Java集合(容器)
集合
集合与数组一样,是一种容器。下面做个集合与数组的对比:
| 对比项 | 数组 | 集合 |
|---|---|---|
| 容量 | 容量不可变 | 容量可变 |
| 可存类型 | 基本数据类型 & 引用数据类型 | 引用数据类型 |
| 类型唯一 | 只能存放同一种类型 | 可存放不同类型(一般还是存放同一类型) |
Collection 接口

-
Collection 常用方法
创建Collection对象需要通过多态的形式,其根据 new 的实现类不同体现不同的特性:
List接口下实现类:[有序]、有下标、可重复
Set接口下实现类:[无序]、无下标、不可重复常用方法名 方法描述 boolean add(Object o) 添加一个对象到集合 boolean remove(Object o) 删除指定对象 void clear() 删除集合所有元素 boolean contains(Object o) 查询集合是否有 o 对象 int size() 返回此集合的元素个数 boolean isEmpty() 判断集合是否为空 boolean addAll(Collection c) 将一个集合的所有对象添加到本集合(可自己添加自己) boolean equals(Object o) 比较两个集合中元素是否相同 Object[ ] toArray() 将此集合转换成数组 Iterator iterator() 返回此集合中元素的迭代器。(重点方法) -
Iterator 迭代器
说明一下 Iterator 类,它是专为集合所准备的遍历器,其中包含3个主要方法:Iterator类的方法 方法描述 boolean hasNext() 判断迭代器中是否有下一个元素 E next() 返回迭代器中的下一个元素并前进光标位置 void remove() 集合中移除此迭代器返回的最后一个元素(必须先用next()方法才能使用此方法) -
Collection 方法使用
添加元素:public abstract class Demo1 { public static void main(String[] args) { Collection clc = new ArrayList(); //添加元素 clc.add("华为"); clc.add("苹果"); clc.add("小米"); clc.add("OPPO"); //查看集合元素个数 System.out.println("集合中有:"+clc.size()+"个元素"); System.out.println(clc); } } ---*--- 输出结果: 集合中有:4个元素 [华为, 苹果, 小米, OPPO]删除元素:
public abstract class Demo1 { public static void main(String[] args) { Collection clc = new ArrayList(); //添加元素 clc.add("华为"); clc.add("苹果"); clc.add("小米"); clc.add("OPPO"); //查看集合元素个数 System.out.println("集合中有:"+clc.size()+"个元素"); System.out.println(clc); //删除元素 clc.remove("小米"); System.out.println("集合中有:"+clc.size()+"个元素"); clc.clear(); System.out.println("集合中有:"+clc.size()+"个元素"); } } ---*--- 输出结果: 集合中有:4个元素 [华为, 苹果, 小米, OPPO] 集合中有:3个元素 集合中有:0个元素判断:
public abstract class Demo1 { public static void main(String[] args) { Collection clc = new ArrayList(); //添加元素 clc.add("华为"); clc.add("苹果"); clc.add("小米"); clc.add("OPPO"); //查看集合元素个数 System.out.println("集合中有:"+clc.size()+"个元素"); System.out.println(clc); //判断是否有此元素 System.out.println(clc.contains("小米")); //判断集合是否为空 System.out.println(clc.isEmpty()); } } ---*--- 输出结果: 集合中有:4个元素 [华为, 苹果, 小米, OPPO] true false遍历:
public abstract class Demo1 { public static void main(String[] args) { Collection clc = new ArrayList(); //添加元素 clc.add("华为"); clc.add("苹果"); clc.add("小米"); clc.add("OPPO"); //查看集合元素个数 System.out.println("集合中有:"+clc.size()+"个元素"); System.out.println(clc); //遍历元素 System.out.println("-----增强for遍历-----"); for (Object o: clc) { String s = (String)o; System.out.println(o); } System.out.println("-----Iterator遍历-----"); Iterator it = clc.iterator(); while (it.hasNext()){ String s = (String)it.next(); System.out.println(s); } } } ---*--- 输出结果: 集合中有:4个元素 [华为, 苹果, 小米, OPPO] -----增强for遍历----- 华为 苹果 小米 OPPO -----Iterator遍历----- 华为 苹果 小米 OPPO
