, [0, 10, 10, 0], tf.stack([-1, height - 20, width - 20, -1]))
out = tf.image.crop_to_bounding_box(out, 10, 10, height-20, width-20)
# out = tf.reshape(out, imgs_shape)
return out, variables
"""caculate the loss"""
import vgg_simple as vgg
import os
def styleloss(f1, f2, f3, f4):
gen_f, _, style_f = tf.split(f1, 3, 0)
size = tf.size(gen_f)
style_loss = tf.nn.l2_loss(gram(gen_f) - gram(style_f))*2 / tf.to_float(size)
gen_f, _, style_f = tf.split(f2, 3, 0)
size = tf.size(gen_f)
style_loss += tf.nn.l2_loss(gram(gen_f) - gram(style_f)) * 2 / tf.to_float(size)
gen_f, _, style_f = tf.split(f3, 3, 0)
size = tf.size(gen_f)
style_loss += tf.nn.l2_loss(gram(gen_f) - gram(style_f)) * 2 / tf.to_float(size)
gen_f, _, style_f = tf.split(f4, 3, 0)
size = tf.size(gen_f)
style_loss += tf.nn.l2_loss(gram(gen_f) - gram(style_f)) * 2 / tf.to_float(size)
return style_loss
def gram(layer):
shape = tf.shape(layer)
num_images = shape[0]
width = shape[1]
height = shape[2]
num_filters = shape[3]
filters = tf.reshape(layer, tf.stack([num_images, -1, num_filters]))
grams = tf.matmul(filters, filters, transpose_a=True) / tf.to_float(width * height * num_filters)
return grams
if __name__ == '__main__':
with tf.device('/cpu:0'):
a = [[1., 2.], [3., 4.], [5, 6]]
b, c, e = tf.split(a, 3, 0)
with tf.Session() as sess:
c, d, g = sess.run([b, c, e])
print c
print d
print g
实现了风格迁移。上面代码实现首先经过VGG网络训练。最终得到是以某一张风格图为背景的图,而内容图可以随意,最终训练生成的是以某一张风格图为背景的图。
在DEIBAN10 上实现目标检测(利用神经网络,VGG网络)
代码实现:YOLOv3算法
train.py:
# coding: utf-8
from __future__ import division, print_function
import tensorflow as tf
import numpy as np
import logging
from tqdm import trange
import args
from utils.data_utils import get_batch_data
from utils.misc_utils import shuffle_and_overwrite, make_summary, config_learning_rate, config_optimizer, AverageMeter
from utils.eval_utils import evaluate_on_cpu, evaluate_on_gpu, get_preds_gpu, voc_eval, parse_gt_rec
from utils.nms_utils import gpu_nms
from model import yolov3
# setting loggers
logging.basicConfig(level=logging.DEBUG, format='%(asctime)s %(levelname)s %(message)s',
datefmt='%a, %d %b %Y %H:%M:%S', filename=args.progress_log_path, filemode='w')
# setting placeholders
is_training = tf.placeholder(tf.bool, name="phase_train")
handle_flag = tf.placeholder(tf.string, [], name='iterator_handle_flag')
# register the gpu nms operation here for the following evaluation scheme
pred_boxes_flag = tf.placeholder(tf.float32, [1, None, None])
pred_scores_flag = tf.placeholder(tf.float32, [1, None, None])
gpu_nms_op = gpu_nms(pred_boxes_flag, pred_scores_flag, args.class_num, args.nms_topk, args.score_threshold, args.nms_threshold)
##################
# tf.data pipeline
##################
train_dataset = tf.data.TextLineDataset(args.train_file)
train_dataset = train_dataset.shuffle(args.train_img_cnt)
train_dataset = train_dataset.batch(args.batch_size)
train_dataset = train_dataset.map(
lambda x: tf.py_func(get_batch_data,
inp=[x, args.class_num, args.img_size, args.anchors, 'train', args.multi_scale_train, args.use_mix_up, args.letterbox_resize],
Tout=[tf.int64, tf.float32, tf.float32, tf.float32, tf.float32]),
num_parallel_calls=args.num_threads
)
train_dataset = train_dataset.prefetch(args.prefetech_buffer)
val_dataset = tf.data.TextLineDataset(args.val_file)
val_dataset = val_dataset.batch(1)
val_dataset = val_dataset.map(
lambda x: tf.py_func(get_batch_data,
inp=[x, args.class_num, args.img_size, args.anchors, 'val', False, False, args.letterbox_resize],
Tout=[tf.int64, tf.float32, tf.float32, tf.float32, tf.float32]),
num_parallel_calls=args.num_threads
)
val_dataset.prefetch(args.prefetech_buffer)
iterator = tf.data.Iterator.from_structure(train_dataset.output_types, train_dataset.output_shapes)
train_init_op = iterator.make_initializer(train_dataset)
val_init_op = iterator.make_initializer(val_dataset)
# get an element from the chosen dataset iterator
image_ids, image, y_true_13, y_true_26, y_true_52 = iterator.get_next()
y_true = [y_true_13, y_true_26, y_true_52]
# tf.data pipeline will lose the data `static` shape, so we need to set it manually
image_ids.set_shape([None])
image.set_shape([None, None, None, 3])
for y in y_true:
y.set_shape([None, None, None, None, None])
##################
# Model definition
##################
yolo_model = yolov3(args.class_num, args.anchors, args.use_label_smooth, args.use_focal_loss, args.batch_norm_decay, args.weight_decay, use_static_shape=False)
