本文转载自:斗篷客(ID:wearecloakman)
区块链如同 2000 年前后的互联网,正一步步走入我们每个人的生活中。
作为区块链整套技术中的核心之一,智能合约/虚拟机的设计在推动区块链创新的进程中,正扮演着越来越重要的角色。由此出发,虚拟机的设计也呈现着百花齐放的姿态。
秘猿科技根据对智能合约层以及区块链虚拟机的理解与反思,基于 RISC-V 硬件指令集打造了虚拟机 CKB-VM。在这次分享中,我们将会介绍我们选择 RISC-V 打造虚拟机的缘由,并展示 RISC-V 为我们的区块链落地与创新中带来的前所未有的灵活性。
迄今为止,CKB-VM 是市面上唯一一个能在智能合约中直接部署密码学算法的区块链虚拟机,其他任何区块链虚拟机层都不具备实现达到与 CKB-VM 相近的能力。
与此同时,我们认为 CKB-VM 并不仅仅在区块链领域中适用, 在芯片逐渐碎片化的今天,CKB-VM 可以为云应用开发者提供一个稳定的指令集,并通过底层优化实现,将代码运行在更多体系结构之上,实现真正意义上的 write once, run anywhere 的愿景。
分享提纲:
1、探讨区块链对智能合约的需求,以及现有设计中遇到的问题
2、介绍 CKB-VM 的核心设计,以及我们如何通过引入 RISC-V 指令集,来解 CKB-VM 遇到的实际问题
3、探讨 CKB-VM 在区块链之外的云原生领域中同样广阔的应用
4、回顾在 CKB-VM 实现过程中遇到的挑战与应对方式,展示未来的工作计划
现有区块链虚拟机困境以及如何使用 RISC-V 解决
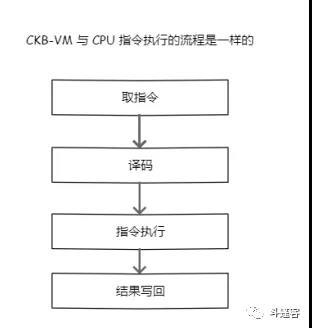
在一个通用计算机平台上模拟另一个计算机具有悠久的历史,我们通常将这种位于源 ISA 和目标 ISA 之间的翻译软件称为虚拟机。
自从以太坊开始,在区块链系统中加入的智能合约代表了区块链从一个单一的公共账本到金融服务应用角色转变的一个重要阶段。

为了支撑智能合约中的业务,我们希望底层虚拟机足够安全,这不仅仅意味着虚拟机本身的安全性, 还意味着虚拟机字节码本身是易审计和易静态分析的,同时除了安全性之外,性能也是一个重要的考虑目标,这要求从源 ISA 到目标 ISA 之间的翻译可以使用尽量少的代码完成。
除了安全性和性能之外,我们还希望这个虚拟机的周边生态是完善的,有多种不同的高级语言,多种不同的 IDE 和数量众多的开发者辅助工具帮助应用开发者编写出健壮的代码。
目前最广泛流行在世界上的区块链虚拟机只有两类: EVM 与 WebAssembly。
EVM 它存在诸多的问题, 例如它的动态跳转(dynamic jumps)机制导致 EVM 代码无法被静态分析,导致 EVM 上安全性漏洞频发,而它的 256 位整数又导致虚拟机性能极差,这还不是最糟糕的,最糟糕的问题是:由于区块链的性质我们无法对 EVM 做任何根本上的升级。
在 EVM 负重前行之时,一些人转而使用 WebAssembly,但是很难说 WebAssembly 是一个好的选择。

