新东方在有状态服务 In K8s 的实践
作者|周培,新东方架构部容器组专家
有状态服务建设一直以来都是 K8s 中非常具有挑战性的工作,新东方在有状态服务云化过程中,采用定制化 Operator 与自研本地存储服务结合的模式,增强了 K8s 原生本地存储方案的能力,在摸索中稳步推进企业的容器化建设。
新东方有状态服务 In K8s 的现状
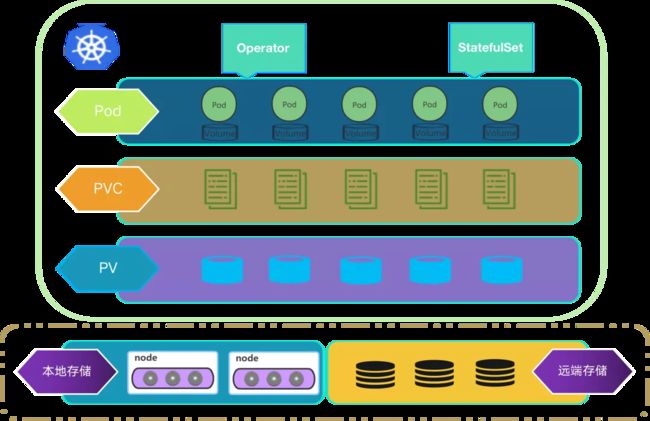
如上图所示,上层 Pod 由自定义的 Operator 和 StatefulSet 控制器来托管,Pod 关联 PVC,PVC 绑定 PV,最下层是存储服务。
最下层的存储服务包含本地存储和远端存储两类,对于一般的存储需求,首选是远端存储服务;而对于高性能 IO 的存储需求,那就要选择本地存储服务。目前,本地存储服务包含 K8s 原生 local 存储服务和自研的 xlss 存储服务 2 种。
原生 K8s 支撑有状态服务的能力
原生 K8s 支撑有状态服务的能力是有状态服务建设的基础,其管理模式是:StatefulSet 控制器 + 存储服务。
1. StatefulSet 控制器
StatefulSet 控制器:
用来管理有状态应用的工作负载 API 对象的控制器。管理某 Pod 集合的部署和扩缩,并为这些 Pod 提供持久存储和持久标识符。
StatefulSet 资源的特点:
- 稳定的、唯一的网络标识
- 稳定的、持久的存储
- 有序的、优雅的部署和缩放
- 有序的、自动的滚动更新
StatefulSet 资源的局限:
- 关于存储,StatefulSet 控制器是不提供存储供给的。
- 删除或者缩容时,StatefulSet 控制器只负责 Pod。
- 人工要建一个无头服务,提供每个 Pod 创建唯一的名称。
- 优雅删除 StatefulSet,建议先缩放至 0 再删除。
- 有序性也导致依赖性,比如编号大的 pod 依赖前面 pod 的运行情况,前面 pod 无法启动,后面 pod 就不会启动。
这 5 点局限可进一步概括为:StatefulSet 控制器管理 Pod 和部分存储服务(比如扩容时 pvc 的创建),其它的就无能为力。有序性引起的依赖性也会带来负面影响的,需要人工干预治愈。
2. 存储服务
Cloud Native Storage
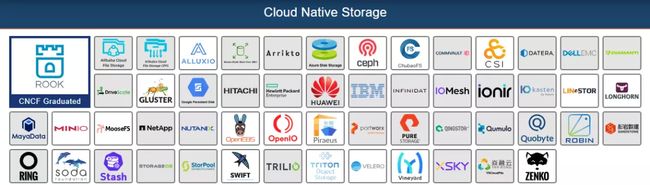
这是 CNCF 官网关于云原生存储的一副截图。截图时间是 2021 年 7 月初,有 50 多种存储产品,接近半数属于商业产品,开源产品多数都是远端存储类型,有支持文件系统的、有支持对象存储的、还有支持块存储的。
K8s PV 类型
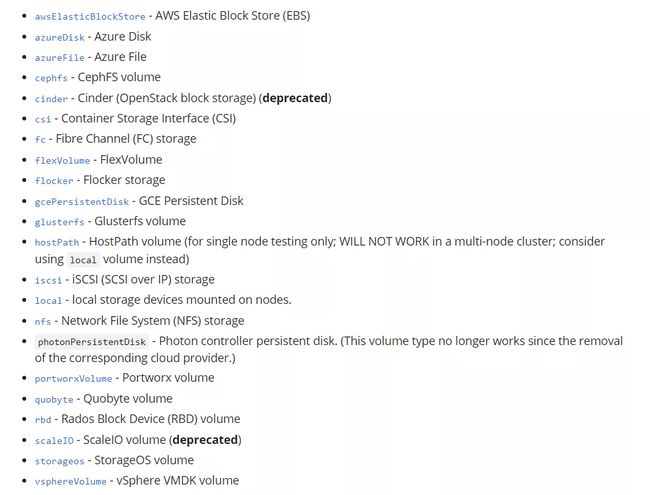
数据来源于官网,原生 K8s 支持的 PV 类型,有常用的 rbd、hostpath、local 等类型。
如何选择?
