《R数据科学》学习笔记|Note5:使用dplyr进行数据转换(下)
点击蓝字
关注我!
写在前面
本系列为《R数据科学》(R for Data Science)的学习笔记。相较于其他R语言教程来说,本书一个很大的优势就是直接从实用的R包出发,来熟悉R及数据科学。更新过程中,读者朋友如发现错误,欢迎指正。如果有疑问,也可以在评论区留言或后台私信。希望各位读者朋友能学有所得!
BOOK
3.4
使用 select() 选择列
select() 函数对于航班数据不是特别有用,因为其中只有 19 个变量,但你还是可以通过这个数据集了解一下 select() 函数的大致用法:
1# 按名称选择列
2select(flights, year, month, day)
1# 选择“year”和“day”之间的所有列(包括“year”和“day”)
2select(flights, year:day)
1# 选择不在“year”和“day”之间的所有列(不包括“year”和“day”)
2select(flights, -(year:day))
还可以在 select () 函数中使用一些辅助函数。
• starts_with("abc") :匹配以“abc”开头的名称。
• ends_with("xyz") :匹配以“xyz”结尾的名称。
• contains("ijk") :匹配包含“ijk”的名称。
• matches("(.)\\1") :选择匹配正则表达式的那些变量。这个正则表达式会匹配名称中有重复字符的变量(后续会有正则表达式的知识)。
• num_range("x", 1:3) :匹配 x1、x2 和 x3。
使用 ?select 命令可以获取更多信息。
select() 可以重命名变量,但我们很少这样使用它,因为这样会丢掉所有未明确提及的变量。我们应该使用 select() 函数的变体 rename() 函数来重命名变量,以保留所有未明确提及的变量:
1rename(flights, tail_num = tailnum)
另一种用法是将 select() 函数和 everything() 辅助函数结合起来使用。当想要将几个变量移到数据框开头时,这种用法非常奏效:
1select(flights, time_hour, air_time, everything())
1> select(flights, time_hour, air_time, everything())
2# A tibble: 336,776 x 19
3 time_hour air_time year month day dep_time sched_dep_time
4
5 1 2013-01-01 05:00:00 227 2013 1 1 517 515
6 2 2013-01-01 05:00:00 227 2013 1 1 533 529
7 3 2013-01-01 05:00:00 160 2013 1 1 542 540
8 4 2013-01-01 05:00:00 183 2013 1 1 544 545
9 5 2013-01-01 06:00:00 116 2013 1 1 554 600
10 6 2013-01-01 05:00:00 150 2013 1 1 554 558
11 7 2013-01-01 06:00:00 158 2013 1 1 555 600
12 8 2013-01-01 06:00:00 53 2013 1 1 557 600
13 9 2013-01-01 06:00:00 140 2013 1 1 557 600
1410 2013-01-01 06:00:00 138 2013 1 1 558 600
15# ... with 336,766 more rows, and 12 more variables: dep_delay ,
16# arr_time , sched_arr_time , arr_delay , carrier ,
17# flight , tailnum , origin , dest , distance ,
18# hour , minute 3.5
使用 mutate() 添加新变量
除了选择现有的列,我们还经常需要添加新列,新列是现有列的函数。这就是 mutate() 函数的作用。
mutate() 总是将新列添加在数据集的最后,因此我们需要先创建一个更狭窄的数据集,以便能够看到新变量。当使用 RStudio 时,查看所有列的最简单的方法就是使用 View()函数:
1flights_sml <- select(flights,
2 year:day,
3 ends_with("delay"),
4 distance,
5 air_time)
6
7mutate(flights_sml,
8 gain = arr_delay - dep_delay,
9 speed = distance / air_time * 60)
1> mutate(flights_sml,
2+ gain = arr_delay - dep_delay,
3+ speed = distance / air_time * 60)
4# A tibble: 336,776 x 9
5 year month day dep_delay arr_delay distance air_time gain speed
6
7 1 2013 1 1 2 11 1400 227 9 370.
8 2 2013 1 1 4 20 1416 227 16 374.
9 3 2013 1 1 2 33 1089 160 31 408.
10 4 2013 1 1 -1 -18 1576 183 -17 517.
11 5 2013 1 1 -6 -25 762 116 -19 394.
12 6 2013 1 1 -4 12 719 150 16 288.
13 7 2013 1 1 -5 19 1065 158 24 404.
14 8 2013 1 1 -3 -14 229 53 -11 259.