with tf.variable_scope('yolov3'):
pred_feature_maps = yolo_model.forward(image, is_training=is_training)
loss = yolo_model.compute_loss(pred_feature_maps, y_true)
y_pred = yolo_model.predict(pred_feature_maps)
l2_loss = tf.losses.get_regularization_loss()
# setting restore parts and vars to update
saver_to_restore = tf.train.Saver(var_list=tf.contrib.framework.get_variables_to_restore(include=args.restore_include, exclude=args.restore_exclude))
update_vars = tf.contrib.framework.get_variables_to_restore(include=args.update_part)
tf.summary.scalar('train_batch_statistics/total_loss', loss[0])
tf.summary.scalar('train_batch_statistics/loss_xy', loss[1])
tf.summary.scalar('train_batch_statistics/loss_wh', loss[2])
tf.summary.scalar('train_batch_statistics/loss_conf', loss[3])
tf.summary.scalar('train_batch_statistics/loss_class', loss[4])
tf.summary.scalar('train_batch_statistics/loss_l2', l2_loss)
tf.summary.scalar('train_batch_statistics/loss_ratio', l2_loss / loss[0])
global_step = tf.Variable(float(args.global_step), trainable=False, collections=[tf.GraphKeys.LOCAL_VARIABLES])
if args.use_warm_up:
learning_rate = tf.cond(tf.less(global_step, args.train_batch_num * args.warm_up_epoch),
lambda: args.learning_rate_init * global_step / (args.train_batch_num * args.warm_up_epoch),
lambda: config_learning_rate(args, global_step - args.train_batch_num * args.warm_up_epoch))
else:
learning_rate = config_learning_rate(args, global_step)
tf.summary.scalar('learning_rate', learning_rate)
if not args.save_optimizer:
saver_to_save = tf.train.Saver()
saver_best = tf.train.Saver()
optimizer = config_optimizer(args.optimizer_name, learning_rate)
# set dependencies for BN ops
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
# train_op = optimizer.minimize(loss[0] + l2_loss, var_list=update_vars, global_step=global_step)
# apply gradient clip to avoid gradient exploding
gvs = optimizer.compute_gradients(loss[0] + l2_loss, var_list=update_vars)
clip_grad_var = [gv if gv[0] is None else [
tf.clip_by_norm(gv[0], 100.), gv[1]] for gv in gvs]
train_op = optimizer.apply_gradients(clip_grad_var, global_step=global_step)
if args.save_optimizer:
print('Saving optimizer parameters to checkpoint! Remember to restore the global_step in the fine-tuning afterwards.')
saver_to_save = tf.train.Saver()
saver_best = tf.train.Saver()
with tf.Session() as sess:
sess.run([tf.global_variables_initializer(), tf.local_variables_initializer()])
saver_to_restore.restore(sess, args.restore_path)
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter(args.log_dir, sess.graph)
print('\n----------- start to train -----------\n')
best_mAP = -np.Inf
for epoch in range(args.total_epoches):
sess.run(train_init_op)
loss_total, loss_xy, loss_wh, loss_conf, loss_class = AverageMeter(), AverageMeter(), AverageMeter(), AverageMeter(), AverageMeter()
for i in trange(args.train_batch_num):
_, summary, __y_pred, __y_true, __loss, __global_step, __lr = sess.run(
[train_op, merged, y_pred, y_true, loss, global_step, learning_rate],
feed_dict={is_training: True})
writer.add_summary(summary, global_step=__global_step)
loss_total.update(__loss[0], len(__y_pred[0]))
loss_xy.update(__loss[1], len(__y_pred[0]))
loss_wh.update(__loss[2], len(__y_pred[0]))
loss_conf.update(__loss[3], len(__y_pred[0]))
loss_class.update(__loss[4], len(__y_pred[0]))
if __global_step % args.train_evaluation_step == 0 and __global_step > 0:
# recall, precision = evaluate_on_cpu(__y_pred, __y_true, args.class_num, args.nms_topk, args.score_threshold, args.nms_threshold)
recall, precision = evaluate_on_gpu(sess, gpu_nms_op, pred_boxes_flag, pred_scores_flag, __y_pred, __y_true, args.class_num, args.nms_threshold)
info = "Epoch: {}, global_step: {} | loss: total: {:.2f}, xy: {:.2f}, wh: {:.2f}, conf: {:.2f}, class: {:.2f} | ".format(
epoch, int(__global_step), loss_total.average, loss_xy.average, loss_wh.average, loss_conf.average, loss_class.average)
info += 'Last batch: rec: {:.3f}, prec: {:.3f} | lr: {:.5g}'.format(recall, precision, __lr)
print(info)
logging.info(info)
writer.add_summary(make_summary('evaluation/train_batch_recall', recall), global_step=__global_step)
writer.add_summary(make_summary('evaluation/train_batch_precision', precision), global_step=__global_step)
if np.isnan(loss_total.average):
print('****' * 10)
raise ArithmeticError(
'Gradient exploded! Please train again and you may need modify some parameters.')