控制器只有 StatefulSet 控制器可使用,存储产品很多,PV 类型也不少,该怎么选择呢?

选择存储产品,需要考虑哪些因素呢?新东方在选择存储产品时考虑了以下一些因素:
- 开源 VS 商业
- 本地 VS 远端
- 动态供给 VS 静态供给
- 数据高可用方案
做选择是令人头疼的事情,比如选择开源,好处是不用花钱,但稳定性就很难保证,甚至提供的能力也有限;商业产品能力和稳定性有保证,但要付费。在这里先不下结论,最终还是要看需求。
自研存储产品 XLSS
1. 关键需求
新东方有状态服务建设的关键需求:良好的性能,支持 IO 密集型应用;数据可用性,具有一定的容灾能力;动态供给,实现有状态服务的完全自动化管理。
2. XLSS 介绍

XLSS(XDF Local Storage Service)中文全称:新东方本地存储服务产品,是一种基于本地存储的高性能、高可用存储方案。可以解决 K8s 中本地存储方案的不足之处:localpv 只能静态供给;使用 localpv 时,pod 与 node 的亲和性绑定造成的可用性降低;本地存储存在数据丢失的风险。
应用场景
- 高性能应用,IO 密集型的应用软件,比如 Kafka
- 本地存储的动态化管理
- 数据安全,应用数据定期备份,备份数据加密保护
- 存储资源监控告警,比如 K8s Pv 资源的使用量监控告警
3. XLSS In K8s

如上图所示,XLSS 在 K8s 中的运行状态是 Xlss 的 3 个组件以容器形式运行在 K8s 集群中,使用本地存储为有状态服务提供存储服务,并定期执行数据的备份作业,Xlss 会提供有关存储和相关作业的 metrics 数据。
4. XLSS 核心组件介绍
Xlss 主要组件包含:
- xlss-scheduler
- 基于 kube-scheduler 的自定义调度器
- 对于有状态服务的 pod 的调度,自动识别 xlss localpv 的使用身份,智能干预 pod 调度,消除 pod 与 node 的亲和性绑定造成的可用性降低
- xlss-rescuer
- 以 DaemonSet 资源类型运行在 k8s 集群中
- 按照数据备份策略,执行数据备份作业
- 监视数据恢复请求,执行数据恢复作业
- 提供 metrics 数据
- xlss-localpv-provisioner
- 动态供给本地存储
5. xlss-scheduler 关键逻辑实现思路
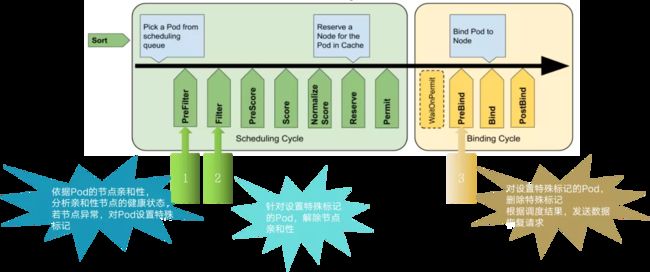
