笔试 sql 忘了?回来看看这篇入门总结!
前言
我们知道,在校招的过程中,笔试是一个非常重要的环节,公司不一样,考察的内容也五花八门。总结一下大概有计算机基础+岗位相关知识+算法题+其他(包括智力题、数学题等等),其中计算机基础的部分除了我们常见的计算机网络、操作系统、数据结构之外,还有非常容易被我们忽视的sql。虽然一般题量不多,难度也不高,但如果长时间没有复习过,也很有可能白白失分,所以这两天花了些时间复习了一遍sql的基本语法,这里做一个简单的总结
目录
- 前言
- 一、基本概念
- 二、语法分类
-
-
- 第一种
- 第二种
- 第三种
- 总结
-
- 三、查询顺序
- 四、DDL
-
-
- 1、创建:create
- 2、修改:alter
- 3、删除:drop
-
- 五、DML
- 六、DQL
-
-
- 1、select
- 2、join...on...
- 3、where
- 4、group by
- 5、having
- 6、order by
- 7、limit
-
- 七、聚合函数
- 八、子查询
- 九、相关问题
-
-
- (1)、where和having有什么区别
- (2)、delete、truncate和drop有什么区别
- (3)、alter、modify和change有什么区别
- (4)、insert into select 和 select into from 的区别
- (5)、case when是什么用法
- (6)、sql注入的关键是什么
- (7)、where 1、where0、count(1)、count(*)
-
- 总结
一、基本概念
- SQL (Structured Query Language:结构化查询语言) 是用于管理关系数据库管理系统(RDBMS)的语言
- RDBMS (关系型数据库管理系统)是 SQL 的基础,同样也是所有现代数据库系统的基础
- sql对大小写不敏感,但是建议语句使用大写,表名列名等数据使用小写
二、语法分类
sql的语法有着多种不同的分类方式,有的分成3类,有的4类5类,甚至6类的也有,虽然大同小异,但我们最好了解一下常见的几种方式,以免在做题时先入为主。
第一种
DDL(Data Definition Language): 数据定义语言
用来定义数据库对象:数据库,表,列等。 关键字:create,drop,,alter等。DML(Data Manipulation Language): 数据操作语言
用来对数据库中的表进行增删改操作。 关键字:insert,delete,update等。DQL(Data Query Language): 数据查询语言
用来查询数据库中表的记录(数据)。 关键字:select,where等DCL(Data Control Language): 数据控制语言
用来定义数据库的访问控制权限和安全级别,及创建用户。关键字:grant,revoke等
第二种
第二种分类方式比上一种多了一类TCL事务控制语言,D开头的一般关心的是数据,而这类语法针对的主要是事务操作。
- TCL(Transaction Control Language): 事务控制语言
用来对数据库中的事务操作进行控制,如设置保存点、回滚提交等。
关键字:SAVEPOINT (设置保存点)ROLLBACK (回滚) COMMIT(提交)
第三种
这种分类方法在第一种的基础上,把DQL合并到了DML里面,变成了这样
DDL(Data Definition Language): 数据定义语言
用来定义数据库对象:数据库,表,列等。 关键字:create,drop,,alter等。DML(Data Manipulation Language): 数据操作语言
用来对数据库中的数据进行增删查改操作。 关键字:insert,delete,update,select等。DCL(Data Control Language): 数据控制语言
用来定义数据库的访问控制权限和安全级别,及创建用户。关键字:grant,revoke等
总结
总而言之,其实核心就是D开头的数据定义、操作和控制三种,其中数据操作DML也可以把查询部分DQL单独分出来变成4种,如果再加上事务控制(TCL)就是5种了。都是在核心分类上进行添加和演变。
三、查询顺序
写法顺序:select--from--join...on--where--group by--having--order by--limit
执行顺序:join...on--from--where--group by--having--select--order by--limit
