Python----数据分析-pandas.DataFrame基础
Python----数据分析-pandas.DataFrame基础
文章目录:
一、DataFrame的创建
二、DataFrame的基础属性
三、DataFrame的排序方法
四、DataFrame的切片操作注意
1.pandas的切片操作注意
2.单列、多行切片操作
3.head()与tail()方法获取多行
五、DataFrame中优化行列的数据获取 -loc(标签索引行) -iloc(位置获取行)-ix()
1.使用loc、iloc方法简单的切片
2.使用loc、iloc方法实现条件切片
3.切片方法之ix
六、DataFrame数据增、删、改、查
七、DataFrame数据的描述分析
1.数值型特征的描述性统计
2.类别型特征的描述性统计
任务实现
DataFrame:一个表格型的数据结构,包含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型等),DataFrame即有行索引也有列索引,可以被看做是由Series组成的字典。
DataFrame对象既有行索引,又有列索引
行索引,表明不同行,横向索引,叫index,0轴,axis=0
列索引,表明不同列,纵向索引,叫columns,1轴,axis=1
一、DataFrame的创建
DataFrame创建的两种方式:
- 通过二维数组创建
- 通过字典的方式创建,此种方法创建同时还要注意:字典中的value值只能是一维数组 或 单个的简单数据类型,如果是数组,要求所有数组长度一致,如果是单个数据,则会使每行添加相同数据。
DataFrame分为行索引和列索引,默认情况下是从0开始,也可以自定义索引,添加行索引使用 index ,添加列索引使用 columns ,此操作称“重置行列索引值”。
import pandas as pd
import numpy as np
t1 = pd.DataFrame(np.arange(12).reshape((3,4)))
print(t1)
# 0 1 2 3
# 0 0 1 2 3
# 1 4 5 6 7
# 2 8 9 10 11
#通过index、columns属性设置行、列索引
t1 = pd.DataFrame(np.arange(12).reshape((3,4)),index=list("abc"),columns=list("WXYZ"))
# print(t1)
# W X Y Z
# a 0 1 2 3
# b 4 5 6 7
# c 8 9 10 11
#字典创建方式
d2 = {
"name":["张三","李四","王五"],"age":["20","21","20"],"tel":["10086","10010","35699"]}
t2 = pd.DataFrame(d2)
print(t2)
# name age tel
# 0 张三 20 10086
# 1 李四 21 10010
# 2 王五 20 35699
d3 = [{
"name":"张三","age":"20","tel":"10086"},{
"name":"李四","tel":"10010"},{
"age":"20","tel":"35699"}]
t3 = pd.DataFrame(d3)
print(t3)
# name age tel
# 0 张三 20 10086
# 1 李四 NaN 10010
# 2 NaN 20 35699
返回顶部
二、DataFrame的基础属性
#DataFrame的基础属性
print(t2.index)
# RangeIndex(start=0, stop=3, step=1)
print(t2.columns)
# Index(['name', 'age', 'tel'], dtype='object')
print(t2.values)
# [['张三' '20' '10086']
# ['李四' '21' '10010']
# ['王五' '20' '35699']]
print(t2.shape)
# (3, 3)
print(t2.dtypes)
# name object
# age object
# tel object
# dtype: object
print(t2.ndim)
# 2
print(t2.head(2)) #显示前两行
# name age tel
# 0 张三 20 10086
# 1 李四 21 10010
print(t2.tail(2)) #显示后两行
# name age tel
# 1 李四 21 10010
# 2 王五 20 35699
print(t2.info()) #展示该DataFrame的具体信息
# 下面如图所示的数据库表单为例:
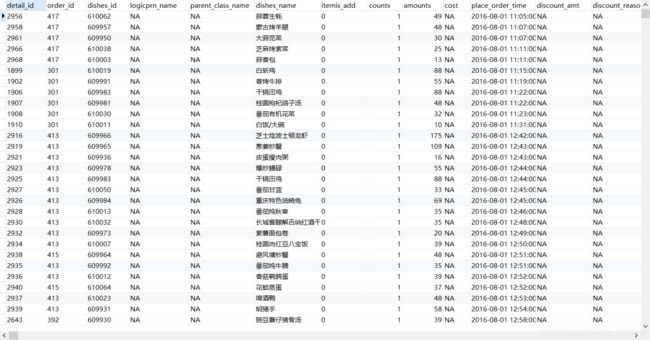
from sqlalchemy import create_engine
import pandas as pd
engine = create_engine('mysql+pymysql://root:[email protected]:3306/testdb?charset=utf8') #创建数据库连接
detail1 = pd.read_sql_table('meal_order_detail1',con=engine)
print('订单详情表的索引为:',detail1.index)
#订单详情表的索引为: RangeIndex(start=0, stop=2779, step=1)
print('订单详情表的所有值为:\n',detail1.values)
#订单详情表的所有值为:
[['2956' '417' '610062' ... 'NA' 'caipu/104001.jpg' '1442']
['2958' '417' '609957' ... 'NA' 'caipu/202003.jpg' '1442']
['2961' '417' '609950' ... 'NA' 'caipu/303001.jpg' '1442']
...