如上图,这是 K8s 调度器的调度框架模型,在调度流程中包含了许多扩展点。xlss-scheduler 就是基于该调度框架模型,通过编写自定义的插件实现,主要在 3 个扩展点上做了增强:
- Prefilter:依据 Pod 的节点亲和性,分析亲和性节点的健康状态,若节点异常,对 Pod 设置特殊标记。
- Filter:针对设置特殊标记的 Pod,解除节点亲和性。
- Prebind:对设置特殊标记的 Pod,删除特殊标记,根据调度结果,发送数据恢复请求。
6. xlss-rescuer 数据备份作业实现逻辑
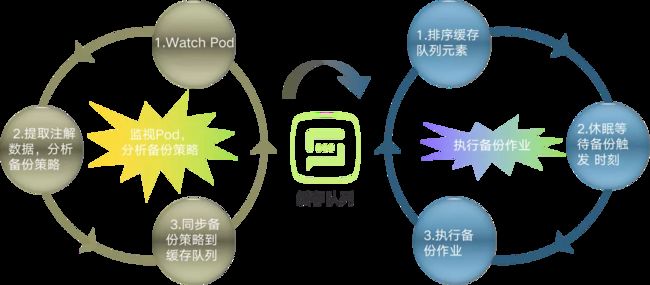
图中 3 个部分,左右各一个循环逻辑,中间通过一个缓存队列实现通信。左边的循环实现的功能:收集备份作业策略,并更新到缓存队列中。主要 3 步:
- watch pod 事件
- 从 pod 注解当中获取备份策略,备份作业的配置信息是通过 pod 注解实现的
- 同步备份策略到缓存队列
右边的循环实现的功能:执行备份作业。也是 3 步:
- 对缓存队列元素排序,排序按照下次备份作业的执行时间点进行升序排列
- 休眠等待,若当前时间还没有到最近的一个备份作业执行时间,就会进行休眠等待
- 执行备份作业
7. xlss-rescuer 数据恢复作业实现逻辑
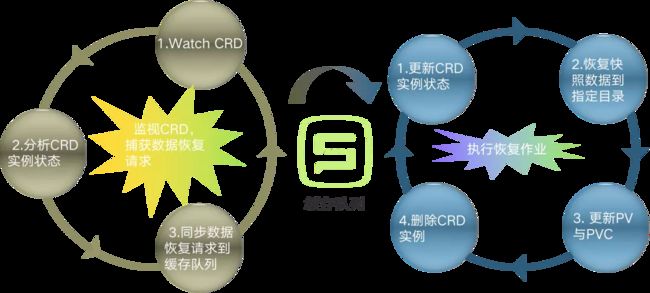
数据恢复作业流程和数据备份作业流程实现思路是类似的,但在具体实现逻辑上有所不同。
左边的循环实现的功能:监视恢复作业请求,并更新到缓存队列中。主要 3 步:
- watch CRD,监视数据恢复请求,接收 xlss-scheduler 发出的数据恢复请求(数据恢复请求以 CRD 方式实现)
- 分析 CRD 状态,避免重复处理
- 同步恢复请求到缓存队列
右边的循环实现的功能:执行恢复作业。这里是 4 步:
- 更新 CRD 实例状态
- 恢复快照数据到指定目录
- 更新 PV 与 PVC
- 删除 CRD 实例
8. xlss-localpv-provisioner 存储创建实现思路
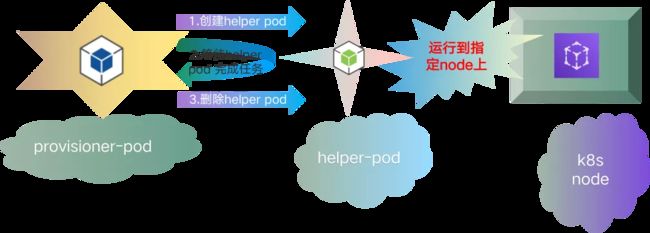
xlss-localpv-provisioner 组件,其功能比较专一,实现本地存储的动态创建。其工作流程当 provisioner pod 获取到创建存储的请求时,首先会创建一个临时的 helper pod,这个 helper pod 会被调度到指定的 node 上面,创建文件目录作为本地存储使用,这就完成了 pv 实际后端存储的创建,当存储创建完毕,provisioner pod 会将这个 helper pod 删除。至此,一次本地存储的动态创建完成。
