每日学习打卡-汇总处
学习的活动都在公司了
基于保密事宜,就不在此打卡记录了。更新暂停。
2021年07月26日~8月1日
上班(加班)、做视频、、
2021年07月17~25日
完了,尽是上班(加班)和干各种杂事。。
2021-07-16
上班(加班)
2021-07-15
上班(加班)
2021-07-14
上班(加班)
2021-07-13
上班(加班)。业务很复杂,理解成本高,不敢怠慢
2021-07-12
上班(加班)
2021-07-11
忙着找房子
2021-07-10
主要是把入职培训视频教程都搞完
2021-07-09
耗费了巨多时间在调通开发工具IDE……
还有就是公司自己也有培训,学习任务繁重
估计周末要有空学习的话也不是go了,而是培训
2021-07-08
估计以后每天都会卷到10点半到家。。
主要是学习公司业务、整理工具——恼人,信息安全导致很多原本的开发工具不能用,疯狂找替代品……
2021-07-07
噔噔咚,入职了
一堆东西要学,过了下新公司py代码规范,装一堆工具和依赖。已经确定要搞go了,老程序看来得战略性暂时搁置一下了。
2021-07-06
继续自学老程序……
进行到项目实战了
2021-07-05
继续自学老程序……
2021-07-04
今天不摸鱼,自学老程序(
2021-07-03
取报告生生被医院系统拖了一上午
然后又是处理买药、买枕头之类的琐事。。
2021-07-02
看病+休息+补Q2总结
2021-07-01
转为纯头皮疼痛了,但还有任务未完成,所以仍去公司了。做完工作后,顺带看了些技术文章
2021-06-30
莫名耳朵、头皮疼痛,休息。
2021-06-29
看了如下文章:
我偷偷监听了他们的通信流量···
https://mp.weixin.qq.com/s/vqBl1lW3RvAg39ocgpmPGA
网卡混杂模式、ARP欺骗
即使删了全库,如何半小时恢复?
https://mp.weixin.qq.com/s/OFPSsOfHhdQa4HYdvDTaRg
最保险方案是:设置两个从库,和主库同步完成后自动断开一小时,且两个从库之间相隔半小时执行主库同步操作。代价是比较耗费资源去维护额外从库。
宕机了,缓存数据没了。。。
https://mp.weixin.qq.com/s/AFd2rOKD7RViadUjBGiobw
主要讲redis的 aof。包含写时复制、aof文件重写、三种将 AOF 日志写回硬盘策略 (Always、Everysec 、No)等知识点
2021-06-28
休病假。。
2021-06-27
又是事情扎堆。。
2021-06-26
太多事堆在周末了……而且还有检测要做,轮次都到4了……何时是尽头
2021-06-25
继续在白天摸鱼看了一批公众号技术文章
2021-06-24
白天摸鱼看了一批公众号技术文章
2021-06-23
白天忙着整理文档和过代码。。
晚上是赶投稿。。
2021-06-22
尝试代理用在git拉代码
2021-06-21
先看了一些旧档公众号技术文章
然后继续策划新视频……
2021-06-20
继续整视频。。
2021-06-19
整视频。。
2021-06-18
把《增长黑客》看完了
尝试搜索《精益创业》的拆书或者读书笔记。暂时还没有好的。
2021-06-17
读《增长黑客》。
策划数据录入。
2021-06-16
一直忙着想新视频的事情……就看了一些技术文章
redis作者与分布式大牛的论战挺精彩的……
2021-06-15
开始自学docker,安装了下docker环境,正在进行一些操作命令的学习
2021-06-14
读了一些积攒的公众号技术文章
2021-06-13
休息……随便看了些公众号技术文章
2021-06-12
完了,啥也没做的样子
忙着搞证件照还没搞成,被节假日休息挡住了
2021-06-11
重新生成并导出了原创榜。但是可能还要再改,ping战士没出现在榜里,需要确认下原因。
添加收藏夹的操作加到了recent_song里。
2021-06-10
天天debug到半夜扛不住
今天休息,就看看文章好了……
2021-06-09
继续重构自己的业余项目代码
一个是recent song的重构,很快完成了
另一个是原创音乐榜的重构,debug了好久……额
2021-06-08
继续重构自己的业余项目代码
重构动态爬取功能
2021-06-07
继续重构自己的业余项目代码
并新加了批量将新歌放入收藏夹的功能
2021-06-06
继续重构自己的业余项目代码
并新加了动态爬取功能
2021-06-05
在自己家里的pc机搭建了python2.7、IDE、mysql开发环境
重构了下自己的业余项目代码
2021-06-04
因为参加公司周年活动,没有整段的学习时间。
倒是在无聊间隙,刷了一些公众号的技术学习文章,有空整理下笔记发出。
2021-06-03
因为去向已定
所以今后的打卡不再有算法内容
而是会以实际技术学习甚至业务学习为主。
学习、复习了以下内容:
开始阅读《增长黑客》
2021-06-02
今天的力扣每日一题是:02.07. 链表相交
https://leetcode-cn.com/problems/intersection-of-two-linked-lists-lcci/
本来是简单题,但被解答提示里的o(n)骗了,本来想好的方法就不自信了,觉得用时太长啥的。。。
坚持自己的做法就行。先分别用一次循环算出两个链表的长度,然后将较长链表的指针提前移动gap步,gap就是链表长度差值。然后就是cur1和cur2同时移动比较,相同就返回cur1。最后外面返回None。
学习、复习了以下内容:
虽是请假面试了……但是没想到自己各种杂事做完居然没时间读书了!
2021-06-01
六一节快乐哈~
今天的力扣每日一题是:19. 删除链表的倒数第 N 个结点
https://leetcode-cn.com/problems/remove-nth-node-from-end-of-list/
挺简单的,以前就记住了做法,就是fast和slow指针,fast先走n步。
学习、复习了以下内容:
打算将《副业赚钱》看完
2021-05-31
史上体验最糟的面试……到底是我的问题还是面试官的问题?
2021-05-30
今天的力扣每日一题是:24. 两两交换链表中的节点
https://leetcode-cn.com/problems/swap-nodes-in-pairs/
临时节点还是很方便的,因为后面步进的时候,只需要移动cur就行了:
cur = dummy
ListNode* tmp = cur->next; // 记录临时节点
ListNode* tmp1 = cur->next->next->next; // 记录临时节点
cur->next = cur->next->next; // 步骤一
cur->next->next = tmp; // 步骤二
cur->next->next->next = tmp1; // 步骤三
cur = cur->next->next; // cur移动两位,准备下一轮交换
但是next太多了,费脑。。。以后做可能还是会用left、mid和right三个指针。步进多一点也没啥
学习、复习了以下内容:
面试……
2021-05-29
学习、复习了以下内容:
加班完后……把《图解HTTP》看完了
2021-05-28
面试+加班……
2021-05-27
今天的力扣每日一题是:206. 反转链表
https://github.com/youngyangyang04/leetcode-master/blob/master/problems/0206.%E7%BF%BB%E8%BD%AC%E9%93%BE%E8%A1%A8.md
反转完忘记把哑结点的next指向left了……而且我用了三个指针……实际上中途用个tmp过渡就行了
学习、复习了以下内容:
加班。。
2021-05-26
今天的力扣每日一题是:707. 设计链表
https://github.com/youngyangyang04/leetcode-master/blob/master/problems/0707.%E8%AE%BE%E8%AE%A1%E9%93%BE%E8%A1%A8.md
本来不难,但是各种细节魔鬼,调试了很久。
需要注意特殊情况,比如index小于0,index超过长度,虚拟头结点
学习、复习了以下内容:
百度面试……
2021-05-25
vivo面试。。
2021-05-24
今天的力扣每日一题是:203. 移除链表元素
https://github.com/youngyangyang04/leetcode-master/blob/master/problems/0203.%E7%A7%BB%E9%99%A4%E9%93%BE%E8%A1%A8%E5%85%83%E7%B4%A0.md
细节是魔鬼,一开始居然没做对。要特别小心,dummy_head做完cur的删除后,只移动cur指针,pre指针不要动!