['6756' '774' '609949' ... 'NA' 'caipu/404005.jpg' '1138']
['6763' '774' '610014' ... 'NA' 'caipu/302003.jpg' '1138']
['6764' '774' '610017' ... 'NA' 'caipu/302006.jpg' '1138']]
print('订单详情表的列名为:\n',detail1.columns)
订单详情表的列名为:
Index(['detail_id', 'order_id', 'dishes_id', 'logicprn_name',
'parent_class_name', 'dishes_name', 'itemis_add', 'counts', 'amounts',
'cost', 'place_order_time', 'discount_amt', 'discount_reason',
'kick_back', 'add_inprice', 'add_info', 'bar_code', 'picture_file',
'emp_id'],
dtype='object')
print('订单详情表的数据类型为:\n',detail1.dtypes)
订单详情表的数据类型为:
detail_id object
order_id object
dishes_id object
logicprn_name object
parent_class_name object
dishes_name object
itemis_add object
counts float64
amounts float64
cost object
place_order_time datetime64[ns]
discount_amt object
discount_reason object
kick_back object
add_inprice object
add_info object
bar_code object
picture_file object
emp_id object
dtype: object
# 查看DataFrame的元素个数
print('订单详情表的元素个数是:',detail1.size)
print('订单详情表的维度数是:',detail1.ndim)
print('订单详情表的形状为:',detail1.shape)
订单详情表的元素个数是: 52801
订单详情表的维度数是: 2
订单详情表的形状为: (2779, 19)
返回顶部
三、DataFrame的排序方法
#DataFrame中的排序方法
t2 = t2.sort_values(by="age") #默认升序
print(t2)
# name age tel
# 0 张三 20 10086
# 2 王五 20 35699
# 1 李四 21 10010
t2 = t2.sort_values(by="age",ascending=False)
print(t2)
# name age tel
# 1 李四 21 10010
# 0 张三 20 10086
# 2 王五 20 35699
返回顶部
四、DataFrame的切片操作注意
1.pandas的切片操作注意
- 方括号写数字,表示取行,对行进行操作
- 方括号写字符串,表示取列,对列进行操作
print(t3[:2]) #从开始至第二行结束
# name age tel
# 0 张三 20 10086
# 1 李四 NaN 10010
print(t3[2:]) #从第三行至最后
# name age tel
# 2 NaN 20 35699
print(t3["age"]) #取出纵索引为age的一列
# 0 20
# 1 NaN
# 2 20
# Name: age, dtype: object
print(type(t3["age"])) #该列的数据类型
# # 使用字典访问的方式取出orderinfo中的某一列
order_id = detail1['order_id']
print('订单详情表中的order_id的形状为:\n',order_id.shape)
# 使用访问属性的方式取出orderinfo中的菜品名称一列
dishes_names = detail1.dishes_name
print('订单详情表中的dishes_name的形状为:\n',dishes_names.shape)
以上两种方法均可以从dataframe中取出某一列数据,但是第二种方法不建议使用,因为在平时表格中的列名大多数以英文呈现,难免有一些列名会与pandas库中的方法相同,会引起程序混乱。
返回顶部
2.单列、多行切片操作
ishes_name5 = detail1['dishes_name'][:5]