15 9 2013 1 1 -3 -8 944 140 -5 405.
1610 2013 1 1 -2 8 733 138 10 319.
17# ... with 336,766 more rows
一旦创建,新列就可以立即使用:
1> mutate(flights_sml,
2+ gain = arr_delay - dep_delay,
3+ hours = air_time / 60,
4+ gain_per_hour = gain / hours)
5# A tibble: 336,776 x 10
6 year month day dep_delay arr_delay distance air_time gain hours
7
8 1 2013 1 1 2 11 1400 227 9 3.78
9 2 2013 1 1 4 20 1416 227 16 3.78
10 3 2013 1 1 2 33 1089 160 31 2.67
11 4 2013 1 1 -1 -18 1576 183 -17 3.05
12 5 2013 1 1 -6 -25 762 116 -19 1.93
13 6 2013 1 1 -4 12 719 150 16 2.5
14 7 2013 1 1 -5 19 1065 158 24 2.63
15 8 2013 1 1 -3 -14 229 53 -11 0.883
16 9 2013 1 1 -3 -8 944 140 -5 2.33
1710 2013 1 1 -2 8 733 138 10 2.3
18# ... with 336,766 more rows, and 1 more variable: gain_per_hour
如果只想保留新变量,可以使用 transmute() 函数:
1> transmute(flights,
2+ gain = arr_delay - dep_delay,
3+ hours = air_time / 60,
4+ gain_per_hour = gain / hours)
5# A tibble: 336,776 x 3
6 gain hours gain_per_hour
7
8 1 9 3.78 2.38
9 2 16 3.78 4.23
10 3 31 2.67 11.6
11 4 -17 3.05 -5.57
12 5 -19 1.93 -9.83
13 6 16 2.5 6.4
14 7 24 2.63 9.11
15 8 -11 0.883 -12.5
16 9 -5 2.33 -2.14
1710 10 2.3 4.35
18# ... with 336,766 more rows 3.5.1
常用创建函数
创建新变量的多种函数可供你同 mutate() 一同使用。最重要的一点是,这种函数必须是向量化的:它必须接受一个向量作为输入,并返回一个向量作为输出,而且输入向量与输出向量具有同样数目的分量。下面是比较常用的函数。
算术运算符:+、-、*、/、^
模运算符:%/% 和 %%
%/%(整数除法)和 %%(求余)满足 x == y * (x %/% y) + (x %% y)。模运算可以拆分整数。例如,在航班数据集中,你可以根据 dep_time 计算出 hour 和 minute:
1> transmute(flights,
2+ dep_time,
3+ hour = dep_time %/% 100,
4+ minute = dep_time %% 100)
5# A tibble: 336,776 x 3
6 dep_time hour minute
7
8 1 517 5 17
9 2 533 5 33
10 3 542 5 42
11 4 544 5 44
12 5 554 5 54
13 6 554 5 54
14 7 555 5 55
15 8 557 5 57
16 9 557 5 57
1710 558 5 58
18# ... with 336,766 more rows
对数函数:log()、log2() 和 log10()
偏移函数
lead() 和 lag() 函数可以返回一个序列的领先值和滞后值。它们可以计算出序列的移动差值(如 x – lag(x))或发现序列何时发生了变化(x != lag(x))。
1> (x <- 1:10)
2 [1] 1 2 3 4 5 6 7 8 9 10
3> lag(x)
4 [1] NA 1 2 3 4 5 6 7 8 9
5> lead(x)
6 [1] 2 3 4 5 6 7 8 9 10 NA
累加和滚动聚合
R 提供了计算累加和、累加积、累加最小值和累加最大值的函数:cumsum()、cumprod()、commin() 和 cummax();dplyr 还提供了 cummean() 函数以计算累加均值。如果想要计算滚动聚合(即滚动窗口求和),那么可以尝试使用 RcppRoll 包:
1> x
2 [1] 1 2 3 4 5 6 7 8 9 10
3> cumsum(x)
4 [1] 1 3 6 10 15 21 28 36 45 55
5> cummean(x)
6 [1] 1.0 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 5.5