只有在无删除发生的时候,才同时移动pre和cur
学习、复习了以下内容:
《图解HTTP》看到了第40页
2021-05-23
今天的力扣每日一题是:59.螺旋矩阵II
https://github.com/youngyangyang04/leetcode-master/blob/master/problems/0059.%E8%9E%BA%E6%97%8B%E7%9F%A9%E9%98%B5II.md
他的python解法和他的图解不一致。python解法和我之前看的官方思路是一样的。
额,反正还是没能独立做出来,思路又混乱了
还是要善于使用xrange(right, left-1, -1)这样的倒序遍历啊,注意left-1是遍历中实际不会触达的值,如果left=0,left-1就是-1,不会遍历到-1 的。
最外层循环是while left<=right and up<=down:
初始化一定要使用matrix = [ [0]*n for _ in range(n)] 否则会出问题。
学习、复习了以下内容:
把《精益创业》看完了
2021-05-22
今天的力扣每日一题是:209. 长度最小的子数组
https://github.com/youngyangyang04/leetcode-master/blob/master/problems/0209.%E9%95%BF%E5%BA%A6%E6%9C%80%E5%B0%8F%E7%9A%84%E5%AD%90%E6%95%B0%E7%BB%84.md
又学废了……
窗口思维。外层是for i in xrange(n) ,也就是右指针,每次都sum+=nums[i]
左指针只有在sum超过target时,才右移
返回时记得判断是不是float("inf")
今天想把借的书《精益创业》先看完了。没有技术学习
2021-05-21
今天的力扣每日一题是:27.移除元素
https://github.com/youngyangyang04/leetcode-master/blob/master/problems/0027.%E7%A7%BB%E9%99%A4%E5%85%83%E7%B4%A0.md
简单题居然翻车了……脑子一团浆糊。
定义左右指针,左指针为val时让右指针的值覆盖它然后右指针向中间靠。左不为val时左指针才向中间靠。其他情况。注意right初始化=nums.size(),最后return left
学习、复习了以下内容:
盘点了一下有关机器卡顿检测的一些linux命令,比如iostat,top,dstat
2021-05-20
今天interview……
2021-05-19
今天开始,按大佬的建议顺序进行刷题:https://github.com/youngyangyang04/leetcode-master
于是今天的力扣每日一题是:
https://github.com/youngyangyang04/leetcode-master/blob/master/problems/0704.%E4%BA%8C%E5%88%86%E6%9F%A5%E6%89%BE.md
注意边界 left<=right 和 right = mid-1
学习、复习了以下内容:
计算机网络:自顶向下方法看到了27页,ISP,分组交换vs电路交换,传输时延&传播时延
2021-05-18
今天的力扣每日一题,37. 解数独
hard,不会。。。
我直接下次一定
学习、复习了以下内容:
读了军哥手记的几篇文章,都是心法心得,不是很多干货……
https://mp.weixin.qq.com/s/i1xIaBHu9LTCDNIBqaGtzw
四本书、一个专栏,揉成这篇MySQL(一)
https://mp.weixin.qq.com/s/qKGUiglWF0EWcnFOlU3JBA
复习了MySQL的一些支持。server在上,引擎在下,using where是server层在过滤。
myisam是查询性能高,插入不行(因为是表锁)
没人告诉过你更复杂的缓存穿透怎么解决
https://mp.weixin.qq.com/s/a_hhpAZ1i4QcJX4caAevzw
除了前置缓存、布隆过滤器以外,多了一个办法:快速过期空值缓存
2021-05-17
在头疼炸裂的情况下,进行了一个面试……太难了我
2021-05-16
嗯,默写出了昨天的题
然后是今天的力扣每日一题,36. 有效的数独
大致先自己构思了扫描法,觉得太麻烦了,于是直接看官方题解了。
答案果然很简洁,关键是子数独矩阵的id计算方法:boxid = (i/3)*3 + j / 3
学习、复习了以下内容:
char和varchar区别
https://blog.csdn.net/qq_20264581/article/details/83755789
char定长255,编码无关,空出的部分用空格填充
varchar不定长65532,有多少存多少,不填充
tcp如何保活
https://blog.csdn.net/chenlycly/article/details/81030671
TCP保活探测报文是将之前TCP报文的序列号减1,并设置1个字节,内容为“00”的应用层数据
如果客户端发送keepalive probe报文之前的TCP报文是1833序号
那么keepalive报文序号是-1,也就是1832序号
对方回复的ack报文,则又会变成1833序号
一般而言,保活探测主要在服务器端实现,如果应用层有相应的保活机制时,传输层的TCP保活就可以不用。
Linux 写时复制机制原理
https://mp.weixin.qq.com/s/e6VESPfZPPWpy2emZEGK_g
fork出子进程时,暂时不会分配新的内存给子进程,而是把父进程的虚拟内存->物理内存的映射关系copy给子进程,这样父子共享同一个只读内存。
当父、子进程其中一方要写内存时,才会发生内存复制,单独给子进程copy内存,使得父子分别映射到不同物理内存区域。
2021-05-15
嗯是默写出了昨天的题,还是有点半知不解的(默写了还各种调试才过)
然后是今天的力扣每日一题,35. 搜索插入位置
简单题,放松了警惕。应该用二分法做的!哦,也不是。如果不是官方提示,我都没发现直接用二分是做不出来的,需要做一些细节,比如ans=n, target <= nums[mid]
学习、复习了以下内容:
今天进行两个面试,真心身体都有掏空的感觉了……
2021-05-14
力扣每日一题,34. 在排序数组中查找元素的第一个和最后一个位置
被细节搞死了,没做出来
等下次背诵全文。。
学习、复习了以下内容:
Redis 核心篇:唯快不破的秘密
https://mp.weixin.qq.com/s/soSL3OZybeYoFKYo-x2PEw
然后就是绝赞加班……
2021-05-13
前天力扣的题,33. 搜索旋转排序数组,隔了一天,默写不出来了。。。感觉还是没能深入了解这个算法。
然后又是燃尽的面试……我的天,已经面了三场,但这周还有两场……
2021-05-12
面试燃尽……
2021-05-11
成功默写出了昨天的力扣题
然后是今天的力扣每日一题,33. 搜索旋转排序数组
https://leetcode-cn.com/problems/search-in-rotated-sorted-array/
我咋记得以前做过类似的……很简单的思路,没想出来。自己做的虽然是通过了,但是时间复杂度不是最优的。明天再默写一遍吧。
摘抄一个评论理解:
将数组一分为二,其中一定有一个是有序的,另一个可能是有序,也能是部分有序。
此时有序部分用二分法查找。无序部分再一分为二,其中一个一定有序,另一个可能有序,可能无序。就这样循环.