WebAssembly,顾名思义是为了 Web 而发明的,它被设计为运行在浏览器之中,但目前的现实是,区块链虚拟机对性能的要求已经超过一个浏览器客户端对性能的要求。
同时 WebAssembly 的字节码是一种 AST(抽象语法树)字节码而非传统意义上的指令, 前者是一种树形结构,而后者则是一种一维的指令流。这种区别使得在加载 WebAssembly 的过程中需要消耗许多时间用于解析二进制数据到 AST。但在区块链的世界中,由于大多数应用的计算量都不高,也不会像浏览器那样长时间运行,因此代码的加载速度和其执行速度同等重要。
如果我们可以在区块链虚拟机上采用 RISV-V 指令集,不但可以有效解决以上的问题,还有许多额外的好处:
- RISC-V 是一个简单的硬件指令集, 经过良好的设计和广泛的测试,不会存在像 EVM 那样过多的设计失误;
- RISC-V 工作在更低的层次(相比 EVM 和 WebAssembly)。目前世界的一个趋势是「简单的硬件, 复杂的软件」,我们可以在如路由器、智能家居等很多领域发现这一点,区块链也应该如此;
- RISC-V 程序采用 ELF 封装, 其装载速度更快;
- RISC-V 程序可以很容易做 JIT 和 AOT 编译,其性能上限更高;
- RISC-V 拥有完善的工具链, 可以很方便的对程序进行分析和调试,对于广泛的开发者群体来说这至关重要;
- 最后, 率先在区块链虚拟机上使用 RISC-V,对未来在 RISC-V 硬件上部署区块链节点有强大的推动作用。
CKB-VM 的核心设计逻辑
在一个资源受限的环境下,如何对资源进行有效的管理和使用是构建一个高性能平台的关键,区块链上的所有用户在有限的时间里共享有限的资源,这使得区块链应用程序在其分配的资源量内高效运行变得更加重要。
这里有两个关键的点,其一是高效运行,其二是限制资源的使用量 。基于此,CKB-VM的核心设计逻辑:
高效运行
![]()
![]()
CKB-VM 决定引入 RISC-V 指令集的关键点之一是,绝大多数 RISC-V IMC 指令集内的指令都可以语义上等价几条 x64 指令的组合,这意味着我们只需要极少的额外消耗就能在 x64 平台上构建一个 RISC-V 虚拟机。
例如 RISC-V 中的 AND 指令与 BGE 指令都能在 x64 平台下以极其精简的方式实现,这里摘取 CKB-VM 的 ASM 解释器实现 AND 指令的代码,你可以看到我们使用了一些宏,这让整个流程变得异常清晰:
![]()

资源限制
CKB-VM 允许开发人员自定义一个函数,该函数接收一个 RISC-V 指令并返回该指令的 cycles 消耗,CKB-VM 内置的检查程序会统计已执行的 RISC-V cycles 数并在预设阈值处停止程序运行。
这将保证运行在 CKB-VM 中的所有应用都能在有限的时间内停止,它避免了在区块链下出现最糟糕的后果: 一个恶意应用停止了区块链的运行。CKB-VM 在内部使用一个字节数组模拟 RISC-V 的内存,我们限制应用程序运行时所需要的内存总量。
在许多时候我们会遇到取舍问题,更大的内存代表着更高的灵活性,但是正如俗话所说任何硬币都有两面,大内存也会导致在初始化虚拟机时消耗较多的时间。CKB-VM 在灵活性与初始化速度之间找到了一个微妙的平衡,这个平衡的内存限制是四兆。我们做了许多测试,表明在四兆的内存限制下能实现绝大多数密码学算法和足够复杂的业务逻辑。
内存的延迟
初始化在中文编码界一直流传着一些意义不明的暗号,例如「烫烫烫」和「屯屯屯」。它们常常出现在 VS 的 debug 模式中,当你看到这些符号就意味着你的程序访问了未初始化的内存。这涉及到一个底层设计,那就是 x64 程序向操作系统申请到的内存是未初始化的。
但对于 RISC-V 情况则有些不同,因为其规范中规定了内存必须以零值进行初始化。由于 malloc 和 calloc 之间存在着巨大的性能差距,使用 calloc 的方式去申请四兆的内存显得十分浪费, CKB-VM 所作的决定是延迟内存的初始化,即只有使用到相关内存页时,该内存页才会被零值初始化,未被使用的内存页被保持在未初始化状态。这有效的提升了执行一些使用内存很少的程序的运行效率。
W^X 内存保护策略
CKB-VM 同样被设计在区块链中运行不受信任的应用程序代码,这些代码可能来自粗心的开发者,也有可能来自蓄意的攻击者。一种常见但有效的攻击方式是攻击者构造特定的输入数据,使得程序将 CPU 指令写入用于存储数据的内存空间,然后运行这些指令。
CKB-VM 做了内置的 W^X(write xor execute)保护。 它是一种内存保护策略,应用程序的地址空间中的每个页都可以是可写的或可执行的, 但不能同时是可写的或可执行的。这种机制允许更灵活地编写应用程序,而不会过于担心一些编程错误导致意外的执行了攻击者的代码。
CKB-VM 通过许多底层逻辑的优化,使它成为了兼顾安全性和性能的运算平台。
CKB-VM 在区块链之外云原生领域的广泛应用