逻辑比较:<、<=、>、>= 和 !=
排秩
排秩函数有很多,最常用的是min_rank()函数。它可以完成最常用的排秩任务 (如第一、第二、第三、第四)。默认的排秩方式是,最小的值获得最前面的名次,使用desc(x) 可以让最大的值获得最前面的名次:
1> y <- c(1, 2, 2, NA, 3, 4)
2> min_rank(y)
3[1] 1 2 2 NA 4 5
4> min_rank(desc(y))
5[1] 5 3 3 NA 2 1
如果 min_rank() 无法满足需要,那么可以看一下其变体row_number()、dense_rank()、percent_rank()、cume_dist() 和 ntile()。可以查看它们的帮助页面以获得更多信息
1> row_number(y)
2[1] 1 2 3 NA 4 5
3> dense_rank(y)
4[1] 1 2 2 NA 3 4
5> percent_rank(y)
6[1] 0.00 0.25 0.25 NA 0.75 1.00
7> cume_dist(y)
8[1] 0.2 0.6 0.6 NA 0.8 1.03.6
使用 summarize() 进行分组摘要
最后一个核心函数是 summarize(),它可以将数据框折叠成一行:
1> summarize(flights, delay = mean(dep_delay, na.rm = TRUE))
2# A tibble: 1 x 1
3 delay
4
51 12.6
group_by() 可以将分析单位从整个数据集更改为单个分组。接下来,在分组后的数据框上使用 dplyr 函数时, 它们会自动地应用到每个分组。例如,如果对按日期分组的一个数据框应用与上面完全相同的代码,那么我们就可以得到每日平均延误时间:
1> by_day <- group_by(flights, year, month, day)
2> summarize(by_day, delay = mean(dep_delay, na.rm = TRUE))
3`summarise()` regrouping output by 'year', 'month' (override with `.groups` argument)
4# A tibble: 365 x 4
5# Groups: year, month [12]
6 year month day delay
7
8 1 2013 1 1 11.5
9 2 2013 1 2 13.9
10 3 2013 1 3 11.0
11 4 2013 1 4 8.95
12 5 2013 1 5 5.73
13 6 2013 1 6 7.15
14 7 2013 1 7 5.42
15 8 2013 1 8 2.55
16 9 2013 1 9 2.28
1710 2013 1 10 2.84
18# ... with 355 more rows
group_by() 和 summarize() 的组合构成了使用 dplyr 包时最常用的操作之一:分组摘要。
3.6.1
使用管道组合多种操作
例子:每个目的地的距离和平均延误时间之间的关系。
1by_dest <- group_by(flights, dest) #按照目的地对航班进行分组
2delay <- summarize(by_dest,
3 count = n(),
4 dist = mean(distance, na.rm = TRUE),
5 delay = mean(arr_delay, na.rm = TRUE)
6) # 进行摘要统计,计算距离、平均延误时间和航班数量。
7
8delay <- filter(delay, count > 20, dest != "HNL")
9#通过筛选除去噪声点和火奴鲁鲁机场,因为到达该机场的距离几乎是到离它最近机场的
10#距离的 2 倍。
11ggplot(data = delay, mapping = aes(x = dist, y = delay)) +
12 geom_point(aes(size = count), alpha = 1/3) +
13 geom_smooth(se = FALSE) #画图并添加曲线
使用管道,%>%,可以使代码更加简洁:
1delays <- flights %>%
2 group_by(dest) %>%
3 summarize(
4 count = n(),
5 dist = mean(distance, na.rm = TRUE),
6 delay = mean(arr_delay, na.rm = TRUE)
7) %>%
8filter(count > 20, dest != "HNL")
你可以将其读作一串命令式语句:分组,然后摘要统计,然后进行筛选。在阅读代码时,%>% 最好读作“然后”。
使用这种方法时,x %>% f(y) 会转换为 f(x, y),x %>% f(y) %>% g(z) 会转换为 g(f(x, y), z),以此类推。
3.6.2
缺失值
我们在前面使用了参数 na.rm 。如果没有设置这个参数,会发生什么情况呢?
