卷积神经网络模型研究
文章目录
- 会议期刊
- 卷积层之间是否应该使用dropout?
- 图像分类、目标检测、图像分割的区别
- 分割网络
- 分类网络
- 模型可解释性、可视化
- 类激活图
- FCN
-
- 代码
- NIN (Network in Network)
- SSD网络
- resnet残差网络
-
- bottleneck architecture 瓶颈结构
- mobilenet
-
- MobilenetV3的h_swish和h_sigmoid
-
- 代码
- 深度可分离卷积
-
- 代码
- Deeplab
-
- 代码
- 空洞卷积(Dilated/Atrous Convolution)
- 空洞卷积感受野计算
- PSPnet
- Fast Rcnn
- 深度学习模型压缩方法
- Unet
-
- 深度可分离卷积和Xception的区别
- 下采样和池化的区别
- Low-level feature和High level feature
- 高级语义信息、低级语义信息
- 不需要提前预训练网络
- 卷积神经网络中拍案叫绝的操作
- 多孔的空间金字塔池化(ASPP)
-
- 代码
- SEnet 注意力机制
-
- 代码
- Inception 模块
-
- pytorch代码实现
- one/zero short
- dense net
- 目标检测网络
会议期刊
ArXiv是计算机领域bai常用的论文预发表du平台,上面发表了完整的论文,甚至只zhi是一点零星的想法。dao作者们通过将论文预发表至该平台,以声称对某种方法和思路的所有权。当然在该平台预发表后,不影响去其他期刊或会议的投稿和发表。
**预印本(Preprint)**是指科研工作者的研究成果还未在正式出版物上发表,而出于和同行交流目的自愿先在学术会议上或通过互联网发布的科研论文、科技报告等文章。与刊物发表的文章以及网页发布的文章比,预印本具有交流速度快、利于学术争鸣、可靠性高的特点。
volumn(册),issue(期) no(number): 第几册第几期
CVPR ICCV
什么是arXiv.org?
计算机视觉顶尖期刊和会议有哪些?
论文中引用文献怎么引用?
卷积层之间是否应该使用dropout?
应该仅在全连接层上使用Dropout操作,并在卷积层之间使用批量标准化。
Dropout大杀器已过时?视网络模型而定!
深度学习基础系列(九)| Dropout VS Batch Normalization? 是时候放弃Dropout了
图像分类、目标检测、图像分割的区别
分类、目标检测、语义分割、实例分割的区别
目标分类与目标检测
分割网络
语义分割网络介绍对比-FCN,SegNet,U-net DeconvNet
语义分割相关网络简述
干货 | 一文概览主要语义分割网络,FCN、UNet、SegNet、DeepLab 等等等等应有尽有
当今主流分割网络有哪些?12篇文章一次带你看完
初探Unet网络
语义分割概念及应用介绍
计算机视觉之语义分割
基于U-Net+残差网络的语义分割缺陷检测
[深度学习语义分割、分类定位与目标检测
在图像分割领域,图像输入到CNN(典型的网络比如FCN[3])中,FCN先像传统的CNN那样对图像做卷积再pooling,降低图像尺寸的同时增大感受野,但是由于图像分割预测是pixel-wise的输出,所以要将pooling后较小的图像尺寸upsampling到原始的图像尺寸进行预测(upsampling一般采用deconv反卷积操作)之前的pooling操作使得每个pixel预测都能看到较大感受野信息。因此图像分割FCN中有两个关键,一个是pooling减小图像尺寸增大感受野,另一个是upsampling扩大图像尺寸。在先减小再增大尺寸的过程中,肯定有一些信息损失掉了,那么能不能设计一种新的操作,不通过pooling也能有较大的感受野看到更多的信息呢?答案就是dilated conv。
笔记:基于DCNN的图像语义分割综述
DCNN 经典模型 AIl in One
卷积神经网络常见架构AlexNet、ZFNet、VGGNet、GoogleNet和ResNet模型
大话CNN经典模型:GoogLeNet(从Inception v1到v4的演进)
大话CNN经典模型:AlexNet
分类网络
[图像分类]CNN模型
分类网络(AlexNet, VGG net 和 GoogLeNet)
在传统的分类 CNNs 中,池化操作用来增加视野,同时减少特征图的分辨率。这对于分类任务来说非常有用,因为分类的最终目标是找到某个特定类的存在,而对象的空间位置无关紧要。因此,在每个卷积块之后引入池化操作,以使后续块能够从已池化的特征中提取更多抽象、突出类的特征。