List 接口
-
特点
List 接口继承 Collection 接口,特点是 List 有序、有下标、元素可重复。所以这里着重介绍 List 特有方法。 -
List方法
常用方法 方法描述 void add(int index,Object o) 在index位置插入对象O E remove(int index) 取走集合中指定位置元素 E set(int index, E element) 替换集合中指定位置元素 E get(int index) 返回集合中指定位置元素 boolean addAll(int index, Collection c) 将一个集合的所有对象添加到本集合指定位置 List subList(int fromIndex, int toIndex) 返回formIndex(包含)到toIndex(不包含)之间的元素集合 int indexOf(Object o) 返回集合中 o 元素的下标 ListIterator listIterator() 返回此列表中元素的列表迭代器(正反迭代) -
ListIterator 列表迭代器
ListIterator 类继承 Iterator,它是专为List集合所准备的遍历器,可以从反方向遍历集合。下面说一下其特有方法:ListIterator特有方法 方法描述 boolean hasPrevious() 判断当前光标的上一个位置是否有元素 E Previous() 返回当前光标的上一个位置元素并后移动光标位置 void add(E e) 将指定的元素插入集合 void set(E e) 用指定的元素替换 next()或 previous()返回的最后一个元素 int nextIndex() 返回当前光标位置数值 int previousIndex() 返回当前光标位置的上一个数值 -
List 方法使用
通过下标插入元素:
public class Demo { public static void main(String[] args) { List list = new ArrayList(); list.add("苹果"); list.add("华为"); list.add(0,"小米");//通过下标添加元素 System.out.println("集合元素个数为:"+list.size()); System.out.println(list); } } ---*--- 输出结果: 集合元素个数为:3 [小米, 苹果, 华为]通过下标删除元素:
public class Demo { public static void main(String[] args) { List list = new ArrayList(); list.add("苹果"); list.add("华为"); list.add(0,"小米"); System.out.println("删除前集合元素个数为:"+list.size()); System.out.println("删除的元素是:"+list.remove(1));//通过下标删除元素 System.out.println("删除后集合元素个数为:"+list.size()); System.out.println(list); } } ---*--- 输出结果: 删除前集合元素个数为:3 删除的元素是:苹果 删除后集合元素个数为:2 [小米, 华为]通过下标替换元素:
public class Demo { public static void main(String[] args) { List list = new ArrayList(); list.add("苹果"); list.add("华为"); list.add(0,"小米"); System.out.println("替换掉的元素是:"+list.set(1, "中兴"));//替换元素 System.out.println("集合元素个数为:"+list.size()); System.out.println(list); } } ---*--- 输出结果: 替换掉的元素是:苹果 集合元素个数为:3 [小米, 中兴, 华为]遍历:
public class Demo { public static void main(String[] args) { List list = new ArrayList(); list.add("苹果"); list.add("华为"); list.add(0,"小米"); System.out.println(list); System.out.println("----for遍历集合----"); for (int i = 0; i < list.size(); i++) { String s = (String)list.get(i); System.out.println(s); } System.out.println("----增强for遍历集合----"); for (Object o:list) { String s = (String) o; System.out.println(s); } System.out.println("----Iterator遍历集合----"); Iterator it = list.iterator(); while(it.hasNext()){ String s = (String) it.next(); System.out.println(s); } System.out.println("----ListIterator遍历集合----"); ListIterator listit = list.listIterator(); while (listit.hasNext()){ String s = (String) listit.next(); System.out.println(s); } while (listit.hasPrevious()){ String s = (String)listit.previous(); System.out.println(s); } } } ---*--- 输出结果: [小米, 苹果, 华为] ----for遍历集合---- 小米 苹果 华为 ----增强for遍历集合---- 小米 苹果 华为 ----Iterator遍历集合---- 小米 苹果 华为 ----ListIterator遍历集合---- 小米 苹果 华为 华为 苹果 小米补充:增删基本数据类型
