测试点
选择的测试点有两个
- 一个是用户与浏览器(客户端)之间的节点,也就是模拟用户对浏览器的操作与获取的响应来进行测试,称之为“前测试点”(Front Test Point)。
- 一个是浏览器(客户端)与服务器之间的节点,也就是模拟客户端来向服务器收发HTTP请求来进行测试,称之为“后测试点”(Back Test Point)。
我们没有在服务器内部设置测试点,也就是说我们将服务器视为一个黑盒。
测试阶段目标(Roadmap)
- alpha阶段:
- 搭建自动测试环境
- 在后测试点,实现测试逻辑和测试数据分离,为持续测试做基础。
- 在前测试点,实现自动化测试,为持续测试做基础。
- 检验各功能在理想条件下是否如规格书所描述地运行。
- 理想条件:完全符合预期的简单输入。
- 搭建自动测试环境
- beta阶段:
- 兼容性检查:测试在不同终端、不同平台、不同浏览器上的运行情况。
- 不同终端:mobile、PC
- 不同平台:mac OS, windows, android, ios
- 不同浏览器:chrome, edge, firefox
- 安全性检查:使用攻击性的测试思路,挖掘安全性漏洞。
- 泄露敏感信息的代码、包、数据、接口。
- 可以被利用的接口。
- 在被攻破后的可执行的应急措施。
- 兼容性检查:测试在不同终端、不同平台、不同浏览器上的运行情况。
- gamma阶段:
- 易用性检查:检验是否存在不合理的设计/不易用的情景。
- 良好的响应性。
- 快捷的操作。
- 直观的反馈。
- 需求的满足程度。
- 鲁棒性检查:检验边界条件,在非异常的极端/特殊情况下各功能是否如规格书所描述地运行。
- 在后测试点,构建复杂测试样例。
- 在前测试点,构造usercase模拟一套用户的操作,并在此基础上实现并行测试。
- 并行测试:构建多个usercase,随机伪并发执行,检验是否运作正常。
- 易用性检查:检验是否存在不合理的设计/不易用的情景。
各阶段出口条件:
- alpha:在理想条件下运行符合规格描述。
- beta:通过安全性、兼容性检查。并通过alpha阶段的回归测试。
- gamma:通过鲁棒性、易用性检查。并通过alpha, beta阶段的回归测试。
测试工具
测试架构完全使用Django的django.test模块。
服务器端对两个测试点使用不同的做法:
- 对于前测试点,因为需要在js代码中指定后端的域名+端口,所以无法使用django.test模块初始化时提供的具有随机端口的django测试服务器。所以我们每次进行前测试的时候,都需要手动在本地建立一个测试服务器,然后手动刷新一下它的数据库,将测试数据填充进去。
- 对于后测试点,直接使用django的fixture系统来填充测试数据库。
客户端对两个测试点采用不同的工具来模拟:
- 对于前测试点,使用Selenium模拟客户端。
- 对于后测试点,使用Django原生的Client模拟客户端。
前测试点
设计模式
使用Page Object作为Design Pattern。即,将每个页面作为一个类,将该页面提供的服务作为接口。每个类内部自己维护该页面的元素定位符。
测试环境的搭建
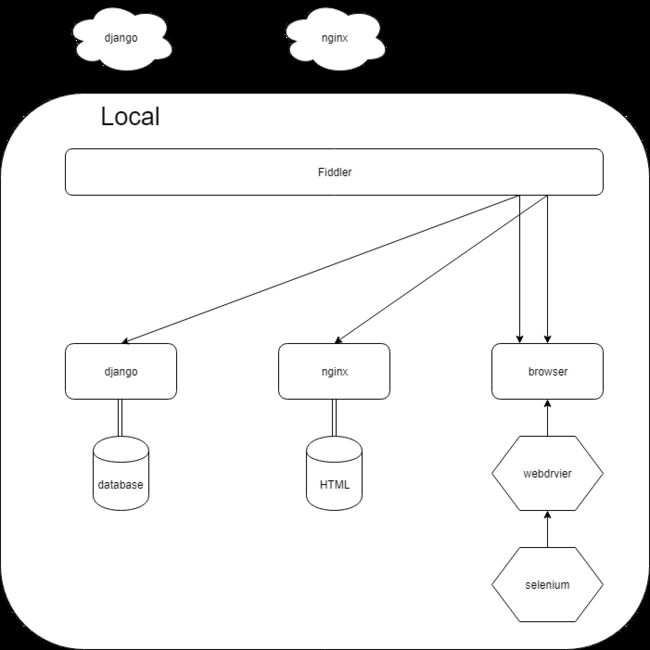
使用Fiddler对域名和端口进行重映射,将对远端服务器的请求转换为对本地服务器的请求。
通过使用openssl自己签个证书以及使用werkzeug_debugger_runserver实现本机支持https。
本地劫持腾讯验证码服务器