另一方面,池化和带步长的卷积对语义分割是不利的,因为这些操作造成了空间信息的丢失。下面列出的大多数架构主要在解码器中使用了不同的机制,但目的都在于恢复在编码器中降低分辨率时丢失的信息。如上图所示,FCN-8s 融合了不同粗糙度(conv3、conv4和fc7)的特征,利用编码器不同阶段不同分辨率的空间信息来细化分割结果。
【深度学习】分类神经网络发展 从LeNet到SeNet
模型可解释性、可视化
卷积网络的可视化与可解释性(资料整理)
CNN可视化/可解释性
“看懂”卷积神经网(Visualizing and Understanding Convolutional Networks)
从可视化的内容来分,主要的三种可视化模式:
1.特征可视化:又可分为两类—(1)直接将卷积核输出的feature map可视化,即可视化卷积操作后的结果,帮助理解卷积核的抽取到了什么特征。(2)与第一种方法类似,但不再是可视化卷积层输出的feature map,而是使用反卷积与反池化来可视化输入图像的激活特征。
2.卷积核参数的可视化,对卷积核本身进行可视化,对卷积核学习到的行为进行解释。
3.类激活图可视化(CAM/grad-CAM),通过热度图,了解图像分类问题中图像哪些部分起到了关键作用,同时可以定位图像中物体的位置。
类激活图
Tensorflow2.0 卷积神经网络可视化 (三)类激活热力图 (CAM,class activation map)
CAM论文笔记–Learning Deep Features for Discriminative Localization
浅谈Class Activation Mapping(CAM)
Learning Deep Features for Discriminative Localization笔记
Learning Deep Features for Discriminative Localization 阅读笔记
CAM 和 Grad-CAM 实现
凭什么相信你,我的CNN模型?(篇一:CAM和Grad-CAM)
凭什么相信你,我的CNN模型?(篇二:万金油LIME)
Grad-CAM: Visualize class activation maps with Keras, TensorFlow, and Deep Learning
Learning Deep Features for Discriminative Localization笔记
CAM论文笔记–Learning Deep Features for Discriminative Localization
tensorflow学习之关于全局均值池化(GAP)
FCN
经过多次卷积和pooling以后,得到的图像越来越小,分辨率越来越低。其中图像小的一层时(下图的H/32 x W/32),所产生图叫做heatmap(热图),热图就是我们最重要的高维特征图,得到高维特征的heatmap之后就是最重要的一步也是最后的一步对原图像进行upsampling,把图像进行放大、放大、放大,到原图像的大小。最后的输出是n(类别数)个通道heatmap经过upsampling变为原图大小的图片,为了对每个像素进行分类预测label成最后已经进行语义分割的图像,通过逐个像素地求其在n个通道上该像素位置的最大数值描述(概率)作为该像素的分类,由此产生了一张已经分类好的图片。
全卷积网络 FCN 详解
论文精读及分析:Fully Convolutional Networks for Semantic Segmentation
Fully Convolutional Networks for semantic Segmentation(深度学习经典论文翻译)
Fully Convolutional Networks for semantic Segmentation(深度学习经典论文翻译)
图像分割:全卷积神经网络(FCN)详解
代码
【实验】FCN.tensorflow
FCN详解与pytorch简单实现(附详细代码解读)
【代码】FCN.tensorflow(1):FCN.py
pytorch实现FCN全卷积网络的语义分割(Fully Convolutional Networks for Semantic Segmentation论文简单复现)
FCN详解与pytorch简单实现(附详细代码解读)
基于Tensorflow平台的2D FCN图像分割学习
【实验】FCN.tensorflow
全卷积神经网络FCN-TensorFlow代码精析
NIN (Network in Network)
NIN(Network in Network)学习笔记
(2013, NIN)Network in Network
使用VGG-19模型训练自己的数据集
全局平均池化代替全连接层
通过用全局平均池化(GAP)替换全连接层,这样可以大大减少网络模型的大小,同时提高网络模型的性能。
为什么为什么全局平均池化层有用,为什么可以替代全连接层?
