Kubernetes 1.20.5 安装Prometheus-Oprator
背景
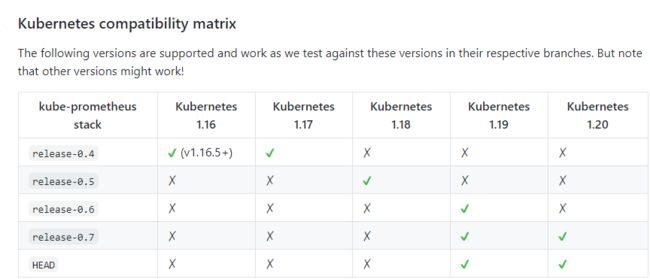
线上kubernetes集群为1.16版本 Prometheus oprator 分支为0.4关于Prometheus oprator与kubernetes版本对应关系如下图。可见https://github.com/prometheus-operator/kube-prometheus.
注: Prometheus operator? kube-prometheus? kube-prometheus 就是 Prometheus的一种operator的部署方式…Prometheus-operator 已经改名为 Kube-promethues。
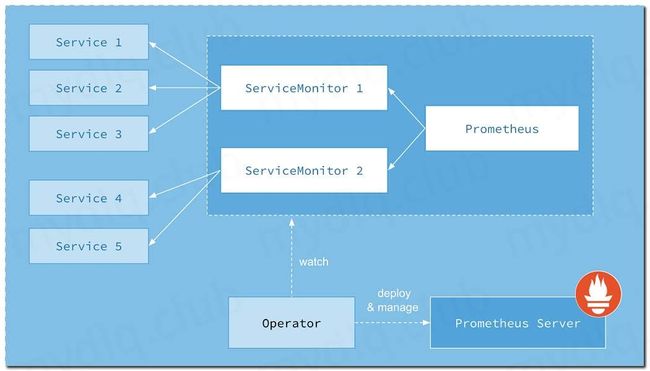
关于部署过程可以参考超级小豆丁大佬的笔记:http://www.mydlq.club/article/10/。Prometheus这种架构图,在各位大佬的文章中都可以看到的…
先简单部署一下Prometheus oprator(or或者叫kube-promethus)。完成微信报警的集成,其他的慢慢在生成环境中研究。
基本过程就是Prometheus oprator 添加存储,增加微信报警,外部traefik代理应用。
1. prometheus环境的搭建
1. 克隆prometheus-operator仓库
git clone https://github.com/prometheus-operator/kube-prometheus.git

网络原因,经常会搞不下来的,还是直接下载zip包吧,其实安装版本的支持列表kubernetes1.20的版本可以使用kube-prometheus的0.6 or 0.7 还有HEAD分支的任一分支。偷个懒直接用HEAD了。
记录一下tag,以后有修改了也好能快速修改了 让版本升级跟得上…
上传zip包解压缩
unzip kube-prometheus-main.zip

2. 按照快捷方式来一遍
cd kube-prometheus-main/
kubectl create -f manifests/setup
until kubectl get servicemonitors --all-namespaces ; do date; sleep 1; echo ""; done
kubectl create -f manifests/
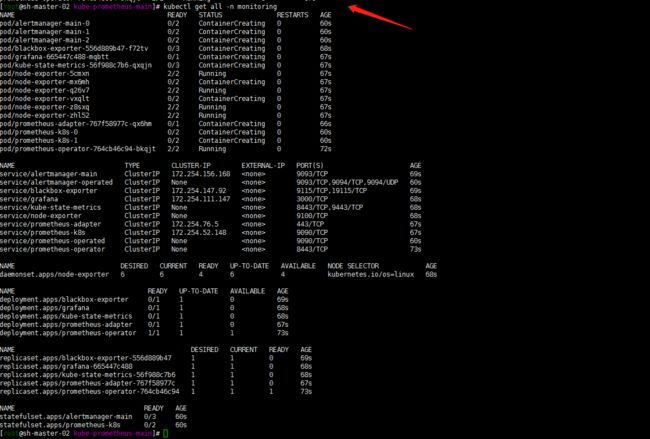
kubectl get pods -n monitoring