学习、复习了以下内容:
操作系统(程序员cxuan编写).pdf
看到265页
2021-05-10
力扣每日一题,32. 最长有效括号
https://leetcode-cn.com/problems/longest-valid-parentheses/
hard难度,而我低估了它的难度,自己用栈做了半天也没搞出来……
最后看了方法三,感觉贪心算法挺妙的,对left、right计数,左右各扫一次。不需要额外空间。
我决定明天再默写一遍py版。也决定了以后如果题做不出来,就先看题解,第二天再默写(前提是题目不要太复杂了)
学习、复习了以下内容:
没有。今天面试,已无余力了……
2021-05-09
力扣每日一题,31. 下一个排列
https://leetcode-cn.com/problems/next-permutation/
遗憾的是我又没做出来(看到答案后更加遗憾了)
因为感觉思路其实不复杂,但就是想不出:
首先从后向前查找第一个顺序对 (i,i+1),满足 a[i] < a[i+1]。这样「较小数」即为 a[i]。此时 [i+1,n)必然是下降序列。
如果找到了顺序对,那么在区间 [i+1,n)中从后向前查找第一个元素 j 满足 a[i] < a[j]。这样「较大数」即为 a[j]。
交换 a[i] 与 a[j],此时可以证明区间 [i+1,n) 必为降序。我们可以直接使用双指针反转区间 [i+1,n) 使其变为升序,而无需对该区间进行排序。
学习、复习了以下内容:
阅读 图解网络-小林coding.pdf 已看完,回头需要重新看一次,整理里面用到的实验命令、参数
2021-05-08
力扣每日一题,30. 串联所有单词的子串
hard难度,我直接跪
这个解法好,我跪again
https://leetcode-cn.com/problems/substring-with-concatenation-of-all-words/solution/xiang-xi-tong-su-de-si-lu-fen-xi-duo-jie-fa-by-w-6/
大意:滑动窗口,两个hashmap,并大步跳过已确认会包含非法子串的部分
学习、复习了以下内容:
阅读 图解网络-小林coding.pdf 看到了240页
2021-05-07
力扣每日一题,29. 两数相除
https://leetcode-cn.com/problems/divide-two-integers/
做不出,也没有官方解
看了宫水下面的评论的解法,略微懂了些但是不敢说掌握了
https://leetcode-cn.com/problems/divide-two-integers/solution/shua-chuan-lc-er-fen-bei-zeng-cheng-fa-j-m73b/
需要学习 :判断溢出、判断negative 、 快速乘法 以及 二分法快速找出商
学习、复习了以下内容:
阅读 图解网络-小林coding.pdf 看到了169页
2021-05-06
今天辅导新人入职,完全没时间摸鱼……
晚上面试,于是连题也没得刷了,休息……
2021-05-05
力扣每日一题,24. 两两交换链表中的节点
https://leetcode-cn.com/problems/swap-nodes-in-pairs/
以前做过的题。结果,一开始做错了,交换完之后,second的位置变了,所以步进指针的时候应该是用first来做。比如second = first.next.next
学习、复习了以下内容:
阅读 图解网络-小林coding.pdf 看到了46页
2021-05-04
力扣每日一题,23. 合并K个升序链表
https://leetcode-cn.com/problems/merge-k-sorted-lists/
没做出来。。。其实问题可以化为多个成对的list合并的小问题的,不管是分治还是用数组维护……自己想复杂了,想到了优先队列那里去了,然后总想用非组件的方式实现优先队列(实际上官方直接用了c++自带的)。
学习、复习了以下内容:
今天听了下面试分享的直播(可惜是校招的,勉强能有一些能用的……)
1、面试的时候试一下录音吧,方便复盘
2、突击算法,适合刷剑指offer
3、投入时间在算法上不宜过多,性价比略低
4、多看面经中的多次出现的,比较考基础的题
5、专精计网?
6、有时间的话还是推荐正统的去学算法书而不是直接刷题
2021-05-03
力扣每日一题,22. 括号生成
https://leetcode-cn.com/problems/generate-parentheses/
没思路……看了官方答还是没懂。太抽象了
学习、复习了以下内容:
1.3w字,操作系统高频面试题大分享
https://mp.weixin.qq.com/s/oTEMOQY1xcG8uVceW-kLDA
如何提升多线程的效率:
尽量使用池化技术,也就是线程池,从而不用频繁的创建,销毁线程
减少线程之间的同步和通信
通过Huge Page的方式避免产生大量的缺页异常
避免需要频繁共享写的数据
进程的调度算法有哪些?
先来先服务调度算法
时间片轮转调度算法
短作业优先调度算法
最短剩余时间优先调度算法
高响应比优先调度算法(等的越久、越是短作业,则越优先)
优先级调度算法
页面置换算法有哪些?
https://www.cnblogs.com/wingsless/p/12295246.html
最佳置换算法OPT:仅是一种理想情况,作为标尺
先进先出算法:belady异常,不适合作为实际使用
最近最少使用算法:被认为是最接近OPT的算法
时钟置换算法:在时钟置换算法的基础上可以做一个改进,就是增加一个标记为m,修改过标记为1,没有修改过则标记为0。那么u和m组成了一个元组,有四种可能,其被逐出的优先顺序也不一样:
(u=0, m=0) 没有使用也没有修改,被逐出的优先级最高;
(u=1, m=0) 使用过,但是没有修改过,优先级第二;
(u=0, m=1) 没有使用过,但是修改过,优先级第三;
(u=1, m=1) 使用过也修改过,优先级第四。
belady异常
https://blog.csdn.net/weixin_36340947/article/details/78177817
即,缓存页面容量越多,缺页率反而越高的怪异现象
2021-05-02
力扣每日一题,21. 合并两个有序链表
https://leetcode-cn.com/problems/merge-two-sorted-lists/
想复杂了,老想着对List1进行插入修改(虽说做出来了)
实际上,官方答案里只需要搞个临时头结点,pre=head,让pre-next指向更小的节点,然后不断移动pre就行了。
学习、复习了以下内容:
把codesheep的计算机网络面试题总结.pdf 看完了
Ping 命令的具体过程是怎么样的?
参考文章:《对于 Ping 的过程,你真的了解吗?》
https://mp.weixin.qq.com/s/DfQT3Vw2xaq60YIil-7Yxw
基于ICMP((Internet Control Message Protocol)Internet控制报文协议)
开局a电脑ARP询问并缓存ip对应的mac地址
结束后,b电脑反过来ARP询问并缓存a电脑ip对应的mac地址,以待下次使用
查看arp缓存的命令 : ARP - a
2021-05-01
力扣每日一题,20. 有效的括号
https://leetcode-cn.com/problems/valid-parentheses/
简单的做过的题,用栈即可,不赘述。
学习、复习了以下内容:
InnoDB的七种锁
https://mp.weixin.qq.com/s/f4_o-6-JEbIzPCH09mxHJg
(1)自增锁(Auto-inc Locks):表级锁,专门针对事务插入AUTO_INC的列,如果插入位置冲突,多个事务会阻塞,以保证数据一致性;
(2)共享/排它锁(Shared and Exclusive Locks):行级锁,S锁与X锁,强锁;
(3)意向锁(Intention Locks):表级锁,IS锁与IX锁,弱锁,仅仅表明意向;
(4)插入意向锁(Insert Intention Locks):如果插入位置不冲突,虽然事务隔离级别是RR,虽然是同一个索引,虽然是同一个区间,但插入的记录并不冲突
(5)记录锁(Record Locks):索引记录上加锁,对索引记录实施互斥,以保证数据一致性;
(6)间隙锁(Gap Locks):封锁索引记录中间的间隔,在RR下有效,防止间隔中被其他事务插入;
(7)临键锁(Next-key Locks):封锁索引记录,以及索引记录中间的间隔,在RR下有效,防止幻读;
2021-04-30
力扣每日一题,19. 删除链表的倒数第 N 个结点
独立做出来了,好耶!
用的是快慢指针的方法,常数空间,一次遍历完成。
然后是做了HW(怀疑是外包,因为外带了个外企德科的前缀)的机试。跪了,一道都没完全通过的。自闭去了
2021-04-29
力扣每日一题,18. 四数之和
https://leetcode-cn.com/problems/4sum/
我竟没看懂……留作以后回头细看
生病休息。。明天看医生
2021-04-28
力扣每日一题,17. 电话号码的字母组合
https://leetcode-cn.com/problems/letter-combinations-of-a-phone-number/
没有使用递归去做,但貌似也暗合了官方的回溯法的思想
学习、复习了以下内容:
今天太忙了……
2021-04-27
力扣每日一题,16. 最接近的三数之和
https://leetcode-cn.com/problems/3sum-closest/
和昨天一样,先排序,只用两个嵌套循环。跳过上次已经枚举过的数,内层循环是相互靠近的双指针。
综合这几点,就能优化时间复杂度
……然而今天做,忘记排序了,内层循环也忘了大半。
而且不知道为啥,我默写官方的解法也超时。。。
学习、复习了以下内容:
电脑的 IP 是怎么来的呢?
