【二】MADDPG多智能体算法实现(parl)【追逐游戏复现】
相关文章:
【一】MADDPG-单智能体|多智能体总结(理论、算法)
【二】MADDPG多智能体深度强化学习算法算法实现(parl)--【追逐游戏复现】
【一】-环境配置+python入门教学
【二】-Parl基础命令
【三】-Notebook、&pdb、ipdb 调试
【四】-强化学习入门简介
【五】-Sarsa&Qlearing详细讲解
【六】-DQN
【七】-Policy Gradient
【八】-DDPG
【九】-四轴飞行器仿真
飞桨PARL_2.0&1.8.5(遇到bug调试修正)
1.论文全称:Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments
论文原文:https://download.csdn.net/download/sinat_39620217/16203960
论文翻译:https://blog.csdn.net/qiusuoxiaozi/article/details/79066612

具体原理见:【一】MADDPG-单智能体|多智能体总结(理论、算法)
1.1 OpenAI 的捉迷藏环境
很有意思的OpenAI的捉迷藏环境,主要讲的是两队开心的小朋友agents在玩捉迷藏游戏中经过训练逐渐学到的各种策略:


视频链接:https://www.bilibili.com/video/bv1ZA411N7jg 大家可以看看效果挺有趣的
这个环境是基于mujoco的, mujoco是付费的,这里有一个简化版的类似捉迷藏的环境,也是OpenAI的.
1.2 OpenAI的小球版“追逐游戏”环境
代码源:https://gitee.com/dingding962285595/gitee_work_python


里面一共有9个多智能体环境,
simple、simple_adversary、simple_crypto、simple_push、simple_reference、simple_speaker_listener、simple_spread、simple_tag、simple_world_comm
这里以simple_world_comm这个环境为例:

环境中有6个智能体,其中两个绿色小球速度快,他们要去蓝色小球(水源)那里获得reward;而另外四个红色小球速度较慢,他们要追逐绿色小球以此来获得reward。
- 剩下的两个绿色大球是森林,绿色小球进入森林时,红色小球就无法获取绿色小球的位置;
- 黑色小球是障碍物,小球都无法通过;
- 两个蓝色小球是水源,绿色小球可以通过靠近水源的方式获取reward。
这个环境中,只有智能体可以移动,每个episode结束后,环境会随机改变。
这是一个合作与竞争的环境,绿色小球和红色小球都要学会和队友合作,于此同时,绿色小球和红色小球之间存在竞争的关系。
下面给出官网每个文件解释我就不一一翻译了。
1.2.1 代码架构
make_env.py: contains code for importing a multiagent environment as an OpenAI Gym-like object.
./multiagent/environment.py: contains code for environment simulation (interaction physics, _step() function, etc.)
./multiagent/core.py: contains classes for various objects (Entities, Landmarks, Agents, etc.) that are used throughout the code.
./multiagent/rendering.py: used for displaying agent behaviors on the screen.
./multiagent/policy.py: contains code for interactive policy based on keyboard input.
./multiagent/scenario.py: contains base scenario object that is extended for all scenarios.
./multiagent/scenarios/: folder where various scenarios/ environments are stored. scenario code consists of several functions:
make_world(): creates all of the entities that inhabit the world (landmarks, agents, etc.), assigns their capabilities (whether they can communicate, or move, or both). called once at the beginning of each training session
reset_world(): resets the world by assigning properties (position, color, etc.) to all entities in the world called before every episode (including after make_world() before the first episode)
reward(): defines the reward function for a given agent
observation(): defines the observation space of a given agent(optional) benchmark_data(): provides diagnostic data for policies trained on the environment (e.g. evaluation metrics)1.2.2 环境列表
| Env name in code (name in paper) | Communication? | Competitive? | Notes |
|---|---|---|---|
simple.py |
N | N | Single agent sees landmark position, rewarded based on how close it gets to landmark. Not a multiagent environment -- used for debugging policies. |
simple_adversary.py (Physical deception) |
N | Y | 1 adversary (red), N good agents (green), N landmarks (usually N=2). All agents observe position of landmarks and other agents. One landmark is the ‘target landmark’ (colored green). Good agents rewarded based on how close one of them is to the target landmark, but negatively rewarded if the adversary is close to target landmark. Adversary is rewarded based on how close it is to the target, but it doesn’t know which landmark is the target landmark. So good agents have to learn to ‘split up’ and cover all landmarks to deceive the adversary. |
simple_crypto.py (Covert communication) |
Y | Y | Two good agents (alice and bob), one adversary (eve). Alice must sent a private message to bob over a public channel. Alice and bob are rewarded based on how well bob reconstructs the message, but negatively rewarded if eve can reconstruct the message. Alice and bob have a private key (randomly generated at beginning of each episode), which they must learn to use to encrypt the message. |
simple_push.py (Keep-away) |
N | Y | 1 agent, 1 adversary, 1 landmark. Agent is rewarded based on distance to landmark. Adversary is rewarded if it is close to the landmark, and if the agent is far from the landmark. So the adversary learns to push agent away from the landmark. |
simple_reference.py |
Y | N | 2 agents, 3 landmarks of different colors. Each agent wants to get to their target landmark, which is known only by other agent. Reward is collective. So agents have to learn to communicate the goal of the other agent, and navigate to their landmark. This is the same as the simple_speaker_listener scenario where both agents are simultaneous speakers and listeners. |
simple_speaker_listener.py (Cooperative communication) |
Y | N | Same as simple_reference, except one agent is the ‘speaker’ (gray) that does not move (observes goal of other agent), and other agent is the listener (cannot speak, but must navigate to correct landmark). |
simple_spread.py (Cooperative navigation) |
N | N | N agents, N landmarks. Agents are rewarded based on how far any agent is from each landmark. Agents are penalized if they collide with other agents. So, agents have to learn to cover all the landmarks while avoiding collisions. |
simple_tag.py (Predator-prey) |
N | Y | Predator-prey environment. Good agents (green) are faster and want to avoid being hit by adversaries (red). Adversaries are slower and want to hit good agents. Obstacles (large black circles) block the way. |
simple_world_comm.py |
Y | Y | Environment seen in the video accompanying the paper. Same as simple_tag, except (1) there is food (small blue balls) that the good agents are rewarded for being near, (2) we now have ‘forests’ that hide agents inside from being seen from outside; (3) there is a ‘leader adversary” that can see the agents at all times, and can communicate with the other adversaries to help coordinate the chase. |
1.3 MADDPG码源
环境代码源:https://github.com/dingidng/multiagent-particle-envs
所有程序码源:https://gitee.com/dingding962285595/myenv/tree/master/gym/multiagent 上述两个链接都有完整程序!