RISC-V + CKB-VM + Cloud Native RISC-V 是一项全新的技术,它正在硬件领域中快速发展,但我认为它的潜力远不止如此——在未来它可能将在云原生领域扮演更重要的角色。
目前云领域基本上是 x86 和 AMD 的市场,我认为 RISC-V 可以以一种巧妙的方式加入。它不同于直接竞争,而是借助 CKB-VM,将 RISC-V 程序通过 CKB-VM 运行在 x86 平台上。 在有足够的市场之后,再尝试使用真实的 RISC-V 硬件,同时对于云厂商,他们不需要去承担切换架构的风险投入, 因此推进的阻力会比直接上 RISC-V 硬件小很多。
我们来看一下 RISC-V + CKB-VM + Cloud Native 相比传统的 Cloud Native 有什么优点。
目前 Cloud Native 的一个普遍的实践是首先启动一个 Docker 做环境和资源的隔离,然后在 Docker 内部直接运行一个二进制程序,或者间接的通过 NodeJS,Python 或是一个 JVM 来执行用户的脚本代码。
我不禁要问为什么要将事情搞得如此复杂呢?
特别是随着像 Rust,Golang 等高级语言的 RISC-V 后端逐渐成熟,我们完全可以将 RISC-V 看作一种「跨平台的字节码」,通过 CKB-VM,它可以真正实现 write once, run anywhere 的愿景。
较 Docker 而言更细致的权限控制
![]()
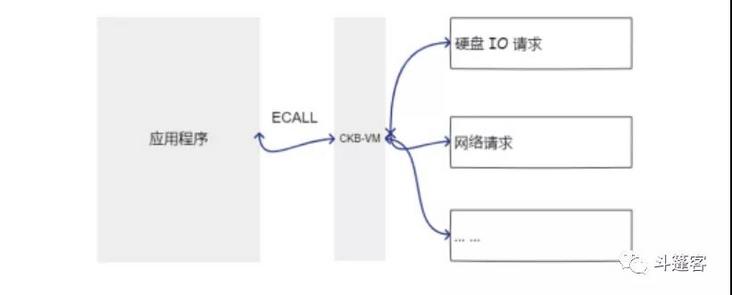
相较于 Docker 提供的资源隔离的基本功能,采用 RISC-V + CKB-VM 的方式可以提供更多云计算平台所需要的更加细粒度的权限控制。 RISC-V 程序采用系统调用(system call)的方式与操作系统通信,CKB-VM 的实现方式上可以代理应用程序的发出的全部系统调用,之后,云计算平台便可以根据用户的相关权限与当前的资源使用情况等来决定是否响应这次系统调用。例如:
- 控制应用程序使用的最大文件句柄数量
- 控制应用程序建立的 TCP 链接数量
- 控制应用程序的 IO 使用量
以上这些细粒度的控制很难使用 Docker 实现,至少不会很直观,而采用 RISC-V + CKB-VM 的话,由于资源的请求与释放全部通过系统调用,云计算平台可以在应用程序的资源和权限上做到几乎无限粒度的控制 。
代理资源请求
当我们在代码中使用 open 函数的时候,我们在干什么?

