Linux系统命令与CPU、硬盘、内存、网络状态监控
1. Linux常用工具命令:
Linux系统中需要关注的指标包括CPU、硬盘、内存、网络状态这四个模块。
常用于“监控”的Linux系统命令包括:
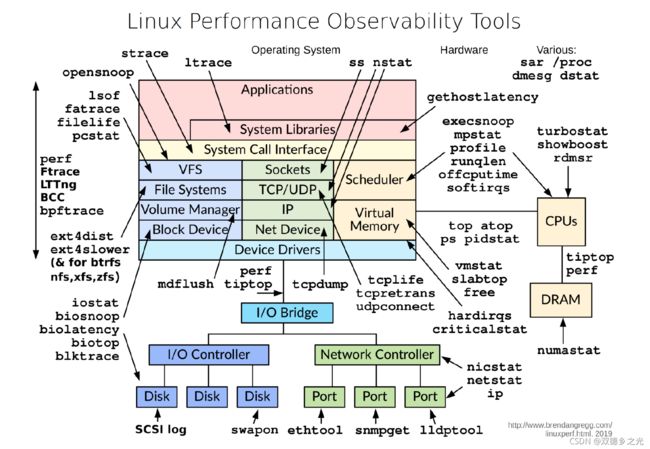
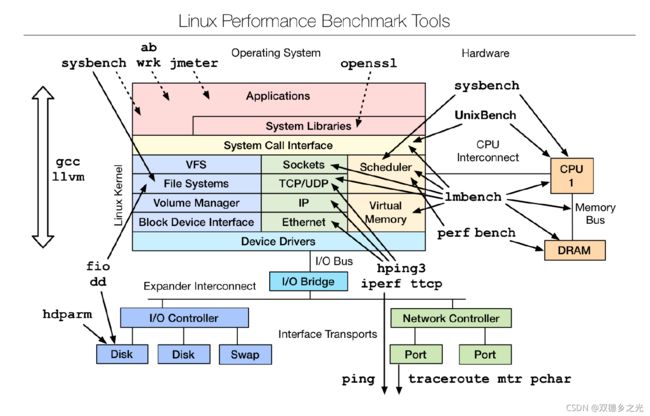
常用于“性能测试”的Linux系统命令包括:
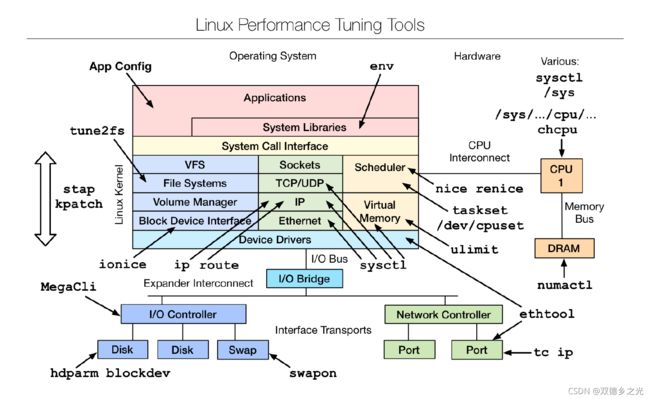
常用于“优化”的Linux系统命令包括:
2. 基础命令和工具:
2.1 uptime:机器启动时间+负载
root@virtual-machine:/# uptime
16:19:47 up 4 days, 5:30, 2 users, load average: 1.30, 1.34, 1.34
通常用于在线上应急或者技术攻关中,确定操作系统的重启时间。
2.2 ulimit:用户资源
Linux系统对每个登录用户都限制其最大进程数和打开的最大文件句柄数。可根据实际的需求进行设置,使用 ulimit -a 来显示当前系统对用户的各项使用资源的限制。
root@virtual-machine:/# ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 15394
max locked memory (kbytes, -l) 65536
max memory size (kbytes, -m) unlimited
open files (-n) 1024
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 15394
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
2.3 curl http:HTTP返回结果
curl命令用于查看HTTP调用返回的结果是否符合预期。
curl -i "http://www.sina.com" # 打印请求响应头信息
curl -I "http://www.sina.com" # 仅返回http头
curl -v "http://www.sina.com" # 打印更多的调试信息
curl -verbose "http://www.sina.com" # 打印更多的调试信息
curl -d 'abc=def' "http://www.sina.com" # 使⽤post⽅法提交http请求
curl -sw '%{http_code}' "http://www.sina.com" # 打印http响应码
例如:
root@virtual-machine:/# curl -I www.baidu.com
HTTP/1.1 200 OK
Accept-Ranges: bytes
Cache-Control: private, no-cache, no-store, proxy-revalidate, no-transform
Connection: keep-alive
Content-Length: 277
Content-Type: text/html
Date: Thu, 07 Oct 2021 08:28:21 GMT
Etag: "575e1f72-115"
Last-Modified: Mon, 13 Jun 2016 02:50:26 GMT
Pragma: no-cache
Server: bfe/1.0.8.18
3. 关于进程的命令:
3.1 ps:进程信息
ps -ef 查看系统内所有进程,使用 grep进行过滤:
root@virtual-machine:/# ps -ef | grep redis
xuesong 6573 1379 0 10月03 ? 00:10:52 ./redis-server 127.0.0.1:6379
root 309595 308064 0 16:33 pts/4 00:00:00 grep --color=auto redis
使用 grep -v 反向过滤,忽略某些不想看到的内容:
root@virtual-machine:/# ps -ef | grep redis | grep -v grep
xuesong 6573 1379 0 10月03 ? 00:10:52 ./redis-server 127.0.0.1:6379
3.2 top:进程CPU内存信息
top命令用于查看活动进程的CPU和内存信息,能够实时显示系统中各个进程的资源占用情况,可以按照CPU、内存的使用情况和执行时间对进程进行排序。
top - 17:04:13 up 4 days, 5:58, 2 users, load average: 1.17, 1.33, 1.39
任务: 360 total, 3 running, 356 sleeping, 1 stopped, 0 zombie
%Cpu(s): 40.3 us, 11.2 sy, 0.0 ni, 48.2 id, 0.0 wa, 0.0 hi, 0.3 si, 0.0 st
MiB Mem : 3906.4 total, 122.4 free, 3107.5 used, 676.5 buff/cache
MiB Swap: 923.3 total, 0.0 free, 923.3 used. 505.3 avail Mem
进程号 USER PR NI VIRT RES SHR %CPU %MEM TIME+ COMMAND
303054 root 20 0 78648 21620 176 R 99.7 0.5 167:38.28 gdb
307836 root 20 0 0 0 0 I 0.7 0.0 0:03.51 kworker/1:4-events
10 root 20 0 0 0 0 S 0.3 0.0 0:13.30 ksoftirqd/0
6573 xuesong 20 0 60588 1552 948 S 0.3 0.0 10:53.75 redis-server
7715 root 20 0 84696 276 0 S 0.3 0.0 2:32.02 file_server
7763 root 20 0 85108 892 556 S 0.3 0.0 3:34.93 http_msg_server
7785 root 20 0 644128 44592 896 S 0.3 1.1 28:36.37 db_proxy_server
45195 root 20 0 972708 4896 0 S 0.3 0.1 10:03.11 containerd
245808 xuesong 20 0 2452252 34200 10200 S 0.3 0.9 0:28.57 WebExtensions
309588 root 20 0 0 0 0 I 0.3 0.0 0:00.71 kworker/0:2-events