https://mp.weixin.qq.com/s/QN-mzf5NGfuB6UxKNL-pfg
新电脑广播,源ip=0.0.0.0,目的ip=255.255.255.255,请求分配ip(discover 报文)
dhcp服务器给新电脑发ip分配报文 目的mac=新电脑mac,目的ip为255.255.255.255(offer报文)
新电脑一般选择拿到的第一个offer报文,向它回复ack(request 报文)
如果 DHCP 服务器没有在我们所在的局域网里怎么办?这个 discover 报文 就会通过我们的网关来进行传递,并且会把源 ip 替换成网络的 ip,源端口是 68,这里涉及到 NAT 地址到转换。
在DHCP客户端的租约时间到达 1/2 时,客户端会向为它分配 IP 地址的DHCP服务器发送 request 单播报文。若回复 ACK 报文,则是通知租约成功。若回复 NAK 报文,则是通知客户端续约失败。
若续约失败,7/8 时间时,广播发送 request 报文进行续约。DHCP服务器处理同首次分配 IP 地址的流程。
Redis多线程网络模型全面揭秘
https://mp.weixin.qq.com/s/Vrw4Q7CB1QItm9RojoquVw
4.0 版本,UNLINK 命令其实就是 DEL 的异步版本,它不会同步删除数据,而只是把 key 从 keyspace 中暂时移除掉,然后将任务添加到一个异步队列,最后由后台线程去删除
6.0 版本之后,Redis 正式在核心网络模型中引入了多线程,也就是所谓的 I/O threading
主线程和 I/O 线程之间共享的变量有三个:
io_threads_pending 计数器、io_threads_op I/O 标识符和 io_threads_list 线程本地任务队列。
io_threads_pending 是原子变量,不需要加锁保护,io_threads_op 和 io_threads_list 这两个变量则是通过控制主线程和 I/O 线程交错访问来规避共享数据竞争问题
在 Redis 的多线程方案中,I/O 线程任务仅仅是通过 socket 读取客户端请求命令并解析,却没有真正去执行命令,所有客户端命令最后还需要回到主线程去执行,因此对多核的利用率并不算高,而且每次主线程都必须在分配完任务之后忙轮询等待所有 I/O 线程完成任务之后才能继续执行其他逻辑。
总结
使用 I/O 线程实现网络 I/O 多线程化,I/O 线程只负责网络 I/O 和命令解析,不执行客户端命令。
利用原子操作+交错访问实现无锁的多线程模型。
通过设置 CPU 亲和性,隔离主进程和其他子进程,让多线程网络模型能发挥最大的性能。
2021-04-26
力扣每日一题,15. 三数之和
先排序,只用两个嵌套循环。跳过上次已经枚举过的数,内层循环是相互靠近的双指针。
综合这几点,就能优化时间复杂度
今天主要是自学小程序去了。想从前到后自己搭一个项目
2021-04-25
力扣每日一题,14. 最长公共前缀
采用了纵向扫描的方式进行检查
学习、复习了以下内容:
TCP ,丫的终于来了!!(原文标题就是这个。。
https://mp.weixin.qq.com/s/o7qF2yti9KaoXTM6SKMdzA
tcp半开启:有一方下线,却不通知对方
tcp半关闭:只开一个方向的传输
RST:(Reset the connection)用于复位因某种原因引起出现的错误连接,也用来拒绝非法数据和请求。如果接收到 RST 位时候,通常发生了某些错误。
csrf 攻击
https://www.cnblogs.com/hyddd/archive/2009/04/09/1432744.html
https://blog.csdn.net/namechenfl/article/details/91038624
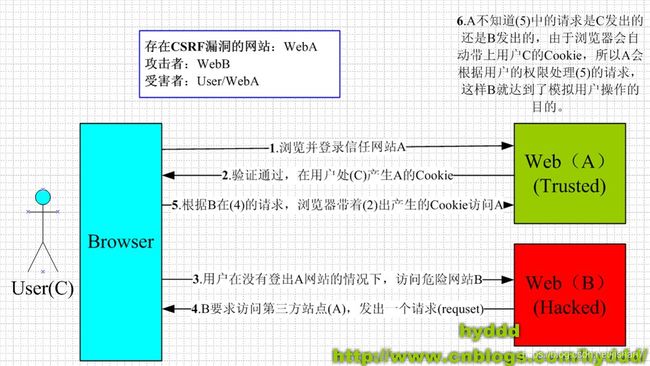
从上图可以看出,要完成一次CSRF攻击,受害者必须依次完成两个步骤:
1、登录受信任网站A,并在本地生成Cookie。
2、在不登出A的情况下,访问危险网站B。
最多能创建多少个 TCP 连接?【故事
https://mp.weixin.qq.com/s/X6c_H5_4OInR8nFQVn7IMA
tcp连接数受 可用端口数、可打开文件数、IO模型、内存大小、cpu处理速度的 限制
cat /proc/sys/net/ipv4/ip_local_port_range 查看可用端口总数
1024 65000
只要源端口号不用够用了,就不断变换目标 IP 和目标端口号,保证四元组不重复,我就能创建好多好多 TCP 连接啦
关于文件数量上限,系统级:当前系统可打开的最大数量,通过 cat /proc/sys/fs/file-max 查看
用户级:指定用户可打开的最大数量,通过 cat /etc/security/limits.conf 查看
进程级:单个进程可打开的最大数量,通过 cat /proc/sys/fs/nr_open 查看
如果不是多路复用模式,那么一个线程只能管一个tcp连接,一万个线程导致cpu不停上下文切换,卡死。
负载均衡的原理
https://mp.weixin.qq.com/s/NUFRX51D9Yf9yzRQnPeWlg
LVS是4层LB(网络层的load balance
nginx是7层LB
2021-04-24
力扣每日一题,377. 组合总和 Ⅳ
1、明知是动规;2、做不出来;3、直接放弃看解析
我觉得策略不对。以后不做每日一题了。代之以每天按题号顺序刷题,否则每天都做中高阶难度的题,没有打底基础,没效果。
学习、复习了以下内容:
今天做一个公司的在线笔试,烧脑,休息……
2021-04-23
力扣每日一题,368. 最大整除子集
1、明知是动规;2、做不出来;3、初看答案看不懂;4、看解析比做题时间长n倍;5、隐隐中思路明白了不过背答案依旧是背不明白
学习、复习了以下内容:
线程安全是什么?举个例子?
https://blog.csdn.net/suifeng3051/article/details/52164267
多线程只要对同个资源有写操作,并且无法预测和控制顺序,那么就不是线程安全的
python可变、不可变类型
https://zhuanlan.zhihu.com/p/88306012
可变类型list、dict、set:修改它们时,是在它们所在的内存地址上直接修改value。
不可变类型str、num、tuple:修改它们时,是重新开个新的内存地址空间,存放新值。旧地址的内容并未变。
python的可变变量、不可变变量在堆和栈是怎么分布
https://blog.csdn.net/qq_41065770/article/details/104623012
a=5 是在堆还是在栈?答案是堆,因为它是短数字,在小对象整数池(这个池位于堆)
最多能创建多少个TCP连接【故事
https://mp.weixin.qq.com/s/mGkf-9LZhhUgSIRBRqfRDw
我是一个路由器【故事
https://mp.weixin.qq.com/s/VyGQ4-Dn4UX2Z0CrCHgUqw
我是一个网卡【故事
https://mp.weixin.qq.com/s/vyHlB9pem4rv4htJS9ca6Q
TCP/IP 之 大明王朝邮差【故事
https://mp.weixin.qq.com/s/SiHkaWeV0JSmdv5s0jqWgg
一个故事讲完https【故事
https://mp.weixin.qq.com/s/StqqafHePlBkWAPQZg3NrA
2021-04-22
力扣每日一题,363. 矩形区域不超过 K 的最大数值和
https://leetcode-cn.com/problems/max-sum-of-rectangle-no-larger-than-k/
太复杂了,改天看……
据说要先看懂以下(前缀和解法
https://leetcode-cn.com/problems/range-sum-query-2d-immutable/solution/xia-ci-ru-he-zai-30-miao-nei-zuo-chu-lai-ptlo/
然后才是看这个
https://leetcode-cn.com/problems/max-sum-of-rectangle-no-larger-than-k/solution/gong-shui-san-xie-you-hua-mei-ju-de-ji-b-dh8s/
学习、复习了以下内容:
Nginx 默认提供的负载均衡策略
1、轮询(默认)round_robin
2、IP 哈希 ip_hash
3、最少连接 least_conn
4、权重 weight
还可以通过插件支持其他策略。
Nginx的master和worker是如何工作的?
1、Nginx 在启动后,会有一个 master 进程和多个相互独立的 worker 进程。
2、master 接收来自外界的信号,先建立好需要 listen 的 socket(listenfd) 之后,然后再 fork 出多个 worker 进程,然后向各worker进程发送信号,每个进程都有可能来处理这个连接。
3、所有 worker 进程的 listenfd 会在新连接到来时变得可读 ,为保证只有一个进程处理该连接,所有 worker 进程在注册 listenfd 读事件前抢占 accept_mutex ,抢到互斥锁的那个进程注册 listenfd 读事件 ,在读事件里调用 accept 接受该连接。
4、当一个 worker 进程在 accept 这个连接之后,就开始读取请求、解析请求、处理请求,产生数据后,再返回给客户端 ,最后才断开连接。
nginx中500、502、503、504 有什么区别?