就是select要放后面,如果有order by,则order by放最后,因为order by 是对结果进行排序
执行的时候:
1、首先通过from和join…on(先连接两表)获得我们的数据源表
2、然后使用where对源表进行条件筛选,得到临时表
3、group by对临时表进行分组,分组后having二次筛选,得到结果表
4、有了结果表我们才可以使用select选择和操作结果
5、最后再使用order by进行排序,排序后的结果可以用limit选择性展示
写一个结合上面语法顺序的完整查询语句:
SELECT DISTINCT column1, AGG_FUNC(column_or_expression), …
FROM mytable
JOIN another_table
ON mytable.column1 = another_table.column1
WHERE constraint_expression
GROUP BY column1
HAVING constraint_expression
ORDER BY column1 ASC/DESC
LIMIT count OFFSET COUNT;
四、DDL
1、创建:create
创建数据库
CREATE DATABASE test
创建表
CREATE TABLE pet (
id INT, //属性名+数据类型
name VARCHAR(20),
owner VARCHAR(20),
s_id INT,
sex CHAR(1),
birth DATE
);
也可以加上一些约束
CREATE TABLE pet (
id INT PRIMARY KEY, //主键约束,不能重复不能为空,可设置在多个属性上
name VARCHAR(20) NOT NULL, //非空约束,不能为空
owner VARCHAR(20) UNIQUE, //唯一约束,保证该列的每行必须有唯一的值
s_id INT,
sex CHAR(1) DEFAULT '1', //默认约束,添加一个默认值
birth DATE,
FOREIGN KEY(s_id) REFERENCES class(id) //外键约束,s_id必须来自class表的主键id
);
2、修改:alter
先看看alter的语法:
ALTER TABLE <表名> [修改选项]
{ ADD COLUMN <列名> <类型>
| CHANGE COLUMN <旧列名> <新列名> <新列类型>
| ALTER COLUMN <列名> { SET DEFAULT <默认值> | DROP DEFAULT }
| MODIFY COLUMN <列名> <类型>
| DROP COLUMN <列名>
| RENAME TO <新表名> }
alter主要是对表的结构进行增删改,如
ALTER TABLE pet ADD PRIMARY KEY(c_id); //添加主键c_id
ALTER TABLE pet MODIFY c_id INT PRIMARY KEY; //修改c_id类型为主键
ALTER TABLE pet drop PRIMARY KEY; //删除主键
其中change、modify和alter三种修改的区别是常考点,我们会在后面进行阐述。
3、删除:drop
删除数据库
DROP DATABASE test
删除表
DROP TABLE pet
用DROP INDEX还可以删除索引;
drop、truncate和delete三种删除方式的区别也是常考点,同样在后面说明。
五、DML
插入数据
INSERT INTO test value(3,'大黄'); //数据要符合表内设置的格式
更新数据
UPDATE test SET name = '小黄' WHERE id = '3'; //更新数据必须要用where指定对应的行
查询数据
SELECT name FROM test
删除数据
DELETE FROM test WHERE name = '小黄'; //如果不使用where指定列,可能会清空表的数据
六、DQL
1、select
SELECT * FROM pet; //查询所有属性列
SELECT id,name FROM pet; //查询指定属性列
SELECT DISTINCT sex FROM pet; //distinct去掉重复值,查询唯一值
2、join…on…
join是表连接的语法,利用它可以实现多表查询
SELECT * FROM pet //pet在join左边为左表,people为右表
JOIN people ON pet.id = people.petid //两表通过对应的id和petid联系起来
