Pytorch机器学习(九)—— YOLO中对于锚框,预测框,产生候选区域及对候选区域进行标注详解
Pytorch机器学习(九)—— YOLO中锚框,预测框,产生候选区域及对候选区域进行标注详解
目录
Pytorch机器学习(九)—— YOLO中锚框,预测框,产生候选区域及对候选区域进行标注
前言
一、基本概念
1、边界框(bounding box)
xyxy格式
xywh格式
2、锚框(anchor box)
3、预测框(prediction box)
中心目标生成
长宽生成
4、对候选区域进行标注
objectness标签
location标签
label标签
二、代码讲解
总结
前言
YOLO中或者说one-stage的目标检测中的第一步就是产生候选区域,如何产生候选区域是目标检测领域的核心问题,而产生候选区域可以:分为以下两步
- 按一定的规则在图片上生成一系列位置固定的锚框,将这些锚框看作是可能的候选区域。
- 对锚框是否包含目标物体进行预测,如果包含目标物体,还需要预测所包含物体的类别,以及预测框相对于锚框位置需要调整的幅度。
这篇文章主要就讲解以上两个步骤,下面的代码借鉴了百度课程和YOLOV5的源码进行编写。
只想了解概念的看前面就行,第二部分主要是代码。
一、基本概念
在介绍下面内容之前,先简单介绍一下几个基本的概念。其中锚框和预测框在后续特别容易弄混,请多加留意。
1、边界框(bounding box)
在目标检测中,用边界框来表示物体的位置,边界框为能正好包含物体的矩形框。如下图中包含人脸位置的矩形框即为边界框。

边界框主要有以下两种表现形式。
xyxy格式
即边界框由左上角坐标(x1,y1)和右下角坐标(x2,y2)来表示
xywh格式
即边界框由中心坐标(x,y)和框的长宽(w,h)来表示,YOLO中采用的主要是这种形式。
我们在训练的时候,也会把边界框称为ground true box,真实框
2、锚框(anchor box)
锚框与物体边界框不同,是由人们假想出来的一种框。先设定好锚框的大小和形状,再以图像上某一个点为中心画出矩形框。
而在YOLO中,生成规则是将图片分割成mxn个区域,然后在每个格子的中心,按照设定的长宽比等,生成一系列的锚框。
这里说一下,设定的长宽,在YOLO中是采用聚类的方法产生的,而在YOLOV5中具体为采用k-means聚类+遗传算法计算得到,后续更新。
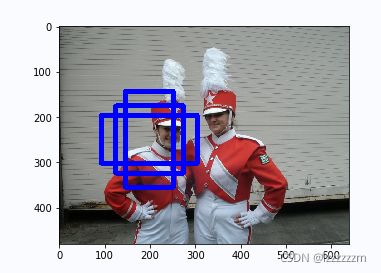

在目标检测任务中,通常会以某种规则在图片上生成一系列锚框,将这些锚框当成可能的候选区域。模型对这些候选区域是否包含物体进行预测,如果包含目标物体,则还需要进一步预测出物体所属的类别。还有更为重要的一点是,由于锚框位置是固定的,它不大可能刚好跟物体边界框重合,所以需要在锚框的基础上进行微调以形成能准确描述物体位置的预测框,模型需要预测出微调的幅度。
简单的说,锚框对于预测框来说,就相当于网络对其的初始化权重。
3、预测框(prediction box)
预测框即是锚框的微调结果,其结果是更加的贴近真实框,问题就在与如何微调锚框,才能得到较好的结果。在YOLO中,主要采用下面的方法对锚框进行微调。
中心目标生成
由锚框的生成方法可知,它是以某个划分格子的中心坐标,以一定长宽比生成的,但在YOLO中预测框,则是以某个格子的左上角坐标为原点进行偏移的。

图中格子的坐的左上角坐标为(cx,cy) ,则预测框中的中心坐标为(bx,by),其中


由sigmoid函数可知,其函数值在(0,1)之间,bx,by的中心坐标一定在这个划分的格子中。
长宽生成
而对于预测框的长宽生成,则是基于锚框的初始长宽(pw,ph),以下面公式生成(bw,bh)
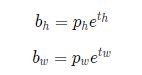
由上面的公式可以知道,我们的网络其实就是在预测tx,ty,th,tw的值。由于我们是知道真实框的bx,by,bh,bw,由反函数,容易知道真实框tx*,ty*,th*,tw*,则我们网络其中一个边界框loss,为tx,ty,th,tw和tx*,ty*,th*,tw*计算得出,有关loss的东西下次在详细说。
下面简单说一下为什么采用这种方法得出bx,by,bh,bw。其实主要就是采用sigmoid和e指数函数,对于网络的输出没有约束。
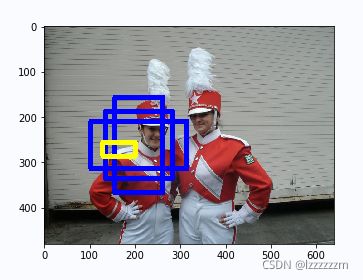
下图黄色框则为其中一个anchor box以tx = 3,ty = 0.3,tw = 0.3,th = 0.2生成的预测框。
4、对候选区域进行标注
这里有很多关于锚框(anchor box)和预测框(prediction box)的概念,请注意区分!