309875 root 20 0 20792 3896 3128 R 0.3 0.1 0:01.75 top
1 root 20 0 171580 7808 3704 S 0.0 0.2 1:29.20 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.58 kthreadd
3 root 0 -20 0 0 0 I 0.0 0.0 0:00.01 rcu_gp
4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 rcu_par_gp
top命令参数详解参考:
https://blog.csdn.net/yjclsx/article/details/81508455
3.3 pidstat:进程资源:
pidstat 用于监控全部或指定进程占用系统资源的情况,包括CPU、内存、磁盘I/O、线程切换、线程数等数据。
命令参数:
-u: 查看cpu相关的性能指标
-r: 查看内存使用信息
-d: 查看磁盘I/O统计数据
-p: 指明进程号
例如:
//第一步先使用ps命令查看redis的进程号:
root@virtual-machine:/home/xuesong# ps -ef | grep redis | grep -v grep
xuesong 6573 1379 0 10月03 ? 00:10:54 ./redis-server 127.0.0.1:6379
//第二步根据进程号6573查看进程的CPU、内存、磁盘的占用信息:
root@virtual-machine:/# pidstat -urd -p 6573
Linux 5.8.0-53-generic (xuesong-virtual-machine) 2021年10月07日 _x86_64_ (2 CPU)
17时12分48秒 UID PID %usr %system %guest %wait %CPU CPU Command
17时12分48秒 1000 6573 0.08 0.10 0.00 0.05 0.18 0 redis-server
17时12分48秒 UID PID minflt/s majflt/s VSZ RSS %MEM Command
17时12分48秒 1000 6573 11.19 0.01 60588 1512 0.04 redis-server
17时12分48秒 UID PID kB_rd/s kB_wr/s kB_ccwr/s iodelay Command
17时12分48秒 1000 6573 1.56 0.00 0.00 447 redis-server
CPU信息:
%usr:用户层正在使用的CPU百分比;
%system: 系统层正在使用的CPU百分比;
%CPU:进程整个占用的CPU时间百分比(%usr+%system)
CPU:处理器个数
%guest:运行虚拟机的CPU占用百分比。
对于“计算密集型”的应用,正常情况下应该占用更多的 %usr;
对于“IO密集型”的应用,正常情况下应该占用更多的 %system。
所以,如果你的应用程序是IO密集型的,比如是处理网络IO的程序,但是却 %usr过高导致cpu过高,那么这个时候需要关注一下是不是应用程序写的有问题。
内存信息:
VSZ:该线程使用的虚拟内存(以KB为单位);
RSS:该线程使用的物理内存(以KB为单位);
%MEM:当前任务使用的有效内存的百分比;
磁盘信息:
kB_rd/s:每秒此进程从磁盘读取的字节数(kB/s);
kB_wr/s:每秒此进程已经或者将要写入磁盘的字节数(kB/s)
kB_ccwr/s:由任务取消的写入磁盘的字节数(kB/s)。
4. 关于内存的命令:
4.1 free:内存
free命令用于显示系统内存的使用情况,包括总体内存、已经使用的内存;还可用于显示系统内核使用的缓冲区,包括缓冲(buffer)和缓存(cache)等。
root@virtual-machine:/# free
总计 已用 空闲 共享 缓冲/缓存 可用
内存: 4000136 3200592 126500 41356 673044 500884
交换: 945464 945464 0
5. 关于CPU使用情况的命令:
5.1 vmstat:
vmstat命令用于显示关于内核线程、虚拟内存、磁盘I/O、陷阱和CPU占用率的统计信息。
root@virtual-machine:/# vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b 交换 空闲 缓冲 缓存 si so bi bo in cs us sy id wa st
1 0 945464 122688 13800 659896 1 3 133 65 5 20 3 2 95 0 0
cs: 表示线程环境的切换次数,此数据如果太大时表明线程的同步机制有问题;(图中cs值为20)
si和so较大时,说明系统频繁使用交换区,应该查看操作系统的内存是否够用
6. 关于磁盘I/O的监控命令:
6.1 iostat:IO状态
iostat命令用于监控CPU占用率、平均负载值和I/O读写速度等。
root@virtual-machine:/# iostat
Linux 5.8.0-53-generic (virtual-machine) 2021年10月07日 _x86_64_ (2 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
3.30 0.09 1.81 0.04 0.00 94.75
Device tps kB_read/s kB_wrtn/s kB_dscd/s kB_read kB_wrtn kB_dscd
loop0 0.02 0.55 0.00 0.00 204205 0 0
loop1 0.01 0.03 0.00 0.00 10397 0 0
loop10 0.00 0.01 0.00 0.00 3264 0 0
loop11 0.22 13.99 0.00 0.00 5177743 0 0
loop12 0.00 0.01 0.00 0.00 4109 0 0
loop13 0.00 0.05 0.00 0.00 17772 0 0
loop14 0.00 0.01 0.00 0.00 3933 0 0
loop15 0.00 0.01 0.00 0.00 3248 0 0
loop16 0.00 0.01 0.00 0.00 2415 0 0
loop17 0.00 0.00 0.00 0.00 1203 0 0
loop18 0.00 0.00 0.00 0.00 14 0 0
loop2 0.01 0.03 0.00 0.00 12149 0 0
loop3 0.01 0.18 0.00 0.00 66360 0 0