![]()
我们是真的「打开」了硬盘上的一个真实存在的文件吗?
并不是,我们是像操作系统发出了一个请求,操作系统有时会从硬盘上读取这个文件,有时则是从缓存中给我们返回了这个文件,这取决于操作系统的想法。这种情况下可以说操作系统管理了硬盘资源。
云原生编程应当与本机编程具有相似的编程体验, 但目前这方面行业内做的远远不够。许多云厂商都有提供云存储的功能, 但是在大多数情况下,仍需要先行安装这些厂商的 SDK,然后通过相关 API 进行访问。这种体验造成了一种云应用与原生应用的割裂感觉。
正如上面所说的,CKB-VM 代理了应用程序发出的全部系统调用,在采用 RISC-V + CKB-VM 的方案时,可以做到云代码与原生代码完全一致:
例如当开发者写下
open("/foo/bar") 时,如果其代码是在本机运行,那么程序会打开本机文件系统下的 /foo/bar 文件;而如果将此代码运行在云计算平台上,它将会打开你当前账号下相关云存储桶里的 /foo/bar 文件。
最重要的一点是这一切都是自动的,无需开发者对代码做任何修改, 甚至不需要重新编译!
毫秒级的冷启动,极低的资源消耗,极快的运行速度
CKB-VM 的这些特性,使得它非常适合作为 Lambda 函数执行。这一切特性使之全面优于传统的基于 Docker 的 Lambda 函数。并且可以为云厂商节省一大笔机器费用。
多语言支持
仅仅就目前而言, C/C++, Golang 和 Rust 等通用语言均可以生成较为优质的 RISC-V 代码,它们可以直接运行在 CKB-VM 中。更进一步的话,甚至可以通过将 JavaScript,Lua 和 Ruby 等解释器编译为 RISC-V ,而支持在 CKB-VM 。
CKB-VM 的过去与未来

秘猿科技在 CKB-VM 开发过程中,遇到过许多富有挑战性的难题,在解决这些问题的过程中积累了大量的开发经验。
如何高效的对指令集进行模拟?
CKB-VM 最初使用 Rust 实现了一个解释器,但是 Rust 解释器编译后的代码质量一般,其性能远不如手工编写的汇编代码。CKB-VM 做了另外两个尝试, 其一是 AOT 编译器,它会在执行前首先将 RISC-V 程序编译为 x64 程序。其二是手工编写的 ASM 解释器,相比起 AOT 编译器,这可以在寄存器分配层面上做到更加细致的控制。
例如执行环境的上下文信息,或是指令中的源操作数,目的操作数和立即数,这些数据在整个执行阶段都被固定分配在某几个寄存器中。这一切都工作的非常好,但在尝试将 B extension 加入 CKB-VM 的时候遇到了一点问题,例如,B extension 中的 bfp 指令的实现对于手工编写的 ASM 代码来说就过于复杂了(无论对于逻辑的实现还是寄存器分配来说):

为此,在 ASM 的解释器循环中,当指令被解码之后,将根据指令的类型决定指令的执行路径: 在 CKB-VM 中成为快速路径 和慢速路径。在快速路径下,指令的执行过程将在汇编代码内部处理完毕;在慢速路径下,指令的执行会被交由 Rust 解释器来做。
考虑到这些复杂指令出现在程序中的频次很低,同时可以在应用程序代码中有意的避免使用这种复杂指令,因此快速路径+慢速路径结合使用的方式几乎可以在不影响主要性能指标的前提下避免在汇编实现的解释器循环中添加过重的计算过程。
如何对虚拟机进行测试?
首先,保证虚拟机实现能通过官方的测试集,这能提供最低限度的正确性保障。
其次,使用模糊测试(fuzzing test)可以对代码进行更好的覆盖,利用程序生成大量随机的有意义或无意义的代码,分别使用 CKB-VM 与其它现有的 RISC-V 模拟器例如 riscvOVPsim, spike 等执行并比对它们的最终结果。
CKB-VM 的未来开发计划
我们计划为 CKB-VM 提供 V extension(向量指令)的支持,这将允许我们以一种新的思路去进一步优化区块链中的密码学算法。
算法的向量化是一个有趣的挑战,绝大多数算法或多或少都是可以在一定程度上并行的,换句话说,我们总能找到一种可以用向量化思想表示的算法来完全或部分解决问题。对于 CKB-VM 来说,向量指令的底层可以通过 SIMD 或者多线程来解决。