public class Demo { public static void main(String[] args) { List list = new ArrayList(); //添加数字自动装箱 list.add(10); list.add(20); list.add(30); list.add(40); list.add(50); System.out.println(list); //删除操作 // list.remove(20); remove方法默认以下标删除 list.remove((Object) 20); list.remove(Integer.valueOf(20)); System.out.println(list); } } ---*--- 输出结果: [10, 20, 30, 40, 50] [10, 30, 40, 50]
ArrayList & LinkedList & Vector 类
ArrayList 、LinkedList 和 Vector 都实现了 List 接口( List 接口有一个 AbstractList 抽象类用来重写通用方法),所以它们的使用方法也基本是相同的。下面说一下区别:
| 类名 | 存储结构 | 适用场景 | 线程安全 |
|---|---|---|---|
| ArrayList | 数组结构 | 查询快、增删慢 | X |
| LinkedList | 链表结构 | 查询慢、增删快 | X |
| Vector | 数组结构 | 查询快、增删慢 | √ |
Set 接口
-
特点
Set 接口继承 Collection 接口,特点是 Set [无序]、无下标、元素不重复。Set集合没有特有方法,全继承自 Collection 接口。其根据 new 的实现类不同体现不同的特性:- HashSet:无序、无下标、不重复
- LinkedHashSet:有序、无下标、不重复
- TreeSet:定制排序、无下标、不重复
-
元素不重复原理
在 HashSet 对象添加元素时会进行以下两次判断:- 根据元素的哈希值确定存放位置,如果该位置没有元素则直接存入,如果该位置有元素先进行哈希值对比。
- 哈希值不同,将元素存入集合。哈希值相同再调用equals进行确认,如结果为true,则拒绝元素存入集合。
-
啥是哈希值
1.哈希值是JDK根据对象的 地址或字符串或数字 算出来的 int类型的数值。
2.因为 Object 类中有一个 hashCode() 方法,该方法返回对象的哈希码值。所以任何对象都有哈希码值。//学生类 class Student { private String name; private int age; public Student(String name ,int age) { this.name = name; this.age = age; } } //测试类 public class Demo { public static void main(String[] args) { Student s1 = new Student("赵子龙",27); Student s2 = new Student("张翼德",33); System.out.println("s1的哈希值为:"+s1.hashCode()); System.out.println("s1的哈希值为:"+s1.hashCode()); System.out.println("s2的哈希值为:"+s2.hashCode()); } } ---*--- 输出结果: s1的哈希值为:1239731077 s1的哈希值为:1239731077 s2的哈希值为:557041912可以看出,同一个对象的哈希码值是不变的。不同对象的哈希码值是不同的。(重写hashCode方法可以让同类型不同对象的哈希值相同)
-
重写 hashCode 方法和 equals 方法
默认情况下同一个类的不同对象的哈希值是不同的。实际中我们希望一个类的多个对象属性不同时才视为不同元素。
重写 hashCode 方法:为了让属性个数和值相同的对象,哈希值相同。(注意:这里不同类型的属性个数和值相同,哈希值也会相同)
重写 equals 方法:为了判对象是否是同一类型。//学生类 class Student { private String name; private int age; public Student(String name ,int age) { this.name = name; this.age = age; } //重写equals方法 @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Student student = (Student) o; return age == student.age && Objects.equals(name, student.name); } //重写hashCode方法 @Override public int hashCode() { return Objects.hash(name, age); } } //测试类 public class Demo { public static void main(String[] args) { HashSet<Student> hs = new HashSet<>(); Student s1 = new Student("赵子龙",27); Student