loop4 0.03 0.62 0.00 0.00 227688 0 0
loop5 0.00 0.01 0.00 0.00 3668 0 0
loop6 0.04 0.35 0.00 0.00 129844 0 0
loop7 0.00 0.15 0.00 0.00 55638 0 0
loop8 0.02 0.04 0.00 0.00 13506 0 0
loop9 0.03 1.21 0.00 0.00 448455 0 0
sda 7.09 247.27 129.15 0.00 91507211 47796127 0
scd0 0.00 0.00 0.00 0.00 4 0 0
//cpu的统计信息:(如果是多cpu系统,显示的所有cpu的平均统计信息)
%user: ⽤户进程消耗cpu的⽐例
%nice: ⽤户进程优先级调整消耗的cpu⽐例
%sys: 系统内核消耗的cpu⽐例
%iowait: 等待磁盘io所消耗的cpu⽐例
%idle: 闲置cpu的⽐例(不包括等待磁盘I/O)
//磁盘的统计参数:
tps: 该设备每秒的传输次数(Indicate the number of transfers per second that were issued to the device.)。"⼀次传输"意思是"⼀次I/O请求"。多个逻辑请求可能会被合并为"⼀次I/O请求"。"⼀次传输"请求的⼤⼩是未知的。
kB_read/s: 每秒从设备(drive expressed)读取的数据量;
kB_wrtn/s: 每秒向设备(drive expressed)写⼊的数据量;
kB_read: 读取的总数据量;
kB_wrtn: 写⼊的总数量数据量;这些单位都为Kilobytes
5.2 df:硬盘使用情况:
df命令用于查看文件系统的硬盘挂载点和空间使用情况。
root@virtual-machine:/# df
文件系统 1K-块 已用 可用 已用% 挂载点
udev 1970520 0 1970520 0% /dev
tmpfs 400016 3624 396392 1% /run
/dev/sda2 19993200 14781992 4172568 78% /
tmpfs 2000068 0 2000068 0% /dev/shm
tmpfs 5120 4 5116 1% /run/lock
tmpfs 2000068 0 2000068 0% /sys/fs/cgroup
/dev/loop1 224256 224256 0 100% /snap/gnome-3-34-1804/66
/dev/loop4 224256 224256 0 100% /snap/gnome-3-34-1804/72
/dev/loop6 52224 52224 0 100% /snap/snap-store/547
/dev/loop5 52352 52352 0 100% /snap/snap-store/518
/dev/loop8 66688 66688 0 100% /snap/gtk-common-themes/1515
/dev/sda1 523248 8036 515212 2% /boot/efi
tmpfs 400012 120 399892 1% /run/user/1000
/dev/loop10 56832 56832 0 100% /snap/core18/2074
/dev/loop12 56832 56832 0 100% /snap/core18/2128
/dev/loop16 101760 101760 0 100% /snap/core/11606
/dev/loop9 33152 33152 0 100% /snap/snapd/12883
/dev/loop0 213504 213504 0 100% /snap/code/74
/dev/loop13 33152 33152 0 100% /snap/snapd/13170
/dev/loop17 101760 101760 0 100% /snap/core/11743
/dev/loop11 128 128 0 100% /snap/bare/5
/dev/loop14 213504 213504 0 100% /snap/code/75
/dev/loop15 66816 66816 0 100% /snap/gtk-common-themes/1519
7. 查看网络信息和网络监控的命令:
7.1 ifconfig:网卡信息
ifconfig命令用于查看机器挂载的网卡情况。
其中lo是本地回绕。
root@virtual-machine:/# ifconfig
docker0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
inet6 fe80::42:29ff:fe65:1c1a prefixlen 64 scopeid 0x20<link>
ether 02:42:29:65:1c:1a txqueuelen 0 (以太网)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 10 bytes 1104 (1.1 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.16.5X.139 netmask 255.255.255.0 broadcast 172.16.5X.255
inet6 fe80::8798:75a4:862d:d083 prefixlen 64 scopeid 0x20<link>
ether 00:0c:29:3b:d5:f0 txqueuelen 1000 (以太网)
RX packets 2192604 bytes 2726506782 (2.7 GB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 653905 bytes 83491630 (83.4 MB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10<host>
loop txqueuelen 1000 (本地环回)
RX packets 5533524 bytes 508807570 (508.8 MB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 5533524 bytes 508807570 (508.8 MB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
7.2 ping:检查网络连接
ping命令是用检测网络故障的常用命令,可以用来测试一台主机到另外一台主机的网络是否连通。
7.3 telnet:远程登录:
telnet 是TCP/IP协议族的一员,是网络远程登录服务器的标准协议,帮助用户在本地计算机上连接远程主机。