print('订单详情表中的dishes_name前5个元素为:\n',dishes_name5)
#订单详情表中的dishes_name前5个元素为:
0 蒜蓉生蚝
1 蒙古烤羊腿
2 大蒜苋菜
3 芝麻烤紫菜
4 蒜香包
Name: dishes_name, dtype: object
orderDish = detail1[['order_id','dishes_name']][:5]
print('订单详情表中的order_id和dishes_name前5个元素为:\n',orderDish)
#订单详情表中的order_id和dishes_name前5个元素为:
order_id dishes_name
0 417 蒜蓉生蚝
1 417 蒙古烤羊腿
2 417 大蒜苋菜
3 417 芝麻烤紫菜
4 417 蒜香包
order5 = detail1[:][1:6]
print('订单详情表1-6行元素为:\n',order5)
#订单详情表1-6行元素为:
detail_id order_id dishes_id logicprn_name parent_class_name dishes_name \
1 2958 417 609957 NA NA 蒙古烤羊腿
2 2961 417 609950 NA NA 大蒜苋菜
3 2966 417 610038 NA NA 芝麻烤紫菜
4 2968 417 610003 NA NA 蒜香包
5 1899 301 610019 NA NA 白斩鸡
itemis_add counts amounts cost place_order_time discount_amt \
1 0 1.0 48.0 NA 2016-08-01 11:07:00 NA
2 0 1.0 30.0 NA 2016-08-01 11:07:00 NA
3 0 1.0 25.0 NA 2016-08-01 11:11:00 NA
4 0 1.0 13.0 NA 2016-08-01 11:11:00 NA
5 0 1.0 88.0 NA 2016-08-01 11:15:00 NA
discount_reason kick_back add_inprice add_info bar_code picture_file \
1 NA NA 0 NA NA caipu/202003.jpg
2 NA NA 0 NA NA caipu/303001.jpg
3 NA NA 0 NA NA caipu/105002.jpg
4 NA NA 0 NA NA caipu/503002.jpg
5 NA NA 0 NA NA caipu/204002.jpg
emp_id
1 1442
2 1442
3 1442
4 1442
5 1095
返回顶部
3.head()与tail()方法获取多行
head()、tail()方法使用的都是默认参数,所以访问的是前、后5行,只要在方法后的()中输入访问行数,即可实现目标行数数据的查看。
print('订单详情表中前5行的数据:\n',detail1.head())
print('订单详情表中后5行的数据:\n',detail1.tail())
订单详情表中前5行的数据:
detail_id order_id dishes_id logicprn_name parent_class_name dishes_name \
0 2956 417 610062 NA NA 蒜蓉生蚝
1 2958 417 609957 NA NA 蒙古烤羊腿
2 2961 417 609950 NA NA 大蒜苋菜
3 2966 417 610038 NA NA 芝麻烤紫菜
4 2968 417 610003 NA NA 蒜香包
itemis_add counts amounts cost place_order_time discount_amt \
0 0 1.0 49.0 NA 2016-08-01 11:05:00 NA
1 0 1.0 48.0 NA 2016-08-01 11:07:00 NA
2 0 1.0 30.0 NA 2016-08-01 11:07:00 NA
3 0 1.0 25.0 NA 2016-08-01 11:11:00 NA
4 0 1.0 13.0 NA 2016-08-01 11:11:00 NA
discount_reason kick_back add_inprice add_info bar_code picture_file \
0 NA NA 0 NA NA caipu/104001.jpg
1 NA NA 0 NA NA caipu/202003.jpg
2 NA NA 0 NA NA caipu/303001.jpg
3 NA NA 0 NA NA caipu/105002.jpg
4 NA NA 0 NA NA caipu/503002.jpg