s2 = new Student("张翼德",33); Student s3 = new Student("张翼德",33); hs.add(s1);//成功添加 hs.add(s2);//成功添加 hs.add(s3); hs.add(s1); System.out.println("集合元素个数:"+hs.size()); System.out.println("s1的哈希值为:"+s1.hashCode()); System.out.println("s2的哈希值为:"+s2.hashCode()); System.out.println("s3的哈希值为:"+s3.hashCode()); } } ---*--- 输出结果: 集合元素个数:2 s1的哈希值为:1102553374 s2的哈希值为:757717223 s3的哈希值为:757717223重写了hashCode方法和equals方法,当哈希值相同而且还是同一对象时。我们就视为同一元素,不存储该元素。
-
Set 集合存储并遍历
public class Demo { public static void main(String[] args) { Set<String> ss = new HashSet<>(); //添加元素 ss.add("1.苹果"); ss.add("2.华为"); ss.add("3.vivo"); ss.add("3.vivo");//来一个重复的元素 ss.add("4.菠萝"); //遍历 for (String str : ss){ String s1 = str; System.out.println(s1); } } } ---*--- 输出结果: 3.vivo 1.苹果 2.华为 4.菠萝 //可以看出元素无序且不重复结果可以看出HashSet集合存储元素是无序的并且不重复。
HashSet & LinkedHashSet & TreeSet 类
| 类名 | 存储结构 | 适用场景 |
|---|---|---|
| HashSet | 哈希表(数组+链表) | 不重复、无序 |
| TreeSet | 红黑树 | 不重复、定制排序 |
| LinkdeHashSet | 哈希表+链表 | 不重复、有序 |
HashSet 类
- 特点
HashSet集合是用哈希表存储的,可以理解为元素是链表的数组。由于存储的位置是由哈希值确定的,所以是无序的。public class Demo { public static void main(String[] args) { Set<String> ss = new HashSet<>(); ss.add("1.苹果"); ss.add("2.华为"); ss.add("3.vivo"); ss.add("4.三星"); ss.add("4.三星"); //遍历 Iterator<String> it = ss.iterator(); while (it.hasNext()){ String s = it.next(); System.out.println(s); } } } ---*--- 输出结果: 3.vivo 4.三星 1.苹果 2.华为
TreeSet 类
-
特点
- 基于排列顺序实现元素不重复。
- 元素按照一定规则进行排序,具体取决与构造方法。
.TreeSet():根据元素的自然排序进行排序
.TreeSet(Comparator c) :根据指定比较器排序
-
TreeSet 存储结构
Tree翻译是树的意思,TreeSet以节点形式存储数据,每个节点可有两个子节点。当存储数据时,第一个数据将存储在根节点上,之后的数据都会和根节点比较,比根节点小存入根节点左边子节点,比根节点大存入根节点右边子节点,和根节点相等则视为相同数据不存储。当子节点已经有数据时,存入数据和子节点数据进行比较,比子节点小存左,比子节点大存右。以此类推,找到没有数据的节点。
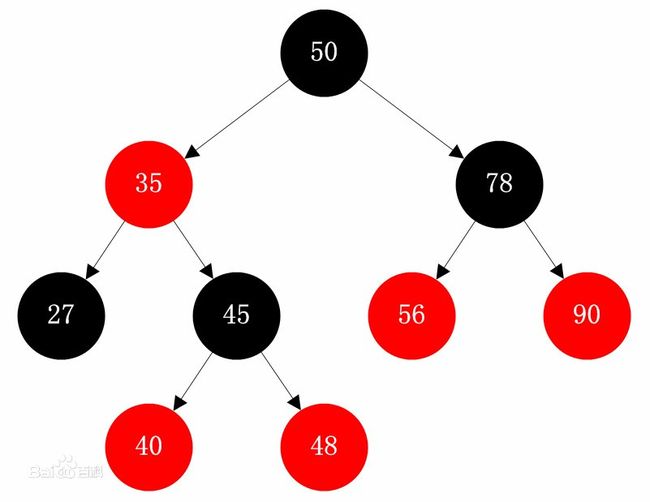
-
无参构造存放学生对象并遍历(自然排序)
//学生类 class Student implements Comparable<Student>{ String name; int age; public Student(String name, int age) { this.name = name; this.age = age; } //该方法用于判断是否元素相同和存储位置 @Override public int compareTo(Student s) { int num = this.age-s.age; int num2 = num==0? this.name.compareTo(s.name):num; return num2; } } //测试类 public class Demo { public static void main(String[] args) { TreeSet<Student> trs = new TreeSet<>(); Student s1 = new Student("zhanglei", 18); Student s2 = new Student("xiaohong", 8); Student s3 = new Student("renxianqi", 38); Student s4 = new Student("wanglihong", 38); trs.add(s1);//如果没有继承Comparable则抛出异常 trs.add(s2); trs.add(s3); trs.add(s4); trs.add(s4); System.out.println("集合中元素个数:"+trs.size()); for (Student stu: trs){ System.out.println(stu.name+","+stu.age); } } } ---*--- 输出结果: 集合中元素个数:4 xiaohong,8 zhanglei,18 renxianqi,38 wanglihong,38注意:使用TreeSet集合无参构造创建的对象添加元素,需要元素对象的类型必须实现Comparable接口,重写CompareTo方法(方法用于判断元素是否重复和元素存放位置)。