1.3.1 智能体部分:(agent.py)
- 每个Actor都单独地与环境交互,即采样的过程是独立的
- 每个Actor都有一个可以观测全局的Critir,从而指导Actor做动作
import numpy as np import parl from parl import layers from paddle import fluid from parl.utils import ReplayMemory from parl.utils import machine_info, get_gpu_count class MAAgent(parl.Agent): def __init__(self, algorithm, agent_index=None, obs_dim_n=None, act_dim_n=None, batch_size=None, speedup=False): assert isinstance(agent_index, int) assert isinstance(obs_dim_n, list) assert isinstance(act_dim_n, list) assert isinstance(batch_size, int) assert isinstance(speedup, bool) self.agent_index = agent_index self.obs_dim_n = obs_dim_n self.act_dim_n = act_dim_n self.batch_size = batch_size self.speedup = speedup self.n = len(act_dim_n) self.memory_size = int(1e6) self.min_memory_size = batch_size * 25 # batch_size * args.max_episode_len self.rpm = ReplayMemory( max_size=self.memory_size, obs_dim=self.obs_dim_n[agent_index], act_dim=self.act_dim_n[agent_index]) self.global_train_step = 0 if machine_info.is_gpu_available(): assert get_gpu_count() == 1, 'Only support training in single GPU,\ Please set environment variable: `export CUDA_VISIBLE_DEVICES=[GPU_ID_TO_USE]` .' super(MAAgent, self).__init__(algorithm) # Attention: In the beginning, sync target model totally. self.alg.sync_target(decay=0) def build_program(self): self.pred_program = fluid.Program() self.learn_program = fluid.Program() self.next_q_program = fluid.Program() self.next_a_program = fluid.Program() with fluid.program_guard(self.pred_program): obs = layers.data( name='obs', shape=[self.obs_dim_n[self.agent_index]], dtype='float32') self.pred_act = self.alg.predict(obs) with fluid.program_guard(self.learn_program): obs_n = [ layers.data( name='obs' + str(i), shape=[self.obs_dim_n[i]], dtype='float32') for i in range(self.n) ] act_n = [ layers.data( name='act' + str(i), shape=[self.act_dim_n[i]], dtype='float32') for i in range(self.n) ] target_q = layers.data(name='target_q', shape=[], dtype='float32') self.critic_cost = self.alg.learn(obs_n, act_n, target_q) with fluid.program_guard(self.next_q_program): obs_n = [ layers.data( name='obs' + str(i), shape=[self.obs_dim_n[i]], dtype='float32') for i in range(self.n) ] act_n = [ layers.data( name='act' + str(i), shape=[self.act_dim_n[i]], dtype='float32') for i in range(self.n) ] self.next_Q = self.alg.Q_next(obs_n, act_n) with fluid.program_guard(self.next_a_program): obs = layers.data( name='obs', shape=[self.obs_dim_n[self.agent_index]], dtype='float32') self.next_action = self.alg.predict_next(obs) if self.speedup: self.pred_program = parl.compile(self.pred_program) self.learn_program = parl.compile(self.learn_program, self.critic_cost) self.next_q_program = parl.compile(self.next_q_program) self.next_a_program = parl.compile(self.next_a_program) def predict(self, obs): obs = np.expand_dims(obs, axis=0) obs = obs.astype('float32') act = self.fluid_executor.run( self.pred_program, feed={'obs': obs}, fetch_list=[self.pred_act])[0] return act[0] def learn(self, agents): self.global_train_step += 1 # only update parameter every 100 steps if self.global_train_step % 100 != 0: return 0.0 if self.rpm.size() <= self.min_memory_size: return 0.0 batch_obs_n = [] batch_act_n = [] batch_obs_new_n = [] rpm_sample_index = self.rpm.make_index(self.batch_size) for i in range(self.n): batch_obs, batch_act, _, batch_obs_new, _ \ = agents[i].rpm.sample_batch_by_index(rpm_sample_index) batch_obs_n.append(batch_obs) batch_act_n.append(batch_act) batch_obs_new_n.append(batch_obs_new) _, _, batch_rew, _, batch_isOver \ = self.rpm.sample_batch_by_index(rpm_sample_index) # compute target q target_q = 0.0 target_act_next_n = [] for i in range(self.n): feed = {'obs': batch_obs_new_n[i]} target_act_next = agents[i].fluid_executor.run( agents[i].next_a_program, feed=feed, fetch_list=[agents[i].next_action])[0] target_act_next_n.append(target_act_next) feed_obs = {'obs' + str(i): batch_obs_new_n[i] for i in range(self.n)} feed_act = { 'act' + str(i): target_act_next_n[i] for i in range(self.n) } feed = feed_obs.copy() feed.update(feed_act) # merge two dict target_q_next = self.fluid_executor.run( self.next_q_program, feed=feed, fetch_list=[self.next_Q])[0] target_q += ( batch_rew + self.alg.gamma * (1.0 - batch_isOver) * target_q_next) feed_obs = {'obs' + str(i): batch_obs_n[i] for i in range(self.n)} feed_act = {'act' + str(i): batch_act_n[i] for i in range(self.n)} target_q = target_q.astype('float32') feed = feed_obs.copy() feed.update(feed_act) feed['target_q'] = target_q critic_cost = self.fluid_executor.run( self.learn_program, feed=feed, fetch_list=[self.critic_cost])[0] self.alg.sync_target() return critic_cost def add_experience(self, obs, act, reward, next_obs, terminal): self.rpm.append(obs, act, reward, next_obs, terminal)
1.3.2 网络部分(model.py)
Actor和Critir相当于神经网络,采用的都是三层全连接层
这一部分可以不做修改,有能力的同学可以尝试对这一部分进行调优
import paddle.fluid as fluid import parl from parl import layers class MAModel(parl.Model): def __init__(self, act_dim): self.actor_model = ActorModel(act_dim) self.critic_model = CriticModel() def policy(self, obs): return self.actor_model.policy(obs) def value(self, obs, act): return self.critic_model.value(obs, act) def get_actor_params(self): return self.actor_model.parameters() def get_critic_params(self): return self.critic_model.parameters() class ActorModel(parl.Model): def __init__(self, act_dim): hid1_size = 64 hid2_size = 64 self.fc1 = layers.fc( size=hid1_size, act='relu', param_attr=fluid.initializer.Normal(loc=0.0, scale=0.1)) self.fc2 = layers.fc( size=hid2_size, act='relu', param_attr=fluid.initializer.Normal(loc=0.0, scale=0.1)) self.fc3 = layers.fc( size=act_dim, act=None, param_attr=fluid.initializer.Normal(loc=0.0, scale=0.1)) def policy(self, obs): hid1 = self.fc1(obs) hid2 = self.fc2(hid1) means = self.fc3(hid2) means = means return means class CriticModel(parl.Model): def __init__(self): hid1_size = 64 hid2_size = 64 self.fc1 = layers.fc( size=hid1_size, act='relu', param_attr=fluid.initializer.Normal(loc=0.0, scale=0.1)) self.fc2 = layers.fc( size=hid2_size, act='relu', param_attr=fluid.initializer.Normal(loc=0.0, scale=0.1)) self.fc3 = layers.fc( size=1, act=None, param_attr=fluid.initializer.Normal(loc=0.0, scale=0.1)) def value(self, obs_n, act_n): inputs = layers.concat(obs_n + act_n, axis=1) hid1 = self.fc1(inputs) hid2 = self.fc2(hid1) Q = self.fc3(hid2) Q = layers.squeeze(Q, axes=[1]) return Q