emp_id
0 1442
1 1442
2 1442
3 1442
4 1442
订单详情表中后5行的数据:
detail_id order_id dishes_id logicprn_name parent_class_name dishes_name \
2774 6750 774 610011 NA NA 白饭/大碗
2775 6742 774 609996 NA NA 牛尾汤
2776 6756 774 609949 NA NA 意文柠檬汁
2777 6763 774 610014 NA NA 金玉良缘
2778 6764 774 610017 NA NA 酸辣藕丁
itemis_add counts amounts cost place_order_time discount_amt \
2774 0 1.0 10.0 NA 2016-08-10 21:56:00 NA
2775 0 1.0 40.0 NA 2016-08-10 21:56:00 NA
2776 0 1.0 13.0 NA 2016-08-10 22:01:00 NA
2777 0 1.0 30.0 NA 2016-08-10 22:03:00 NA
2778 0 1.0 33.0 NA 2016-08-10 22:04:00 NA
discount_reason kick_back add_inprice add_info bar_code \
2774 NA NA 0 NA NA
2775 NA NA 0 NA NA
2776 NA NA 0 NA NA
2777 NA NA 0 NA NA
2778 NA NA 0 NA NA
picture_file emp_id
2774 caipu/601005.jpg 1138
2775 caipu/201006.jpg 1138
2776 caipu/404005.jpg 1138
2777 caipu/302003.jpg 1138
2778 caipu/302006.jpg 1138
返回顶部
五、DataFrame中优化行列的数据获取 -loc(标签索引行) -iloc(位置获取行)
1.使用loc、iloc方法简单的切片
loc只能通过index和columns(行标签)来取,不能用数字
iloc只能用数字(行号)索引,不能用索引名
#优化行列的数据获取 -loc(标签索引行) -iloc(位置获取行)
t1 = pd.DataFrame(np.arange(12).reshape((3,4)),index=list("abc"),columns=list("WXYZ"))
print(t1)
# W X Y Z
# a 0 1 2 3
# b 4 5 6 7
# c 8 9 10 11
print(t1.loc["a","W"])
print(type(t1.loc["a","W"]))
# 0
# orderDish1 = detail1.loc[:,['order_id','dishes_name']]
print('使用loc提取order_id和dishes_name列的size为:',
orderDish1.size)
orderDish2 = detail1.iloc[:,[1,3]]
print('使用iloc提取第1和第3列的size为:', orderDish2.size)
# 代码 4-23
print('列名为order_id和dishes_name的行名为3的数据为:\n',
detail1.loc[3,['order_id','dishes_name']])
print('列名为order_id和dishes_name行名为2,3,4,5,6的数据为:\n',
detail1.loc[2:6,['order_id','dishes_name']])
print('列位置为1和3行位置为3的数据为:\n',detail1.iloc[3,[1,3]])
print('列位置为1和3行位置为2,3,4,5,6的数据为:\n',
detail1.iloc[2:7,[1,3]])

返回顶部
2.使用loc、iloc方法实现条件切片
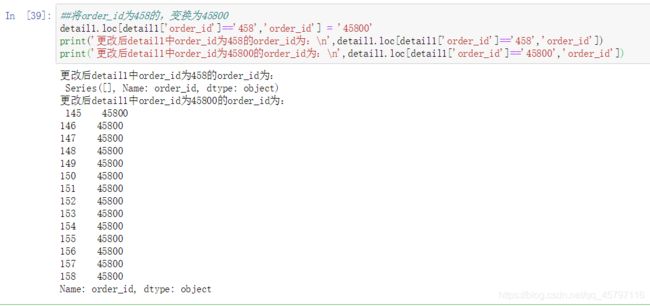
## loc内部传入表达式
print('detail1中order_id为458的dishes_name为:\n',
detail1.loc[detail1['order_id']=='458',
['order_id','dishes_name']])
#detail1中order_id为458的dishes_name为:
order_id dishes_name
145 458 蒜香辣花甲
146 458 剁椒鱼头
147 458 凉拌蒜蓉西兰花
148 458 木须豌豆
149 458 辣炒鱿鱼