深度学习基础系列(十)| Global Average Pooling是否可以替代全连接层?
深度学习| 用global average pooling 代替最后的全连接层
全连接层(FC)与全局平均池化层(GAP)
NIN是在VGG-Net和GoogleNet之前提出的一个CNN分类模型,在我看来,这篇论文最大的亮点是:提出使用全局平均池化层 ,取代经典CNN分类器如AlexNet、LeNet-5中的全连接层。
传统的CNN分类网络如AlexNet、LeNet,甚至2014年出现的VGG-Net,其典型架构是:
- 网络浅层部分执行一系列卷积/下采样操作,用于提取图像的抽象特征,充当一个特征提取器(feature extractor);
- 网络顶层部分是一个传统的全连接层/多层感知机MLP,充当一个分类器(classifier)。
- 特征提取器部分的最后一层输出的feature map,经过向量化(vectorized)后喂入分类器执行分类任务,最后通过一个softmax层输出类别概率。
这类网络架构的一个显著特点是模型的参数数量大得惊人。AlexNet包含约6000万个模型参数,其中最后一个全连接层输出的feature map尺寸为256x6x6。那么全连接层部分产生的权重数量(不算bias)=256x6x6x4096+4096x4096+4096x1000=5862万,即全连接层占了整个模型参数的97.7%;
一般的池化(Pooling)是不重叠的,池化区域的窗口大小与步长相同。在AlexNet中使用的池化(Pooling)却是可重叠的,也就是说,在池化的时候,每次移动的步长小于池化的窗口长度。AlexNet池化的大小为3×3的正方形,每次池化移动步长为2,这样就会出现重叠。重叠池化可以避免过拟合,这个策略贡献了0.3%的Top-5错误率。
网络的模型参数越多,模型越容易过拟合,
用全局平均池化层代替全连接层执行分类器的职责。
为什么最后可以直接对卷积特征执行全局平均池化得到分类结果?
SSD网络
『TensorFlow』SSD源码学习_其二:基于VGG的SSD网络前向架构
SSD目标检测
SSD原理解读-从入门到精通
彻底搞懂SSD网络结构
resnet残差网络
ResNets
bottleneck architecture 瓶颈结构
短路连接(shortcut connection)
ResNet之Deeper Bottleneck Architectures
深度学习之Bottleneck Layer or Bottleneck Features
ResNet :( residual 、residual bottleneck)
Deeper Bottleneck(瓶颈) Architectures
倒置残差与线性瓶颈层从原理到实现
mobilenet
mobilenet系列之又一新成员—mobilenet-v3
轻量级神经网络“巡礼”(二)—— MobileNet,从V1到V3
MobileNet系列
MobileNet V1提出了深度可分离卷积(depthwise separable convolution),这种深度可分离卷积虽然很好的减少计算量,但同时也会损失一定的准确率。该网络基本去除了pool层,使用stride来进行降采样。
MobileNet V2 引入了Inverted Residuals和Linear Bottlenecks。
MobileNet V3发表于2019年,该v3版本结合了v1的深度可分离卷积、v2的Inverted Residuals和Linear Bottleneck、SE模块,利用NAS(神经结构搜索)来搜索网络的配置和参数
轻量化网络
从SqueezeNet开始模型的参数量就不断下降,为了进一步减少模型的实际操作数(MAdds),MobileNetV1利用了深度可分离卷积提高了计算效率,而MobileNetV2则加入了线性bottlenecks和反转残差模块构成了高效的基本模块。随后的ShuffleNet充分利用了组卷积和通道shuffle进一步提高模型效率。CondenseNet则学习保留有效的dense连接在保持精度的同时降低,ShiftNet则利用shift操作和逐点卷积代替了昂贵的空间卷积。
近年来,随着智能应用的不断增加,轻量化网络成为近年来的一个研究热点,毕竟不是所有设备都有GPU来计算的,轻量化 网络顾名思义,就是网络的参数量比较少,速度较快,下面总结了目前常用的一些减少网络计算量的方法:
基于轻量化网络设计:比如mobilenet系列,shufflenet系列, Xception等,使用Group卷积、1x1卷积等技术减少网络计算量的同时,尽可能的保证网络的精度。
模型剪枝: 大网络往往存在一定的冗余,通过剪去冗余部分,减少网络计算量。
量化:利用TensorRT量化,一般在GPU上可以提速几倍。
知识蒸馏:利用大模型(teacher model)来帮助小模型(student model)学习,提高student model的精度。
MobilenetV3的h_swish和h_sigmoid
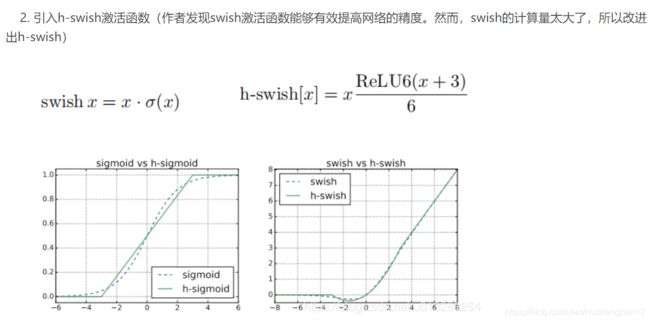
DL知识拾贝(Pytorch)(二):DL元素之一:激活函数
为什么MobilenetV3的h_swish和h_sigmoid不需要计算FLOPs?