1.3.3 训练代码:(train.py)
#import sys #print(sys.path) #sys.path.append("H:/Anaconda3-2020.02/envs/parl/Lib/site-packages/parl/env") #sys.path.append("H:\Anaconda3-202002\envs\parl\Lib\site-packages\gym\envs\multiagent") import os import time import argparse import numpy as np from simple_model import MAModel from simple_agent import MAAgent import parl from gym.envs.multiagent.multiagent_simple_env import MAenv from parl.utils import logger, summary def run_episode(env, agents): obs_n = env.reset() total_reward = 0 agents_reward = [0 for _ in range(env.n)] steps = 0 while True: steps += 1 action_n = [agent.predict(obs) for agent, obs in zip(agents, obs_n)] next_obs_n, reward_n, done_n, _ = env.step(action_n) done = all(done_n) terminal = (steps >= args.max_step_per_episode) # store experience for i, agent in enumerate(agents): agent.add_experience(obs_n[i], action_n[i], reward_n[i], next_obs_n[i], done_n[i]) # compute reward of every agent obs_n = next_obs_n for i, reward in enumerate(reward_n): total_reward += reward agents_reward[i] += reward # check the end of an episode if done or terminal: break # show animation if args.show: time.sleep(0.1) env.render() # show model effect without training if args.restore and args.show: continue # learn policy for i, agent in enumerate(agents): critic_loss = agent.learn(agents) summary.add_scalar('critic_loss_%d' % i, critic_loss, agent.global_train_step) return total_reward, agents_reward, steps def train_agent(): env = MAenv(args.env) logger.info('agent num: {}'.format(env.n)) logger.info('observation_space: {}'.format(env.observation_space)) logger.info('action_space: {}'.format(env.action_space)) logger.info('obs_shape_n: {}'.format(env.obs_shape_n)) logger.info('act_shape_n: {}'.format(env.act_shape_n)) for i in range(env.n): logger.info('agent {} obs_low:{} obs_high:{}'.format( i, env.observation_space[i].low, env.observation_space[i].high)) logger.info('agent {} act_n:{}'.format(i, env.act_shape_n[i])) if ('low' in dir(env.action_space[i])): logger.info('agent {} act_low:{} act_high:{} act_shape:{}'.format( i, env.action_space[i].low, env.action_space[i].high, env.action_space[i].shape)) logger.info('num_discrete_space:{}'.format( env.action_space[i].num_discrete_space)) from gym import spaces from gym.envs.multiagent.multi_discrete import MultiDiscrete for space in env.action_space: assert (isinstance(space, spaces.Discrete) or isinstance(space, MultiDiscrete)) agents = [] for i in range(env.n): model = MAModel(env.act_shape_n[i]) algorithm = parl.algorithms.MADDPG( model, agent_index=i, act_space=env.action_space, gamma=args.gamma, tau=args.tau, critic_lr=args.critic_lr, actor_lr=args.actor_lr) agent = MAAgent( algorithm, agent_index=i, obs_dim_n=env.obs_shape_n, act_dim_n=env.act_shape_n, batch_size=args.batch_size, speedup=(not args.restore)) agents.append(agent) total_steps = 0 total_episodes = 0 episode_rewards = [] # sum of rewards for all agents agent_rewards = [[] for _ in range(env.n)] # individual agent reward final_ep_rewards = [] # sum of rewards for training curve final_ep_ag_rewards = [] # agent rewards for training curve if args.restore: # restore modle for i in range(len(agents)): model_file = args.model_dir + '/agent_' + str(i) + '.ckpt' if not os.path.exists(model_file): logger.info('model file {} does not exits'.format(model_file)) raise Exception agents[i].restore(model_file) t_start = time.time() logger.info('Starting...') while total_episodes <= args.max_episodes: # run an episode ep_reward, ep_agent_rewards, steps = run_episode(env, agents) if args.show: print('episode {}, reward {}, steps {}'.format( total_episodes, ep_reward, steps)) # Record reward total_steps += steps total_episodes += 1 episode_rewards.append(ep_reward) for i in range(env.n): agent_rewards[i].append(ep_agent_rewards[i]) # Keep track of final episode reward if total_episodes % args.stat_rate == 0: mean_episode_reward = np.mean(episode_rewards[-args.stat_rate:]) final_ep_rewards.append(mean_episode_reward) for rew in agent_rewards: final_ep_ag_rewards.append(np.mean(rew[-args.stat_rate:])) use_time = round(time.time() - t_start, 3) logger.info( 'Steps: {}, Episodes: {}, Mean episode reward: {}, Time: {}'. format(total_steps, total_episodes, mean_episode_reward, use_time)) t_start = time.time() summary.add_scalar('mean_episode_reward/episode', mean_episode_reward, total_episodes) summary.add_scalar('mean_episode_reward/steps', mean_episode_reward, total_steps) summary.add_scalar('use_time/1000episode', use_time, total_episodes) # save model if not args.restore: os.makedirs(os.path.dirname(args.model_dir), exist_ok=True) for i in range(len(agents)): model_name = '/agent_' + str(i) agents[i].save(args.model_dir + model_name) if __name__ == '__main__': parser = argparse.ArgumentParser() # Environment parser.add_argument( '--env', type=str, default='simple_spread', help='scenario of MultiAgentEnv') parser.add_argument( '--max_step_per_episode', type=int, default=50, help='maximum step per episode') parser.add_argument( '--max_episodes', type=int, default=25000, help='stop condition:number of episodes') parser.add_argument( '--stat_rate', type=int, default=500, #第1000episodes保存一下,并显示reward值。 help='statistical interval of save model or count reward') # Core training parameters parser.add_argument( '--critic_lr', type=float, default=1e-3, help='learning rate for the critic model') parser.add_argument( '--actor_lr', type=float, default=1e-3, ##修改 default值可修改学习率 help='learning rate of the actor model') parser.add_argument( '--gamma', type=float, default=0.95, help='discount factor') parser.add_argument( '--batch_size', type=int, default=1024, help='number of episodes to optimize at the same time') parser.add_argument('--tau', type=int, default=0.01, help='soft update') # auto save model, optional restore model parser.add_argument( '--show', action='store_true', default=False, help='display or not') #TRUE表示显示渲染 parser.add_argument( '--restore', action='store_true', default=False, help='restore or not, must have model_dir') parser.add_argument( '--model_dir', type=str, default='./model', help='directory for saving model') args = parser.parse_args() train_agent()