telnet与ssh的区别:
本质区别:telnet是明文传输,ssh是加密传输;
端口区别:telnet使用端口 23,ssh使用端口 22。
7.4 netstat:网络连接端口信息:
netstat命令用于显示网络连接、端口信息等。
主要能查看到的信息包括: ① 端口状态(TCP的11个状态)、② 某条连接上的本端和对端的IP/端口信息、③ 某条连接上的发送队列/接收队列中的缓存报文信息(Recv-Q/Send-Q)。
常用参数:
`-t`: tcp
`-u`: udp
`-l`: listening //监听态
`-a`: all //所有的
`-n`: numeric //不要显示主机名,而是显示IP地址
`-c`: continuous //动态刷新,一秒一次
`-p`: program //显示占用端口的主机程序名,如redis
netstat -a:显示所有:
注意其中显示的是localhost主机名,使用-n则可以转为IP地址127.0.0.1。
root@virtual-machine:/# netstat -a
激活Internet连接 (服务器和已建立连接的)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 0.0.0.0:8700 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:microsoft-ds 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:8000 0.0.0.0:* LISTEN
tcp 0 0 localhost:33060 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:8100 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:10600 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:8200 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:8008 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:netbios-ssn 0.0.0.0:* LISTEN
tcp 0 0 localhost:6379 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:http 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:8400 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:http-alt 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:tproxy 0.0.0.0:* LISTEN
tcp 0 0 localhost:domain 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:ssh 0.0.0.0:* LISTEN
tcp 0 0 localhost:ipp 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:8600 0.0.0.0:* LISTEN
tcp 0 0 localhost:8601 0.0.0.0:* LISTEN
tcp 0 0 localhost:55934 localhost:mysql ESTABLISHED
tcp 0 0 localhost:36074 localhost:6379 ESTABLISHED
tcp 0 0 localhost:36072 localhost:6379 ESTABLISHED
tcp 0 0 localhost:55928 localhost:mysql ESTABLISHED
tcp 0 0 localhost:10600 localhost:59514 ESTABLISHED
tcp 0 0 localhost:59536 localhost:10600 ESTABLISHED
tcp 0 0 localhost:36060 localhost:6379 ESTABLISHED
使用方法:
- 根据进程ID或应用程序名称查找端口:
注意:此时必须使用参数-p,否则不显示进程ID或者程序名,也就无法使用grep进行过滤了
root@xuesong-virtual-machine:/# netstat -anp | grep redis
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36062 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36066 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36060 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36058 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36076 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36074 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36072 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36064 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36068 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36070 ESTABLISHED 6573/./redis-server
//或者:
root@xuesong-virtual-machine:/# netstat -anp | grep 6573