因为我们使用了腾讯验证码作为安全措施,但这个措施会导致自动测试的不可行。解决方案是本地架设了一台假的腾讯验证码服务器,然后利用Fiddler劫持一切发送给真的腾讯验证码服务器上的请求给假的上面去,从而确保自动化测试的可行性。
端口情况
- nginx服务器,开在80端口,负责分发html, js文件。
- django服务器,开在随机用户端口,负责后端接口的供应。
- faketx服务器,开在3668端口,负责假装自己是腾讯的验证码服务器
- testcase进程,开在随机用户端口,负责调用selenium,然后selenium打开浏览器,请求nginx服务器获取网页文件,再通过ajax请求django服务器获取后端数据。
代码覆盖率计算方法
使用jscover,启用local-storage来支持跨页面的插桩记录存取。详见。
基本流程如下:
- 使用jscover对前端js文件插桩。
- 修改测试代码,使得每个WebDriver被销毁前会保存插桩记录。
- 合并插桩记录,得到覆盖率报告。
不过需要注意的是,仅仅只对js文件插桩,裸写在html文件中的js代码不会被纳入覆盖率的统计中。
测试思路
细的来说:
- 检查用户需要知道的信息的元素是否出现在页面上。
- 检查页面上是否出现了不该出现的元素。(例如已经登录的用户却在界面上找到了登录按钮)
- 检查用户操作是否得到预期的响应。
- 检查页面跳转逻辑是否如逾期执行。
- 检查异常处理是否合理完善。
粗的来说:
- 检查典型用户的一套操作流程是否能正常执行,并且用户是否能够的得到他们想要的信息。
- 检查用户的异常操作是否会得到合理的报错,并能顺利恢复现场。
测试样例总览
此处不将列出详细的测试用例内容,只列出每族测试样例的概述。
- [+]号表示还未完成。
- 页面跳转逻辑检查
- 功能检查
- 登录功能
- 注册功能
- 注销功能
- 搜索功能
- 切页功能
- 评论发表功能
- 个人信息修改功能
- 评论赞踩功能
- [+]页面冗余检查
- 兼容性检查
- [+]页面长宽比兼容性检查:在不同长宽比的浏览器界面下是否都能有良好响应
- 浏览器兼容性检查:在不同浏览器中是否都能有良好响应
- chrome, firefox, edge
- [+]国产浏览器
- [+]操作系统兼容性检查
- [+]硬件平台兼容性检查
- [+]易用性检查
- 在登录/注册信息不完整/错误的情况下能否给出有效提示引导用户完善信息
- 在评论超字数的情况下能否给出有效提示引导用户
- 各功能的响应速度是否合理
后测试点
前提
我们默认一切规格规定的渠道的用户输入都已在前端被充分检验正确性(例如,注册时用户名、密码是否符合格式),故在后端不做任何相关测试。
代码覆盖率计算方法
使用python的coverage获取代码覆盖率。仅计算rateMyCoure目录下的代码。
测试思路
- 检查各接口是否如规格描述地正确响应。
- 检查是否存在不该暴露给用户的资源也暴露了。
- 使用代码覆盖率,检查是否存在无用代码。
测试样例总览
此处不将列出详细的测试用例内容,只列出每族测试样例的概述。
- [+]号表示还未完成。
- 标准检查:对于非常良好的输入的情况下,各接口是否给出正确输出。
- [+]边界检查:对于满足传入需求,但处在边界的输入,各接口是否能给出正确输出。
- 安全性检查:是否存在能在无权限的情况下获取敏感信息的接口,或在无限制的情况下占用过多服务器资源的接口。
Beta阶段测试结果
因为大量使用了python的subTest,很多测试样例被转变成了一组子测试样例的线性执行序列,所以统计测试样例数目已经变成一件没啥意义的事情了,以后也都不将统计。
前测试点
commit: 5c6e26850dd8f74f423433f78d60535647bd90ef
Bug:
