一文搞懂什么是分布估计算法【附应用举例】
本文参考了很多张军老师《计算智能》的第八章知识。
本文来源:https://blog.csdn.net/qq_44186838/article/details/109181453
分布估计算法
1.1 分布估计算法简介
1.1.1 产生背景
为啥分布估计算法会出现呢?或者说它出现是为了解决什么问题呢?
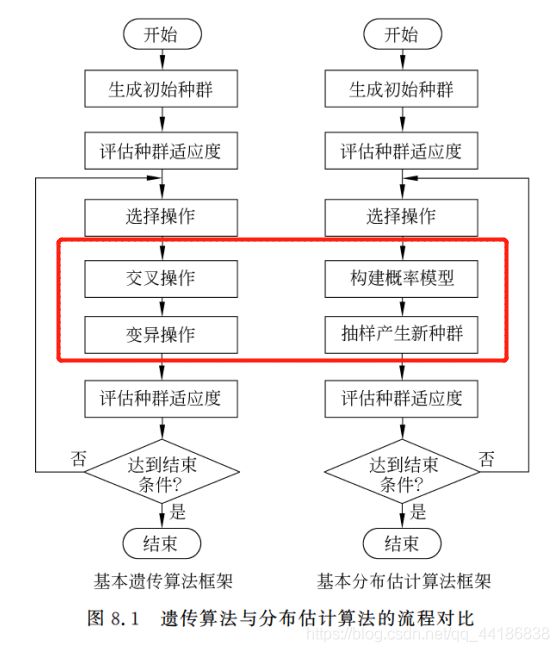
大家看到这的时候,或者或少也都了解过遗传算法了。这里简单回顾一下:遗传算法通过初始化种群,计算种群每个个体的适应度,然后通过交叉和变异得到新的种群,以此接近最优解。那在这个过程中,其实它面向的往往是具体到个体的层面(“积木块”),这样子导致当面对高维的问题时其性能较差。
所以这个时候如果我们想要解决这些问题,那就需要将面向层面提高到种群上,如果我们把种群的分布规律分析出来,是不是就可以用来提高算法的性能呢?
改进遗传算法的交叉操作和变异操作,防止破环积木块.采用概率模型和抽样的隐式形式产生新个体。
即以一种带有“全局操控”性的操作模式替换掉遗传算法中对“积木块”具有破坏作用的遗传算子(选择算子、交配算子和变异算子),这就是我们所要描述的分布估计算法。
看图:
1.1.2 分布估计算法的发展历史
开山始祖
PBIL:(1994 Baluja)
UMDA: (1996 H.Miihlenbein & Paass)
早期的算法专注于二进制编码
MIMIC: (1997 J.S.D.Bonet)
COMIT:(1997 S.Baluja)
FDA: (1999 HM Uhlenbein)
BOA: (1999 M.Pelikan)
逐渐扩展到连续分布估计算法
PBILc (Sebag, 1998)
UMDAc (Larrañaga, P., et al, 2000)
CEDGA (Q. Lu, 2005)
FWH & FHH (Tsutsui et al , 2001)
sur-shr-HEDA(N. Ding, et al, 2006)
混合分布估计算法
EDA与粒子群优化的混合
EDA与遗传算法的混合
EDA与差分进化算法的混合
并行分布估计算法
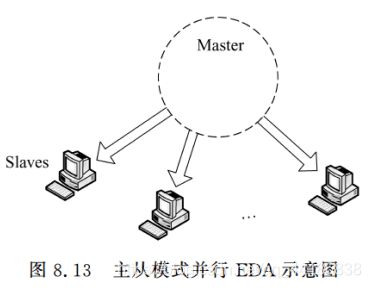
主从模式
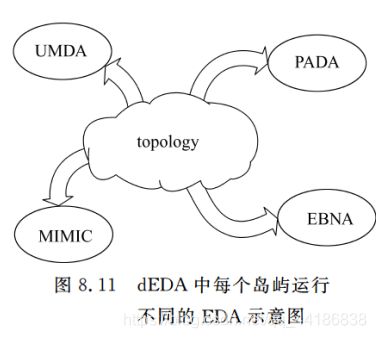
岛屿模型
1.2 基本流程
1.2.1 基本的分布估计算法
分布估计算法的通用流程
Randomly generated the initial population P(0);
t = 0;
While not met the termination condition do
Begin
Select a set of promising individuals D(t) form the current population P(t);
Estimate the probability distribution of the selected set D(t);
Generate a set of new individuals N(t) according to the estimate;