9. xlss 自动灾难恢复工作流程
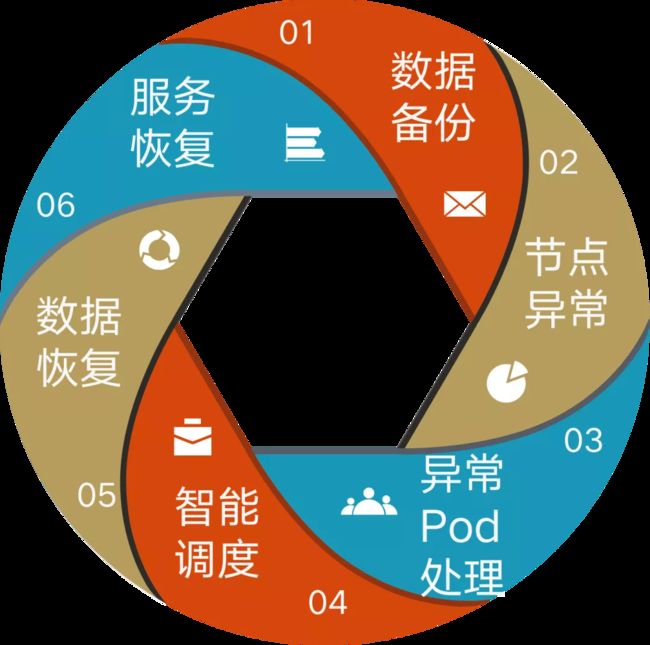
完整的自动灾难恢复工作流程要经历 6 个阶段:
- 数据备份:以 pod 为粒度,对 pv 数据进行备份。
- 节点异常:此时集群出现异常情况,某一节点发生异常,比如服务器损坏,引起在其上面的 pod 工作异常,最后有状态服务的 pod 就会一直处于 Terminating 状态。
- 异常 pod 处理:当有状态服务的 pod 处于 Terminating 状态时,要清理掉这些 pod,可以手动删除,也可借助工具,让这些有状态的 pod 有重新创建的机会。
- 智能调度 :解除亲和性,将新 pod 调度到健康的节点上。
- 数据恢复:拉取该 pod 对应的最新的快照数据进行数据恢复。
- 服务恢复:启动应用,对外提供服务。
至此,一个完整的自动灾难恢复工作流程结束,最后又回到起点。
大规模存储型中间件服务
存储问题基本解决了,那该怎么落地呢?答案就是建设存储型中间件服务。
1. Kafka Cluster In K8s
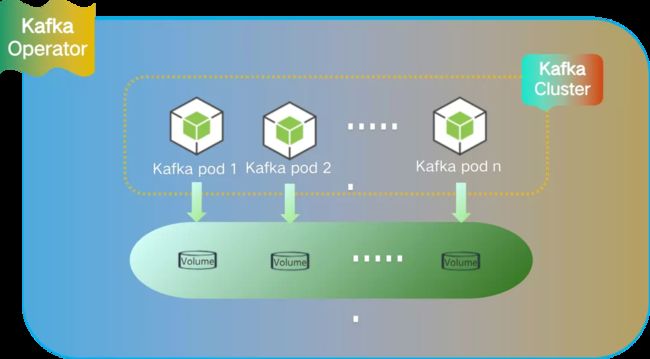
以 kafka 集群为例,通过定制化的 kafka operator 来部署 kafka 集群,指定存储服务使用 xlss 存储。采取定制化 Operator + xlss 模式去建设存储型中间件服务。
2. 有状态中间件服务 In K8s
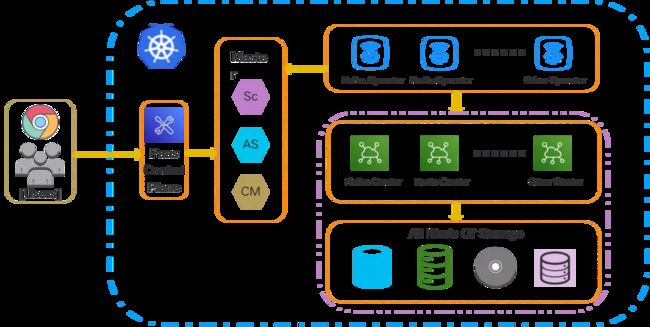
有状态中间件服务在 K8s 中的运行状态如上图所示,这些存储型中间件服务集群托管于对应的 Operator,底层存储根据业务需要适配各类存储。随着中间件服务集群规模的日益扩大,我们建设了 PaaS 控制面,用户可以通过该控制面来管理运行在 K8s 中的各类中间件服务集群。控制面可以直接和 apiserver 交互,用户通过控制面增删改 CRD 资源,Operator 根据 CRD 资源的最新状态,调和中间件服务集群的状态。
3. 用户申请中间件服务示例
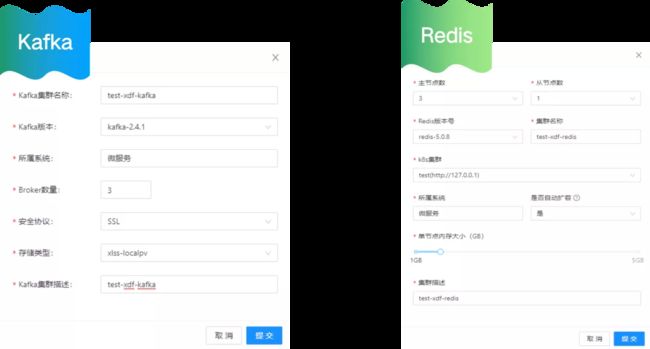
这是用户申请中间件服务的示例:用户通过管理台申请服务,填写相关的配置信息后,申请通过后,就可以在 K8s 集群里面创建相应的服务了。
基于 KubeSphere 部署 XLSS
如果希望使用 xlss 存储,那该怎么部署呢?