1.3.4 MADDPG算法部分:
PARL里有现成的MADDPG算法,,可以调用:train.py函数中调用格式如下
from parl.algorithms import MADDPG algorithm = parl.algorithms.MADDPG( )MADDPG.py算法程序:
import warnings warnings.simplefilter('default') from parl.core.fluid import layers from copy import deepcopy from paddle import fluid from parl.core.fluid.algorithm import Algorithm __all__ = ['MADDPG'] from parl.core.fluid.policy_distribution import SoftCategoricalDistribution from parl.core.fluid.policy_distribution import SoftMultiCategoricalDistribution def SoftPDistribution(logits, act_space): """Args: logits: the output of policy model act_space: action space, must be gym.spaces.Discrete or multiagent.multi_discrete.MultiDiscrete Return: instance of SoftCategoricalDistribution or SoftMultiCategoricalDistribution """ # is instance of gym.spaces.Discrete if (hasattr(act_space, 'n')): return SoftCategoricalDistribution(logits) # is instance of multiagent.multi_discrete.MultiDiscrete elif (hasattr(act_space, 'num_discrete_space')): return SoftMultiCategoricalDistribution(logits, act_space.low, act_space.high) else: raise AssertionError("act_space must be instance of \ gym.spaces.Discrete or multiagent.multi_discrete.MultiDiscrete") class MADDPG(Algorithm): def __init__(self, model, agent_index=None, act_space=None, gamma=None, tau=None, lr=None, actor_lr=None, critic_lr=None): """ MADDPG algorithm Args: model (parl.Model): forward network of actor and critic. The function get_actor_params() of model should be implemented. agent_index: index of agent, in multiagent env act_space: action_space, gym space gamma (float): discounted factor for reward computation. tau (float): decay coefficient when updating the weights of self.target_model with self.model lr (float): learning rate, lr will be assigned to both critic_lr and actor_lr critic_lr (float): learning rate of the critic model actor_lr (float): learning rate of the actor model """ assert isinstance(agent_index, int) assert isinstance(act_space, list) assert isinstance(gamma, float) assert isinstance(tau, float) # compatible upgrade of lr if lr is None: assert isinstance(actor_lr, float) assert isinstance(critic_lr, float) else: assert isinstance(lr, float) assert actor_lr is None, 'no need to set `actor_lr` if `lr` is not None' assert critic_lr is None, 'no need to set `critic_lr` if `lr` is not None' critic_lr = lr actor_lr = lr warnings.warn( "the `lr` argument of `__init__` function in `parl.Algorithms.MADDPG` is deprecated \ since version 1.4 and will be removed in version 2.0. \ Recommend to use `actor_lr` and `critic_lr`. ", DeprecationWarning, stacklevel=2) self.agent_index = agent_index self.act_space = act_space self.gamma = gamma self.tau = tau self.lr = lr self.actor_lr = actor_lr self.critic_lr = critic_lr self.model = model self.target_model = deepcopy(model) def predict(self, obs): """ input: obs: observation, shape([B] + shape of obs_n[agent_index]) output: act: action, shape([B] + shape of act_n[agent_index]) """ this_policy = self.model.policy(obs) this_action = SoftPDistribution( logits=this_policy, act_space=self.act_space[self.agent_index]).sample() return this_action def predict_next(self, obs): """ input: observation, shape([B] + shape of obs_n[agent_index]) output: action, shape([B] + shape of act_n[agent_index]) """ next_policy = self.target_model.policy(obs) next_action = SoftPDistribution( logits=next_policy, act_space=self.act_space[self.agent_index]).sample() return next_action def Q(self, obs_n, act_n): """ input: obs_n: all agents' observation, shape([B] + shape of obs_n) output: act_n: all agents' action, shape([B] + shape of act_n) """ return self.model.value(obs_n, act_n) def Q_next(self, obs_n, act_n): """ input: obs_n: all agents' observation, shape([B] + shape of obs_n) output: act_n: all agents' action, shape([B] + shape of act_n) """ return self.target_model.value(obs_n, act_n) def learn(self, obs_n, act_n, target_q): """ update actor and critic model with MADDPG algorithm """ actor_cost = self._actor_learn(obs_n, act_n) critic_cost = self._critic_learn(obs_n, act_n, target_q) return critic_cost def _actor_learn(self, obs_n, act_n): i = self.agent_index this_policy = self.model.policy(obs_n[i]) sample_this_action = SoftPDistribution( logits=this_policy, act_space=self.act_space[self.agent_index]).sample() action_input_n = act_n + [] action_input_n[i] = sample_this_action eval_q = self.Q(obs_n, action_input_n) act_cost = layers.reduce_mean(-1.0 * eval_q) act_reg = layers.reduce_mean(layers.square(this_policy)) cost = act_cost + act_reg * 1e-3 fluid.clip.set_gradient_clip( clip=fluid.clip.GradientClipByNorm(clip_norm=0.5), param_list=self.model.get_actor_params()) optimizer = fluid.optimizer.AdamOptimizer(self.actor_lr) optimizer.minimize(cost, parameter_list=self.model.get_actor_params()) return cost def _critic_learn(self, obs_n, act_n, target_q): pred_q = self.Q(obs_n, act_n) cost = layers.reduce_mean(layers.square_error_cost(pred_q, target_q)) fluid.clip.set_gradient_clip( clip=fluid.clip.GradientClipByNorm(clip_norm=0.5), param_list=self.model.get_critic_params()) optimizer = fluid.optimizer.AdamOptimizer(self.critic_lr) optimizer.minimize(cost, parameter_list=self.model.get_critic_params()) return cost def sync_target(self, decay=None): if decay is None: decay = 1.0 - self.tau self.model.sync_weights_to(self.target_model, decay=decay)
至此已经把多智能体深度强化学习算法算法实现核心代码讲完了,下面开始讲述如何实现!