# NOTE: this is just demo. You can set the conditions when to save the weights.
if epoch % args.save_epoch == 0 and epoch > 0:
if loss_total.average <= 2.:
saver_to_save.save(sess, args.save_dir + 'model-epoch_{}_step_{}_loss_{:.4f}_lr_{:.5g}'.format(epoch, int(__global_step), loss_total.average, __lr))
# switch to validation dataset for evaluation
if epoch % args.val_evaluation_epoch == 0 and epoch >= args.warm_up_epoch:
sess.run(val_init_op)
val_loss_total, val_loss_xy, val_loss_wh, val_loss_conf, val_loss_class = \
AverageMeter(), AverageMeter(), AverageMeter(), AverageMeter(), AverageMeter()
val_preds = []
for j in trange(args.val_img_cnt):
__image_ids, __y_pred, __loss = sess.run([image_ids, y_pred, loss],
feed_dict={is_training: False})
pred_content = get_preds_gpu(sess, gpu_nms_op, pred_boxes_flag, pred_scores_flag, __image_ids, __y_pred)
val_preds.extend(pred_content)
val_loss_total.update(__loss[0])
val_loss_xy.update(__loss[1])
val_loss_wh.update(__loss[2])
val_loss_conf.update(__loss[3])
val_loss_class.update(__loss[4])
# calc mAP
rec_total, prec_total, ap_total = AverageMeter(), AverageMeter(), AverageMeter()
gt_dict = parse_gt_rec(args.val_file, args.img_size, args.letterbox_resize)
info = '======> Epoch: {}, global_step: {}, lr: {:.6g} <======\n'.format(epoch, __global_step, __lr)
for ii in range(args.class_num):
npos, nd, rec, prec, ap = voc_eval(gt_dict, val_preds, ii, iou_thres=args.eval_threshold, use_07_metric=args.use_voc_07_metric)
info += 'EVAL: Class {}: Recall: {:.4f}, Precision: {:.4f}, AP: {:.4f}\n'.format(ii, rec, prec, ap)
rec_total.update(rec, npos)
prec_total.update(prec, nd)
ap_total.update(ap, 1)
mAP = ap_total.average
info += 'EVAL: Recall: {:.4f}, Precison: {:.4f}, mAP: {:.4f}\n'.format(rec_total.average, prec_total.average, mAP)
info += 'EVAL: loss: total: {:.2f}, xy: {:.2f}, wh: {:.2f}, conf: {:.2f}, class: {:.2f}\n'.format(
val_loss_total.average, val_loss_xy.average, val_loss_wh.average, val_loss_conf.average, val_loss_class.average)
print(info)
logging.info(info)
if mAP > best_mAP:
best_mAP = mAP
saver_best.save(sess, args.save_dir + 'best_model_Epoch_{}_step_{}_mAP_{:.4f}_loss_{:.4f}_lr_{:.7g}'.format(
epoch, int(__global_step), best_mAP, val_loss_total.average, __lr))
writer.add_summary(make_summary('evaluation/val_mAP', mAP), global_step=epoch)
writer.add_summary(make_summary('evaluation/val_recall', rec_total.average), global_step=epoch)
writer.add_summary(make_summary('evaluation/val_precision', prec_total.average), global_step=epoch)
writer.add_summary(make_summary('validation_statistics/total_loss', val_loss_total.average), global_step=epoch)
writer.add_summary(make_summary('validation_statistics/loss_xy', val_loss_xy.average), global_step=epoch)
writer.add_summary(make_summary('validation_statistics/loss_wh', val_loss_wh.average), global_step=epoch)
writer.add_summary(make_summary('validation_statistics/loss_conf', val_loss_conf.average), global_step=epoch)
writer.add_summary(make_summary('validation_statistics/loss_class', val_loss_class.average), global_step=epoch)
model.py
# coding=utf-8
# for better understanding about yolov3 architecture, refer to this website (in Chinese):
# https://blog.csdn.net/leviopku/article/details/82660381
from __future__ import division, print_function
import tensorflow as tf
slim = tf.contrib.slim
from utils.layer_utils import conv2d, darknet53_body, yolo_block, upsample_layer
class yolov3(object):
def __init__(self, class_num, anchors, use_label_smooth=False, use_focal_loss=False, batch_norm_decay=0.999, weight_decay=5e-4, use_static_shape=True):
# self.anchors = [[10, 13], [16, 30], [33, 23],
# [30, 61], [62, 45], [59, 119],
# [116, 90], [156, 198], [373,326]]
self.class_num = class_num
self.anchors = anchors
self.batch_norm_decay = batch_norm_decay
self.use_label_smooth = use_label_smooth
self.use_focal_loss = use_focal_loss
self.weight_decay = weight_decay
# inference speed optimization
# if `use_static_shape` is True, use tensor.get_shape(), otherwise use tf.shape(tensor)
# static_shape is slightly faster
self.use_static_shape = use_static_shape
def forward(self, inputs, is_training=False, reuse=False):
# the input img_size, form: [height, weight]
# it will be used later
self.img_size = tf.shape(inputs)[1:3]
# set batch norm params
batch_norm_params = {
'decay': self.batch_norm_decay,
'epsilon': 1e-05,
'scale': True,
'is_training': is_training,
'fused': None, # Use fused batch norm if possible.