500:Internal Server Error 内部服务错误,比如脚本错误,编程语言语法错误。
502:Bad Gateway错误,网关错误。比如服务器当前连接太多,响应太慢,页面素材太多、带宽慢。
503:Service Temporarily Unavailable,服务不可用,web服务器不能处理HTTP请求,可能是临时超载或者是服务器进行停机维护。
504:Gateway timeout 网关超时,程序执行时间过长导致响应超时,例如程序需要执行20秒,而nginx最大响应等待时间为10秒,这样就会出现超时。
2021-04-21
力扣每日一题,解码方法
https://leetcode-cn.com/problems/decode-ways/solution/jie-ma-fang-fa-by-leetcode-solution-p8np/
想过可能是动态规划,但是不会写迁移方程。。
最后直接看了答案。
需牢记:
f = [1] + [0] * n
f[i] += f[i - 1] 如果 s[i-1] != '0'
f[i] += f[i - 2] 如果 i > 1 and s[i-1]和s[i-2]两个字符能组成合法的字母
然后就是晚上面试+超级加倍……今天先这样
2021-04-20
力扣每日一题,求解子串。用了暴力匹配去做了。。
https://leetcode-cn.com/problems/implement-strstr/solution/shi-xian-strstr-by-leetcode-solution-ds6y/
KMP算法,之前接触过,很快忘了(因为过于复杂)。以后有空复习吧
然后就是超级加倍(班)没时间复习了,今天先这样
2021-04-19
力扣每日一题, 移除元素。终于打破了进球荒,自己把题做出来了,而且吻合官方优化版的方法二。
双指针,左指针是val则用右指针存的值覆盖,右指针加1
不是val,则左指针+1
最后返回左指针的偏移量即长度
学习、复习了以下内容:
一直停留在time_wait是什么情况
原因:服务器主动关闭连接时产生time_wait。短连接表示“业务处理+传输数据的时间 远远小于 TIMEWAIT超时的时间”的连接,高并发会导致关闭行为非常多,产生time_wait也会非常多。
实操解决:
https://www.cnblogs.com/dadonggg/p/8778318.html
https://blog.csdn.net/qq_35238352/article/details/106052401
让服务器能够快速回收和重用那些TIME_WAIT的资源
websocket标记位
客户端 to 服务端
GET /chat HTTP/1.1
Host: server.example.com
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Key: dGhlIHNhbXBsZSBub25jZQ==
Origin: http://example.com
Sec-WebSocket-Protocol: chat, superchat
Sec-WebSocket-Version: 13
服务端 to 客户端
HTTP/1.1 101 Switching Protocols
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Accept: s3pPLMBiTxaQ9kYGzzhZRbK+xOo=
Sec-WebSocket-Protocol: chat
https://www.cnblogs.com/liyuanhong/articles/10066811.html
websocket握手协议
生成器 send和next区别
https://blog.csdn.net/qq_39521554/article/details/79864889
send能传参send(val), next()不行
send不能在第一次调用生成器时传参
send传进去的参,会先赋值给yield的左边
2021-04-18
今天烧脑面试+大量加班,休息下……
2021-04-17
力扣每日一题, 存在重复元素 III。我直接┗( ´・∧・`)┛投降
一道和重复元素没有关系的题。
花了近一个小时,总算搞清楚了桶算法的原理:
假设数组为:
0,1,2,3,4,5,6
假设t=3,每个数都去除以t+1,即除以4【是地板除】,得到每个数的桶id分布为:
0,0,0,0,1,1,1
0号桶装着【0,1,2,3】,1号桶装着【4,5,6】。可以看出桶内部元素之间差值都是<=t =3的
用这种方法可以非常轻松的划分出一堆 桶内元素差值符合条件的多个桶,降低了复杂度。
地板除结果相同的数,比如456,必定是彼此相差不超过t=3的。直观上看8-4超过了3,所以不在这个桶里,实际规律上可知8/4=2,其他数地板除=1,所以不在一个桶。
但相邻桶是有可能相差小于等于t=3的,比如8和5。所以算法上,遍历到某个数x时,除了要判断x归属的桶里有没有数,还要判断相邻的桶有么有符合条件的数。
至于怎么取桶id。。。正数就是x/(t+1),负数就是(x + 1) / (t+1) - 1
怎么理解负数的id取法?
假设数组为:
0,1,2,3,4,5,6, 0,-1,-2,-3,-4,-5,-6
如果直接用t+1=4,地板除得到每个数的id:
0,0,0,0,1,1,1, 0,0,0,0,-1,-1,-1
不行啊!-3和+3怎么能放在同一个桶id=0里面呢?他两的差是6>t=3!
后排的偏移直接-1也不行,因为这样后面的桶分布是【-1,-2,-3】【-4,-5,-6,-7】【-8,-9,-10,-11】。。。桶的分片不均匀了。
所以最终做法是原数+1,然后除以t+1【为了均匀】,得到的偏移量再-1【为了避免都挤在0号桶】 即-------(x + 1) / (t+1) - 1
最终的桶划分是这样的:
[0, 1, 2, 3,][ 4, 5, 6, 7]
[-1,-2,-3, -4,] [-5,-6,-7,-8]
学习、复习了以下内容:
死锁是啥?如何解开死锁?
https://zhuanlan.zhihu.com/p/61221667
互斥条件:一个资源每次只能被一个进程使用。
请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺。
循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
死锁防止:在程序运行之前防止发生死锁。
1、使资源同时访问而非互斥使用,就没有进程会阻塞在资源上,从而不发生死锁。
2、静态分配,指进程必须在执行之前就申请需要的全部资源,且直至所要的资源全部得到满足后才开始执行。
3、占有资源的进程若要申请新资源,必须主动释放已占有资源,若需要此资源,应该向系统重新申请。或者:资源分配管理程序为进程分配新资源时,若有则分配;否则将剥夺此进程已占有的全部资源,并让进程进入等待资源状态,资源充足后再唤醒它重新申请所有所需资源。
4、给系统的所有资源编号,规定进程请求所需资源的顺序必须按照资源的编号依次进行。
死锁避免(运用银行家算法,避免进入不安全状态,即死锁状态)
死锁检测(不试图阻止死锁的发生,发生后才恢复)
死锁检测算法:每种类型一个资源的死锁检测算法是通过检测有向图是否存在环来实现,从一个节点出发进行深度优先搜索,对访问过的节点进行标记,如果访问了已经标记的节点,就表示有向图存在环,也就是检测到死锁的发生。
死锁恢复法:
资源剥夺法、进程回退法、进程撤销法、系统重启法
Supervisor
https://zhuanlan.zhihu.com/p/63340417
Supervisor是用Python开发的一套通用的进程管理程序,能将一个普通的命令行进程变为后台daemon,并监控进程状态,异常退出时能自动重启。它是通过fork/exec的方式把这些被管理的进程当作supervisor的子进程来启动,这样只要在supervisor的配置文件中,把要管理的进程的可执行文件的路径写进去即可。当子进程挂掉的时候,父进程可以获取子进程挂掉的信息,选择是否自己启动和报警。
https://www.zhihu.com/question/48833333/answer/302719973
缺点:不能跨主机,本身需要被监控,开机自启依赖其他程序
可能需要Systemd来负责Supervisord的运行
Celery
https://zhuanlan.zhihu.com/p/208951697
Celery是一个功能完备即插即用的异步任务队列框架
Celery的架构由三部分组成,消息队列(message broker),任务执行单元(worker)和任务执行结果存储(task result store)组成。
任务队列是一种跨线程、跨机器工作的一种机制.
