刘二大人《PyTorch深度学习实践》
刘二大人《PyTorch深度学习实践》笔记
- 线性模型
- 梯度下降
- 反向传播
- 用pytorch实现线性回归
- 零碎
-
- Dataset和Dataloader
- 多维输出
- 简单卷积神经网络
- 一个epoch
- Softmax分类器
- 卷积
- Inception
- ResNet
- RNN
线性模型
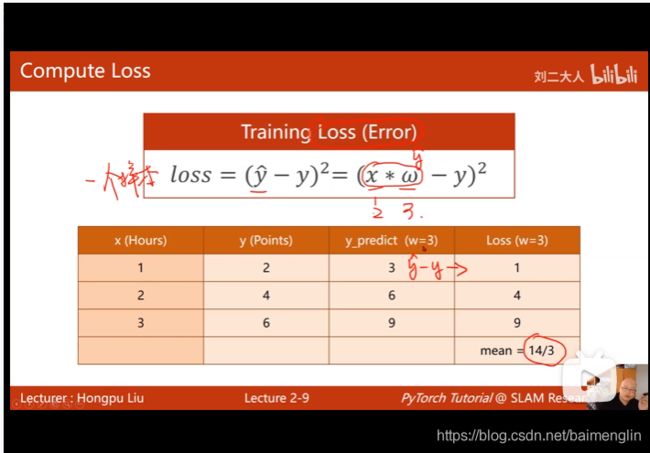
损失函数是针对一个样本的
training set得到的是一个平均平方误差MSE
穷举法绘制损失曲线:numpy和matplotlib
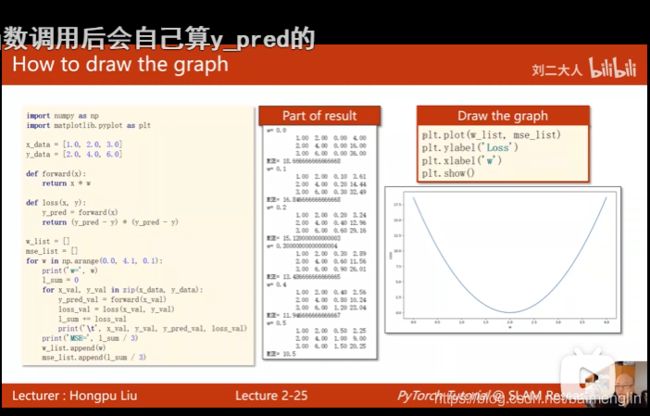
import numpy as np
import matplotlib.pyplot as plt
#数据集
x_data = [1.0,2.0,3.0]
y_data = [2.0,4.0,6.0]
#定义模型
def forward(x):
return x * w
#定义损失函数
def loss(x,y):
y_pred = forward(x)
return (y_pred-y) * (y_pred-y)
#存放权重和权重损失值对应的列表
w_list = []
mse_list = []
#w取值为0-4,间隔为0.1
for w in np.arange(0.0,4.1,0.1):
print("w=",w)
l_sum = 0
# 把数据集里的数据取出来拼成x_val和y_val
for x_val,y_val in zip(x_data,y_data):
y_pred_val = forward(x_val)
loss_val = loss(x_val, y_val)
l_sum += loss_val#先求和
print('\t',x_val,y_val,y_pred_val,loss_val)
print("MSE=",l_sum/3)#取平均
w_list.append(w)
mse_list.append(l_sum/3)
plt.plot(w_list, mse_list)
plt.ylabel('Loss')
plt.xlabel('w')
plt.show()
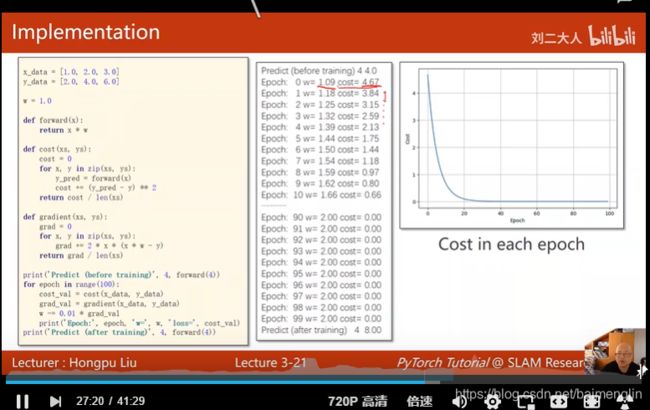
梯度下降
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = 1.0
def forward(x):
return x * w
def cost(xs, ys):
cost = 0
for x, y in zip(xs, ys):
y_pred = forward(x)
cost += (y_pred - y) ** 2
return cost / len(xs)
def gradient(xs, ys):
grad = 0
for x, y in zip(xs, ys):
grad += 2 * x * (x * w - y) # 求导的导数公式
return grad / len(xs)
print('predict (before training)', 4, forward(4))
for epoch in range(100):
cost_val = cost(x_data, y_data)
grad_val = gradient(x_data, y_data)
w -= 0.01 * grad_val
print('epoch:', epoch, 'w=', w, 'loss=', cost_val)
print('predict (after training)', 4, forward(4))