3. imagepullbackoff
由于网络原因会出现有些镜像下载不下来的问题,可墙外服务器下载镜像修改tag上传到harbor,修改yaml文件中镜像为对应私有镜像仓库的标签tag解决(由于我的私有仓库用的腾讯云的仓库,现在跨地域上传镜像应该个人版的不可以了,所以我使用了docker save导出镜像的方式):

kubectl describe pods kube-state-metrics-56f988c7b6-qxqjn -n monitoring
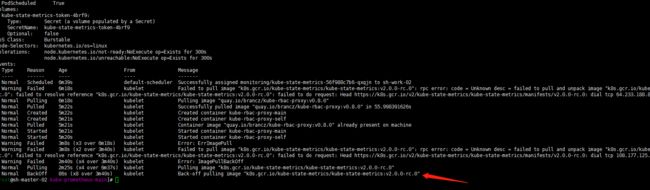
1. 使用国外服务器下载镜像,并打包为tar包下载到本地。
docker pull k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.0.0-rc.0
docker save k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.0.0-rc.0 -o kube-state-metrics.tar

2. ctr导入镜像
ctr -n k8s.io i import kube-state-metrics.tar
![]()
导入的只是一个工作节点这样,但是kubernetes本来就是保证高可用用性,如果这个pod漂移调度到其他节点呢?难道要加上节点亲和性?这个节点如果就崩溃了呢?每个节点都导入此镜像?新加入的节点呢?还是老老实实的上传到镜像仓库吧!
正常的流程应该是这样吧?
crictl images
ctr image tag k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.0.0-rc.0 ccr.ccs.tencentyun.com/k8s_containers/kube-state-metrics:v2.0.0-rc.0

但是为什么是not found?不知道是不是标签格式问题…。反正就这样了 ,然后上传到镜像库,具体命令可以参考https://blog.csdn.net/tongzidane/article/details/114587138 https://blog.csdn.net/liumiaocn/article/details/103320426/
(上传我的仓库权限还是有问题(仓库里面可以下载啊但是我…搞迷糊了),不先搞了直接导入了)

反正咋样把kube-state-metrics-XXXX启动起来就好了,有时间好好研究下ctr crictl命令 还是有点懵。
3. 验证服务都正常启动
kubectl get pod -n monitoring
kubectl get svc -n monitoring

4. 使用traefik代理应用
注: 参照前文Kubernetes 1.20.5 安装traefik在腾讯云下的实践https://www.yuque.com/duiniwukenaihe/ehb02i/odflm7#WT4ab。比较习惯了ingresroute的方式就保持这种了没有使用ingress 或者api的方式。
cat monitoring.com.yaml
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
namespace: monitoring
name: alertmanager-main-http
spec:
entryPoints:
- web
routes:
- match: Host(\`alertmanager.saynaihe.com\`)
kind: Rule
services:
- name: alertmanager-main
port: 9093
---
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
namespace: monitoring
name: grafana-http
spec:
entryPoints:
- web
routes:
- match: Host(\`monitoring.saynaihe.com\`)
kind: Rule
services:
- name: grafana
port: 3000
---
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
namespace: monitoring
name: prometheus
spec:
entryPoints:
- web
routes:
- match: Host(\`prometheus.saynaihe.com\`)
kind: Rule
services:
- name: prometheus-k8s
port: 9090
---
kubectl apply -f monitoring.com.yaml
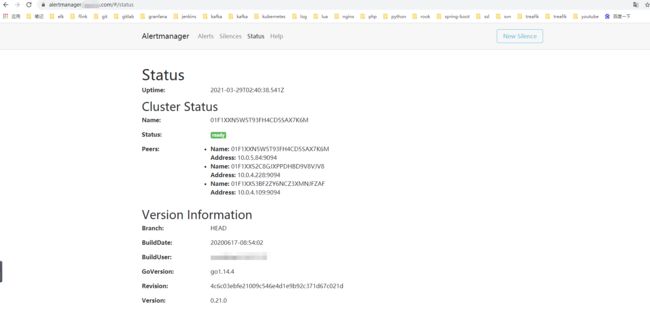
验证traefik代理应用是否成功:
修改密码
先随便演示一下,后面比较还要修改
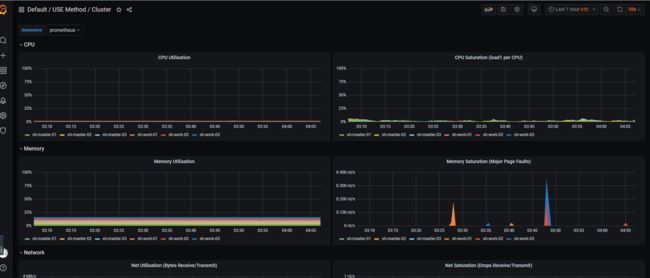
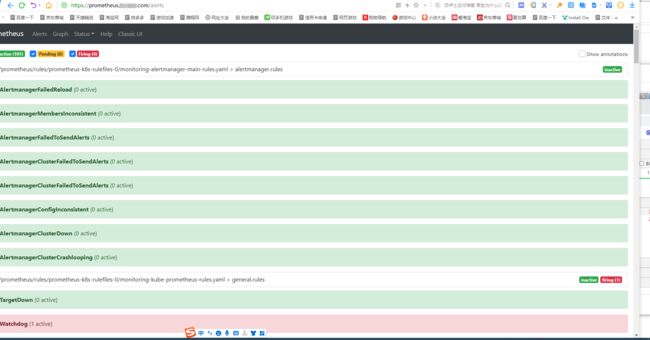
仅用于演示,后面起码alertmanager Prometheus两个web要加个basic安全验证…
5. 添加 kubeControllerManager kubeScheduler监控
通过https://prometheus.saynaihe.com/targets 页面可以看到和前几个版本一样依然木有kube-scheduler 和 kube-controller-manager 的监控。