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36062 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36066 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36060 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36058 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36076 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36074 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36072 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36064 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36068 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36070 ESTABLISHED 6573/./redis-server
- 想要看看某个端口被哪个进程所占用,或者想要查看某个端口的当前TCP状态,使用netstat按照端口号进行过滤:
root@xuesong-virtual-machine:/# netstat -antp | grep 6379
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 6573/./redis-server
tcp 0 0 127.0.0.1:36074 127.0.0.1:6379 ESTABLISHED 7785/./db_proxy_ser
tcp 0 0 127.0.0.1:36072 127.0.0.1:6379 ESTABLISHED 7785/./db_proxy_ser
tcp 0 0 127.0.0.1:36060 127.0.0.1:6379 ESTABLISHED 7785/./db_proxy_ser
tcp 0 0 127.0.0.1:36062 127.0.0.1:6379 ESTABLISHED 7785/./db_proxy_ser
tcp 0 0 127.0.0.1:36068 127.0.0.1:6379 ESTABLISHED 7785/./db_proxy_ser
tcp 0 0 127.0.0.1:6379 127.0.0.1:36062 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36066 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36060 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:36066 127.0.0.1:6379 ESTABLISHED 7785/./db_proxy_ser
tcp 0 0 127.0.0.1:6379 127.0.0.1:36058 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36076 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:36070 127.0.0.1:6379 ESTABLISHED 7785/./db_proxy_ser
tcp 0 0 127.0.0.1:36064 127.0.0.1:6379 ESTABLISHED 7785/./db_proxy_ser
tcp 0 0 127.0.0.1:36058 127.0.0.1:6379 ESTABLISHED 7785/./db_proxy_ser
tcp 0 0 127.0.0.1:36076 127.0.0.1:6379 ESTABLISHED 7785/./db_proxy_ser
tcp 0 0 127.0.0.1:6379 127.0.0.1:36074 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36072 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36064 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36068 ESTABLISHED 6573/./redis-server
tcp 0 0 127.0.0.1:6379 127.0.0.1:36070 ESTABLISHED 6573/./redis-server
-p是一个很有用的参数,可以查看到对应某个端口的应用程序名称及进程ID。
7.5 tcpdump:网络抓包
tcpdump是网络状况分析和跟踪工具,是可以用来抓包的使用命令。 使用前需要对TCP/IP有所熟悉,因为过滤使用的信息是TCP/IP格式。
常用参数:
`-i`: interface 指定网卡
`-n`: Don't convert address to names 显示原始IP,不转换成主机名
//原语运算:
与: `&&` 或者 `and`
或: `||` 或者 `or`
非: `!` 或者 `not`
//例如:
src or dst portrange 6000-8000 && tcp
//限定词:
//1. Type:
host : IP地址
port : 端口
portrange : 设置端口范围
//2. Dir:
src
dst
src or dst
src and dst
//3. Proto:
ethr
feddi
tr
wlan
ip
ip6
arp
tcp
udp
//文件操作:
-w : 输出结果至文件
-C : 限制输出文件的大小,超出后,以后缀1等数字的方式递增,单位是 1,000,000 字节
-W : 指定输出文件的最大数量,超出后重写第一个文件
-r : 读取一个抓包文件
-V : 将待读取的多个文件名写入一个文件中,通过读取该文件同时读取多个文件
练习:
root@virtual-machine:/# tcpdump -n -i ens33 && tcp && src host 172.16.52.1 && src port 62557
21:04:54.605637 IP 172.16.52.1.62557 > 172.16.52.129.22: Flags [P.], seq 397:433, ack 645856, win 2048, options [nop,nop,TS val 287647214 ecr 3287211780], length 36
21:04:54.605740 IP 172.16.52.129.22 > 172.16.52.1.62557: Flags [P.], seq 646212:646568, ack 433, win 501, options [nop,nop,TS val 3287211781 ecr 287647214], length 356
......