}
with slim.arg_scope([slim.conv2d, slim.batch_norm], reuse=reuse):
with slim.arg_scope([slim.conv2d],
normalizer_fn=slim.batch_norm,
normalizer_params=batch_norm_params,
biases_initializer=None,
activation_fn=lambda x: tf.nn.leaky_relu(x, alpha=0.1),
weights_regularizer=slim.l2_regularizer(self.weight_decay)):
with tf.variable_scope('darknet53_body'):
route_1, route_2, route_3 = darknet53_body(inputs)
with tf.variable_scope('yolov3_head'):
inter1, net = yolo_block(route_3, 512)
feature_map_1 = slim.conv2d(net, 3 * (5 + self.class_num), 1,
stride=1, normalizer_fn=None,
activation_fn=None, biases_initializer=tf.zeros_initializer())
feature_map_1 = tf.identity(feature_map_1, name='feature_map_1')
inter1 = conv2d(inter1, 256, 1)
inter1 = upsample_layer(inter1, route_2.get_shape().as_list() if self.use_static_shape else tf.shape(route_2))
concat1 = tf.concat([inter1, route_2], axis=3)
inter2, net = yolo_block(concat1, 256)
feature_map_2 = slim.conv2d(net, 3 * (5 + self.class_num), 1,
stride=1, normalizer_fn=None,
activation_fn=None, biases_initializer=tf.zeros_initializer())
feature_map_2 = tf.identity(feature_map_2, name='feature_map_2')
inter2 = conv2d(inter2, 128, 1)
inter2 = upsample_layer(inter2, route_1.get_shape().as_list() if self.use_static_shape else tf.shape(route_1))
concat2 = tf.concat([inter2, route_1], axis=3)
_, feature_map_3 = yolo_block(concat2, 128)
feature_map_3 = slim.conv2d(feature_map_3, 3 * (5 + self.class_num), 1,
stride=1, normalizer_fn=None,
activation_fn=None, biases_initializer=tf.zeros_initializer())
feature_map_3 = tf.identity(feature_map_3, name='feature_map_3')
return feature_map_1, feature_map_2, feature_map_3
def reorg_layer(self, feature_map, anchors):
'''
feature_map: a feature_map from [feature_map_1, feature_map_2, feature_map_3] returned
from `forward` function
anchors: shape: [3, 2]
'''
# NOTE: size in [h, w] format! don't get messed up!
grid_size = feature_map.get_shape().as_list()[1:3] if self.use_static_shape else tf.shape(feature_map)[1:3] # [13, 13]
# the downscale ratio in height and weight
ratio = tf.cast(self.img_size / grid_size, tf.float32)
# rescale the anchors to the feature_map
# NOTE: the anchor is in [w, h] format!
rescaled_anchors = [(anchor[0] / ratio[1], anchor[1] / ratio[0]) for anchor in anchors]
feature_map = tf.reshape(feature_map, [-1, grid_size[0], grid_size[1], 3, 5 + self.class_num])
# split the feature_map along the last dimension
# shape info: take 416x416 input image and the 13*13 feature_map for example:
# box_centers: [N, 13, 13, 3, 2] last_dimension: [center_x, center_y]
# box_sizes: [N, 13, 13, 3, 2] last_dimension: [width, height]
# conf_logits: [N, 13, 13, 3, 1]
# prob_logits: [N, 13, 13, 3, class_num]
box_centers, box_sizes, conf_logits, prob_logits = tf.split(feature_map, [2, 2, 1, self.class_num], axis=-1)
box_centers = tf.nn.sigmoid(box_centers)
# use some broadcast tricks to get the mesh coordinates
grid_x = tf.range(grid_size[1], dtype=tf.int32)
grid_y = tf.range(grid_size[0], dtype=tf.int32)
grid_x, grid_y = tf.meshgrid(grid_x, grid_y)
x_offset = tf.reshape(grid_x, (-1, 1))
y_offset = tf.reshape(grid_y, (-1, 1))
x_y_offset = tf.concat([x_offset, y_offset], axis=-1)
# shape: [13, 13, 1, 2]
x_y_offset = tf.cast(tf.reshape(x_y_offset, [grid_size[0], grid_size[1], 1, 2]), tf.float32)
# get the absolute box coordinates on the feature_map
box_centers = box_centers + x_y_offset
# rescale to the original image scale
box_centers = box_centers * ratio[::-1]
# avoid getting possible nan value with tf.clip_by_value
box_sizes = tf.exp(box_sizes) * rescaled_anchors
# box_sizes = tf.clip_by_value(tf.exp(box_sizes), 1e-9, 100) * rescaled_anchors
# rescale to the original image scale
box_sizes = box_sizes * ratio[::-1]
# shape: [N, 13, 13, 3, 4]
# last dimension: (center_x, center_y, w, h)
boxes = tf.concat([box_centers, box_sizes], axis=-1)
# shape:
# x_y_offset: [13, 13, 1, 2]
# boxes: [N, 13, 13, 3, 4], rescaled to the original image scale
# conf_logits: [N, 13, 13, 3, 1]
# prob_logits: [N, 13, 13, 3, class_num]
return x_y_offset, boxes, conf_logits, prob_logits
def predict(self, feature_maps):
'''
Receive the returned feature_maps from `forward` function,
the produce the output predictions at the test stage.