2.在本地实现
2.1 安装parl、gym创建环境
- 首先安装parl、步骤见:https://blog.csdn.net/sinat_39620217/article/details/114537725
- 如果还没有安装anaconda也请参考:https://blog.csdn.net/sinat_39620217/article/details/115861876
- 安装gym:https://blog.csdn.net/sinat_39620217/article/details/115510483
如果不会设置环境创建自己的gym游戏参考上面文章,正确放置好maddp的环境才可以跑通程序! 不懂必看!!或者下面看我设置有问题不理解时候,回头重新看!
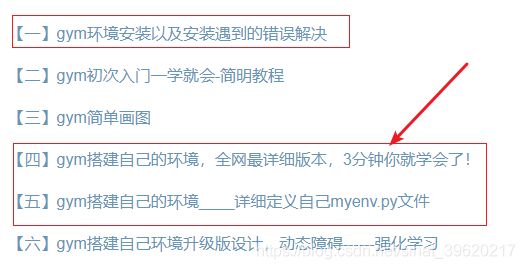
2.2 放置下载文件
首先确认下载下来的文件:
- 核实环境文件:



- 核实主程序运行文件:
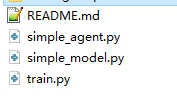
开始放置文件位置
将环境文件放置到上述创建的虚拟环境parl【安装了飞桨】中。我的路径如下:
H:\Anaconda3-2020.02\envs\parl\Lib\site-packages\gym\envs
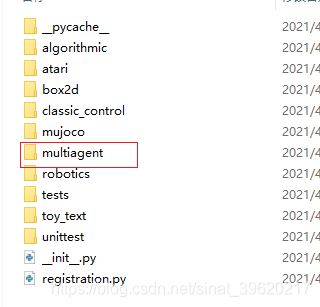
2.3 设置环境参数init文件修改
首先是: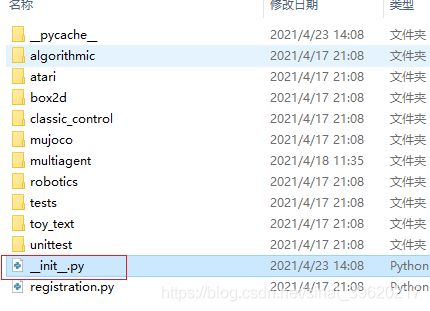 路径下的init文件进行修改
路径下的init文件进行修改
H:\Anaconda3-2020.02\envs\parl\Lib\site-packages\gym\envs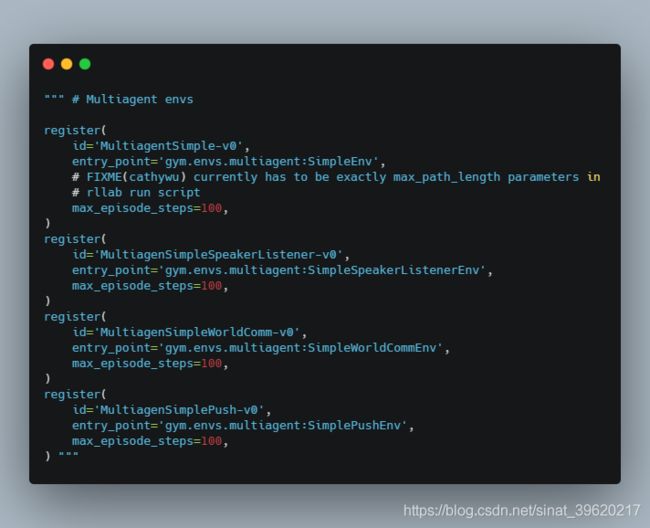
这里会发现可能和官网提供的环境文件也发有关,不同场景需要程序里改动调用。并没有明确的某个环境,所以写不写并没有影响!
再是:
该路径下init文件进行修改
H:\Anaconda3-2020.02\envs\parl\Lib\site-packages\gym\envs\multiagent
至此完成环境路径在gym中的声明
2.4 修改文件中导入库的路径
每个人放置路径不同和gym安装路径不同会导致很多库可能无法调用,因此需要一一修改。
如果在运行中遇到报错,请仔细看清楚报错出现在那一行!再根据我下面写的进行修改:
- train文件中:
import os
import time
import argparse
import numpy as np
from simple_model import MAModel
from simple_agent import MAAgent
import parl
from gym.envs.multiagent.multiagent_simple_env import MAenv
from parl.utils import logger, summary
from gym import spaces
from gym.envs.multiagent.multi_discrete import MultiDiscretegym.envs.multiagent.这个部分就是修改过的部分,放置在gym路径下!