150 458 酸辣藕丁
151 458 炝炒大白菜
152 458 香菇鸡肉粥
153 458 干锅田鸡
154 458 桂圆枸杞鸽子汤
155 458 五香酱驴肉
156 458 路易拉菲红酒干红
157 458 避风塘炒蟹
158 458 白饭/大碗
print('detail1中order_id为458的第1,5列数据为:\n',
detail1.iloc[detail1['order_id']=='458',[1,5]])
#NotImplementedError: iLocation based boolean indexing on an integer type is not available
# 代码 4-25
print('detail1中order_id为458的第1,5列数据为:\n',
detail1.iloc[(detail1['order_id']=='458').values,[1,5]])
#detail1中order_id为458的第1,5列数据为:
order_id dishes_name
145 458 蒜香辣花甲
146 458 剁椒鱼头
147 458 凉拌蒜蓉西兰花
148 458 木须豌豆
149 458 辣炒鱿鱼
150 458 酸辣藕丁
151 458 炝炒大白菜
152 458 香菇鸡肉粥
153 458 干锅田鸡
154 458 桂圆枸杞鸽子汤
155 458 五香酱驴肉
156 458 路易拉菲红酒干红
157 458 避风塘炒蟹
158 458 白饭/大碗
我们注意到此处的iloc方法不能够接受条件表达式,因为此处返回的是一个布尔值series,而iloc接受的数据类型不包括series,所以此处将其改为series中的值,再让iloc方法接受为True的值。
返回顶部
3.切片方法之ix
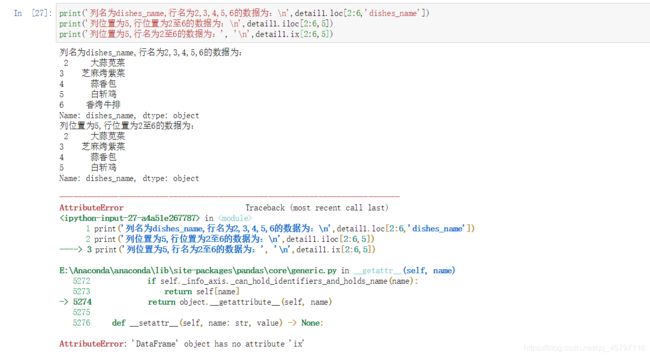
在运行DataFrame.ix时出现报错。了解到是因为在pandas的1.0.0版本开始,移除了Series.ix and DataFrame.ix 方法。代替方法使用可以使用 iloc 代替 pandas.DataFrame.iloc。

返回顶部
六、DataFrame数据增、删、改、查
增:

删:

改:
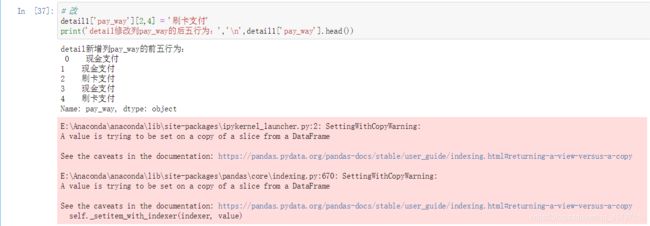
关于上面出现的Warning参见官方文档:
查:
DataFrame的查询包括了其切片处理,参见上文切片即可~
返回顶部
七、DataFrame数据的描述分析
描述性统计是用来概括、表述事物整体状况,以及事物间关联、类属关系的统计方法。通过几个统计值可以简洁地表示一组数据的集中趋势和离散程度。
1.数值型特征的描述性统计
数值型特征的描述主要包括了计算数值类型数据的完整情况、最小值、最大值、均值、中位数、四分位数、极差、方差、标准差、协方差和变异系数等等。
鉴于pandas库基于numpy,自然numpy 中的统计函数可以用来对数据进行统计。所以在进行统计的时候我们可以使用numpy函数或pandas来实现。
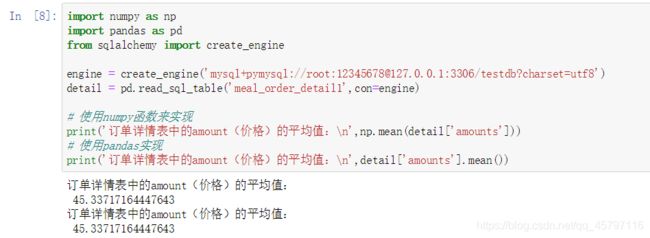
numpy中常见的数值型描述性统计函数
| 函数名称 | 说明 | 函数名称 | 说明 |
|---|---|---|---|
| np.min | 最小值 | np.max | 最大值 |
| np.mean | 均值 | np.ptp | 极差 |
| np.median | 中位数 | np.std | 标准差 |
| np.var | 方差 | np.cov | 协方差 |
pandas中常见的数值型描述性统计方法
| 方法名称 | 说明 | 方法名称 | 说明 |
|---|---|---|---|
| min | 最小值 | max | 最大值 |
| mean | 均值 | ptp | 极差 |
| median | 中位数 | std | 标准差 |
| var | 方差 | cov | 协方差 |
| sem | 标准误差 | mode | 众数 |
| skew | 样本偏度 | kurt | 样本峰度 |
| quantile | 四分位数 | count | 非空值数目 |
| describe | 描述统计 | mad | 平均绝对离差 |
这里我们着重说明一下describe方法:
该方法能够一次性得出数据框中所有数值型特种的非空值数目、均值、四分位数、标准差。比起用numpy函数逐个统计无疑要方便很多。
2.类别型特征的描述性统计
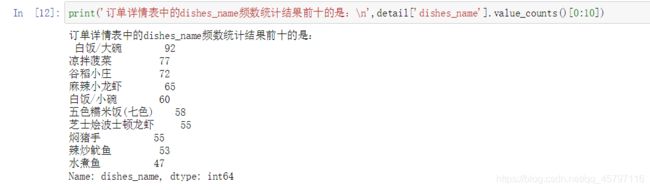
与数值型特征类似,该统计方法针对的是对于类别型特征的频数统计。实现频数统计的基本方法是value_counts().(注意此处的S不能丢!!!)