随机梯度下降:取一个损失更新(以前是平均全部损失)(一加入了噪声,二大样本计算量大)
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = 1.0
def forward(x):
return x * w
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
def gradient(x, y):
return 2 * x * (x * w - y)
print('predict (before training)', 4, forward(4))
for epoch in range(100):
for x, y in zip(x_data, y_data):
grad = gradient(x, y)
w -= 0.01 * grad # 对每一个样本及时更新,没办法并行运算,batch
print('\tgrad:', x, y, grad)
l = loss(x, y)#计算现在的损失
print("progress:", epoch, "w=", w, "loss", l)
print('predict (after training)', 4, forward(4))
反向传播
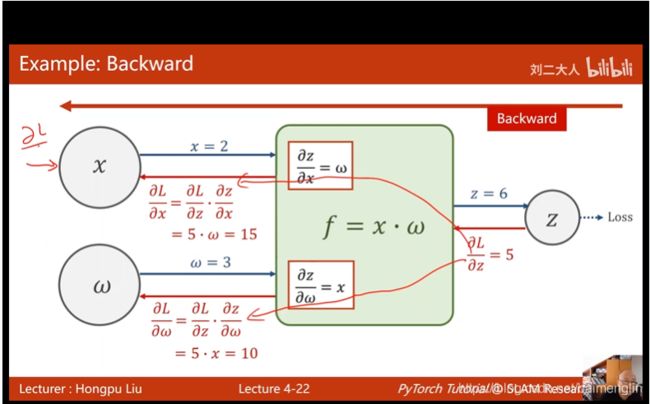
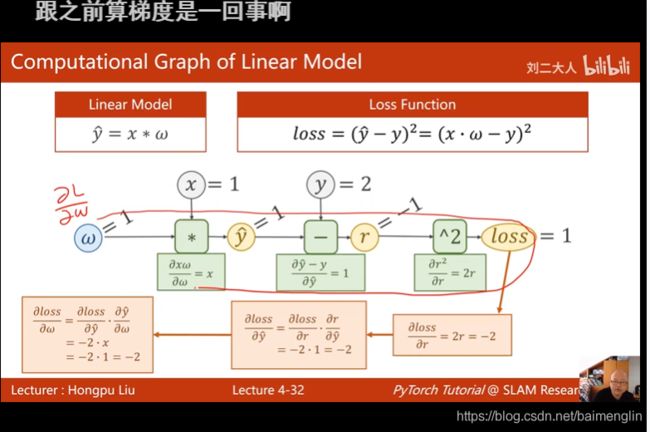
import torch
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = torch.Tensor([1.0])
w.requires_grad = True # 需要计算梯度
def forward(x):
return x * w # tensor
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2#写代码先画计算图
#训练过程
print('predict (before training)', 4, forward(4).item())
for epoch in range(100):
for x, y in zip(x_data, y_data):
l = loss(x, y) # 前向,计算loss
l.backward() # 做完后计算图会释放,再做loss计算,会创建一个新的计算图
print('\tgrad:', x, y, w.grad.item()) # 获取梯度,item取值,要是张量,就是计算图一直累积
w.data -= 0.01 * w.grad.data # 不取data,会是TENSOR有计算图,纯数值的计算
w.grad.data.zero_() # 计算出来的梯度不清零会累加
print("progress:", epoch, l.item())
print('predict (after training)', 4, forward(4).item())
l.item()可以把损失值取出来,sum+=l.item()
w是Tensor(张量类型),Tensor中包含data和grad,data和grad也是Tensorl。grad初始为None,调用l.backward()方法后w.grad为Tensor,故更新w.data时需使用w.grad.data。如果w需要计算梯度,那构建的计算图中,跟w相关的tensor都默认需要计算梯度。
每一次epoch的训练过程,总结就是
①前向传播,求y hat (输入的预测值)
②根据y_hat和y_label(y_data)计算loss
③反向传播 backward (计算梯度)
④根据梯度,更新参数
