打开聊天软件,跟重要的人说个早安,扫一眼关闭了提醒的群消息。相信这是很多人开始一天的“固定动作”。
随着移动互联网和通信技术的高速发展,线上交流已成为人们工作、生活的最重要方式。没带手机出门就像失去了全世界,电量低于 50% 就开始焦虑,因为好友列表里保存着我们跟这个世界的联结。而通过会话列表打开一个会话,是我们每天最频繁的动作之一。
IM 会话列表里会话的准确性、实时性会直接影响用户的使用体验与感受。本文分享融云 IM 即时通讯的会话服务数据读写设计思路。(关注 融云全球互联网通信云,了解更多IM & RTC技术、场景话题)
海量消息会话的技术挑战
以单聊为例,用户 A 给用户 B 发送消息,会产生两条会话记录:一条发送者的会话,一条接受者的会话。服务端会把这两条会话记录保存到数据库中,便于后续服务重启、更新、查询使用。
为了减少服务端与客户端的交互,通常情况下,我们会在会话记录中保存最后一条消息。之后每次 A 给 B 发消息,或 B 给 A 发消息都会相应地更新这两条会话的消息记录以及会话的最后时间等。
假如某一时刻有 10 万个单聊用户发送消息,便会产生 20 万条会话的添加(第一次聊天)或更新(后续聊天)操作。
在高频次读写的场景下,要提供准确快速的查询,以及可靠的存储就很考验服务在高并发场景下的处理能力了。
高并发下会话的查询操作
为了提供快速的查询能力,我们一般会把被频繁访问的热点数据存储在缓存中,比如 Redis 等,以方便系统快速做出响应,而不是每次查询到数据库造成数据库压力。
为了减少网络交互,降低服务器压力和提升用户体验,我们可以将热点数据放到服务内存中。当下次用户查询时,先去内存中查找是否存在。若存在则直接返回给用户;若不存在则去数据库中查询出来再放到内存中缓存起来,便于下次查询直接从内存中获取然后返回给用户。

(图 1 会话查询流程)
在分布式系统架构中,为了提高内存中缓存数据的命中率,我们一般会采用一致性 Hash 的方式,将一个用户的所有会话的操作都落到同一个服务实例上。这样做,不仅利于性能提升,还有助于降低处理分布式读写带来的数据一致性问题的难度。
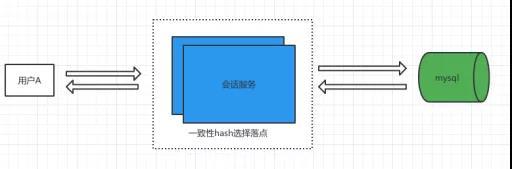
(图 2 一致性 Hash 算法计算服务落点)
高并发下会话的插入更新操作
解决完查询操作,我们再来看看如何优化写操作,包含插入、更新以及删除等。
当有大量数据要添加到数据库中时,势必提高数据库查询的延时。该如何处理呢?
首先,内存大小是有限的,把所有的会话都放在内存中是不现实的。我们会把新添加的会话放到 LRU 缓存中供查询使用,然后把要添加的会话写入到队列中,通过异步方式添加到数据库。此时你可能会想:这也并没有减少插入数据库的次数呀,只是放到后面异步处理了而已。是的,到这一步确实达不到减少操作数据库次数的效果,且往下看。

(图 3 异步化数据落地处理)
假如要添加会话 A,首先会更新到 LRU 中,然后把会话加入到队列中等待添加到数据库中。此时队列中若没有积压,则会直接更新到数据库中;若有积压,更新到此条会话时先对比 LRU 中的会话,把最新的会话更新到数据库中,并记录最新的会话时间。

(图 4 会话数据存取策略)
如图 4,从队列中取出会话 1 进行存储,此刻队列中的会话 1 的消息时间是 1,LRU 中的会话 1 的消息时间是 4。相比较 LRU 中的会话是最新的,则把 LRU 中的会话入库,并记录这条会话的更新时间。当队列中更新到 time 为 3 这条旧的会话 1 时,由于这条会话的时间比记录的时间小,则丢弃不入库。这样,就可以有效减少高并发积压的情况下,相同会话频繁更新导致频繁入库的情况,从而达到减小数据库压力的目的。
总而言之,融云的会话服务数据读写的设计思路如下:
充分利用内存对热点数据进行缓存,减少对后端数据存储服务的读取压力;
通过服务落点计算,提升缓存命中率;
通过合并业务数据, 尽量减少无效业务操作,减少对存储服务的写入操作;
通过异步解耦业务与数据写入流程。
随着通信能力成为越来越多场景的基础需求,高并发场景越来越多,我们也将不断对服务架构进行迭代,提高并发支持能力,为广大开发者提供稳定、可靠、低延时的通信能力支持。