Create a new population P(t+1) by replacing some individuals of P(t) by N(t);
t = t+1;
end
以UMDA为例,其算法执行步骤如下。
第一步:随机产生N个个体来组成一个初始群体,并评估初始种群中所有个体的适应度。
第二步:按适应度从高到低的顺序对种群进行排序,并从中选择出最优的Se个个体(Se ≤ \leq ≤N)。
第三步:分析所选出的Se个个体所包含的信息,估计其联合概率分布p(x)。
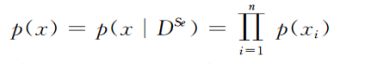
其中,n为解的维数,p( x i x_i xi)的边缘分布。
第四步,从构建的概率模型p(x)中采样,得到N个新样本,构成新种群。此时,若达到算法终止条件则结束,否则执行第二步。
**从第三步的公式可以看出在估计概率模型时认为变量之间是独立不相关的。**但实际上往往不是这样,后面会提到。
1.2.2 一个简单分布估计算的例子

我们用UMDA算法来解决,步骤如上所述。
现在,我们采用UMDA来求解一个四维的OneMax问题。在这个例子中,我们用一个简单的概率向量p=( p 1 p_1 p1, p 2 p_2 p2, p 3 p_3 p3, p 4 p_4 p4)来表示描述种群分布的概率模型,其中 p i p_i pi表示 x i x_i xi取1的概率,(1— p i p_i pi)则为 x i x_i xi取0的概率。
第一步:产生初始种群。为了使初始种群在定义域内符合均匀分布,我们定义初始化概率向量模型p=(0.5,0.5,0.5,0.5),然后根据p产生规模为10的初始种群,最后根据F(x)= x 1 x_1 x1+ x 2 x_2 x2+ x 3 x_3 x3+ x 4 x_4 x4,计算出初始种群的适应度,最终的结果如下表所示。
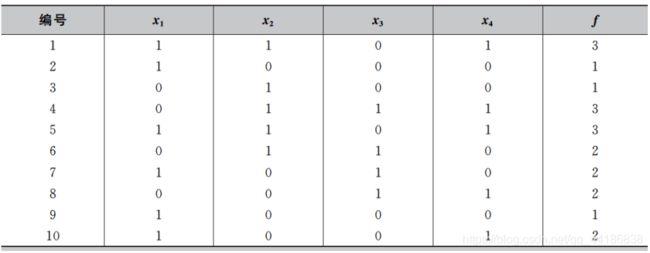
第二步:按照种群的适应度从高到低进行排序。假设Se=5,则从种群中选出适应度较高的5个个体用来更新概率向量模型p。更新概率模型时令 p i p_i pi = n i n_i ni/Se,这里 n i n_i ni 为在选出的较优个体中 x i x_i xi =1的个体数。最终选出的个体如下表所示,从而得到新的概率模型为p=( 3 5 \frac{3}{5} 53, 4 5 \frac{4}{5} 54, 3 5 \frac{3}{5} 53, 3 5 \frac{3}{5} 53) = (0.6,0.8,0.6,0.6)。
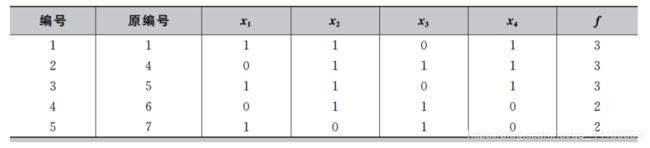
第三步:根据更新后的概率模型p产生新的样本,并计算这些新样本的适应度。最终得到新一代的种群如下表所示。
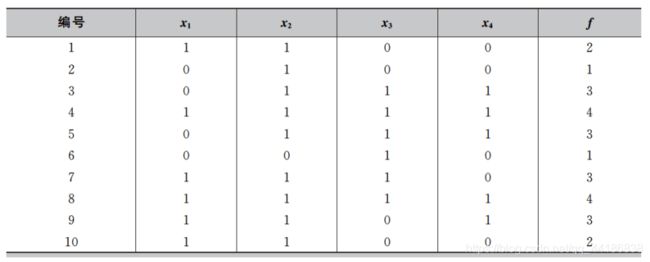
通过以上三步,分布估计算法完成了第一代的进化过程。接着重复第二步和第三步完成下一代的进化,最终得到的种群平均适应度和概率模型如下表所示。我们可以看出,随着演化的进行,种群的整体质量不断提高,概率向量逐渐逼近全局最优解。

1.3 分布估计算法的改进及理论研究
1.3.1 概率模型的改进
还记得我们前面提到的假设变量独立不相关吗?