修改/etc/kubernetes/manifests/目录下kube-controller-manager.yaml kube-scheduler.yaml将 - --bind-address=127.0.0.1 修改为 - --bind-address=0.0.0.0

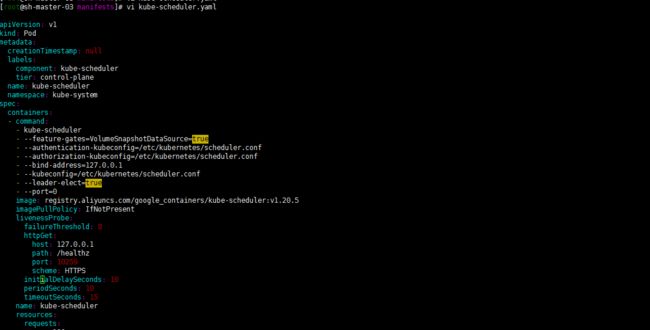
修改为配置文件 control manager scheduler服务会自动重启的。等待重启验证通过。

在manifests目录下(这一步一点要仔细看下新版的matchLabels发生了改变)
grep -A2 -B2 selector kubernetes-serviceMonitor*

cat < kube-controller-manager-scheduler.yml
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-controller-manager
labels:
app.kubernetes.io/name: kube-controller-manager
spec:
selector:
component: kube-controller-manager
type: ClusterIP
clusterIP: None
ports:
- name: https-metrics
port: 10257
targetPort: 10257
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler
labels:
app.kubernetes.io/name: kube-scheduler
spec:
selector:
component: kube-scheduler
type: ClusterIP
clusterIP: None
ports:
- name: https-metrics
port: 10259
targetPort: 10259
protocol: TCP
EOF
kubectl apply -f kube-controller-manager-scheduler.yml


cat < kube-ep.yml
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: kube-controller-manager
name: kube-controller-manager
namespace: kube-system
subsets:
- addresses:
- ip: 10.3.2.5
- ip: 10.3.2.13
- ip: 10.3.2.16
ports:
- name: https-metrics
port: 10257
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: kube-scheduler
name: kube-scheduler
namespace: kube-system
subsets:
- addresses:
- ip: 10.3.2.5
- ip: 10.3.2.13
- ip: 10.3.2.16
ports:
- name: https-metrics
port: 10259
protocol: TCP
EOF
kubectl apply -f kube-ep.yml

登陆https://prometheus.saynaihe.com/targets进行验证:
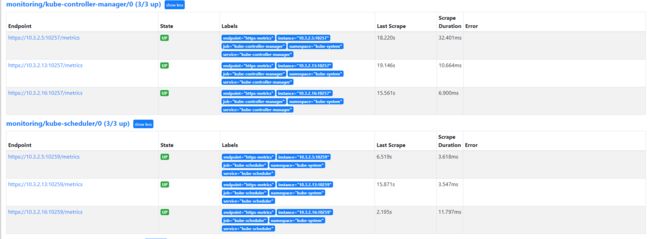
6. ECTD的监控
kubectl -n monitoring create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/healthcheck-client.crt --from-file=/etc/kubernetes/pki/etcd/healthcheck-client.key --from-file=/etc/kubernetes/pki/etcd/ca.crt
kubectl edit prometheus k8s -n monitoring