3637 packets captured
3683 packets received by filter
46 packets dropped by kernel
9. Linux系统的高级工具:
9.1 pstack:查看进程的调用栈
pstack命令用来查看每个进程的调用栈,相当于是gdb的shell封装。使用方法是 pstack + 进程ID。
[root@VM_0_3_centos ~]# pstack 25901
Thread 2 (Thread 0x7f950fd02700 (LWP 25902)):
#0 0x00007f9514a1ff73 in select () from /usr/lib64/libc.so.6
#1 0x00007f95136b95a5 in apr_sleep () from /usr/lib64/libapr-1.so.0
#2 0x00007f9514645f19 in ?? ()
#3 0x0000000001186ec0 in ?? ()
#4 0x0000000001186ec0 in ?? ()
#5 0x00007f950fd01d60 in ?? ()
#6 0x00007f95146a3d9e in ?? ()
#7 0x0000000001184da0 in ?? ()
#8 0x0000000000000000 in ?? ()
Thread 1 (Thread 0x7f9515b348c0 (LWP 25901)):
#0 0x00007f9514a29483 in epoll_wait () from /usr/lib64/libc.so.6
#1 0x000000000048604f in CEventDispatch::StartDispatch (this=0x1195600,
wait_timeout=100) at /root/im/0voice_im/server/src/base/EventDispatch.cpp:365
#2 0x0000000000479ad2 in netlib_eventloop (wait_timeout=100) at
/root/im/0voice_im/server/src/base/netlib.cpp:160
#3 0x000000000046f598 in main (argc=1, argv=0x7ffc278e13a8) at
/root/im/0voice_im/server/src/login_server/login_server.cpp:132
9.2 strace:查看进程使用的系统调用
strace是Linux系统下的一款程序调试工具,用来监控一个应用程序所使用的系统调用,通过它可以跟踪系统调用,让你熟悉一个Linux程序在背后是怎么工作的。
使用举例:
root@xuesong-virtual-machine:/# ps -ef | grep redis
xuesong 6573 1379 0 10月03 ? 00:11:06 ./redis-server 127.0.0.1:6379
root 317750 313626 0 21:20 pts/4 00:00:00 grep --color=auto redis
root@xuesong-virtual-machine:/# strace -p 6573
strace: Process 6573 attached
read(3, 0x7fff9710b807, 1) = -1 EAGAIN (资源暂时不可用)
epoll_wait(5, [], 10128, 41) = 0
getpid() = 6573
openat(AT_FDCWD, "/proc/6573/stat", O_RDONLY) = 17
read(17, "6573 (redis-server) R 1379 6573 "..., 4096) = 345
close(17) = 0
read(3, 0x7fff9710b807, 1) = -1 EAGAIN (资源暂时不可用)
epoll_wait(5, [], 10128, 100) = 0
getpid() = 6573
openat(AT_FDCWD, "/proc/6573/stat", O_RDONLY) = 17
read(17, "6573 (redis-server) R 1379 6573 "..., 4096) = 345
close(17) = 0
read(3, 0x7fff9710b807, 1) = -1 EAGAIN (资源暂时不可用)
epoll_wait(5, [], 10128, 99) = 0
getpid() = 6573
......
9.3 proc:查看运行时的系统内核参数:
Linux系统内核提供了通过 /proc 文件系统查看运行时内核内部数据结构的能力,也可以改鬓内核参数设置。
例如:
//查看CPU信息:
cat /proc/cpuinfo
//查看内存信息:
cat /proc/meminfo
//查看磁盘映射信息:
cat /proc/mounts