'''
feature_map_1, feature_map_2, feature_map_3 = feature_maps
feature_map_anchors = [(feature_map_1, self.anchors[6:9]),
(feature_map_2, self.anchors[3:6]),
(feature_map_3, self.anchors[0:3])]
reorg_results = [self.reorg_layer(feature_map, anchors) for (feature_map, anchors) in feature_map_anchors]
def _reshape(result):
x_y_offset, boxes, conf_logits, prob_logits = result
grid_size = x_y_offset.get_shape().as_list()[:2] if self.use_static_shape else tf.shape(x_y_offset)[:2]
boxes = tf.reshape(boxes, [-1, grid_size[0] * grid_size[1] * 3, 4])
conf_logits = tf.reshape(conf_logits, [-1, grid_size[0] * grid_size[1] * 3, 1])
prob_logits = tf.reshape(prob_logits, [-1, grid_size[0] * grid_size[1] * 3, self.class_num])
# shape: (take 416*416 input image and feature_map_1 for example)
# boxes: [N, 13*13*3, 4]
# conf_logits: [N, 13*13*3, 1]
# prob_logits: [N, 13*13*3, class_num]
return boxes, conf_logits, prob_logits
boxes_list, confs_list, probs_list = [], [], []
for result in reorg_results:
boxes, conf_logits, prob_logits = _reshape(result)
confs = tf.sigmoid(conf_logits)
probs = tf.sigmoid(prob_logits)
boxes_list.append(boxes)
confs_list.append(confs)
probs_list.append(probs)
# collect results on three scales
# take 416*416 input image for example:
# shape: [N, (13*13+26*26+52*52)*3, 4]
boxes = tf.concat(boxes_list, axis=1)
# shape: [N, (13*13+26*26+52*52)*3, 1]
confs = tf.concat(confs_list, axis=1)
# shape: [N, (13*13+26*26+52*52)*3, class_num]
probs = tf.concat(probs_list, axis=1)
center_x, center_y, width, height = tf.split(boxes, [1, 1, 1, 1], axis=-1)
x_min = center_x - width / 2
y_min = center_y - height / 2
x_max = center_x + width / 2
y_max = center_y + height / 2
boxes = tf.concat([x_min, y_min, x_max, y_max], axis=-1)
return boxes, confs, probs
def loss_layer(self, feature_map_i, y_true, anchors):
'''
calc loss function from a certain scale
input:
feature_map_i: feature maps of a certain scale. shape: [N, 13, 13, 3*(5 + num_class)] etc.
y_true: y_ture from a certain scale. shape: [N, 13, 13, 3, 5 + num_class + 1] etc.
anchors: shape [9, 2]
'''
# size in [h, w] format! don't get messed up!
grid_size = tf.shape(feature_map_i)[1:3]
# the downscale ratio in height and weight
ratio = tf.cast(self.img_size / grid_size, tf.float32)
# N: batch_size
N = tf.cast(tf.shape(feature_map_i)[0], tf.float32)
x_y_offset, pred_boxes, pred_conf_logits, pred_prob_logits = self.reorg_layer(feature_map_i, anchors)
###########
# get mask
###########
# shape: take 416x416 input image and 13*13 feature_map for example:
# [N, 13, 13, 3, 1]
object_mask = y_true[..., 4:5]
# the calculation of ignore mask if referred from
# https://github.com/pjreddie/darknet/blob/master/src/yolo_layer.c#L179
ignore_mask = tf.TensorArray(tf.float32, size=0, dynamic_size=True)
def loop_cond(idx, ignore_mask):
return tf.less(idx, tf.cast(N, tf.int32))
def loop_body(idx, ignore_mask):
# shape: [13, 13, 3, 4] & [13, 13, 3] ==> [V, 4]
# V: num of true gt box of each image in a batch
valid_true_boxes = tf.boolean_mask(y_true[idx, ..., 0:4], tf.cast(object_mask[idx, ..., 0], 'bool'))
# shape: [13, 13, 3, 4] & [V, 4] ==> [13, 13, 3, V]
iou = self.box_iou(pred_boxes[idx], valid_true_boxes)
# shape: [13, 13, 3]
best_iou = tf.reduce_max(iou, axis=-1)
# shape: [13, 13, 3]
ignore_mask_tmp = tf.cast(best_iou < 0.5, tf.float32)
# finally will be shape: [N, 13, 13, 3]
ignore_mask = ignore_mask.write(idx, ignore_mask_tmp)
return idx + 1, ignore_mask