Tensor和tensor的区别点这里
用pytorch实现线性回归
数据集准备、设计模型、构造损失函数和优化器、训练周期(前馈反馈更新)
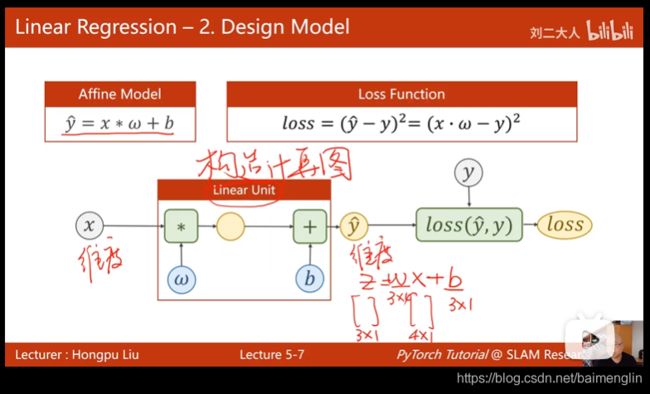
import torch
# prepare dataset
# x,y是矩阵,3行1列 也就是说总共有3个数据,每个数据只有1个特征
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])
#design model using class
"""
our model class should be inherit from nn.Module, which is base class for all neural network modules.
member methods __init__() and forward() have to be implemented
class nn.linear contain two member Tensors: weight and bias
class nn.Linear has implemented the magic method __call__(),which enable the instance of the class can
be called just like a function.Normally the forward() will be called
"""
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel, self).__init__()#调用父类的init
# (1,1)是指输入x和输出y的特征维度,这里数据集中的x和y的特征都是1维的
# 该线性层需要学习的参数是w和b 获取w/b的方式分别是~linear.weight/linear.bias
self.linear = torch.nn.Linear(1, 1)#类后+括号,构造对象
def forward(self, x):
y_pred = self.linear(x)
return y_pred
model = LinearModel()
# construct loss and optimizer
# criterion = torch.nn.MSELoss(size_average = False)
criterion = torch.nn.MSELoss(reduction = 'sum')
optimizer = torch.optim.SGD(model.parameters(), lr = 0.01) # model.parameters()自动完成参数的初始化操作
# training cycle forward, backward, update
for epoch in range(100):
y_pred = model(x_data) # forward:predict
loss = criterion(y_pred, y_data) # forward: loss
print(epoch, loss.item())
optimizer.zero_grad() # the grad computer by .backward() will be accumulated. so before backward, remember set the grad to zero
loss.backward() # backward: autograd,自动计算梯度
optimizer.step() # update 参数,即更新w和b的值
print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)