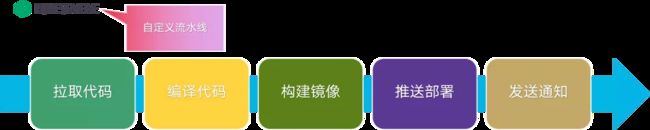
若是首次部署,首先要做好本地磁盘的规划,创建好提供给 xlss 使用的存储空间。然后,就是将 xlss 的各个组件运行到 K8s 集群中。将 xlss 组件部署到 K8s 集群中,我们借助了 KubeSphere 的 CI/CD 流水线。自定义流水线一共 5 步,实现将 xlss 组件从静态代码到运行在 K8s 中的容器的转换,高度自动化维护。
CI/CD 流水线如下图所示:
Road Map

目前,新东方的有状态服务容器化建设大致可分成 4 阶段。
第一阶段:“云前时代”
有状态服务容器化的起点,确定了容器化的目标。这个阶段有状态服务主要特征是 VM+PaaS 组合的模式管理有状态服务。实现的主要功能:资源管理、白屏运维、简单调度策略、运行时管理。
第二阶段:“初上云端”
从这个阶段开始,尝试将有状态服务从 VM 中解脱出来,迁移到 K8s 平台。这个阶段有状态服务主要特征是 K8s+Operator 组合的模式管理有状态服务。
这时,运行时被托管到 K8s,有状态服务由 Opeartor 接管,自动化程度显著提高。此时也暴露出一些不足:比如远端存储的性能不够好,本地存储的可用性不能保证。
第三阶段:“自研之路”
主要是新东方自研 xlss 的实践阶段,前面章节已有涉及。此阶段有状态服务建设的典型特征:Scheduler + Logical Backup 组合模式。这基本达到了我们期望的:本地存储 + 动态供给 + 数据可用性保证。但事情永远都不会那么完美,那还有那些瑕疵呢?
- 数据恢复时长取决于数据量大小,如果数据量很大,恢复时间也会增大,在 node 异常发生的情况下,这就增大了有状态服务的不可用时间。
- 现在 PV 数据还没能做到存储隔离,无法约束应用对存储的使用量,会存在一定的风险。
瑕不掩瑜,在小规模存储场景:如 redis、kafka 等还是有用武之地的,但是对于大数据量的服务,目前 xlss 的能力还有些勉强。
第四阶段:“追求卓越”
在这个阶段,有状态服务建设的典型特征:Isolation + Physical Backup 组合模式。重点会解决第三阶段发现的瑕疵。大致的解决思路是:利用 LVM 技术实现存储的隔离;利用 DRBD 技术,增加 DRBD 同步物理备份能力,实现应用数据的同步实时备份,解决由于数据量大导致恢复时间增长的问题。
在使用 DRBD 技术时,有一个需要权衡的地方,那就是副本数量的设置。若副本数量设置多些,则会增大存储资源使用量;若副本数量设置少些,在 K8s 集群 node 异常情况下,有状态服务 Pod 漂移可选择的 node 数量就会减少。最终需要根据业务场景做出合理选择。
本文由博客一文多发平台 OpenWrite 发布!