describe 方法除了支持传统数值类型的数据以外,还能够支持对category类型的数据进行描述性统计,因此我们可以将类别型特征转换为category类型来使用describe方法进行描述性统计。在此之前,我们要先了解astype方法,该方法可以将目标特征的数据类型转换为category类型。转换好了之后在使用describe方法,可以得到的四个统计量为:列非空元素的数目、类别的数目、数目最多的类别、数目最多类别的数目。
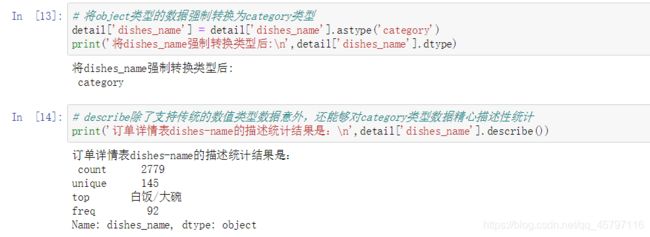
任务实现:
查看餐饮数据的大小和维度
# 查看餐饮数据大小和维度
from sqlalchemy import create_engine
import numpy as np
import pandas as pd
engine = create_engine('mysql+pymysql://root:[email protected]:3306/testdb?charset=utf8')
detail = pd.read_sql_table('meal_order_detail1',con = engine)
order = pd.read_table('data/meal_order_info.csv',sep=',',encoding='gbk')
users = pd.read_excel('data/users.xlsx')
print('订单详情表的维度是:',detail.ndim)
print('订单信息表的维度是:',order.ndim)
print('客户信息表的维度是:',users.ndim)
订单详情表的维度是: 2
订单信息表的维度是: 2
客户信息表的维度是: 2
print('订单详情表的形状是:',detail.shape)
print('订单信息表的形状是:',order.shape)
print('客户信息表的形状是:',users.shape)
订单详情表的形状是: (2779, 19)
订单信息表的形状是: (945, 21)
客户信息表的形状是: (734, 37)
print('订单详情表的元素个数是:',detail.size)
print('订单信息表的元素个数是:',order.size)
print('客户信息表的元素个数是:',users.size)
订单详情表的元素个数是: 52801
订单信息表的元素个数是: 19845
客户信息表的元素个数是: 27158
统计餐饮菜品销售情况:
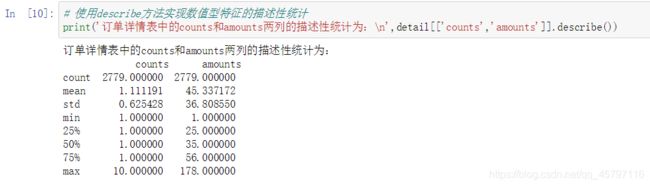
print('订单详情表counts和amounts两列的描述性统计为:\n',detail.loc[:,['counts','amounts']].describe())
print('订单详情表counts和amounts两列的描述性统计为:\n',detail[['counts','amounts']].describe())
订单详情表counts和amounts两列的描述性统计为:
counts amounts
count 2779.000000 2779.000000
mean 1.111191 45.337172
std 0.625428 36.808550
min 1.000000 1.000000
25% 1.000000 25.000000
50% 1.000000 35.000000
75% 1.000000 56.000000
max 10.000000 178.000000