-
带参构造存放学生对象并遍历(比较器排序)
//学生类 class Student { String name; int age; public Student(String name, int age) { this.name = name; this.age = age; } } //测试类 public class Demo { public static void main(String[] args) { TreeSet<Student> trs = new TreeSet<>(new Comparator<Student>() { //该方法和CompareTo功能一样 @Override public int compare(Student o1, Student o2) { int num = o1.age - o2.age; int num2 = num==0?o1.name.compareTo(o2.name):num; return num2; } }); Student s1 = new Student("zhanglei", 18); Student s2 = new Student("xiaohong", 8); Student s3 = new Student("renxianqi", 38); Student s4 = new Student("wanglihong", 38); trs.add(s1); trs.add(s2); trs.add(s3); trs.add(s4); trs.add(s4); System.out.println("集合中元素个数:"+trs.size()); for (Student stu: trs){ System.out.println(stu.name+","+stu.age); } } } ---*--- 输出结果: 集合中元素个数:4 xiaohong,8 zhanglei,18 renxianqi,38 wanglihong,38使用比较器排序可以实现和自然排序一样的功能,区别是自然排序需要在元素类型中实现Comparable接口,比较器是在TreeSet构造方法中传一个Comparator。
-
Comparable 和 Comparator 接口
使用TreeSet集合存储元素,需要元素对象类型实现Comparable接口重写其compareTo方法或者使用TreeSet的带参构造传入一个Comparator(比较器)对象。两者其本质是一样的,需要将存入元素和已有元素进行对比,以确定存入的元素是否重复,和存放的位置。(具体参考上面的 TreeSet 存储结构)。public class Demo { public static void main(String[] args) { TreeSet<Integer> is = new TreeSet<>(new Comparator<Integer>() { @Override public int compare(Integer o1, Integer o2) { return o2 - o1;//o2-o1反序 --- o1-o2正序 } }); is.add(20); is.add(50); is.add(10); is.add(30); is.add(40); for (Integer ii : is) { System.out.println(ii); } } } ---*--- 输出结果: 50 40 30 20 10上面是调用TreeSet带参构造创建的集合对象,存储Integer对象。着重说明一下Comparator中的compare方法。
public int compare(Integer o1, Integer o2) { return o2-o1;}该方法会返回一个int类型的值,当集合存储元素时,会把存即将入元素(o1)和已有元素(o2)进行比较。o1-o2=0说明两元素相同不进行存储,o1-o2>0将o1存储到o2元素后面,o1-o2<0将o1存储到o2元素前面。 -
练习:TreeSet存储字符串元素,以长短排序,相同长度以字母排序。
public class Demo1 { public static void main(String[] args) { //带参构造创建集合对象 TreeSet<String> ss = new TreeSet<>(new Comparator<String>() { //重写compare方法 @Override public int compare(String o1, String o2) { int num = o1.length()-o2.length(); int num2 = num==0?o1.compareTo(o2):num; return num2; } }); //添加元素 ss.add("xyz"); ss.add("abc"); ss.add("xz"); ss.add("x"); ss.add("xysdsz"); ss.add("xyaaadfz"); ss.add("aab"); ss.add("aaa"); for (String s:ss ) { System.out.println(s); } } } ---*--- 输出结果: x xz aaa aab abc xyz xysdsz xyaaadfz
LinkdeHashSet 类
-
特点