_, ignore_mask = tf.while_loop(cond=loop_cond, body=loop_body, loop_vars=[0, ignore_mask])
ignore_mask = ignore_mask.stack()
# shape: [N, 13, 13, 3, 1]
ignore_mask = tf.expand_dims(ignore_mask, -1)
# shape: [N, 13, 13, 3, 2]
pred_box_xy = pred_boxes[..., 0:2]
pred_box_wh = pred_boxes[..., 2:4]
# get xy coordinates in one cell from the feature_map
# numerical range: 0 ~ 1
# shape: [N, 13, 13, 3, 2]
true_xy = y_true[..., 0:2] / ratio[::-1] - x_y_offset
pred_xy = pred_box_xy / ratio[::-1] - x_y_offset
# get_tw_th
# numerical range: 0 ~ 1
# shape: [N, 13, 13, 3, 2]
true_tw_th = y_true[..., 2:4] / anchors
pred_tw_th = pred_box_wh / anchors
# for numerical stability
true_tw_th = tf.where(condition=tf.equal(true_tw_th, 0),
x=tf.ones_like(true_tw_th), y=true_tw_th)
pred_tw_th = tf.where(condition=tf.equal(pred_tw_th, 0),
x=tf.ones_like(pred_tw_th), y=pred_tw_th)
true_tw_th = tf.log(tf.clip_by_value(true_tw_th, 1e-9, 1e9))
pred_tw_th = tf.log(tf.clip_by_value(pred_tw_th, 1e-9, 1e9))
# box size punishment:
# box with smaller area has bigger weight. This is taken from the yolo darknet C source code.
# shape: [N, 13, 13, 3, 1]
box_loss_scale = 2. - (y_true[..., 2:3] / tf.cast(self.img_size[1], tf.float32)) * (y_true[..., 3:4] / tf.cast(self.img_size[0], tf.float32))
############
# loss_part
############
# mix_up weight
# [N, 13, 13, 3, 1]
mix_w = y_true[..., -1:]
# shape: [N, 13, 13, 3, 1]
xy_loss = tf.reduce_sum(tf.square(true_xy - pred_xy) * object_mask * box_loss_scale * mix_w) / N
wh_loss = tf.reduce_sum(tf.square(true_tw_th - pred_tw_th) * object_mask * box_loss_scale * mix_w) / N
# shape: [N, 13, 13, 3, 1]
conf_pos_mask = object_mask
conf_neg_mask = (1 - object_mask) * ignore_mask
conf_loss_pos = conf_pos_mask * tf.nn.sigmoid_cross_entropy_with_logits(labels=object_mask, logits=pred_conf_logits)
conf_loss_neg = conf_neg_mask * tf.nn.sigmoid_cross_entropy_with_logits(labels=object_mask, logits=pred_conf_logits)
# TODO: may need to balance the pos-neg by multiplying some weights
conf_loss = conf_loss_pos + conf_loss_neg
if self.use_focal_loss:
alpha = 1.0
gamma = 2.0
# TODO: alpha should be a mask array if needed
focal_mask = alpha * tf.pow(tf.abs(object_mask - tf.sigmoid(pred_conf_logits)), gamma)
conf_loss *= focal_mask
conf_loss = tf.reduce_sum(conf_loss * mix_w) / N
# shape: [N, 13, 13, 3, 1]
# whether to use label smooth
if self.use_label_smooth:
delta = 0.01
label_target = (1 - delta) * y_true[..., 5:-1] + delta * 1. / self.class_num
else:
label_target = y_true[..., 5:-1]
class_loss = object_mask * tf.nn.sigmoid_cross_entropy_with_logits(labels=label_target, logits=pred_prob_logits) * mix_w
class_loss = tf.reduce_sum(class_loss) / N
return xy_loss, wh_loss, conf_loss, class_loss
def box_iou(self, pred_boxes, valid_true_boxes):
'''
param:
pred_boxes: [13, 13, 3, 4], (center_x, center_y, w, h)
valid_true: [V, 4]
'''
# [13, 13, 3, 2]
pred_box_xy = pred_boxes[..., 0:2]
pred_box_wh = pred_boxes[..., 2:4]
# shape: [13, 13, 3, 1, 2]
pred_box_xy = tf.expand_dims(pred_box_xy, -2)
pred_box_wh = tf.expand_dims(pred_box_wh, -2)
# [V, 2]
true_box_xy = valid_true_boxes[:, 0:2]
true_box_wh = valid_true_boxes[:, 2:4]
# [13, 13, 3, 1, 2] & [V, 2] ==> [13, 13, 3, V, 2]
intersect_mins = tf.maximum(pred_box_xy - pred_box_wh / 2.,
true_box_xy - true_box_wh / 2.)
intersect_maxs = tf.minimum(pred_box_xy + pred_box_wh / 2.,
true_box_xy + true_box_wh / 2.)
intersect_wh = tf.maximum(intersect_maxs - intersect_mins, 0.)