代码
MobileNet-v2 pytorch 代码实现
mobilenet V1&V2讲解以及torch代码
(原)MobileNetV1
(原)MobileNetV2
MobileNet V1代码pytorch
【论文学习】轻量级网络——MobileNetV3终于来了(含开源代码)
MobileNets V3神经网络简介与代码实战
深度可分离卷积
深度和可分离的卷积结构可以加快训练速度,并大大减少计算量
我最早接触深度可分离卷积是在Xception网络结构中,这个网络就不在这里赘述了,这里主要讲一下参数计算。
假设某一层输入通道是8,输出通道是16,使用的卷积核是3x3,使用正常卷积那么这层的参数计算方式为(8x3x3+1)x16=1168,其中1是偏置带来的参数。具体为,输入通道数据被16个不同的8x3x3大小的卷积核遍历,
在可分离卷积里面参数计算方式为8x3x3+16x(8x1x1+1)=216,其中和8相乘的1是大小为1卷积核参数,最后加的1是偏置带来的参数。具体为,输入通道数据被8个不同3x3大小的卷积核遍历1次,生成8个特征图谱,8个特征图谱中每个被16个8x1x1卷积核遍历,生成16个特征图谱。
通过分离卷积操作参数从1168个降到216个,可见在模型复制度上有很大的优化


TensorFlow实现深度可分离卷积
深度可分离卷积(Xception 与 MobileNet 的点滴)
Depthwise卷积与Pointwise卷积
卷积神经网络中的Separable Convolution
通道洗牌、变形卷积核、可分离卷积?盘点卷积神经网络中十大令人拍案叫绝的操作
卷积 | 深度可分离卷积、分组卷积、空洞卷积、转置卷积(反卷积)
代码
PyTorch实现深度可分离卷积(以MobileNet为例)
Deeplab
DeepLabv1 [1]: We use atrous convolution to explicitly control the resolution at which feature responses are computed within Deep Convolutional Neural Networks.
DeepLabv2 [2]: We use atrous spatial pyramid pooling (ASPP) to robustly segment objects at multiple scales with filters at multiple sampling rates and effective fields-of-views.
DeepLabv3 [3]: We augment the ASPP module with image-level feature [5, 6] to capture longer range information. We also include batch normalization [7] parameters to facilitate the training. In particular, we applying atrous convolution to extract output features at different output strides during training and evaluation, which efficiently enables training BN at output stride = 16 and attains a high performance at output stride = 8 during evaluation.
DeepLabv3+ [4]: We extend DeepLabv3 to include a simple yet effective decoder module to refine the segmentation results especially along object boundaries. Furthermore, in this encoder-decoder structure one can arbitrarily control the resolution of extracted encoder features by atrous convolution to trade-off precision and runtime.