这里from gym.envs.multiagent.multiagent_simple_env import MAenv需要注意
这个文件是在:
H:\Anaconda3-2020.02\envs\parl\Lib\site-packages\parl\envparl自己环境下多智能体简单环境
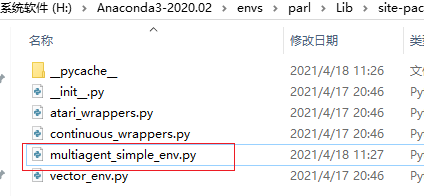
将该文件进行复制,放到我们放置的gym路径下:

然后把路径修改如下:即可

- environment文件
import gym
from gym import spaces
from gym.envs.registration import EnvSpec
import numpy as np
from gym.envs.multiagent.multi_discrete import MultiDiscrete在multi_discrete 文件中
import numpy as np
import gym
from gym.spaces import prngprng在gym在0.11后的版本删除prng的内容,因此要安装之前的版本。如果报错了请参考:https://blog.csdn.net/sinat_39620217/article/details/115818626进行新修改!
ModuleNotFoundError的报错是指:在.py文件的搜索路径下,找不到指定的Module。(这种问题分两种情况,一种是你压根就没安装这个包,一种是你安装的路径不对)
也可以添加路径 import sys ;sys.append 路径也行,我传到码云程序都有写的
错误如下:
ModuleNotFoundError: No module named 'multiagent' from parl.env.multiagent_simple_env import MAenv
再对下面渲染环境中需要调用rendering库进行修改:
from gym.envs.multiagent import rendering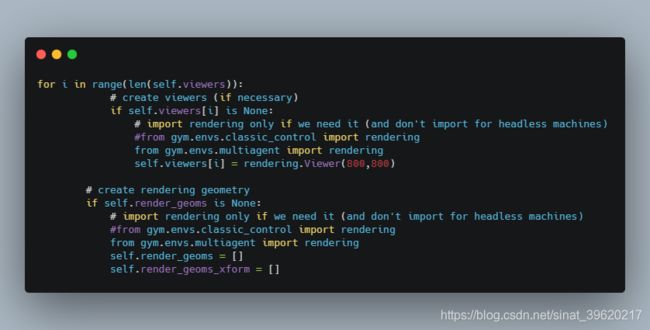
2.5 scenarios文件夹下环境库导入修改
所有的文件都修改如下:simple、simple_adversary、simple_crypto、simple_push、simple_reference、simple_speaker_listener、simple_spread、simple_tag、simple_world_comm
import numpy as np
from gym.envs.multiagent.core import World, Agent, Landmark
from gym.envs.multiagent.scenario import BaseScenario至此已经全部修改完毕
3.主要调整参数
- 根据自己需求修改default
- 下面是我自己根据官网提供的参数进行了修改
parser.add_argument(
'--env',
type=str,
default='simple_world_comm', #修改环境场景
help='scenario of MultiAgentEnv')
parser.add_argument(
'--max_step_per_episode',
type=int,
default=50, #每个episode中最大step
help='maximum step per episode')
parser.add_argument(
'--max_episodes',
type=int,
default=50000, #一共训练多少step
help='stop condition:number of episodes')
parser.add_argument(
'--stat_rate',
type=int,
default=1000, #第1000episodes保存一下,并显示reward值。
help='statistical interval of save model or count reward')
# Core training parameters
parser.add_argument(
'--critic_lr',
type=float,
default=1e-3,
help='learning rate for the critic model')
parser.add_argument(
'--actor_lr',
type=float,
default=1e-3, ##修改 default值可修改学习率
help='learning rate of the actor model')
parser.add_argument(
'--gamma', type=float, default=0.95, help='discount factor')
parser.add_argument(
'--batch_size',
type=int,
default=1024,
help='number of episodes to optimize at the same time')
parser.add_argument('--tau', type=int, default=0.01, help='soft update')
# auto save model, optional restore model
parser.add_argument(
'--show', action='store_true', default=True, help='display or not') #TRUE表示显示渲染
parser.add_argument(
'--restore',
action='store_true',
default=False,
help='restore or not, must have model_dir')
parser.add_argument(
'--model_dir',
type=str,
default='./model',
help='directory for saving model')如果在选择环境运行出错提示reshape格式不对把train文件中138行保存文件这里修改为下面:(可能.ckpt格式遗漏导致)
if args.restore:
# restore modle
for i in range(len(agents)):
model_file = args.model_dir + '/agent_' + str(i) + '.ckpt'
if not os.path.exists(model_file):
logger.info('model file {} does not exits'.format(model_file))
raise Exception
agents[i].restore(model_file)4.运行展示
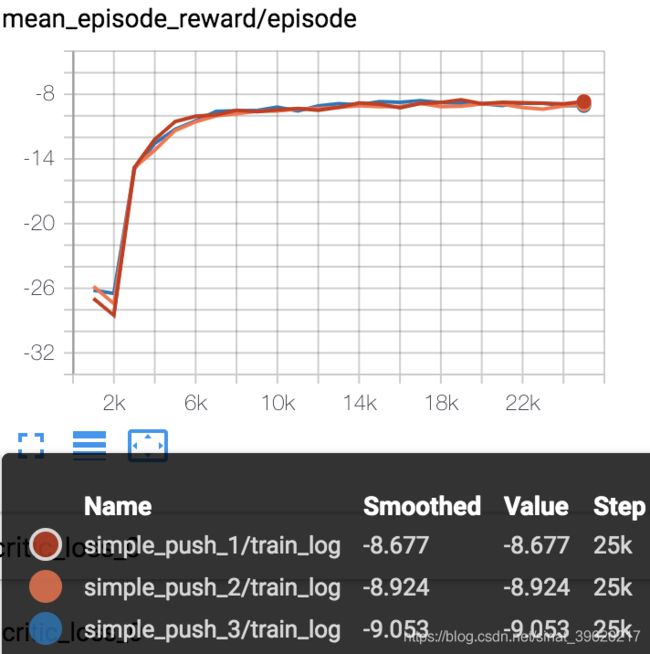
4.1 simple_speaker_listener结果:

结果如下:
[33m[04-23 14:09:53 MainThread @tensorboard.py:34][0m [5m[33mWRN[0m [tensorboard] logdir is None, will save tensorboard files to train_log\train
View the data using: tensorboard --logdir=./train_log\train --host=10.22.151.209
[32m[04-23 14:10:31 MainThread @train.py:166][0m Steps: 25000, Episodes: 1000, Mean episode reward: -146.71197663766637, Time: 38.256
[32m[04-23 14:10:32 MainThread @machine_info.py:91][0m Cannot find available GPU devices, using CPU or other devices now.