1> flights %>%
2+ group_by(year, month, day) %>%
3+ summarize(mean = mean(dep_delay))
4`summarise()` regrouping output by 'year', 'month' (override with `.groups` argument)
5# A tibble: 365 x 4
6# Groups: year, month [12]
7 year month day mean
8
9 1 2013 1 1 NA
10 2 2013 1 2 NA
11 3 2013 1 3 NA
12 4 2013 1 4 NA
13 5 2013 1 5 NA
14 6 2013 1 6 NA
15 7 2013 1 7 NA
16 8 2013 1 8 NA
17 9 2013 1 9 NA
1810 2013 1 10 NA
19# ... with 355 more rows
我们会得到很多缺失值!这是因为聚合函数遵循缺失值的一般规则:如果输入中有缺失值,那么输出也会是缺失值。好在所有聚合函数都有一个 na.rm 参数,它可以在计算前除去缺失值。
1> flights %>%
2+ group_by(year, month, day) %>%
3+ summarize(mean = mean(dep_delay, na.rm = TRUE))
4`summarise()` regrouping output by 'year', 'month' (override with `.groups` argument)
5# A tibble: 365 x 4
6# Groups: year, month [12]
7 year month day mean
8
9 1 2013 1 1 11.5
10 2 2013 1 2 13.9
11 3 2013 1 3 11.0
12 4 2013 1 4 8.95
13 5 2013 1 5 5.73
14 6 2013 1 6 7.15
15 7 2013 1 7 5.42
16 8 2013 1 8 2.55
17 9 2013 1 9 2.28
1810 2013 1 10 2.84
19# ... with 355 more rows
当然,我们也可以通过先去除缺失值(本例为取消的航班)来解决缺失值问题。
1not_cancelled <- flights %>%
2 filter(!is.na(dep_delay), !is.na(arr_delay))
3.6.3
计数
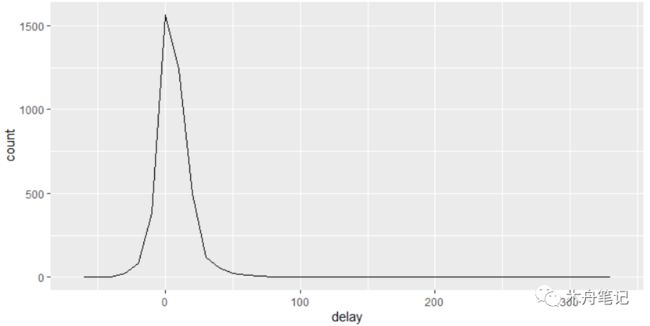
聚合操作中包括一个计数(n())或非缺失值的计数(sum(!is_na()))可以确保自己没有基于非常少量的数据作出结论。例如,我们查看一下具有最长平均延误时间的飞机(通过机尾编号进行识别):
1delays <- not_cancelled %>% #去掉NA的数据
2 group_by(tailnum) %>%
3 summarize(
4 delay = mean(arr_delay)
5 )
6delays
7
8ggplot(data = delays, mapping = aes(x = delay)) +
9 geom_freqpoly(binwidth = 10)
我们可以画一张航班数量和平均延误时间的散点图:
1delays <- not_cancelled %>%
2 group_by(tailnum) %>%
3 summarize(
4 delay = mean(arr_delay, na.rm = TRUE),
5 n = n()
6 )
7ggplot(data = delays, mapping = aes(x = n, y = delay)) +
8 geom_point(alpha = 1/10)
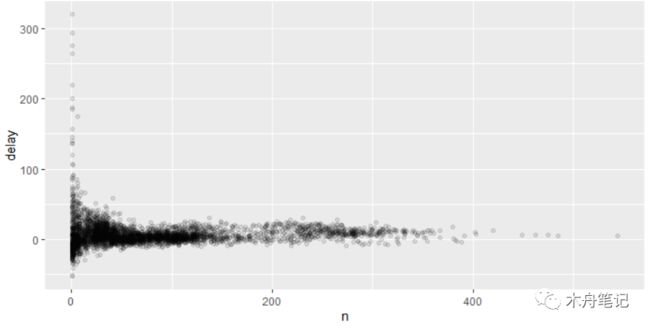
结果并不出乎意料,当航班数量非常少时,平均延误时间的变动特别大。这张图的形状非常能够说明问题:当绘制均值(或其他摘要统计量)和分组规模的关系时,你总能看到随着样本量的增加,变动在不断减小。
3.6.4
常用的摘要函数
只使用均值、计数和求和是远远不够的,R 中还提供了很多其他的常用的摘要函数。
位置度量: mean(x),median(x)
分散程度度量:sd(x)、IQR(x) 和 mad(x)
均方误差(又称标准误差,standard deviation,sd)是分散程度的标准度量方式。四分位距 IQR() 和绝对中位差 mad(x) 基本等价,更适合有离群点的情况。
1# 为什么到某些目的地的距离比到其他目的地更多变?