LinkdeHashSet集合的存储结构是哈希表+链表实现的,其存储元素不重复且有序。有序是由链表实现的。public class Demo { public static void main(String[] args) { LinkedHashSet<String> ss = new LinkedHashSet<>(); ss.add("1.苹果"); ss.add("2.华为"); ss.add("3.vivo"); ss.add("4.三星"); ss.add("4.三星"); //遍历 for (String str : ss){ System.out.println(str); } } } ---*--- 输出结果: 1.苹果 2.华为 3.vivo 4.三星LinkedHashSet 算是 HashSet 的增强版,让元素不重复并且实现了存取顺序一致。
并发修改异常
-
概述
简单来说就是,集合中的元素个数修改时会有一个A变量计数,创建迭代器时将集合中的A赋值给了迭代器中的变量B。在迭代器调用next()方法时会先判断A是否等于B,如果不等于就抛出并发修改异常。所以在创建迭代器之后不能使用集合中的方法进行增删元素,只能使用迭代器中的方法增删。 -
演示代码
import java.util.ArrayList; import java.util.Iterator; import java.util.List; public class Demo { public static void main(String[] args) { List<String> list = new ArrayList<>(); list.add("苹果"); //拿到该集合的迭代器 Iterator<String> iterator = list.iterator(); //修改集合元素个数 list.add("榴莲"); while (iterator.hasNext()){ String s = iterator.next();//此处报错 System.out.println(s); } } } ---*--- 输出结果: Exception in thread "main" java.util.ConcurrentModificationException at java.base/java.util.ArrayList$Itr.checkForComodification(ArrayList.java:1043) at java.base/java.util.ArrayList$Itr.next(ArrayList.java:997) at com.Zy.Demo.main(Demo.java:17)解决办法:使用增强for代替Iterator
Map 接口
创建 Map 对象需要通过多态的形式,其根据 new 的实现类不同体现不同的特性:
- HashMap:无序、无下标、(键不重复,值可重复)
- LinkedHashMap:有序、无下标、(键不重复,值可重复)
- TreeMap:定制排序、无下标、(键不重复,值可重复)

-
Map 常用方法
常用方法名 描述 V put(K kkey,V value) 添加元素 V remove(Object key) 根据键删除键值对元素 void clear() 删除集合所有元素 boolean containsKey(Object key) 判断集合是否包含指定的键 boolean containsValue(Object value) 判断集合是否包含指定的值 boolean isEmpty() 判断集合是否为空 int size() 返回集合长度 V get(Object key) 根据键获取值 Set< K > keySet() 获取所有键的集合 Collection< V > values() 获取所有值的集合 Set< Map.Entry< K,V >> entrySet() 获取所有键值对对象的集合 -
方法练习
添加元素(提示:添加元素出现键相同值不同时,值将被替换。)public class Demo { public static void main(String[] args) { Map<String,String> map = new HashMap<>(); map.put("cn","中国"); map.put("usa","美国"); map.put("br","巴西"); map.put("cu","古巴"); map.put("cu","巴古"); System.out.println(map); } } ---*--- 输出结果: { br=巴西, usa=美国, cu=巴古, cn=中国}删除元素
public class Demo { public static void main(String[] args) { Map<String,String> map = new HashMap<>(); map.put("cn","中国"); map.put("usa","美国"); map.put("br","巴西"); map.put("cu","古巴"); System.out.println("集合元素个数:"+map.size()); map.remove("usa"); System.out.println("删除后元素个数:"+map.size()); } } ---*--- 输出结果: 集合元素个数:4 删除后元素个数:3遍历
public class Demo { public static void main(String[] args) { Map<String,String> map = new HashMap<>(); map.put("cn","中国"); map.put("usa","美国"); map.put("br","巴西"); map.put("cu","古巴"); System.out.println("集合元素个数:"+map.size()); //keySet遍历 Set<String> strings = map.keySet(); for (String s:strings ) { //strings可以替换为map.keySet() System.out.println(s+","+map.get(s)); } System.out.println("--------"); //entrySet遍历 Set<Map.Entry<String, String>> entries = map.entrySet(); for (Map.Entry<String,String> ii: entries){ entries可以替换为map.entrySet() System.out.println(ii.getKey()+","+ii.getValue()); } } } ---*--- 输出结果: 集合元素个数:4 br,巴西 usa,美国 cu,古巴 cn,中国 -------- br,巴西 usa,美国 cu,古巴 cn,中国 -