任务队列中包含称作任务的工作单元。有专门的工作进程持续不断的监视任务队列,并从中获得新的任务并处理.
celery通过消息进行通信,通常使用一个叫Broker(中间人)来协client(任务的发出者)和worker(任务的处理者).
clients发出消息到队列中,broker将队列中的信息派发给worker来处理。
Celery本身不提供消息队列功能,但是可以很方便地和第三方提供的消息中间件进行集成,包括RabbitMQ,Redis,mysql,MongoDB等
如果将来项目中存在大批量,并发量高的异步任务,则务必使用RabbitMQ.
如果将来项目中存在少批量,并发量低的异步任务,则建议使用Redis.
python+celery+redis实现定时任务。
https://zhuanlan.zhihu.com/p/112933211
Celery Beat:任务调度器,Beat进程会读取配置文件的内容,周期性地将配置中到期需要执行的任务发送给任务队列
select、poll、epoll发生了几次系统调用,调用都叫什么名字
https://blog.csdn.net/apacat/article/details/51810276
https://blog.csdn.net/wteruiycbqqvwt/article/details/90299610
select:只有select()一次系统调用,阻塞
poll:只有poll()一次系统调用,阻塞
epoll:
第一步:epoll_create()系统调用。此调用返回一个句柄,之后所有的使用都依靠这个句柄来标识。
第二步:epoll_ctl()系统调用。通过此调用向epoll对象中添加、删除、修改感兴趣的事件(即描述符)。
第三部:epoll_wait()系统调用(阻塞)。通过此调用收集在epoll监控中已经发生的事件。
select、poll、epoll 区别总结:
1、支持一个进程所能打开的最大连接数
select:单个进程所能打开的最大连接数有FD_SETSIZE宏定义,其大小是32个整数的大小(在32位的机器上,大小就是3232,同理64位机器上FD_SETSIZE为3264),当然我们可以对进行修改,然后重新编译内核,但是性能可能会受到影响,这需要进一步的测试。
poll:本质上和select没有区别,但是它没有最大连接数的限制,原因是它是基于链表来存储的。【待研究】
epoll:虽然连接数有上限,但是很大,1G内存的机器上可以打开10万左右的连接,2G内存的机器可以打开20万左右的连接。
2、FD剧增后带来的IO效率问题
select:因为每次调用时都会对连接进行线性遍历,所以随着FD的增加会造成遍历速度慢的“线性下降性能问题”。
poll:同上
epoll:因为epoll内核中实现是根据每个fd上的callback函数来实现的,只有活跃的socket才会主动调用callback,所以在活跃socket较少的情况下,使用epoll没有前面两者的线性下降的性能问题,但是所有socket都很活跃的情况下,可能会有性能问题。
3、 消息传递方式
select:内核需要将消息传递到用户空间,都需要内核拷贝动作
poll:同上
epoll:epoll通过内核和用户空间共享一块内存来实现的。
进程间通讯有哪些?管道通讯是什么情况下用?
https://zhuanlan.zhihu.com/p/111195310
PIPE可称为“匿名管道”,无需命名,在具有亲属关系的进程中使用;
FIFO又可称为“命名管道”,在使用过程中,其会在系统中创建FIFO类型文件,从而可通过此文件进行不相关进程间的通信。
PIPE为半双工通信,即在一次通讯中,数据只能在一个方向上流动。
FIFO为全双工通信,在一次通讯中,两端可以同时收发数据。
匿名管道,父进程先创建管道,然后fork子进程,于是他们拥有了一个管道可以通讯
FIFO管道mkfifo出来后,还需要open函数打开才能使用。他可以跨进程,无需父子
什么场景适合使用PIPE管道?
https://zhuanlan.zhihu.com/p/66466326
无需关心回收,进程结束系统自动回收资源;实现简单;输出流格式标准化
进程通信方式和应用场景
https://www.jianshu.com/p/4989c35c9475
2021-04-16
力扣每日一题,扰乱字符串。我直接┗( ´・∧・`)┛投降
改天再详细的,看一下解法,背一背吧。我估计即便是投入大量精力去搞它,面试也不会出,而且即便面试碰到了也写不出来吧。。。
学习、复习了以下内容:
硬核讲解秒杀设计
https://mp.weixin.qq.com/s/rbXrhzIJG2NtYt_61OmzTA
漏桶算法,令牌桶算法。后者是比较常用的缓存限流方法。
Google开源项目Guava实现了令牌桶,有空需要进一步了解
乐观锁、悲观锁
https://www.jianshu.com/p/d2ac26ca6525
https://blog.csdn.net/L_BestCoder/article/details/79298417
悲观:读数据、写数据都加锁。包含共享锁和排他锁两种
乐观:写的时候才判断,先前读的数据是否有变。缺点是一旦遇上高并发的时候,就只有一个线程可以修改成功,那么就会存在大量的失败。
乐观锁实现之版本号控制:
一般是在数据表中加上一个数据版本号 version 字段,表示数据被修改的次数。当数据被修改时,version 值会+1。当线程A要更新数据值时,在读取数据的同时也会读取 version 值,在提交更新时,若刚才读取到的 version 值与当前数据库中的 version 值相等时才更新,否则重试更新操作,直到更新成功。
innodb的MVCC(多版本并发控制技术)
https://www.cnblogs.com/chenpingzhao/p/5065316.html
DATA_TRX_ID 标记了最新更新这条行记录的transaction id
DATA_ROLL_PTR 指向undo log记录,找之前版本的数据就是通过这个指针
DB_ROW_ID,当由innodb自动产生聚集索引时,聚集索引包括这个DB_ROW_ID的值
DELETE BIT标记删除
理想MVCC难以实现的根本原因在于企图通过乐观锁代替二段提交。为了保证其一致性,修改两行数据,与修改两个分布式系统中的数据并无区别,而二提交是目前这种场景保证一致性的唯一手段。二段提交的本质是锁定,乐观锁的本质是消除锁定,二者矛盾,故理想的MVCC难以真正在实际中被应用,Innodb只是借了MVCC这个名字,提供了读的非阻塞而已。
2021-04-15
力扣每日一题,打家劫舍 II。我已经dp公式想的差不多了,但就是倒在首尾相连这个特性上,死活搞不对。官方真有毒,老搞这种第一天推高阶题,第二天推低阶题的操作,高阶题的解答还建议我先去读低阶题的解答,搞什么,提前剧透明天的每日一题?那我明天干嘛?
学习、复习了以下内容:
布隆过滤器和布谷鸟过滤器
https://mp.weixin.qq.com/s/8jheJ8abNDeZSExYMZRsGg【布谷鸟的部分没有看完
为什么要分库分表?什么时候才分?
https://mp.weixin.qq.com/s/xiZtNHt6Ie7jgANTCjyhag
图灵机的图解
https://mp.weixin.qq.com/s/aWtV9tYTMGSh2hLKXdacuA
2021-04-14
力扣每日一题,前缀树。我知道前缀树的定义,知道数据结构和操作方法,但是……唯独就是写不出来!看着官方的def我懵了。于是又是默写过去了。
学习、复习了以下内容:
描述符是啥,作用是?
https://blog.csdn.net/qq_28616183/article/details/53507700
property进化版,批量规定实例多个属性的初始化、获取、更新方式和取值设定等。
不用写一大堆get set方法了,函数访问化为属性调用:m.setparam(1) 变成 m.param=1
删除链表的倒数第 n 个节点, 能否只遍历一遍?