2not_cancelled %>%
3 group_by(dest) %>%
4 summarize(distance_sd = sd(distance)) %>%
5 arrange(desc(distance_sd))
6
7> not_cancelled %>%
8+ group_by(dest) %>%
9+ summarize(distance_sd = sd(distance)) %>%
10+ arrange(desc(distance_sd))
11`summarise()` ungrouping output (override with `.groups` argument)
12# A tibble: 104 x 2
13 dest distance_sd
14
15 1 EGE 10.5
16 2 SAN 10.4
17 3 SFO 10.2
18 4 HNL 10.0
19 5 SEA 9.98
20 6 LAS 9.91
21 7 PDX 9.87
22 8 PHX 9.86
23 9 LAX 9.66
2410 IND 9.46
25# ... with 94 more rows
秩的度量:min(x)、quantile(x, 0.25) 和 max(x)
分位数是中位数的扩展。例如,quantile(x, 0.25) 会找出 x 中按从小到大顺序大于前 25% 而小于后 75% 的值
定位度量:first(x)、nth(x, 2) 和 last(x)
计数:
n() ,它不需要任何参数,并返回当前分组的大小。如果想要计算出非缺失值的数量,可以使用 sum(!is.na(x))。要想计算出唯一值的数量,可以使用 n_ distinct(x):
1# 哪个目的地具有最多的航空公司?
2not_cancelled %>%
3 group_by(dest) %>%
4 summarize(carriers = n_distinct(carrier)) %>%
5 arrange(desc(carriers))
dplyr 提供了一个简单的辅助函数,用于只需要计数的情况:
1not_cancelled %>%
2 count(dest)还可以选择提供一个加权变量。例如,你可以使用以下代码算出每 架 飞 机飞行的总里程数(实际上就是求和):
1not_cancelled %>%
2 count(tailnum, wt = distance)
逻辑值的计数和比例:sum(x > 10) 和 mean(y == 0)
1# 多少架航班是在早上5点前出发的?(这通常表明前一天延误的航班数量)
2not_cancelled %>%
3 group_by(year, month, day) %>%
4 summarize(n_early = sum(dep_time < 500))
5
6# 延误超过1小时的航班比例是多少?
7not_cancelled %>%
8 group_by(year, month, day) %>%
9 summarize(hour_perc = mean(arr_delay > 60))3.6.5
按多个变量分组
当使用多个变量进行分组时,每次的摘要统计会用掉一个分组变量。这样就可以轻松地对数据集进行循序渐进的分析:
1daily <- group_by(flights, year, month, day)
2(per_day <- summarize(daily, flights = n()))
3
4(per_month <- summarize(per_day, flights = sum(flights)))
5
6(per_year <- summarize(per_month, flights = sum(flights)))
在循序渐进地进行摘要分析时,需要小心:使用求和与计数操作是没问题的,但如果想要使用加权平均和方差的话,就要仔细考虑一下,在基于秩的统计数据(如中位数)上是无法进行这些操作的。换句话说,对分组求和的结果再求和就是对整体求和,但分组中位数的中位数可不是整体的中位数。
3.6.6
取消分组
如果想要取消分组,并回到未分组的数据继续操作,那么可以使用 ungroup() 函数:
1daily %>%
2 ungroup() %>% # 不再按日期分组
3 summarize(flights = n()) # 所有航班3.7
分组新变量(和筛选器)
虽然与 summarize() 函数结合起来使用是最有效的,但分组也可以与 mutate() 和 filter()函数结合,以完成非常便捷的操作。
找出每个分组中最差的成员:
1flights_sml %>%
2 group_by(year, month, day) %>%
3 filter(rank(desc(arr_delay)) < 10)
找出大于某个阈值的所有分组:
1popular_dests <- flights %>%
2 group_by(dest) %>%
3 filter(n() > 365)
对数据进行标准化以计算分组指标:
1popular_dests %>%
2 filter(arr_delay > 0) %>%
3 mutate(prop_delay = arr_delay / sum(arr_delay)) %>%
4 select(year:day, dest, arr_delay, prop_delay)— END —
往期 · 推荐
《R数据科学》学习笔记|Note1:绪论
《R数据科学》学习笔记|Note2:使用ggplot2进行数据可视化(上)
《R数据科学》学习笔记|Note3:使用ggplot2进行数据可视化(下)
《R数据科学》学习笔记|Note4:使用dplyr进行数据转换(上)
零基础"机器学习"自学笔记|Note5:多变量线性回归
零基础"机器学习"自学笔记|Note6:正规方程及其推导(内附详细推导过程)
零基础"机器学习"自学笔记|Note6:正规方程及其推导(内附详细推导过程)

欢迎关注 木舟笔记