早期很多分布估计算法都是这种,但现实生活中很多并非独立,而是相互关联,所以不难发现,这些算法最终应用都无法给人一个很满意的效果。
基于此,学者们提出了一系列用于求解具有变量相关性的问题的分布估计算法。
根据对于变量关联性捕捉能力的差异,可将其分为三大类。如下图所示。
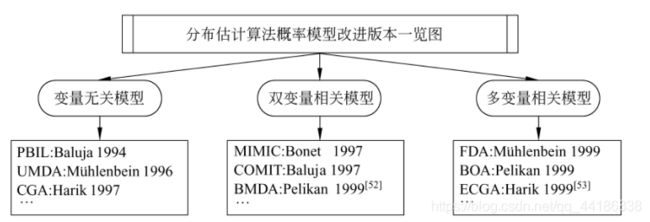
在这里我就以高斯概率模型中的PBILc为例,介绍高斯概率模型解决连续空间的优化问题的流程。
在此之前,先回顾一下高斯分布(正态分布)长啥样。
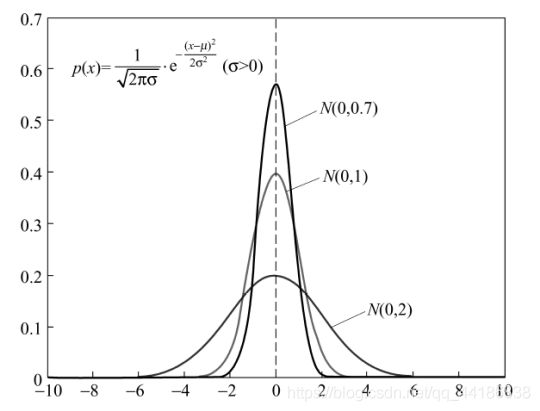

ok,下面正式介绍PBILc的流程。
基于高斯模型的EDA的流程如下:

不难发现,第二步和第三步是最重要的步骤,更新概率模型中的两个重要参数:均值和方差。其实更新的方式多种多样,也可以直接用优秀个体的均值和方差替代原来的均值与方差。
1.3.2 混合分布估计算法
分布估计算法与遗传算法混合
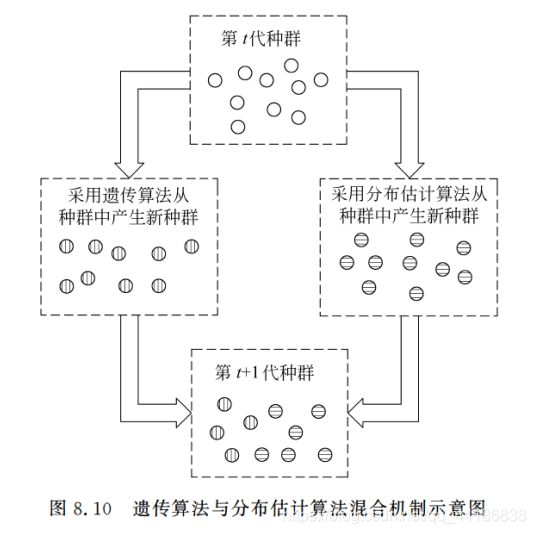
分布估计算法与差分进化算法混合
以DE-EDA为例。
第一步: 从种群中选出M个较优的个体,建立如下概率模型 :
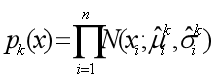
第二步: 产生一个0~1之间的随机值v,若v≤α,则按照DE方式产生新个体,否则按照EDA的方式取样产生新个体。
第三步: 若新个体的适应度大于原个体的的适应度则替换之。
第四步:若产生了足够数量的新种群则终止,否则执行第一步 。
1.3.3 并行分布估计算法
种群级别并行化
思路: 将种群分成多个子种群,每个子种群在不同的机器上运行,然后各个子种群通过迁移等机制进行通信,达到综合信息的目的
适应度评估并行化
思路:适应度评估通常是算法中最耗时的部分,因而,采用多台机器并行计算种群中的适应度可有效提高算法求解速度
概率模型构建并行化
思路:设计复杂的概率模型需要较大的计算量,并行求解复杂概率模型可有效提高算法计算速度.
其他并行机制
采样的操作进行并行化
混合并行机制
1.4 分布估计算法的应用
分布估计算法的应用领域(函数优化)
有效地保护 “积木块”,能够高效求解高维的复杂函数优化问题.
在具有先验知识的情况下,可有针对地选择概率模型,从而设计出性能优越的分布估计算法.
已成功应用于求解复杂的多峰函数, 关联性强的复杂函数优化以及多目标函数优化.
分布估计算法的应用领域(组合优化)
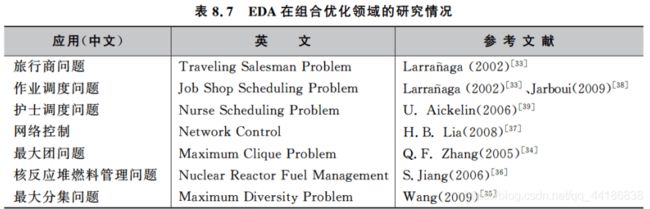
分布估计算法的应用领域(生物信息学及其它)
分布估计算法 在处理高维复杂问题时表现出良好的性能,非常适合于求解含有海量信息的生物信息学领域的问题。
基因结构分析。
DNA微阵列数据的分类和聚类分析。
蛋白质结构预测与蛋白质设计。
分布估计算法在多目标优化、机器学习、模式识别和聚类分析等领域也取得了成功的应用。