给定一个链表: 1->2->3->4->5, 和 n = 2. 当删除了倒数第2个节点后,链表变为 1->2->3->5
答题思路:两个指针a和b,b先走n步,然后a与b同时开始以同样的步进1去遍历。当b遍历到末尾时,a.next刚好就是要删的节点。
2021-04-13
力扣每日一题,二叉搜索树里,任意两个节点的差值中找最小的。思路是中序遍历过程中比较前后的差值。我给气死,执行代码和提交的结果完全不同,明明是同一个测试用例啊!完全没法debug了。逻辑copy过来都不能用,c。
(复习)学习了以下内容:
epoll的边缘触发模式ET和水平触发模式LT
https://mp.weixin.qq.com/s/k3qALmbjxxAPPg6v1-RDOA
如何理解LT:只要IO需要操作(有数据可读或可写),那么必通知
ET:只有IO从不可操作变成可操作时才通知(不可写变成可写;不可读变成可读)
所以,使用 epoll 边缘模式去检测数据是否可读,触发可读事件以后,一定要一次性把 socket 上的数据收取干净才行。水平模式则不需要。
MySQL双主架构
https://mp.weixin.qq.com/s/_tT4L3ukmktUV3K8g7ZmeQ
最佳实践:
(1)双主保证写库高可用,只有一个写库提供服务(主库),另一个是shadow库,在主库挂掉时替补上场;
(2)设置大于1的相同步长,不同初始值,可以避免auto increment生成冲突主键;或者(3)不依赖数据库,业务调用方自己生成全局唯一ID是一个好方法;
(4)内网DNS探测,可以实现在主库1的外网访问出现问题后,延时一个时间(是为了等待主库1到主库2的同步执行完成),再进行主库切换,以保证数据一致性,代价是牺牲了几秒钟的高可用
无锁缓存,每秒10万并发,究竟如何实现?
https://mp.weixin.qq.com/s/BfuRWaB7RDjpGmQbZdmMZw
当业务满足以下条件时:
(1)超高并发;(2)写多读少;(3)定长value;
提升吞吐量的最佳实践是:
(1)一条记录一个锁;需要大内存
(2)无锁,最大化并发;通过签名的方式保证数据的完整性,实现无锁缓存;
写时写签名,读时校验签名。读取缓存发现签名和实际数据无法匹配,则重查数据库。
究竟如何保证session一致性?
https://mp.weixin.qq.com/s/hCrcboJ6CHe8qlg-fv4T0A
最佳实践是:后端统一存储—— web-server重启和扩容,session也不会丢失
原因1、web层、service层无状态是大规模分布式系统设计原则之一,session属于状态,不宜放在web层
原因2、让专业的软件做专业的事情,web-server存session?还是让cache去做这样的事情吧
第三方服务挂了,如何保证服务不受影响?
https://mp.weixin.qq.com/s/FRFnVgqctHzVXO9MBPQD0g
(1)如果业务能接受旧数据:读取本地数据,异步代理定期更新数据;
(2)有多个第三方服务提供商:多个第三方互备;
(3)客户端发起写入请求,本地直接返回成功,同时用异步的形式,将客户端的写入数据传给第三方;
TCP接入层的负载均衡、高可用、扩展性架构
https://mp.weixin.qq.com/s/pKR-Kf2lsqz3bW5M76mR7Q
最佳实践:
服务端提供get-tcp-ip接口,向client端屏蔽负载均衡策略,并实施便捷扩容。
client每次访问tcp-server前,先调用一个新增的get-tcp-ip接口,
对于client而言,这个http接口只返回一个tcp-server的IP;
拿到tcp-server的IP后,和原来一样向tcp-server发起TCP长连接;
另外,get-tcp-ip接口要定期“拉”tcp-server状态,以及时发现并踢掉停止工作的server。
用户中心,1亿数据,架构如何设计?
https://mp.weixin.qq.com/s/8KTK_Bz8netP6R5MNSKeFw
用户中心,是典型的“单KEY”类业务,最佳实践:
(1)用户侧,采用“建立非uid属性到uid的映射关系”的架构方案;
(2)运营侧,采用“前台与后台分离”的架构方案;
——前台用户侧,“建立非uid属性到uid的映射关系”的最佳实践:
(1)缓存映射法:缓存中记录login_name与uid的映射关系;
(2)基因法:login_name基因融入uid;
假设分8库,采用uid%8路由,潜台词是,uid的最后3个bit决定这条数据落在哪个库上,这3个bit就是所谓的“基因”。先生成61bit的全局唯一id,作为用户的标识,如上图绿色部分;接着把3bit的login_name_gene也作为uid的一部分,如上图屎黄色部分;
——后台运营侧,“前台与后台分离”的最佳实践是:
(1)前台、后台系统 web/service/db 分离解耦,避免后台低效查询引发前台查询抖动;
(2)可以采用数据冗余的设计方式;
(3)可以采用“外置索引”(例如ES搜索系统)或者“大数据处理”(例如HIVE)来满足后台变态的查询需求;
帖子中心,1亿数据,架构如何设计?
https://mp.weixin.qq.com/s/40uJBsgFWhcrJ3Xvkraulg
将以“帖子中心”为典型的“1对多”类业务,在架构上,采用元数据与索引数据分离的架构设计方法:
(1)帖子服务,元数据满足uid和tid的查询需求;
(2)搜索服务,索引数据满足复杂搜索寻求;
对于元数据的存储,最佳实践:
(3)基因法,按照uid分库,在生成tid里加入uid上的分库基因,保证通过uid和tid都能直接定位到库;
百亿关系链,架构如何设计?
https://mp.weixin.qq.com/s/nBprprEg6AFcX-m2-S_26A
(这里以好友关系的正反表写入为例。a是b的好友,b是a的好友,在db中是两条记录,一正一反),
冗余数据最佳实践:
线下异步冗余。也就是写正表完成后,留下一条log,异步任务检测到log后,开始写反表。
数据冗余会带来一致性问题,高吞吐互联网业务,完全保证事务一致性很难,常见实践是最终一致性。最终一致性最佳实践是尽快找到不一致,并修复数据,最佳实践:
(5.1)线上实时检测法;
向消息总线发送消息,如上图1-4流程所示:
(1)写入正表T1;
(2)第一步成功后,发送消息msg1;
(3)写入反表T2;
(4)第二步成功后,发送消息msg2;
实时订阅消息的服务不停的收消息。假设正常情况下,msg1和msg2的接收时间应该在3s以内,如果检测服务在收到msg1后没有收到msg2,就尝试检测数据的一致性,不一致时进行补偿修复。
这两天面试的问题较多,需要进一步整理,后续再发
2021-04-12
力扣每日一题,找出多个数字字符串组合后的最大值。没做出来,主要是耗费在排序算法的选择上,实际上貌似可以直接使用python自带的sort就行?
首先是对昨天问题的一些答案检索:
1、给定一个包含 0, 1, 2, ..., n 中 n 个数的序列,有一个数没有出现在序列中, 找出那个数?
https://leetcode-cn.com/problems/missing-number/solution/que-shi-shu-zi-by-leetcode/
高赞评论的解法很清晰
int sum = 0;
for (int i = 1; i <= nums.length; i++) {
sum += i;
sum -= nums[i - 1];
}
return sum;
2、二叉搜索树(BST)
https://www.cnblogs.com/lykkk/p/10314787.html
3、如何用redis实现延时队列
https://my.oschina.net/u/3266761/blog/1930360
4、redis 主从同步是怎样的过程?
a、从服务器向主服务器发送 SYNC 命令。
b、接到 SYNC 命令的主服务器会调用BGSAVE 命令(fork子进程),创建一个 RDB 文件,并使用缓冲区记录接下来执行的所有写命令。
c、当主服务器执行完 BGSAVE 命令时,它会向从服务器发送 RDB 文件,而从服务器则会接收并载入这个文件。
d、主服务器将缓冲区储存的所有写命令发送给从服务器执行。
5、如何用udp实现消息有序、不丢失不重发的聊天室?
https://blog.csdn.net/qq_43496435/article/details/114231574 【感觉不像是面试官想问的
6、你如何设计flask那样的路径匹配?当有一堆路径注册函数,如何快速搜索找到匹配?
暂未找到
我的回答是使用前缀树。不确定是不是
https://blog.csdn.net/weixin_39778570/article/details/81990417
7、进程调度算法
先来先服务:先来后到
时间片轮转:先来先服务,但是只运行一个时间片(如100ms)
短作业优先 :从后备队列中选择一个或若干个估计运行时间最短的作业,将它们调入内存运行
最短剩余时间:选择预期剩余时间最短的进程
高响应比:R=(w+s)/s (R为响应比,w为等待处理的时间,s为预计的服务时间)
优先级:从后备作业队列中选择优先级最髙的一个或几个作业,将它们调入内存
多级反馈队列:既能使高优先级的作业得到响应又能使短作业(进程)迅速完成
8、LRU的定义
LRU是Least Recently Used的缩写,即最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰。
LRU怎么实现的,底层结构是?
双链表+哈希表。哈希表用于快速定位链表中的每个节点
9、flask底层实现,路由怎么做的?