DeepLabv1
可看作DCNN和CRF的级联。其一由于DCNN中重复的最大池化和下采样造成分辨率下降,DeepLabv1通过带孔(atrous)算法解决。其二分类器获得以对象为中心的决策需要空间不变性,从而限制了DCNN的空间精度,DeepLabv1通过条件随机场(CRF)提高模型捕获精细细节的能力。
基础层是VGG16
DeepLabv2
用多尺度获得更好的分割效果(使用ASPP) ,受SPPNet启发,DeepLabv2提出一个类似结构,对给定输入以不同采样率的空洞卷积进行采样,以多比例捕捉图像上下文,称为ASPP(astrous spatial pyramid pooling)。
基础层由VGG16转为ResNet
DeepLabv2 相对于 v1 最大的改动是增加了受 SPP(Spacial Pyramid Pooling) 启发得来的 ASPP(Atrous Spacial Pyramid Pooling),在模型最后进行像素分类之前增加一个类似 Inception 的结构,包含不同 rate(空洞间隔) 的 Atrous Conv(空洞卷积),增强模型识别不同尺寸的同一物体的能力:
DeepLabv3
回顾了空洞卷积,在级联模块和金字塔池化框架下也能扩大感受野提取多尺度信息。改进了ASPP:由不同的采样率的空洞卷积和BN层组成,以级联或并行的方式布局。大采样率的3×3空洞卷积由于图像边界效应无法捕获长程信息,将退化为1×1的卷积,我们建议将图像特征融入ASPP。复制了ResNet最后的block,并级联起来。
没有使用CRF
DeepLabv3+:通过encoder-decoder进行多尺度信息的融合,同时保留了原来的空洞卷积和ASSP层, 其骨干网络使用了Xception模型,提高了语义分割的健壮性和运行速率。
语义分割丨DeepLab系列总结「v1、v2、v3、v3+」
deeplab 官方PPT
Semantic Segmentation --DeepLab(1,2,3)系列总结
deeplab系列总结(deeplab v1& v2 & v3 & v3+)
从FCN到DeepLab
Semantic Segmentation – (DeepLabv3)Rethinking Atrous Convolution for Semantic Image Segmentation论文解
从FCN到DeepLab
deeplab系列总结
Encoder-Decoder-with-Atrous-Separable-Convolution-for-Semantic-Image-Segmentation
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
代码
【windows10】使用pytorch版本deeplabv3+训练自己数据集
DeepLab系列之V3+
DeepLabV3+ 基本原理及Pytorch版注解
【语义分割系列】deeplabv3相关知识点以及pytorch实现(ASSP模块)
DeepLab 语义分割模型 v1、v2、v3、v3+ 概要(附 Pytorch 实现)
deeplab v3+ pytorch实现 有人写过吗?
pytorch-deeplab-xception代码解析
空洞卷积(Dilated/Atrous Convolution)
在标准的 convolution map 里注入空洞,以此来增加 reception field。dilated的好处是不做pooling损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。
pooling 池化
池化主要任务是对数据降维,减小网络参数,提升网络的计算效率,同时,池化也是增加感受野的方法之一,但在增加感受野的同时,伴随着分辨率的降低,图像细节损失
dilated conv空洞卷积
空洞卷积的出现为了解决pooling层增大感受野之后进行上采样(增加图像的分辨率)过程中,图像信息缺失问题。
空洞卷积与普通卷积相比,增加了感受野,但是不会增加需要训练的参数的量,因为,感受野增加范围内的其他像素点是选择性的跳过,能看得到,但是不需要计算。
是选择性的跳过了部分的像素值进行卷积计算,并不是增加padding,填充像素0的操作。
空洞卷积(Dilated Convolution):有之以为利,无之以为用
空洞卷积(dilated convolution)理解
如何理解空洞卷积(dilated convolution)?