[32m[04-23 14:10:32 MainThread @machine_info.py:91][0m Cannot find available GPU devices, using CPU or other devices now.
[32m[04-23 14:11:22 MainThread @train.py:166][0m Steps: 50000, Episodes: 2000, Mean episode reward: -177.59173856982906, Time: 50.769
[32m[04-23 14:12:15 MainThread @train.py:166][0m Steps: 75000, Episodes: 3000, Mean episode reward: -65.93734078140551, Time: 53.699
[32m[04-23 14:13:07 MainThread @train.py:166][0m Steps: 100000, Episodes: 4000, Mean episode reward: -60.95650945973305, Time: 51.837
[32m[04-23 14:13:58 MainThread @train.py:166][0m Steps: 125000, Episodes: 5000, Mean episode reward: -60.4786219660665, Time: 50.83
[32m[04-23 14:14:47 MainThread @train.py:166][0m Steps: 150000, Episodes: 6000, Mean episode reward: -61.97418693302028, Time: 48.797
[32m[04-23 14:15:36 MainThread @train.py:166][0m Steps: 175000, Episodes: 7000, Mean episode reward: -61.27743577282738, Time: 49.405
[32m[04-23 14:16:26 MainThread @train.py:166][0m Steps: 200000, Episodes: 8000, Mean episode reward: -55.795305675851054, Time: 49.48
[32m[04-23 14:17:15 MainThread @train.py:166][0m Steps: 225000, Episodes: 9000, Mean episode reward: -52.170408578073314, Time: 49.602
[32m[04-23 14:18:05 MainThread @train.py:166][0m Steps: 250000, Episodes: 10000, Mean episode reward: -45.48956962382595, Time: 49.977
[32m[04-23 14:18:57 MainThread @train.py:166][0m Steps: 275000, Episodes: 11000, Mean episode reward: -37.54661975584198, Time: 51.9
[32m[04-23 14:19:51 MainThread @train.py:166][0m Steps: 300000, Episodes: 12000, Mean episode reward: -35.94095515700111, Time: 53.781
[32m[04-23 14:20:45 MainThread @train.py:166][0m Steps: 325000, Episodes: 13000, Mean episode reward: -33.22250130999288, Time: 53.623
[32m[04-23 14:21:38 MainThread @train.py:166][0m Steps: 350000, Episodes: 14000, Mean episode reward: -33.88889589767084, Time: 53.842
[32m[04-23 14:22:32 MainThread @train.py:166][0m Steps: 375000, Episodes: 15000, Mean episode reward: -32.222499746838956, Time: 53.521
[32m[04-23 14:23:21 MainThread @train.py:166][0m Steps: 400000, Episodes: 16000, Mean episode reward: -32.56661045688181, Time: 49.577
[32m[04-23 14:24:11 MainThread @train.py:166][0m Steps: 425000, Episodes: 17000, Mean episode reward: -33.26917140412647, Time: 49.626
[32m[04-23 14:25:01 MainThread @train.py:166][0m Steps: 450000, Episodes: 18000, Mean episode reward: -35.43697273278178, Time: 49.528
[32m[04-23 14:25:50 MainThread @train.py:166][0m Steps: 475000, Episodes: 19000, Mean episode reward: -32.72183170780931, Time: 49.623
[32m[04-23 14:26:40 MainThread @train.py:166][0m Steps: 500000, Episodes: 20000, Mean episode reward: -29.851138059307747, Time: 49.549