添加学生对象并遍历(为了简洁学生类重写了toString方法)
public class Demo { public static void main(String[] args) { Map<String,Student> map = new HashMap<>(); //创建学生对象 Student s1 = new Student("张磊", 15); Student s2 = new Student("小明", 18); Student s3 = new Student("小黑", 20); //添加元素 map.put("001",s1); map.put("002",s2); map.put("003",s3); //遍历 for (Map.Entry<String,Student> ii:map.entrySet()){ String key = ii.getKey(); Student value = ii.getValue(); System.out.println("学号"+key+"\t"+value); } } } ---*--- 输出结果: 学号001 Student{ name='张磊', age=15} 学号002 Student{ name='小明', age=18} 学号003 Student{ name='小黑', age=20}
HashMap & LinkedHashMap & TreeMap
HashMap 和 HashSet 一样要想实现存入键的元素不重复需要重写键元素对象类的hashCode方法和equals方法。
LinkedHashMap 和 LinkedHashSet一样,算是 HashMap 的增强版,让键元素不重复并且实现了存取顺序一致。
TreeMap 和 TreeSet 一样要想实现存入键的元素不重复需要键元素对象类型实现Comparable接口或者使用TreeMap的带参构造传入一个Comparator(比较器)对象。
-
HashMap添加学生对象和住址
public class Demo { public static void main(String[] args) { HashMap<Student,String> treeMap = new HashMap<>(); Student s1 = new Student("张磊", 15); Student s2 = new Student("小明", 38); Student s3 = new Student("小黑", 20); Student s4 = new Student("小黑", 20);//相同属性对象s3 s4 treeMap.put(s2,"重庆"); treeMap.put(s1,"北京"); treeMap.put(s3,"上海"); treeMap.put(s4,"无锡");//添加相同键值对象 //遍历 for (Map.Entry<Student,String> ii:treeMap.entrySet()){ Student key = ii.getKey(); String value = ii.getValue(); System.out.println(key+"居住在:"+value); } } } ---*--- 输出结果: 学生{ 姓名='张磊', 年龄=15}居住在:北京 学生{ 姓名='小明', 年龄=38}居住在:重庆 学生{ 姓名='小黑', 年龄=20}居住在:无锡 -
TreeMap添加学生对象和住址(按学生年龄排序)
public class Demo { public static void main(String[] args) { TreeMap<Student,String> treeMap = new TreeMap<>(new Comparator<Student>() { @Override public int compare(Student o1, Student o2) { int num = o1.age-o2.age;//学生年龄升序 int num2 = num==0?o1.name.compareTo(o2.name):num;//年龄相同按字符排列 return num2; } }); Student s1 = new Student("张磊", 15); Student s2 = new Student("小明", 38); Student s3 = new Student("小黑", 20); Student s4 = new Student("小黑", 20);//相同属性对象s3 s4 treeMap.put(s2,"重庆"); treeMap.put(s1,"北京"); treeMap.put(s3,"上海"); treeMap.put(s4,"江津");//添加相同键值对象 //遍历 for (Map.Entry<Student,String> ii:treeMap.entrySet()){ Student key = ii.getKey(); String value = ii.getValue(); System.out.println(key+"居住在:"+value); } } } ---*--- 输出结果: 学生{ 姓名='张磊', 年龄=15}居住在:北京 学生{ 姓名='小黑', 年龄=20}居住在:江津 学生{ 姓名='小明', 年龄=38}居住在:重庆 -
列表集合存储HashMap元素遍历