每个锚框都可能是候选区域,但我们根据上面的内容可知,一张图片会生成很多锚框,那我们如何确定哪个是我们需要的,如果这个是需要的,我们需要得到它的扫描信息,主要考虑以下三个方面。
-
objectness标签:锚框是否包含物体,这可以看成是一个二分类问题。当锚框包含了物体时,objectness=1,表示预测框属于正类;当锚框不包含物体时,设置objectness=0,表示锚框属于负类。
-
location标签:如果锚框包含了物体,那么它对应的预测框的中心位置和大小应该是多少,或者说上面计算式中的tx,ty,tw,th应该是多少。
-
label标签:如果锚框包含了物体,那么具体类别是什么。
objectness标签
对于objectness标签,锚框是否包含物体,我们主要采用IOU或者GIOU等指标来判别,关于IOU,GIOU等,可以看我下面这篇文章。我下面的讲解都以IOU为指标评价objectness标签。
Pytorch机器学习(五)——目标检测中的损失函数(l2,IOU,GIOU,DIOU, CIOU)
我们可以算出所有我们的锚框与真实框之间的IOU,然后根据IOU这个评价指标,选出n个锚框(n是真实框的个数)
我们将这n个锚框的objectness标签都标记为1,其他都标注为0
但在YOLO中,对于一些IOU也挺大的锚框,是这么处理的,设定一个阈值,若其IOU大于这个阈值,则将objectness标签标注为-1,而不是0.
我们在预测中,也只需要根据objectness标签是1的锚框,进行预测location标签和label标签!!
location标签
对于location标签,即是对于objectness标签为1,标注其真实框tx*,ty*,th*,tw*四个值。注意这里标注的是真实框的tx*,ty*,th*,tw*
label标签
对于label标签,我们采用one-hot编码,比如有4个类别,则标注为[0, 0, 0, 1](假设其为第4个类别)
由此可知,我们对于候选框的标注,一共需要标注,1(objectness标签)+ 4(location标签)+ n(类别数——label标签)个参数。
而我们的网络对于每个预测框也是这么多个参数!!这对于后面理解网络输出很关键!!