常见的join有四种:
- inner join:内连接,默认join的完整写法,也叫等值连接
- left (outer) join:左连接,以左表为基准表,左表所有行都会出现在结果中,右表若匹配不到对应值则会出现null,是一种外连接。
- right (outer) join:右连接,以右表为基准表,右表所有行都会出现在结果中,左表若匹配不到对应值则会出现null,是一种外连接。
- full (outer) join:全连接,两边所有的行都会出现在结果中,匹配不到的值为null,也是一种外连接。
把菜鸟教程的图搬上来看看会清晰一点:
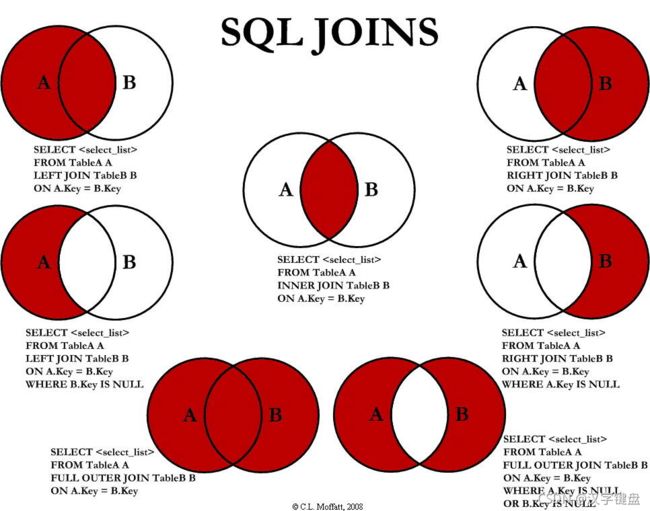
除了以上连接方法,还有交叉连接,相当于笛卡尔积,返回左表行数*右表行数。在多表查询时,我们可以根据场景的需要灵活使用不同的连接方式。
3、where
where可以对未分组的表进行筛选,后面可以用逻辑运算符and,or接上多个筛选条件。
(为方便理解,下面语法使用小写)
Select * from pet where id=7900; // 搜索 id 等于 7900 的数据
Select * from pet where name='SMITH'; //使用单引号表示是字符串,字符串要区分大小写
//也可以使用其他比较运算符,包括:= > < >= ,<=,<> 表示(不等于)
Select * drom pet where id>=7900;
//逻辑运算(优先级为:() > not > and > or)
Select * from pet where id > 2000 and id < 3000;//id 同时大于2000小于3000的值。
Select * from pet where id > 2000 or comm > 500; //id 大于2000或COMM大于500的值。
select * from pet where not id > 1500; //id 不大于1500的值,也就是小于等于
//空值判断(is (not) not)
Select * from pet where comm is (not) null; //查询空值或非空值
//区间判断(between...and...; in)
//查询id大于等于1500且小于等于3000的值,注意包含上下限
Select * from pet where id between 1500 and 3000;
//查询id等于 5000,3000,1500 的值。
Select * from pet where id in (5000,3000,1500);
//模糊查询(Like)
Select * from emp where name like 'M%';//查询名字中以M开头的值
/*
% 表示多个字值,_ 下划线表示一个字符;
M% : 为能配符,正则表达式,表示的意思为模糊查询信息为 M 开头的。
%M% : 表示查询包含M的所有内容。
%M_ : 表示查询以M在倒数第二位的所有内容。
*/
where的筛选能力很强,作用也很多,这里只是做一个简单的总结。
4、group by
group by 语句可以使表按照指定的列分组展示。
SELECT * FROM pet
GROUP BY sex //按照sex分组展示
5、having
having 和 group by 必须要连用,他的作用和where一样是筛选表,但是筛选的对象是分组后的结果。
SELECT * FROM pet
GROUP BY sex //按照sex分组展示
HAVING sex=1000 //筛选分组结果中sex为1000的值
having 的其他用法和where基本相同(见上方),后面会阐述having和where的不同。
6、order by
order by是对最后的结果进行排序展示,可以指定对应的列进行排序
SELECT * FROM pet ORDER BY id; //默认是从上往下,从小到大的升序排列asc
SELECT * FROM pet ORDER BY id desc; //可以在列名后面加上desc实现降序排列
SELECT * FROM pet ORDER BY id, name desc; //先按照id升序排列,在按照name降序排列
- desc 或者 asc 只对它紧跟着的第一个列名有效,其他不受影响,仍然是默认的升序。
- ORDER BY 多列时,先按照第一个column name排序,再按照第二个column name
7、limit