public class Demo { public static void main(String[] args) { ArrayList<HashMap<String,String>> aa = new ArrayList<>(); HashMap<String,String> hh1 = new HashMap<>(); HashMap<String,String> hh2 = new HashMap<>(); HashMap<String,String> hh3 = new HashMap<>(); hh1.put("张无忌","赵敏"); hh1.put("林心如","霍建华"); hh2.put("赵丽颖","冯绍峰"); hh3.put("刘欣","邵峰"); aa.add(hh1); aa.add(hh2); aa.add(hh3); //遍历 for (HashMap<String,String> hh: aa){ for (Map.Entry<String,String> mm: hh.entrySet()){ System.out.println(mm.getKey()+","+mm.getValue()); } } } } ---*--- 输出结果: 林心如,霍建华 张无忌,赵敏 赵丽颖,冯绍峰 刘欣,邵峰
泛型
将一个对象放入集合中时,由于集合并不知道我们要放什么类型,所以统统由 Object 类型变量接收。当我们在次使用对象的时候,对象变为Object类型,我们必须自己转换其类型。为了解决这个问题,则提出泛型。
泛型本质是参数化类型,将数据类型作为参数传递 。可用于类、接口和方法上。
-
格式:
-
使用泛型的好处:
1.提供编译时类型检测
2.避免了强制类型转换
3.提高了代码的灵活性
泛型类
-
泛型类格式:
格式:修饰符 class 类名 < 类型 > { }
范例:public class Generic < T > { } -
//泛型类 class Student <T> { T age; public T getAge() { return age; } public void setAge(T age) { this.age = age; } } //测试类 public class Demo { public static void main(String[] args) { //传入Integer类型 Student<Integer> stu1 = new Student<>(); stu1.setAge(5); System.out.println("传入Integer类型:"+stu1.getAge()); //传入String类型 Student<String> stu2 = new Student<>(); stu2.setAge("8"); System.out.println("传入String类型:"+stu2.getAge()); } } ---*--- 输出结果: 传入Integer类型:5 传入String类型:8注意:当泛型类被实例化或者被继承时,如果没有传入确定的类型,则该泛型将被当做Object类型看待。
泛型接口
-
泛型接口格式:
格式:修饰符 interface 接口名 < 类型 > { }
范例:public interface Generic < T > { } -
//泛型接口 interface Genercic <T> { void show(T t); } //实现类 class Genericimpl<T> implements Genercic<T>{ @Override public void show(T t) { System.out.println(t); } } //测试类 public class Demo { public static void main(String[] args) { Genericimpl<String> s = new Genericimpl<>(); s1.show("苹果"); Genericimpl<Integer> i = new Genericimpl<>(); s2.show(50); } } ---*---- 输出结果: 苹果 50注意:泛型接口的实现类应该是一个泛型类,注意该类的格式。它定义了一个和接口一样的泛型。
泛型方法
-
泛型方法格式:
格式:修饰符 < 类型 > 返回值类型 方法名(类型 变量名) { }
范例:public < T > void show(T t) { } -
//测试类 public class Demo { //泛型方法 public static <T> T show(T t){ System.out.println(t); return t; } //main方法 public static void main(String[] args) { Demo.show("青岛"); Demo.show(100); Demo.show(12.5); Demo.show(true); } } ---*--- 输出结果: 青岛 100 12.5 true很明显,泛型方法可以用更少的代码实现方法的重载。方法传入类型的时候才确定泛型的类型,也就是说传入什么类型就是什么类型。
Collections 集合工具类
- 概述
针对集合的工具类,其中均是静态方法,可通过类名直接调用。 - 常用方法
| 方法 | 描述 |
|---|---|
| 将制定的列表按升序排序 | |
| < T > void sort(List list, Comparator c) | 根据指定比较器引发的顺序对指定列表进行排序 |
| void reverse(Listlist) | 翻转制定列表中元素的顺序 |
| void shuffle(List list) | 使用默认的随机源随机排列指定的列表 |
| < T > void fill(List list, T obj) | 用指定的元素替换指定列表的所有元素 |
Collections更多方法
练习题