10. 日志监控工具:
10.1 tail:
11. 性能监控工具:
11.1 pmap:
11.2 nmon:
11.3 glances:
12. 性能测试:
13. 性能测试sysbench:
14. iperf测试服务器带宽:
15. Linux性能分析:
15.1 CPU性能原理篇:
在进行服务端性能测试时,需要观察系统对CPU的使用情况,以此作为衡量整个系统性能的重要指标,对于Linux CPU主要的关注点在 利用率、运行队列、负载、上下文切换 等,因此了解这些指标的含义和常用的监控方法对性能测试有很大的帮助。
15.1.1 CPU使用率:
Linux CPU使⽤率主要是从以下⼏个维度进⾏统计:
%usr:普通进程在⽤户模下下执⾏的时间;
%sys:进程在内核模式下的执⾏时间;
%nice:被提⾼优先级的进程在⽤户模式下的执⾏时间;
%idle:空闲时间。
%iowait:等待I/O完成的时间。
%irp:处理硬中断请求花费的时间。
%soft:处理软中断请求花费的时间。
%steal:是衡量虚拟机CPU的指标,是指分配给本虚拟机的时间⽚被同⼀宿主机别的虚拟机占⽤,⼀
般%steal值较⾼时,说明宿主机的资源使⽤已达到瓶颈;
⼀般情况下,CPU⼤部分的时间⽚都是消耗在⽤户态和内核态上。
sys和user间的⽐例是相互影响的,%sys⽐例⾼意味着被测服务频繁的进⾏⽤户态和系统态之间的切换,
会带来⼀定的CPU开销,这样分配处理业务的时间⽚就会较少,造成系统性能的下降。对于IO密集型系
统,⽆论是⽹络IO还是磁盘IO,⼀般都会产⽣⼤量的中断,从⽽导致%sys相对升⾼,其中磁盘IO密集型系
统,对磁盘的读写需要占⽤⼤量的CPU,会导致%iowait的值⼀定⽐例的升⾼,所以当出现%iowait较⾼
时,需排查是否存在⼤量的不合理的⽇志操作,或者频繁的数据载⼊等情况;
CPU利⽤的详细情况可以通过top,vmstat命令进⾏查看
15.1.2 运行队列:
当Linux内核要寻找⼀个新的进程在CPU上运⾏时,必须只考虑处于可运⾏状态的进程,(即在
TASK_RUNNING状态的进程),因为扫描整个进程链表是相当低效的,所以引⼊了可运⾏状态进程的双
向循环链表,也叫运⾏队列(runqueue)。每个CPU或者说每个核都会维持⼀个运⾏队列,队列中存放
running和runnable两种状态的进程,CPU会不断的调度队列中的进程运⾏,因此队列中的进程数越多,
每个进程分别到的时间⽚就越少,程序的时间也就越⻓,同时CPU会不断的处于运⾏状态,性能开销较
⼤。可以通过观察⼀定时间内运⾏队列中的进程数量来判断CPU是否达到的瓶颈,这就有了负载的概念;
15.1.3 负载:
CPU的负载(Load),是指在⼀段时间内 CPU正在处理以及等待 CPU处理的进程数之和的统计信息,也
就是 CPU运⾏队列⻓度的统计信息。平均负载(Load Average)是指上⼀段时间内同时处于运⾏队列的
平均进程数,Load Average是反应系统压⼒的重要指标,Load Average越⾼说明对于CPU资源的竞争越
激烈,CPU资源⽐较短缺。对于资源的申请和维护其实也是需要很⼤的成本,所以在这种⾼Average
Load的情况下CPU资源的⻓期“热竞争”也是对于硬件的⼀种损害。
举个例⼦,把CPU处理进程的过程看成⽕⻋站售票:
假如售票处有10个窗⼝,买票的⼈只有1个,毫⽆疑问,这个乘客随便找个窗⼝买完票就可以拍屁股⾛
⼈了,⽽且还有9个售票⼈员可以喝茶看报纸,这时的平均负载是0.1,售票运作毫⽆压⼒;
如果买票的⼈有10个,那也还好,⼀个窗⼝⼀个⼈,所有窗⼝的售票⼈员都在⼯作,也可以快速的买到
票,这时的平均负载是1,所有的售票窗⼝都在运作;
如果有20个⼈在买票,这就要出现排队的情况,售票⼈员要不停的卖票,直到排队的都买到票,这时平
均负载是2,所有售票窗⼝都在运作,⽽且出现了排队情况;
如果是100,200⼈或者更多的⼈买票,这时售票⼈员就要不停的⼯作,为了不把售票⼈员累坏可能就要考
虑增加窗⼝,也就是扩容了。⽽实际CPU处理进程时并不是像售票⼀样卖完⼀个⼈下⼀个⼈,CPU处理每
个进程时是有固定的时间⽚,如果在时间⽚内这个任务没有处理完,就要挂起这个任务处理下⼀个,这是
就会产⽣中断,⾼负载的情况下会不断产⽣进程间的调⽤,从⽽产⽣⼤量中断,造成系统的开销,所以在
做性能测试时,要重点关注负载情况,来判读CPU是否达到了瓶颈,依据经验分析,单核CPU负载<2时,
系统性能是良好的,当单核CPU负载>5时,那么就表明这个机器存在严重的性能问题。
负载可以通过top,uptime、cat /proc/loadavg等命令查看1分钟,5分钟,15分钟的负载值:
15.1.4 上下文切换:
⼀个标准的Linux内核可以⽀持运⾏50~50000个进程运⾏,对于普通的CPU,内核会调度和执⾏这些进
程。每个进程都会分到CPU的时间⽚来运⾏,当⼀个进程⽤完时间⽚或者被更⾼优先级的进程抢占后,它
会备份到CPU的运⾏队列中,同时其他进程在CPU上运⾏。这个进程切换的过程被称作上下⽂切换。
Linux系统具有两个不同级别的运⾏模式,内核态和⽤户态,其中内核态的运⾏级别要⼤于⽤户态,这个级