[32m[04-23 14:27:30 MainThread @train.py:166][0m Steps: 525000, Episodes: 21000, Mean episode reward: -30.199245070908457, Time: 49.909
[32m[04-23 14:28:19 MainThread @train.py:166][0m Steps: 550000, Episodes: 22000, Mean episode reward: -30.753366241189703, Time: 49.638
[32m[04-23 14:29:10 MainThread @train.py:166][0m Steps: 575000, Episodes: 23000, Mean episode reward: -29.245936484505624, Time: 50.944
[32m[04-23 14:30:00 MainThread @train.py:166][0m Steps: 600000, Episodes: 24000, Mean episode reward: -29.90573991291673, Time: 49.776
[32m[04-23 14:30:50 MainThread @train.py:166][0m Steps: 625000, Episodes: 25000, Mean episode reward: -28.012067336375498, Time: 49.603
[32m[04-23 14:31:41 MainThread @train.py:166][0m Steps: 650000, Episodes: 26000, Mean episode reward: -27.606981177395067, Time: 51.432
[32m[04-23 14:32:33 MainThread @train.py:166][0m Steps: 675000, Episodes: 27000, Mean episode reward: -28.298744008978385, Time: 51.444
[32m[04-23 14:33:25 MainThread @train.py:166][0m Steps: 700000, Episodes: 28000, Mean episode reward: -28.153396104027372, Time: 52.03
[32m[04-23 14:34:17 MainThread @train.py:166][0m Steps: 725000, Episodes: 29000, Mean episode reward: -29.419025882229768, Time: 52.388
[32m[04-23 14:35:09 MainThread @train.py:166][0m Steps: 750000, Episodes: 30000, Mean episode reward: -29.029263843079026, Time: 52.416
[32m[04-23 14:36:03 MainThread @train.py:166][0m Steps: 775000, Episodes: 31000, Mean episode reward: -29.873391889162605, Time: 53.696
[32m[04-23 14:36:55 MainThread @train.py:166][0m Steps: 800000, Episodes: 32000, Mean episode reward: -29.46000530751644, Time: 51.57
[32m[04-23 14:37:49 MainThread @train.py:166][0m Steps: 825000, Episodes: 33000, Mean episode reward: -30.474405124370563, Time: 54.476
[32m[04-23 14:38:43 MainThread @train.py:166][0m Steps: 850000, Episodes: 34000, Mean episode reward: -29.484400820070196, Time: 53.409
[32m[04-23 14:39:35 MainThread @train.py:166][0m Steps: 875000, Episodes: 35000, Mean episode reward: -28.966424317648737, Time: 52.674
最后reward一直在-29-28之间波动。其余场景我就不一一贴出来,感兴趣的自己跑一跑,我这边参数可能设定也不是很好,会导致有时候效果不佳,需要调整。
给出建议可以再train文件中添加测试训练来提高模型精度或者把训练参数中max step增大,也增加训练时间步数看看结果
4.2 官网程序跑出来的效果
可以看到simple_speaker_listener跑出结果和图5基本一样收敛了





MADDPG_simple MADDPG_simple_adversary MADDPG_simple_push



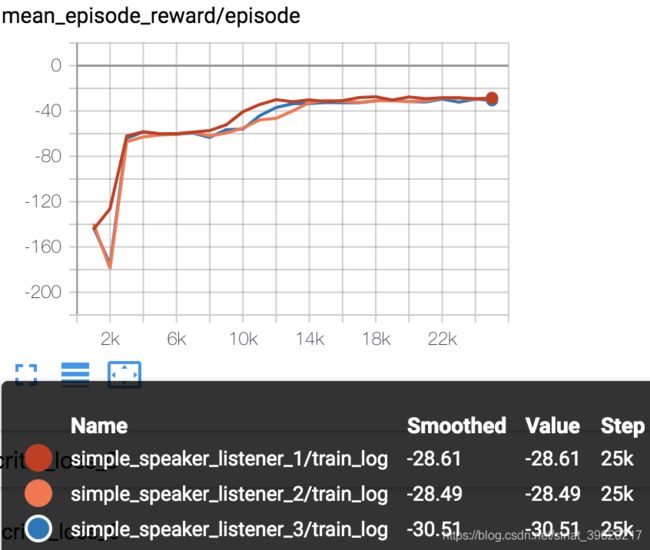
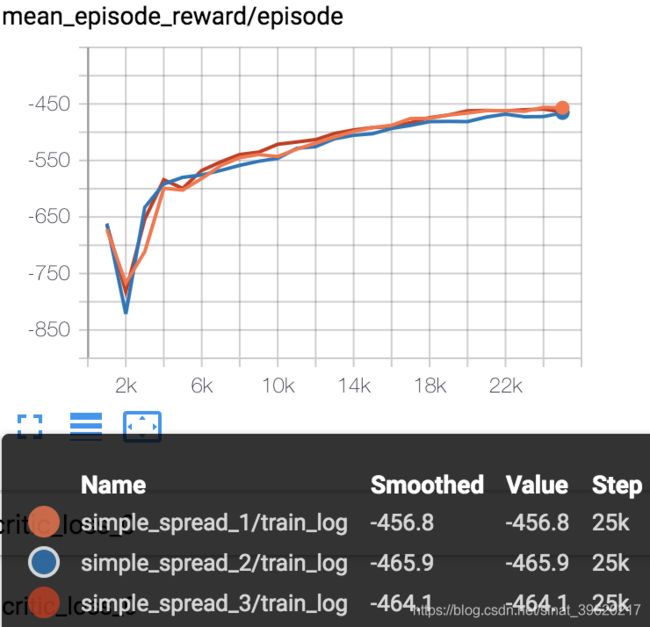
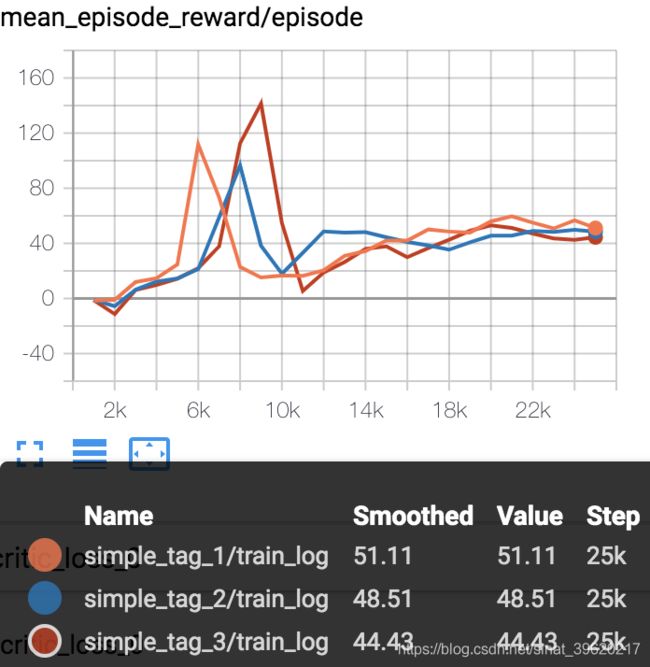
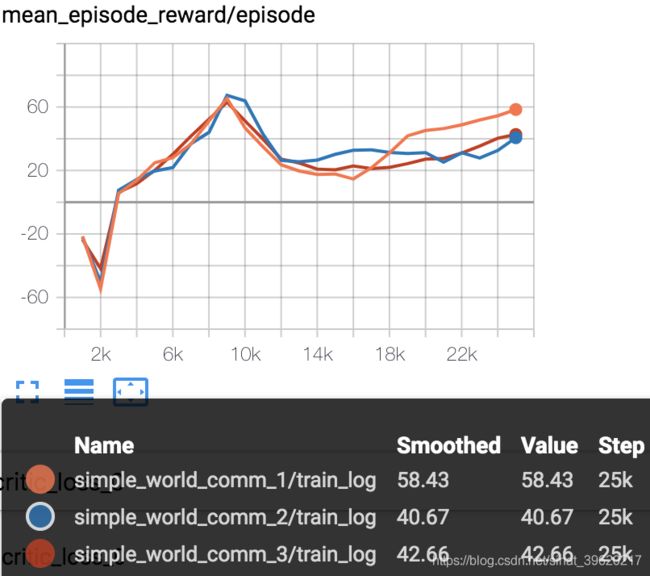
MADDPG_simple_reference MADDPG_simple_speaker_listener MADDPG_simple_spread


MADDPG_simple_tag MADDPG_simple_world_comm