零碎
Dataset和Dataloader
Dataset和DataLoader是加载数据的两个工具类。Dataset:构造数据集(数据集应该支持索引,能够用下标操作快速把数据拿出来)DataLoader:主要目标是拿出一个MiniBatch(一组数据)供我们训练的时候快速使用。


Dataset是抽象类,不能实例化,只能被子类继承,DataLoader这个类用来加载数据,自动完成shuffle,batch-size,在构造数据集的时候有两种选择:
一:把所有的数据从__init__加载进来,都读到内存里面,每一次使用getitem的时候,把构造好的数据集比如矩阵,张量,把其中第i个样本传出去(这种方法适合于数据集本身不大,不如几十个G的图像就不适用了)。
二:初始化只在列表里面存文件名,然后getitem根据索引取文件里面找相应文件。
多维输出
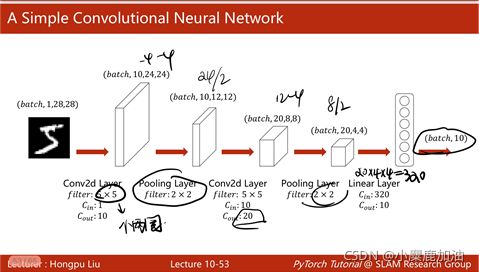
简单卷积神经网络
一个epoch
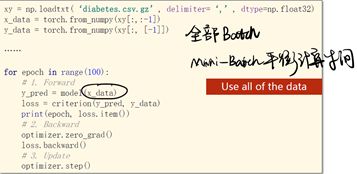
在上面的代码中,训练时,每次给Model做前馈的时候都是把所有的数据(x_data)传进去的
在做梯度下降的时候有两种选择:①全部的数据都用(Batch)。②随机梯度下降:只用一个样本。
只用一个样本可以得到比较好的随机性,可以帮助我们跨越在优化中所遇到的鞍点,而用Batch(所有数据)的优点是可以最大化地利用向量计算的优势提升计算速度,都用一个样本的随机梯度下降训练出的模型效果可能会比其他模型都更好,但是会导致优化用的时间更长,因为每次一个样本没法使用cpu或gpu的并行能力,训练的时间会很长,而使用Batch计算速度快,但是在求得性能上会遇到一些问题,所以在深度学习中我们使用Mini-Batch来平衡训练时间和训练速度上的要求。
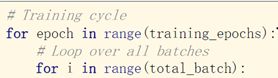
使用Mini-Batch之后训练循环要写成嵌套循环最外层循环每一次循环是一个Epoch,Epoch里面每一次循环执行一个Mini-Batch。
Epoch:所有样本都参与了训练,Epoch表示一个训练周期,所有的样本都进行了正向传播和反向传播。Batch-size:批量大小,每次训练所用的样本数量,进行一次前馈,一次反馈,一次更新用的样本数量,Iteration:表示Batch分出来多少个MiniBatch,如果有10000个样本,每个batch-size是1000,那么迭代次数Iteration=10000/1000=10。
Softmax分类器
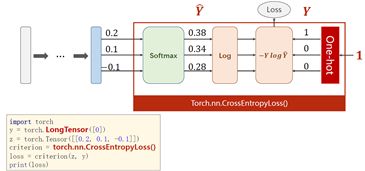
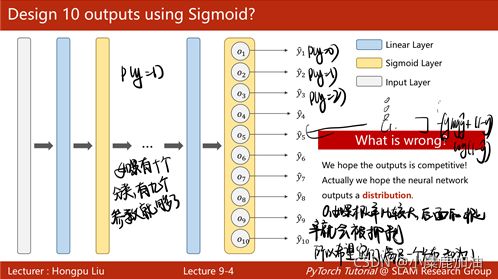
Softmax分类器:①Softmax的输入不需要再做非线性变换,也就是说Softmax之前不再需要激活函数(relu)。Softmax两个作用,如果在进行Softmax前的input有负数,通过指数变换,得到正数。所有类的概率求和为1。②y的标签编码方式是one-hot。我对one-hot的理解是只有一位是1,其他位为0。(但是标签的one-hot编码是算法完成的,算法的输入仍为原始标签) ③多分类问题,标签y的类型是LongTensor。比如说0-9分类问题,如果y = torch.LongTensor,对应的one-hot是[0,0,0,1,0,0,0,0,0,0].(这里要注意,如果使用了one-hot,标签y的类型是LongTensor,糖尿病数据集中的target的类型是FloatTensor) ④CrossEntropyLoss<==>LogSoftmax + NLLLoss。也就是说使用CrossEntropyLoss最后一层(线性层)是不需要做其他变化的;使用NLLLoss之前,需要对最后一层(线性层)先进行SoftMax处理,再进行log操作。