总结-空洞卷积(Dilated/Atrous Convolution)
【深度学习】空洞卷积(Atrous Convolution)
总结-空洞卷积(Dilated/Atrous Convolution)
空洞卷积感受野计算
空洞卷积(dilated convolution)感受野计算
PSPnet
深度学习从入门到女装PSPNet
Semantic Segmentation–Pyramid Scene Parsing Network(PSPNet)论文解读
Fast Rcnn
目标检测算法Fast R-CNN简介
一文读懂Faster RCNN
深度学习模型压缩方法
低秩近似(low-rank Approximation),网络剪枝(network pruning),网络量化(network quantization),知识蒸馏(knowledge distillation)和紧凑网络设计(compact Network design)。
深度学习模型压缩方法(3)-----模型剪枝(Pruning)
【论文阅读笔记】—《A Survey of Model Compression and Acceleration for Deep Neural Networks》
【一文看懂】深度神经网络加速和压缩新进展年度报告
模型压缩总览
浅谈模型压缩之量化、剪枝、权重共享
Unet
初探Unet网络
图像分割的U-Net系列方法
论文精读及分析:U-Net: Convolutional Networks for Biomedical Image Segmentation
U-Net: Convolutional Networks for Biomedical Image Segmentation(理解+github代码)
深度可分离卷积和Xception的区别

下采样和池化的区别
【小记】下采样和池化的区别
Low-level feature和High level feature
Low-level feature: 通常是指图像中的一些小的细节信息,例如边缘(edge),角(corner),颜色(color),像素(pixeles), 梯度(gradients)等,这些信息可以通过滤波器、SIFT或HOG获取;
High level feature:是建立在low level feature之上的,可以用于图像中目标或物体形状的识别和检测,具有更丰富的语义信息。
通常卷积神经网络中都会使用这两种类型的features: 卷积神经网络的前几层学习low level feature,后几层学习的是high level feature。
高级语义信息、低级语义信息
对图像中语义信息、高层和底层特征的理解
图像的低级语义信息指的是颜色,纹理,形状等,关注的是细节信息,语义信息少,但**是目标位置准确。**高级语义信息指的是抽象出来的东西,用于人类去理解,不关注细节信息,语义信息丰富,但是目标位置粗略。比如说识别一张人脸,低级语义信息指的是轮廓,眼睛,鼻子等小的东西,感受野小,高级语义信息指的是整个一张人脸,感受野大。

不需要提前预训练网络
为什么要从0开始训练一个检测模型,而不是fine-tune一个预训练的模型呢?这是本文的出发点,而作者也在文中介绍了三个主要原因:1、是预训练的模型一般是在分类图像数据集比如Imagenet上训练的,不一定可以迁移到检测模型的数据上(比如医疗图像);2、预训练的模型,其结构都是固定的,所以如果你要再修改的话比较麻烦;3、预训练的分类网络的训练目标一般和检测目标不一致,因此预训练的模型对于检测算法而言不一定是最优的选择。
不需要预训练模型的检测算法—DSOD
![]()
卷积神经网络中拍案叫绝的操作
卷积神经网络技巧总结
变形卷积核、可分离卷积?卷积神经网络中十大拍案叫绝的操作。
通道洗牌、变形卷积核、可分离卷积?盘点卷积神经网络中十大令人拍案叫绝的操作。
卷积神经网络中十大拍案叫绝的操作:卷积核大小好处、变形卷积、可分离卷积等
卷积网络CNN中各种常见卷积过程
多孔的空间金字塔池化(ASPP)
可学习的空间金字塔注意力池化模块,用于图像合成和图像到图像转换
【语义分割】ASPP
语义分割(semantic segmentation)–DeepLabV3之ASPP(Atrous Spatial Pyramid Pooling)代码详解
金字塔池化系列的理解SPP、ASPP
一种基于注意力机制的空洞卷积空间金字塔池化上下文学习方法与流程
代码
语义分割(semantic segmentation)–DeepLabV3之ASPP(Atrous Spatial Pyramid Pooling)代码详解
SEnet 注意力机制
Attention(注意力)机制
空间域和通道域注意力机制
卷积核作为CNN的核心,通常都是在局部感受野上将空间(spatial)信息和特征维度(channel-wise)的信息进行聚合最后获取全局信息。卷积神经网络由一系列卷积层、非线性层和下采样层构成,这样它们能够从全局感受野上去捕获图像的特征来进行图像的描述,然而去学到一个性能非常强劲的网络是相当困难的。