别可以进⾏任何操作,⼀般内核运⾏与内核态,⽽应⽤程序是运⾏在⽤户态。当发⽣上下⽂切换时,通过
系统调⽤,处于⽤户态的应⽤程序就会进⼊内核空间,待调⽤完成之后重新返回值⽤户态运⾏,因此上下
⽂切换存在系统开销,会⼀定程度上增加%sys的值。
当⼀个进程在执⾏时,CPU的所有寄存器中的值、进程的状态以及堆栈中的内容被称为该进程的上下⽂。
当内核需要切换到另⼀个进程时,它需要保存当前进程的所有状态,即保存当前进程的上下⽂,以便在再
次执⾏该进程时,能够必得到切换时的状态执⾏下去。在LINUX中,当前进程上下⽂均保存在进程的任务
数据结构中。在发⽣中断时,内核就在被中断进程的上下⽂中,在内核态下执⾏中断服务例程。但同时会保
留所有需要⽤到的资源,以便中断服务结束时能恢复被中断进程的执⾏。
引起上下⽂切换的原因有哪些? 对于抢占式操作系统⽽⾔, ⼤体有⼏种:
- 当前任务的时间⽚⽤完之后,系统CPU正常调度下⼀个任务;
- 当前任务碰到IO阻塞,调度线程将挂起此任务,继续下⼀个任务;
- 多个任务抢占锁资源,当前任务没有抢到,被调度器挂起,继续下⼀个任务;
- ⽤户代码挂起当前任务,让出CPU时间;
- 硬件中断;
vmstat中的cs为中断数量
15.1.6 中断:
中断是指CPU执⾏程序时,由于发⽣了某种随机的事件(外部或内部),引起CPU暂时中断正在运⾏的程
序,转去执⾏⼀段特殊的服务程序(称为中断服务程序或中断处理程序),以处理该事件,该事件处理完后⼜
返回被中断的程序继续执⾏。引⼊中断的原因有以下⼏点:
- 提⾼数据传输率;
- 避免了CPU不断检测外设状态的过程,提⾼了CPU的利⽤率。
- 实现对特殊事件的实时响应。如多任务系统操作系统中缺⻚中断、设备中断、各类异常、实时钟等
中断根据中断源的不同可以分为硬中断和软中断:
硬中断: 硬中断⼜称外部中断,是由硬件产⽣,如键盘,⿏标,打印机等。每个设备或设备集都有它
⾃⼰的中断请求(IRQ),基于IRQ,CPU可以将相应的请求分发到对应的硬件驱动上,处理中断的驱
动是需要在CPU上运⾏的,因此中断产⽣时,CPU会中断当前正在运⾏的任务来处理中断,在多核的
操作系统中,⼀个中断通常只能中断⼀颗CPU(核)。
软中断: 软中断⼜称内部中断,由软件系统本身发给操作系统内核的中断信号。通常是由硬中断处理
程序或进程调度程序对操作系统内核的中断,也就是我们常说的系统调⽤(System Call)。⼀般情况下
软中断是处理I/O请求时发⽣订单,这些请求会调⽤内核中的处理I/O的程序,对于某些设备,I/O请求
需要被⽴即处理,⽽磁盘I/O请求通常可以排队并且可以稍后处理。根据I/O模型的不同,进程或许会被
挂起直到I/O完成,此时内核调度器就会选择另⼀个进程去运⾏。I/O可以在进程之间产⽣并且调度过程
通常和磁盘I/O的⽅式是相同。在I/O密集型系统中可能会出现⼤量的中断请求,中断会产⽣中断上下
⽂,造成CPU开。
可以通过top,vmstat等查看CPU的相关命令中监控中断情况
15.1.7 负载与CPU利用率的关系:
负载和CPU利⽤率都是衡量CPU性能的指标,那么CPU利⽤率⾼的话负载⼀定⾼吗?要回答这个问题⾸先
要CPU资源在什么情况下会被消耗,CPU利⽤率其实是指为了处理进程抢占CPU时间⽚的⽐例,也就是只
有处于运⾏状态的进程才会获得时间⽚,从⽽造成CPU利⽤率的上升,⽽所需CPU时间⽚的多少取决于进
程中需要CPU运算逻辑的复杂程度。⽽负载是指运⾏队列中等待和运⾏的进程数的总和,在负载很⾼时,
可能是出于等待运⾏的进程数较多,这些进⾏并不会占⽤过多的时间⽚,队列中进程消耗的CPU资源也有
可能只是集中在某⼏个对CPU运算依赖较⾼的⼏个进程上。所以CPU利⽤率和负载之间并没有硬性的⽐例
关联关系,衡量CPU性能时要同时关注两个性能指标,综合考虑。
15.2 遇到CPU利用率高该如何排查:
遇到CPU使⽤率⾼时,⾸先确认CPU是消耗在哪⼀块,如果是内核态占⽤CPU较⾼:
- %iowait ⾼,这时要重点关注磁盘IO的相关操作,是否存在不合理的写⽇志操作,数据库操作等;
- %soft或%cs ⾼,观察CPU负载是否较⾼、⽹卡流量是否较⼤,可不可以精简数据、代码在是否在多
线程操作上存在不合适的中断操作等; - %steal ⾼,这种情况⼀般发⽣在虚拟机上,这时要查看宿主机是否资源超限;
如果是⽤户态较⾼,且没有达到预期的性能,说明应⽤程序需要优化。
15.2.1 根据指标查找工具:
15.2.2 如何迅速的分析CPU性能瓶颈:
15.2.3 性能优化方法论:
15.2.4 性能指标总结:
关于CPU的经验指标,可以作为参考:
- 对于每一个CPU来说,运行队列不要超过2,例如,如果是双核CPU,就不要超过4;
- 如果CPU在满负荷运行,应该符合下列分布:
① %usr time: 65%~70%,如果高于此数值,可以考虑对应用程序进行优化;
② %system time:30%~35%,如果高于此数值,观察是否有过多的中断或者上下文切换;
③ %idle:0%~5% - 对于上下文切换,要结合CPU使用率来看,如果CPU使用满足上述分布,大量的上下文切换也是可以接受的。