limit用来控制最终展示哪几行数据,是对最终结果进行选择性区域展示
SELECT * FROM pet LIMIT 3; //LIMIT后面只跟一个参数n时,展示最前面的n条数据
SELECT * FROM pet LIMIT 2,3; //有两个参数 i,j 时,表示跳过前面i条,然后展示j条
SELECT * FROM pet LIMIT 2 OFFSET 3; //可以使用offset关键字实现和上面一样的效果
limit一般是数据展示前的最后处理,mysql里的分页就常使用limit。
七、聚合函数
sql里有许多用于计算的内建函数,其中,那些对多个值进行计算返回单一值的函数,我们称之为聚合函数。
常见的聚合函数有以下几种:
- count():用于计算一组值的数量
- sum():用于对一组值求和
- avg():用于求出一组值的平均数
- min():用于求出一组值的最小值
- max():用于求出一组值的最大值
例如:
SELECT COUNT(column_name) FROM table_name; //此时该列的列名为COUNT(column_name)
SELECT COUNT(column_name) AS nums FROM table_name; //可以用as给列取个别名nums
null和0不等价,所以在使用这些函数的时候,函数一般不会把值为null的内容计算进去。
八、子查询
子查询就是将一个查询(子查询)的结果作为另一个查询(主查询)的数据来源或判断条件的查询,子查询必须是完整的语句。嵌套子查询的作用很强大,用法也很多,详情可以查看下方这篇博客。
sql中的子查询
由于子查询是比较高阶的sql内容,不再属于基本语法,这里不再赘述。
九、相关问题
这是我在做题和总结的过程中发现的一些坑,这里整理了一下答案,作为巩固和补充的知识点:
(1)、where和having有什么区别
- 虽然都是条件筛选语句,但一个在分组前执行,一个在分组后执行
- 书写顺序where在group by前面,having在group by后面
- having必须和group by连用,where则没有限制
- having后面可以接聚合函数,where后面不能接聚合函数
(2)、delete、truncate和drop有什么区别
- delete可以删除指定数据和全部数据,truncate和drop只能删除全部数据
- 三者的删除效率不同:drop>truncate>delete
- delete只删除表内容。truncate删除表内容并释放空间。drop不仅删除内容、释放空间,还会删除表的结构,删除得一干二净
- delete的删除可以通过回滚回复,truncate和drop的不能恢复
(3)、alter、modify和change有什么区别
- alter后面接modify只能修改字段类型
- alter后面接alter可以修改字段数据(如修改默认值)
- alter后面接change可以修改列名和字段类型
(4)、insert into select 和 select into from 的区别
下面两行代码都是把表B的所有内容插入表A,但是他们对表A的要求不同,表A存在才可以使用insert,表A不存在才可以使用select into from。
insert into A select * from B; //插入一行,要求表 A 必须存在
select * into A from B; //也是插入一行,要求表 A 不存在
(5)、case when是什么用法
case … when … then … else … end是一个固定搭配,不能省略或改变其格式
这是简写语法,case函数一般有两种使用方法,都有固定的格式,详情可看下面这篇博客
sql中case when的使用
(6)、sql注入的关键是什么
sql 注入的关键是单引号 ` 的闭合
(7)、where 1、where0、count(1)、count(*)
- where 1 返回所有数据
- where 0 返回一个空集
- count(1)等同于count(*)返回所有数据,不会忽略空值
- count(字段名)会忽略空值
总结
感谢大家看到这里,sql还有非常多的内容可以深入挖掘和学习,博主整理的内容仅为入门知识,希望能够给正在回顾 sql 的你提供一点帮助。除此之外,我再推荐一个学习sql的网站平台
自学SQL
这个网站上可以在线刷SQL题目,只需要把前面12节基础课的题目刷完就可以入门了,后面的VIP课程听说质量不高,所以没有必要付费。当然,如果是想要为笔试做准备,牛客上面的专项练习有sql的专题,也是个不错的选择。