论文的动机是从特征通道之间的关系入手,希望显式地建模特征通道之间的相互依赖关系。另外,没有引入一个新的空间维度来进行特征通道间的融合,而是采用了一种全新的“特征重标定”策略。具体来说,就是通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去增强有用的特征并抑制对当前任务用处不大的特征,通俗来讲,就是让网络利用全局信息有选择的增强有益feature通道并抑制无用feature通道,从而能实现feature通道自适应校准。

图1是SENet的Block单元,图中的Ftr是传统的卷积结构,X和U是Ftr的输入(C’xH’xW’)和输出(CxHxW),这些都是以往结构中已存在的。SENet增加的部分是U后的结构:对U先做一个Global Average Pooling(图中的Fsq(.),作者称为Squeeze过程),输出的1x1xC数据再经过两级全连接(图中的Fex(.),作者称为Excitation过程),最后用sigmoid(论文中的self-gating mechanism)限制到[0,1]的范围,把这个值作为scale乘到U的C个通道上, 作为下一级的输入数据。这种结构的原理是想通过控制scale的大小,把重要的特征增强,不重要的特征减弱,从而让提取的特征指向性更强。

senet论文笔记
ImageNet冠军模型SE-Net详解
Momenta详解ImageNet 2017夺冠架构SENet
解读Squeeze-and-Excitation Networks(SENet)
SENet学习笔记
SENet详解
Squeeze-and-Excitation Networks
CV领域常用的注意力机制模块(SE、CBAM)
【CV中的Attention机制】最简单最易实现的SE模块
代码
[论文笔记]-SENet和SKNet(附代码)
senet代码python
Inception 模块
之前的AlexNet、VGG等结构都是通过增大网络的深度(层数)来获得更好的训练效果,但层数的增加会带来很多负作用,比如overfit、梯度消失、梯度爆炸等。inception的提出则从另一种角度来提升训练结果:能更高效的利用计算资源,在相同的计算量下能提取到更多的特征,从而提升训练结果。
NIN的结构和传统的神经网络中多层的结构有些类似,后者的多层是跨越了不同尺寸的感受野(通过层与层中间加pool层),从而在更高尺度上提取出特征;NIN结构是在同一个尺度上的多层(中间没有pool层),从而在相同的感受野范围能提取更强的非线性。
增加网络深度和宽度的同时减少参数。
增加了网络的宽度,增加了网络对尺度的适应性,不同的支路的感受野是不同的,所以有多尺度的信息在里面。引入了1x1卷积主要是为减少了减参。
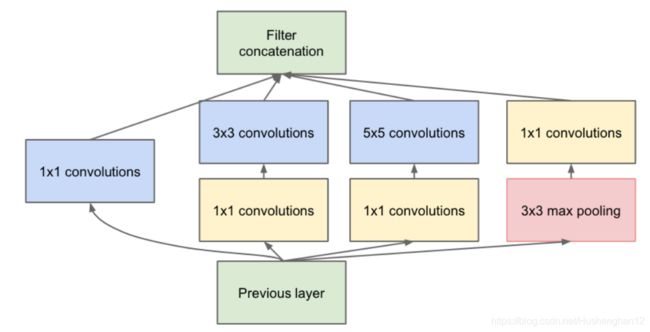
Inception 模块作用
Inception Module-深度解析
一文概览Inception家族的「奋斗史」
inception-v1,v2,v3,v4----论文笔记
极简解释inception V1 V2 V3 V4
从Inception v1,v2,v3,v4,RexNeXt到Xception再到MobileNets,ShuffleNet,MobileNetV2,ShuffleNetV2,MobileNetV3
Group convolution 分组卷积,最早在AlexNet中出现,由于当时的硬件资源有限,训练AlexNet时卷积操作不能全部放在同一个GPU处理,因此作者把feature maps分给多个GPU分别进行处理,最后把多个GPU的结果进行融合。
卷积 | 深度可分离卷积、分组卷积、空洞卷积、转置卷积(反卷积)
pytorch代码实现
Inception(Pytorch实现)
【pytorch torchvision源码解读系列—3】Inception V3
pytorch 实现inception 最简单上手的写法
one/zero short
Zero-shot learning 指的是我们之前没有这个类别的训练样本。但是我们可以学习到一个映射X->Y。如果这个映射足够好的话,我们就可以处理没有看到的类了。
One-shot learning 指的是我们在训练样本很少,甚至只有一个的情况下,依旧能做预测。
什么是 One/zero-shot learning?
dense net
用于减轻梯度消失问题,优点是:省参数和省计算,抗过拟合:对于没有对数据进行数据增广的数据集,DenseNet架构要比其他网络架构表现地更优秀
DenseNet
目标检测网络
目标检测分为了2种主流框架:
- Two stages:以Faster RCNN为代表,即RPN网络先生成proposals目标定位,再对proposals进行classification+bounding box regression完成目标分类。
- Single shot/one stage:以YOLO/SSD为代表,一次性完成classification+bounding box regression