# shape: [13, 13, 3, V]
intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1]
# shape: [13, 13, 3, 1]
pred_box_area = pred_box_wh[..., 0] * pred_box_wh[..., 1]
# shape: [V]
true_box_area = true_box_wh[..., 0] * true_box_wh[..., 1]
# shape: [1, V]
true_box_area = tf.expand_dims(true_box_area, axis=0)
# [13, 13, 3, V]
iou = intersect_area / (pred_box_area + true_box_area - intersect_area + 1e-10)
return iou
def compute_loss(self, y_pred, y_true):
'''
param:
y_pred: returned feature_map list by `forward` function: [feature_map_1, feature_map_2, feature_map_3]
y_true: input y_true by the tf.data pipeline
'''
loss_xy, loss_wh, loss_conf, loss_class = 0., 0., 0., 0.
anchor_group = [self.anchors[6:9], self.anchors[3:6], self.anchors[0:3]]
# calc loss in 3 scales
for i in range(len(y_pred)):
result = self.loss_layer(y_pred[i], y_true[i], anchor_group[i])
loss_xy += result[0]
loss_wh += result[1]
loss_conf += result[2]
loss_class += result[3]
total_loss = loss_xy + loss_wh + loss_conf + loss_class
return [total_loss, loss_xy, loss_wh, loss_conf, loss_class]
代码实现了 视频或图像的相关目标检测。
对抗神经网络
1.实现ministe数据集 来搭建对抗神经网络
import os, time, itertools, imageio, pickle
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# G(z)
def generator(x): #生成器
# initializers
w_init = tf.truncated_normal_initializer(mean=0, stddev=0.02)
b_init = tf.constant_initializer(0.)
# 1st hidden layer
w0 = tf.get_variable('G_w0', [x.get_shape()[1], 256], initializer=w_init)
b0 = tf.get_variable('G_b0', [256], initializer=b_init)
h0 = tf.nn.relu(tf.matmul(x, w0) + b0)
# 2nd hidden layer
w1 = tf.get_variable('G_w1', [h0.get_shape()[1], 512], initializer=w_init)
b1 = tf.get_variable('G_b1', [512], initializer=b_init)
h1 = tf.nn.relu(tf.matmul(h0, w1) + b1)
# 3rd hidden layer
w2 = tf.get_variable('G_w2', [h1.get_shape()[1], 1024], initializer=w_init)
b2 = tf.get_variable('G_b2', [1024], initializer=b_init)
h2 = tf.nn.relu(tf.matmul(h1, w2) + b2)
# output hidden layer
w3 = tf.get_variable('G_w3', [h2.get_shape()[1], 784], initializer=w_init)
b3 = tf.get_variable('G_b3', [784], initializer=b_init)
o = tf.nn.tanh(tf.matmul(h2, w3) + b3)
return o
# D(x)
def discriminator(x, drop_out): #判别器
# initializers
w_init = tf.truncated_normal_initializer(mean=0, stddev=0.02)
b_init = tf.constant_initializer(0.)
# 1st hidden layer
w0 = tf.get_variable('D_w0', [x.get_shape()[1], 1024], initializer=w_init)
b0 = tf.get_variable('D_b0', [1024], initializer=b_init)
h0 = tf.nn.relu(tf.matmul(x, w0) + b0)
h0 = tf.nn.dropout(h0, drop_out)
# 2nd hidden layer
w1 = tf.get_variable('D_w1', [h0.get_shape()[1], 512], initializer=w_init)
b1 = tf.get_variable('D_b1', [512], initializer=b_init)
h1 = tf.nn.relu(tf.matmul(h0, w1) + b1)
h1 = tf.nn.dropout(h1, drop_out)
# 3rd hidden layer
w2 = tf.get_variable('D_w2', [h1.get_shape()[1], 256], initializer=w_init)
b2 = tf.get_variable('D_b2', [256], initializer=b_init)
h2 = tf.nn.relu(tf.matmul(h1, w2) + b2)
h2 = tf.nn.dropout(h2, drop_out)
# output layer
w3 = tf.get_variable('D_w3', [h2.get_shape()[1], 1], initializer=w_init)
b3 = tf.get_variable('D_b3', [1], initializer=b_init)
o = tf.sigmoid(tf.matmul(h2, w3) + b3)
return o
fixed_z_ = np.random.normal(0, 1, (25, 100))
def show_result(num_epoch, show = False, save = False, path = 'result.png', isFix=False):
z_ = np.random.normal(0, 1, (25, 100))
if isFix:
test_images = sess.run(G_z, {z: fixed_z_, drop_out: 0.0})
else:
test_images = sess.run(G_z, {z: z_, drop_out: 0.0})
size_figure_grid = 5
fig, ax = plt.subplots(size_figure_grid, size_figure_grid, figsize=(5, 5))
for i, j in itertools.product(range(size_figure_grid), range(size_figure_grid)):
ax[i, j].get_xaxis().set_visible(False)
ax[i, j].get_yaxis().set_visible(False)
for k in range(5*5):
i = k // 5
j = k % 5
ax[i, j].cla()
ax[i, j].imshow(np.reshape(test_images[k], (28, 28)), cmap='gray')
label = 'Epoch {0}'.format(num_epoch)
fig.text(0.5, 0.04, label, ha='center')
plt.savefig(path)
if show:
plt.show()
else:
plt.close()
def show_train_hist(hist, show = False, save = False, path = 'Train_hist.png'):