暂未找到
10、为什么内存以页为单位分配
暂未找到
11、分布式系统如何获得统一的id序号
a方法: GUID(Globally Unique Identifier,全局唯一标识符)
GUID制定的算法中使用到用户的网卡MAC地址,以保证在计算机集群中生成唯一GUID;在相同计算机上随机生成两个相同GUID的可能性是非常小的,但并不为0。所以,用于生成GUID的算法通常都加入了非随机的参数(如时间),以保证这种重复的情况不会发生。
缺点是32位占用,阅读不友好
b方法:建立两台以上的数据库ID生成服务器,每个服务器都有一张记录各表当前ID的MaxId表,但是MaxId表中Id的增长步长是服务器的数量,起始值依次错开,这样相当于把ID的生成散列到每个服务器节点上。例如:如果我们设置两台数据库ID生成服务器,那么就让一台的MaxId表的Id起始值为1(或当前最大Id+1),每次增长步长为2,另一台的MaxId表的ID起始值为2(或当前最大Id+2),每次步长也为2。这样就将产生ID的压力均匀分散到两台服务器上。
缺点是扩展性差
c方法:我需要翻一下过去看过的某篇文章。
12、redis多主如何同步数据
暂未找到
13、https握手过程?为什么要获取证书?
我需要翻一下过去看过的某篇文章。
14、POST和PUT区别
POST是新增资源,非幂等
PUT是修改资源,是幂等的
其他,语义上面差异很大,注意!【未完成!
https://www.zhihu.com/question/48482736
晚上又进行了一个面试,
面试完很累……明天再把速记下的几个被问到的盲点问题查一下再发
2021-04-11
力扣每日一题, 给你一个整数 n ,请你找出并返回第 n 个 丑数 。
输了,我超时了……又没能自己想出动态规划(思路又是差一点点)
今天进行了面试,比较费脑,休息下……先罗列几个被问到的盲点问题,第二天查一下
1、给定一个包含 0, 1, 2, ..., n 中 n 个数的序列,有一个数没有出现在序列中, 找出那个数?
2、二叉搜索树是?
3、如何用redis实现延时队列
4、redis 主从同步是怎样的过程?
5、如何用udp实现消息有序、不丢失不重发的聊天室?
6、你如何设计flask那样的路径匹配?当有一堆路径注册函数,如何快速搜索找到匹配?
7、进程调度算法
8、LRU怎么实现的,底层结构是?
9、flask底层实现,路由怎么做的?
10、为什么内存以页为单位分配
11、分布式系统如何获得统一的id序号
12、redis多主如何同步数据
13、https握手过程?为什么要获取证书?
14、POST和PUT区别
2021-04-10
力扣每日一题, 丑数。一上来想用递归,溢出……不过改成循环比较好改。代码简洁度略微比官方的差一些。这次答题还不错。
复习了python的metaclass
道(type)生一(元类),一生二(类),二生三(实例),三生万物(实例的属性和方法)
class Hello(object){}
# class 后声明“我是谁”
# 小括号内声明“我来自哪里”
# 中括号内声明“我要到哪里去”
元类是由“type”衍生而出,所以父类需要传入type class SayMetaClass(type)
元类的操作都在 __new__中完成
class Hello(object, metaclass=SayMetaClass): # 一生二:创建类
后续的,和普通类的实例化、调用是一样的
关于先改缓存还是先改数据库的问题:
改db前先设置缓存失效时间为一个较短的时间,然后再改db,
改完db再删缓存或者更新缓存,能更稳妥一些
redis如何实现清理超时数据?
a、惰性删除。访问时判断是否过期,是则删除
b、定期随机取出一些有定时字段的key,是过期则删除
c、内存占用超出设定值,强制清理过期key
学习了python的OrderedDict, defaultdict, ChainMap, Counter、MappingProxyType的用法特点
学习了python的弱引用。
弱引用不会使对方的引用计数+1,因而不会妨碍到对方对象的释放
所以在使用弱引用时,要注意被引用的对象有可能在某个时刻被释放。
弱引用是用来预防循环引用、高效节省内存用的。
2021-04-09
力扣每日一题,寻找旋转排序数组中的最小值 II。好家伙,三连击,我甚至都不知道题目有啥区别?好吧其实这次的就是数组里有重复的(昨天的是不重复的)。
解法改变的地方就是,当nums[pivot]==nums[right],则不能草率的用二分法抛弃某一半数组,只能将right-=1
实操学习了netstat、uptime、nc、free、iostat等Linux系统性能相关的命令。还不太熟练,还要多看看。
2021-04-08
力扣每日一题,寻找旋转排序数组中的最小值。每日一题有毒,就不能把今天的题和昨天调换下顺序吗,我终于懂了啥是旋转了,以及题解里的图让我更明白二分查找实际是怎么实现的了。
搜集了不少linux性能查看、调优的命令。但我觉得还是上机实操,比起单纯的看会更好些
整理了之前的疑难面试题笔记,复习了python __new__、dict底层、list底层、set底层、可哈希和不可改变性 的知识
2021-04-07
力扣每日一题,搜索旋转排序数组 II,其实没看出来为啥叫旋转、旋转有啥意义。官方答案是二分查找的改进,不确定区间是否有序的情况下先lr指针缩进一下。评论区说for循环就解决了,我的方法也比较接近是for循环……
阅读python的源码分析文章:
small_ints 是小整数对象的缓存池,范围是 [-5,256],非小整数对象即使值相同,也会创建2个不同的整数对象。
free_list 和 block_list 保存创建过的整数对象分配的内存,在创建新的整数对象时,直接从free_list获取对象的内存空间,初始化对象后就可以使用。
字符串对象实现了单字符的缓冲区,创建单字符的对象时直接从缓冲区中获取对象。
多字符串对象的拼接使用 join 性能好于 '+'。
list对象内部有定量的缓存,提高创建list item对象的速度
list对象的插入,删除操作成本较高,不适宜频繁操作。(list本质是数组
append操作速度较快。
dict对象采用开放地址散列法。
dict对象内部有定量的缓存,提高创建dict对象的速度。
对于长度较小的dict对象,直接使用对象内部的内存,无需二次分配内存,性能较好。
builtin 是python解释器的全局名空间
global 是module对象的全局名空间,保存着module中的变量和函数的引用
local 对应是当前代码块的名空间,保存局部的变量和函数引用
代码块是可以嵌套的,所以local名空间也是嵌套查找。
2021-04-06
力扣每日一题,删除有序数组中的重复项。思路很乱,写了很复杂的代码而且还没通过,于是看答案并默写了一遍……本来确实已经想到了要用后面的内容把前面的给覆盖掉,但是没想清楚覆盖的流程以及如何计算应该返回的长度。
学习了锦标赛排序,思路简单(找亚军,只需找被冠军击败的一群人加赛即可),但代码难写。。。。
复习之前code过的螺旋排序。。。忘的快,真烦。圈层数为最外层循环,层数为长宽最小值,记得下边和左边遍历要额外判断是否已遍历。。。
复习python的dict实现。感觉搜索不太给力,总感觉还有一些隐藏知识点还没有探索到。
2021-04-05
力扣每日一题,合并两个有序数组。都想到逆向指针了,但是被自己绕晕了,然后卡壳了怎么也理解不了数组1后面的000是什么个东西。。后面才发现,是可以覆盖的,压根不需要插入位移……
学习了一些单key、多key、1对多、多对多的业务场景下的表拆分实践。前后台运营数据需求和生产环境分离,挺实用的。
2021-04-04
力扣每日一题,兔子数量。成功提交,不过和官方的思路(贪心算法)不太一样。我的方法有哈希删除的开销。
复习(xuexi)了字符串匹配算法BF、RK、BM和KMP(-_-||)我真不记得我学过,除了BF。KMP的难度够我喝一壶了。
哈夫曼树和哈夫曼编码(这回这个可是真的复习)
2021-04-03
力扣每日一题,最长公共子序列。本来都想到动态规划这一步了。但是思路卡住了最后还是没想出来,就去看了答案,并做了默写
简略了解了一下golang的优点。在考虑要不要再学一门编译型语言(工作中用的是解释型的python)
阅读了innodb mvcc、分布式共识算法的相关文章。分布式真的只是看了一点皮毛,水太深,偏偏面试爱问。。。
复习了跳跃表(-_-||)