from torchvision import datasets,该datasets里面init,getitem,len魔法函数已实现。
卷积
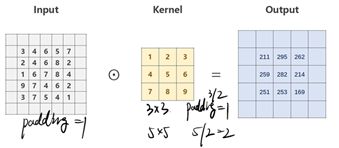
如果卷积核是33,3/2=1,在原矩阵外补1圈0 padding=1,如果卷积核是55,5/2=2,在原矩阵外补2圈0 padding=2。
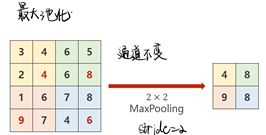
下采样用的比较多的是MaxPooling(最大池化层),是没有权重的,22的maxpooling默认stride=2,就是把图像分成22的一个组,在每个组里面找最大值,所以做maxpooling的时候只能把一个通道拿出来做maxpooling,通道之间不会去找最大值,所以在做最大池化(maxpooling)的时候,通道数量不会发生改变,但是如果用2*2的maxpooling,图像大小会缩成原来的一半。
如果装的是支持cuda版本的pyTorch,available就是True,默认是cuda 0,只有cpu就是false,如果有多个显卡,不同的任务可以使用不同的显卡。model.to(device)把整个模型的参数,缓存,所有的模块都放到cuda里面,转成cuda tensor。
计算的时候要把用来计算的张量也迁移到GPU,主要是输入和对应的输出,把inputs和target都迁移到device上,注意迁移的device和模型的device要在同一块显卡上,比如把模型放在第0块显卡,数据放在第一块显卡,是没法工作的。
inputs, target = inputs.to(device), target.to(device)
Inception
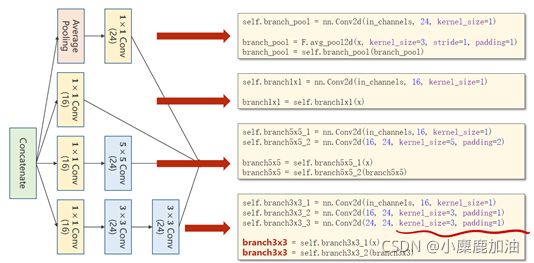

说明:以下是这个inception的代码, 1,2,3,4代表图中的4个通道
1、卷积核超参数选择困难,自动找到卷积的最佳组合。
2、1x1卷积核,不同通道的信息融合。使用1x1卷积核虽然参数量增加了,但是能够显著的降低计算量(operations)。
3、Inception Moudel由4个分支组成,要分清哪些是在Init里定义,哪些是在forward里调用。4个分支在dim=1(channels)上进行concatenate,24+16+24+24 = 88。
梯度消失:因为做的是反向传播,所以要用链式法则把一连串的梯度乘起来,假如每一处的梯度都小于1,不断乘以小于1的值,这个值就会越来越小,趋近于0,w=w-ag;当梯度(g)趋近于0,权重就得不到更新,这里输入比较近的这一块没办法得到充分的训练。
解决方法:逐层训练,Residual net。
ResNet

Dense网络:稠密网络,有很多线性层对输入数据进行空间上的变换,又叫DNN,输入x1,x2…xn是数据样本的不同特征,Dense连接就是指全连接,比如预测天天气,就需要知道之前几天的数据,每一天的数据都包含若个特征,需要若干天的数据作为输入。用全连接稠密网络进行预测,如果输入序列很长,而且每一个序列维度很高的话,对网络训练有很大挑战,因为稠密网络(全连接网络)实际上权重是最多的。
对于卷积层:比如输入通道是128个,输出通道是64个,如果用55的卷积。权重数就是2564188=204800,卷积层的输入输出只与通道数和卷积核的大小有关,全连接层和变换之后的数据大小有关,比如3阶张量经过一系列的卷积变换还剩下4096个元素,4096我们很少直接降成1维或者10维,而是先降成1024维,40961024=4194304,所以相比起来,卷积层的权重并不多,而全连接层的权重较多。在网络的全部参数中,全连接层是占大头的。