x = range(len(hist['D_losses']))
y1 = hist['D_losses']
y2 = hist['G_losses']
plt.plot(x, y1, label='D_loss')
plt.plot(x, y2, label='G_loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend(loc=4)
plt.grid(True)
plt.tight_layout()
if save:
plt.savefig(path)
if show:
plt.show()
else:
plt.close()
# training parameters
batch_size = 100
lr = 0.0002
train_epoch = 1001
# load MNIST
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
train_set = (mnist.train.images - 0.5) / 0.5 # normalization; range: -1 ~ 1
# networks : generator
with tf.variable_scope('G'):
z = tf.placeholder(tf.float32, shape=(None, 100))
G_z = generator(z)
# networks : discriminator
with tf.variable_scope('D') as scope:
drop_out = tf.placeholder(dtype=tf.float32, name='drop_out')
x = tf.placeholder(tf.float32, shape=(None, 784))
D_real = discriminator(x, drop_out)
scope.reuse_variables()
D_fake = discriminator(G_z, drop_out)
# loss for each network
eps = 1e-2
D_loss = tf.reduce_mean(-tf.log(D_real + eps) - tf.log(1 - D_fake + eps))
G_loss = tf.reduce_mean(-tf.log(D_fake + eps))
# trainable variables for each network
t_vars = tf.trainable_variables()
D_vars = [var for var in t_vars if 'D_' in var.name]
G_vars = [var for var in t_vars if 'G_' in var.name]
# optimizer for each network
D_optim = tf.train.AdamOptimizer(lr).minimize(D_loss, var_list=D_vars)
G_optim = tf.train.AdamOptimizer(lr).minimize(G_loss, var_list=G_vars)
# open session and initialize all variables
sess = tf.InteractiveSession()
tf.global_variables_initializer().run()
# results save folder
if not os.path.isdir('MNIST_GAN_results'):
os.mkdir('MNIST_GAN_results')
if not os.path.isdir('MNIST_GAN_results/Random_results'):
os.mkdir('MNIST_GAN_results/Random_results')
if not os.path.isdir('MNIST_GAN_results/Fixed_results'):
os.mkdir('MNIST_GAN_results/Fixed_results')
train_hist = {}
train_hist['D_losses'] = []
train_hist['G_losses'] = []
train_hist['per_epoch_ptimes'] = []
train_hist['total_ptime'] = []
# training-loop
np.random.seed(int(time.time()))
start_time = time.time()
for epoch in range(train_epoch):
G_losses = []
D_losses = []
epoch_start_time = time.time()
for iter in range(train_set.shape[0] // batch_size):
# update discriminator
x_ = train_set[iter*batch_size:(iter+1)*batch_size]
z_ = np.random.normal(0, 1, (batch_size, 100))
loss_d_, _ = sess.run([D_loss, D_optim], {x: x_, z: z_, drop_out: 0.3})
D_losses.append(loss_d_)
# update generator
z_ = np.random.normal(0, 1, (batch_size, 100))
loss_g_, _ = sess.run([G_loss, G_optim], {z: z_, drop_out: 0.3})
G_losses.append(loss_g_)
epoch_end_time = time.time()
per_epoch_ptime = epoch_end_time - epoch_start_time
print('[%d/%d] - ptime: %.2f loss_d: %.3f, loss_g: %.3f' % ((epoch + 1), train_epoch, per_epoch_ptime, np.mean(D_losses), np.mean(G_losses)))
p = 'MNIST_GAN_results/Random_results/MNIST_GAN_' + str(epoch + 1) + '.png'
fixed_p = 'MNIST_GAN_results/Fixed_results/MNIST_GAN_' + str(epoch + 1) + '.png'
show_result((epoch + 1), save=True, path=p, isFix=False)
show_result((epoch + 1), save=True, path=fixed_p, isFix=True)
train_hist['D_losses'].append(np.mean(D_losses))
train_hist['G_losses'].append(np.mean(G_losses))
train_hist['per_epoch_ptimes'].append(per_epoch_ptime)
end_time = time.time()
total_ptime = end_time - start_time
train_hist['total_ptime'].append(total_ptime)
print('Avg per epoch ptime: %.2f, total %d epochs ptime: %.2f' % (np.mean(train_hist['per_epoch_ptimes']), train_epoch, total_ptime))
print("Training finish!... save training results")
with open('MNIST_GAN_results/train_hist.pkl', 'wb') as f:
pickle.dump(train_hist, f)
show_train_hist(train_hist, save=True, path='MNIST_GAN_results/MNIST_GAN_train_hist.png')
images = []
for e in range(train_epoch):
img_name = 'MNIST_GAN_results/Fixed_results/MNIST_GAN_' + str(e + 1) + '.png'
images.append(imageio.imread(img_name))
imageio.mimsave('MNIST_GAN_results/generation_animation.gif', images, fps=5)
sess.close()
代码解析:
通过利用ministe数据集实现搭建生成器和判决器。最终能够使其训练好的网络实现对0-9数字的不断训练更新。达到准确的结果。