二、代码讲解
对于如何生成锚框,与候选框标注的函数如下,代码比较长,注释我写的比较全,一步步看完会对上面的内容理解更深。
# 标注预测框的objectness
def get_objectness_label(img, gt_boxes, gt_labels, iou_threshold = 0.7,
anchors = [116, 90, 156, 198, 373, 326],
num_classes=7, downsample=32):
"""
img 是输入的图像数据,形状是[N, C, H, W]
gt_boxes,真实框,维度是[N, 50, 4],其中50是真实框数目的上限,当图片中真实框不足50个时,不足部分的坐标全为0
真实框坐标格式是xywh,这里使用相对值
gt_labels,真实框所属类别,维度是[N, 50]
iou_threshold,当预测框与真实框的iou大于iou_threshold时不将其看作是负样本
anchors,锚框可选的尺寸
anchor_masks,通过与anchors一起确定本层级的特征图应该选用多大尺寸的锚框
num_classes,类别数目
downsample,特征图相对于输入网络的图片尺寸变化的比例
"""
img_shape = img.shape
batchsize = img_shape[0]
# 这里的anchors两两一组,分别表示长宽
num_anchors = len(anchors) // 2
input_h = img_shape[2]
input_w = img_shape[3]
# 将输入图片划分成num_rows x num_cols个小方块区域,每个小方块的边长是 downsample
# 计算一共有多少行小方块
num_rows = input_h // downsample
# 计算一共有多少列小方块
num_cols = input_w // downsample
# 对于返回值进行全0初始化
label_objectness = np.zeros([batchsize, num_anchors, num_rows, num_cols])
label_location = np.zeros([batchsize, num_anchors, 4, num_rows, num_cols])
label_classification = np.zeros([batchsize, num_anchors, num_classes, num_rows, num_cols])
# 这里有个scale_location,用来调节大目标和小目标的权重的
# 大目标和小目标对于相同的偏移,大目标更加敏感,故增强这个权重系数
scale_location = np.ones([batchsize, num_anchors, num_rows, num_cols])
# 对batchsize进行循环,依次处理每张图片
for n in range(batchsize):
# 对图片上的真实框进行循环,依次找出跟真实框形状最匹配的锚框
for n_gt in range(len(gt_boxes[n])):
gt = gt_boxes[n][n_gt]
# 真实框所属类别
gt_cls = gt_labels[n][n_gt]
# 真实框的中心坐标和长宽(YOLO中采用xywh)
gt_center_x = gt[0]
gt_center_y = gt[1]
gt_width = gt[2]
gt_height = gt[3]
# 如果真实框过小,则认为标签损坏
if (gt_width < 1e-3) or (gt_height < 1e-3):
continue
# 计算这个真实框的中心点落在哪个格子里
i = int(gt_center_y * num_rows)
j = int(gt_center_x * num_cols)
ious = []
for ka in range(num_anchors):
# x,y为0,因为锚框和真实框的x,y相同
bbox1 = [0., 0., float(gt_width), float(gt_height)]
# 生成输入(i,j)这个格子里的锚框
anchor_w = anchors[ka * 2]
anchor_h = anchors[ka * 2 + 1]
bbox2 = [0., 0., anchor_w/float(input_w), anchor_h/float(input_h)]
# 计算iou
iou = box_iou_xywh(bbox1, bbox2)
ious.append(iou)
ious = np.array(ious)
# 算出最大iou的index
inds = np.argsort(ious)
k = inds[-1]
label_objectness[n, k, i, j] = 1
c = gt_cls
label_classification[n, k, c, i, j] = 1.
# for those prediction bbox with objectness =1, set label of location
# 反算出真实框的tx*,ty*,tw*,th*
dx_label = gt_center_x * num_cols - j
dy_label = gt_center_y * num_rows - i
dw_label = np.log(gt_width * input_w / anchors[k*2])
dh_label = np.log(gt_height * input_h / anchors[k*2 + 1])
label_location[n, k, 0, i, j] = dx_label
label_location[n, k, 1, i, j] = dy_label
label_location[n, k, 2, i, j] = dw_label
label_location[n, k, 3, i, j] = dh_label
# scale_location用来调节不同尺寸的锚框对损失函数的贡献,作为加权系数和位置损失函数相乘
# 根据这个计算方法,可以得出真实框越大,权重越小
scale_location[n, k, i, j] = 2.0 - gt_width * gt_height
# 目前根据每张图片上所有出现过的gt box,都标注出了objectness为正的预测框,剩下的预测框则默认objectness为0
# 对于objectness为1的预测框,标出了他们所包含的物体类别,以及位置回归的目标
return label_objectness.astype('float32'), label_location.astype('float32'), label_classification.astype('float32'), \
scale_location.astype('float32')
总结
涉及概念比较多,而且基于自己本人的理解,如果有出错,欢迎讨论指正。