RNN
卷积神经网络的权重比较少是因为使用了权重共享的概念,做卷积时,整个图像的卷积核是共享的,并不是图像上的每一个像素要和下一层的featureMap建立连接,权重数量就少。
处理视频的时候,每一帧就少一张图像,我们需要把一组图像做成一个集合,如果用全连接网络的话,使用到的权重的数量就是一个天文数字,难以处理。
RNN专门用来处理带有序列模式的数据,也使用权重共享减少需要训练的权重的数量,我们把x1,x2,x3,xn看成是一个序列,不仅考虑x1,x2之间的连接关系,还考虑x1,x2的时间上的先后顺序,x2依赖于x1,x3依赖于x2,下一天的天气状况部分依赖于前一天的天气状况,RNN主要处理这种具有序列连接的。
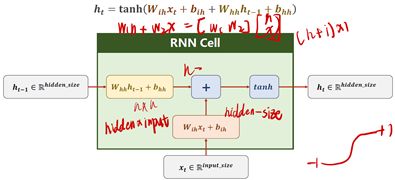
RNN Cell本质是一个线性层(linear),把一个维度映射到另一个维度(比如把输入的3维向量xt变成输出5维向量ht)。
具体的计算过程:
输入xt先做线性变换,h t-1也是,xt的维度是input_size,h t-1的维度是hidden_size,输出ht的维度是hidden_size,我们需要先把xt的维度变成hidden_size,所以Wih应该是一个hidden_sizeinput_size的矩阵,Wihxt得到一个 hidden_size1的矩阵(就是维度为hidden_size的向量),bih是偏置。输入权重矩阵Whh是一个hidden_sizehidden_size的矩阵。
whhHt-1+bhh和WihXt+bih都是维度为hidden_size的向量,两个向量相加,就把信息融合起来了,融合之后用tanh做激活,循环神经网络的激活函数用的是tanh,因为tanh的取值在-1到+1之间,算出结果得到隐藏层输出ht。
PyTorch里面构造RNN的两种方式:
①自己构建Cell,需要设定输入的值input_size,和隐层的值hidden_size,就能确定权重W的维度和偏置b的维度:
cell = torch.nn.RNNCell(input_size=input_size, hidden_size=hidden_size)
hidden = cell(input, hidden)#实例化Cell之后,我们需要给定当前的输入input以及当前的hidden,所以需要用循环来处理。
Hello -->ohlol
首先需要将输入的单词转成向量one-hot vector
注意input_size,如下图

one-hotvector
这里的hidden是([1, 4]), label是 ([1])。
②直接使用RNN
cell = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size,
num_layers=num_layers)#num_layers:RNN的层数
out, hidden = cell(inputs, hidden)
注:直接调用RNN这个不用循环,inputs维度是: (seqLen, batch_size, input_size),labels维度是: (seqLen * batch_size),outputs维度是: (seqLen, batch_size, hidden_size)。
为了能和labels做交叉熵,需要reshape一下: outputs.view(-1, hidden_size)。
如果初始化RNN时,把batch_first设置成了TRUE,那么inputs的参数batch_size和seq_len需要调换一下位置。