- 切页功能:1, 2, 3
- 赞踩功能:1
- Edge的兼容性问题:1, 2
- 其他:1
Invalid:
- 切页功能:1
js覆盖率: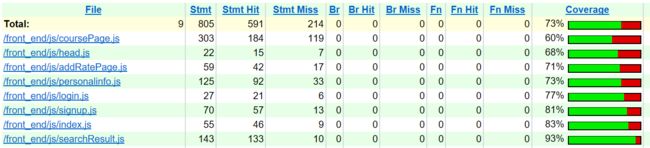
后测试点
commit: ff51f9ec21efb90cce08e5585c90cb7235cd7da1
Bug:
- 评分功能:1
- 评分计算:1
Invalid:
- 评分计算:1
python覆盖率: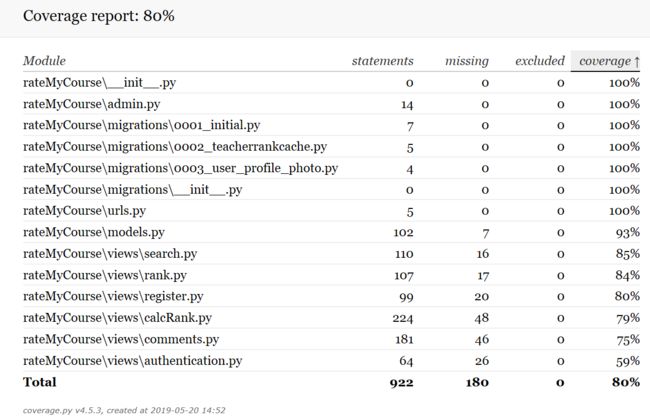
安全性检查
- 分析书
- 解决报告书
主要解决的问题:
- Django的秘钥的存放
- CSRF攻击
- XSS攻击
- Clickjacking攻击
- 启用HSTS
回答问题
在测试过程中发现了多少Bug?有哪些是Beta阶段的新Bug?有哪些是Alpha阶段没有发现的Bug?
边敲边测的单元测试中发现的bug数没有统计,因为没有进issue。黑盒测试的过程中发现了9个bug。没有alpha阶段遗留下来的bug,全部都是beta阶段的新bug。
你是怎么进行场景测试(scenario testing)的?包括你预期不同的用户会怎样使用你的软件?他们有什么需求和目标?你的软件提供的功能怎么组合起来满足他们的需要?(仅描述新功能即可)
场景测试
模拟用户的一系列操作,并在每个操作的步骤上检查页面是否如用户期望进行。
- 一名无聊的学生,需求是查看别人对课程的评价,并且发表自己的评价
- 注册
- 登录
- 搜索课程
- 点进课程页面
- 查看评论
- 点赞/踩评论
- 添加评论
- 注销
- 赞踩功能能够让这名学生在探索课程评价的时候更好地参与并互动进去。
- 一名选课中的学生,需求是大量浏览别人对课程的评价
- 注册
- 登录
- 搜索课程
- 点进课程页面
- 查看评论
- 若已经检索完,则注销,否则返回3
- 切页功能可以使这名学生在大量检索课程时得到更佳高效、舒适的体验。
你是否有回归测试确保新功能的加入没有影响已有功能?请给出一到两个测试用例并解释。
所写的所有测试样例都是回归测试的一部分。
def test_regist_exist_user(self):
page = HomePage(self.driver, self.domain)
page = page.goRegistPage()
page.fillForm(
name="rbq",
email="[email protected]",
password="abc123!@#",
repassword="abc123!@#",
)
page.submit() # Should still be RegistPage
rs(min=3)
page.checkIsSelf()注册功能是alpha阶段已经实现的,在alpha阶段写完的这个测试样例在beta阶段就成为了回归测试的测试样例。它做的事情是打开主页,进入注册页面,填写表单,提交,然后检查是否注册失败(因为是试图注册一个已经注册了的用户)。
给出你的测试矩阵(test matrix),也即在什么样的平台、硬件配置、浏览器类型……上对你的软件进行测试?
| Window Size | Browser |
|---|---|
| PC | Chrome |
| Mobile(Only for Chrome) | Firefox |
| Edge |
你的软件Beta版本的出口条件(exit criteria)是什么?也即在什么条件下,认定你的软件已经足够好,可以发布Beta版本?
通过安全性、兼容性检查。并通过alpha阶段的回归测试。主要功能的代码在测试中都被覆盖到。