订单详情表counts和amounts两列的描述性统计为:
counts amounts
count 2779.000000 2779.000000
mean 1.111191 45.337172
std 0.625428 36.808550
min 1.000000 1.000000
25% 1.000000 25.000000
50% 1.000000 35.000000
75% 1.000000 56.000000
max 10.000000 178.000000
detail['order_id'] = detail['order_id'].astype('category')
detail['dishes_name'] = detail['dishes_name'].astype('category')
print('订单信息表order_id和dishes_name的描述性统计结果为:\n',detail[['order_id','dishes_name']].describe())
订单信息表order_id和dishes_name的描述性统计结果为:
order_id dishes_name
count 2779 2779
unique 278 145
top 392 白饭/大碗
freq 24 92
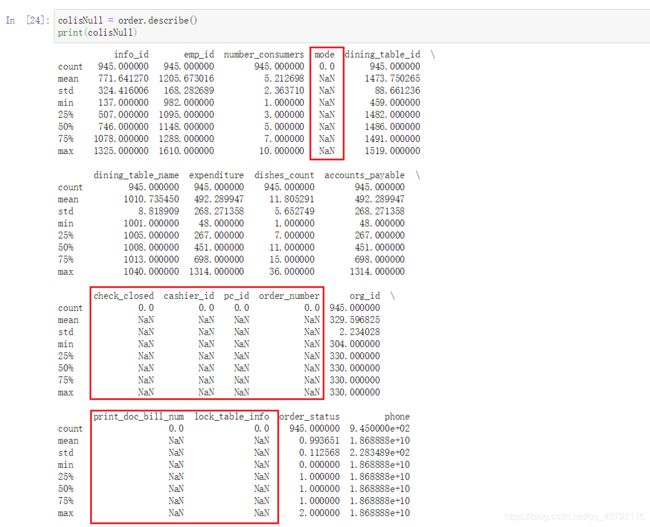
剔除全为空值的列和标准差为0的列:
这里使用Python语法构建了一个函数,关键句理解
删除前后的数据总列数:
beforelen = data.shape[1]afterlen = data.shape[1]
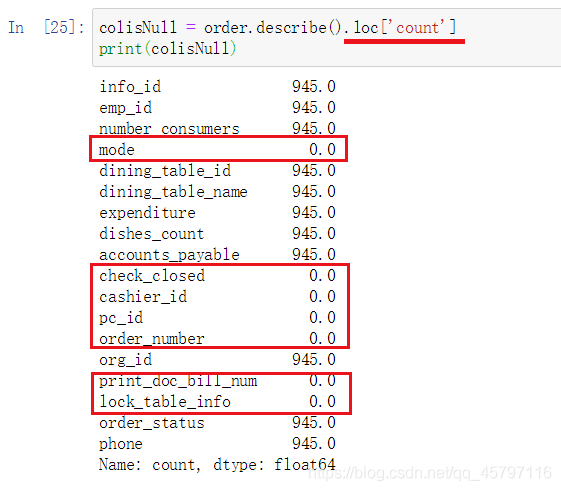
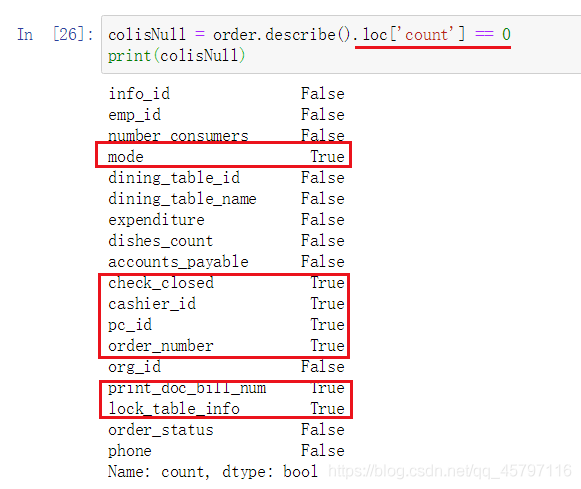
返回布尔类型指定列表:
colisNull = data.describe().loc['count'] == 0
stdisZero = data.describe().loc['std'] == 0
删除空值数据列:
data.drop(colisNull.index[i],axis=1,inplace=True)
data.drop(stdisZero.index[i],axis=1,inplace=True)
detail
# 定义一个函数剔除全为空值的列和标准差为0的列
def dropNullStd(data):
beforelen = data.shape[1]
colisNull = data.describe().loc['count'] == 0
for i in range(len(colisNull)):
if colisNull[i]:
data.drop(colisNull.index[i],axis=1,inplace=True)
stdisZero = data.describe().loc['std'] == 0
for i in range(len(stdisZero)):
if stdisZero[i]:
data.drop(stdisZero.index[i],axis=1,inplace=True)
afterlen = data.shape[1]
print(beforelen)
print(afterlen)
print('剔除列的数目为:',(beforelen-afterlen))
print('剔除后的数据形状为:',data.shape)
dropNullStd(detail)
19
19
剔除列的数目为: 0
剔除后的数据形状为: (2779, 19)

返回顶部