验证Prometheus是否正常挂载证书
[root@sh-master-02 yaml]# kubectl exec -it prometheus-k8s-0 /bin/sh -n monitoring
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
Defaulting container name to prometheus.
Use 'kubectl describe pod/prometheus-k8s-0 -n monitoring' to see all of the containers in this pod.
/prometheus $ ls /etc/prometheus/secrets/etcd-certs/
ca.crt healthcheck-client.crt healthcheck-client.key
cat < kube-ep-etcd.yml
apiVersion: v1
kind: Service
metadata:
name: etcd-k8s
namespace: kube-system
labels:
k8s-app: etcd
spec:
type: ClusterIP
clusterIP: None
ports:
- name: etcd
port: 2379
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: etcd
name: etcd-k8s
namespace: kube-system
subsets:
- addresses:
- ip: 10.3.2.5
- ip: 10.3.2.13
- ip: 10.3.2.16
ports:
- name: etcd
port: 2379
protocol: TCP
---
EOF
kubectl apply -f kube-ep-etcd.yml
cat < prometheus-serviceMonitorEtcd.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: etcd-k8s
namespace: monitoring
labels:
k8s-app: etcd
spec:
jobLabel: k8s-app
endpoints:
- port: etcd
interval: 30s
scheme: https
tlsConfig:
caFile: /etc/prometheus/secrets/etcd-certs/ca.crt
certFile: /etc/prometheus/secrets/etcd-certs/healthcheck-client.crt
keyFile: /etc/prometheus/secrets/etcd-certs/healthcheck-client.key
insecureSkipVerify: true
selector:
matchLabels:
k8s-app: etcd
namespaceSelector:
matchNames:
- kube-system
EOF
kubectl apply -f prometheus-serviceMonitorEtcd.yaml

7. prometheus配置文件修改为正式
1. 添加自动发现配置
网上随便抄 了一个
cat < prometheus-additional.yaml
- job_name: 'kubernetes-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: kubernetes_pod_name
EOF
kubectl create secret generic additional-configs --from-file=prometheus-additional.yaml -n monitoring
2. 增加存储 保留时间 etcd secret
cat < prometheus-prometheus.yaml
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.25.0
prometheus: k8s
name: k8s
namespace: monitoring
spec:
alerting:
alertmanagers:
- apiVersion: v2
name: alertmanager-main
namespace: monitoring
port: web
externalLabels: {}
image: quay.io/prometheus/prometheus:v2.25.0
nodeSelector:
kubernetes.io/os: linux
podMetadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.25.0
podMonitorNamespaceSelector: {}
podMonitorSelector: {}
probeNamespaceSelector: {}
probeSelector: {}
replicas: 2
resources:
requests:
memory: 400Mi
ruleSelector:
matchLabels:
prometheus: k8s
role: alert-rules
secrets:
- etcd-certs
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
additionalScrapeConfigs:
name: additional-configs
key: prometheus-additional.yaml
serviceAccountName: prometheus-k8s
retention: 60d
serviceMonitorNamespaceSelector: {}
serviceMonitorSelector: {}
version: 2.25.0
storage:
volumeClaimTemplate:
spec:
storageClassName: cbs-csi
resources:
requests:
storage: 50Gi
EOF
kubectl apply -f prometheus-prometheus.yaml

8. grafana添加存储
- 新建grafana pvc
cat < grafana-pv.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: grafana
namespace: monitoring
spec:
storageClassName: cbs-csi
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
EOF
kubectl apply -f grafana-pv.yaml
修改manifests目录下grafana-deployment.yaml存储

9. grafana添加监控模板
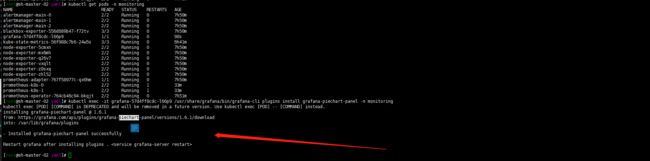
添加etcd traefik 模板,import模板号10906 3070.嗯 会发现traefik模板会出现Panel plugin not found: grafana-piechart-panel.
解决方法:重新构建grafana镜像,/usr/share/grafana/bin/grafana-cli plugins install grafana-piechart-panel安装缺失插件

10. 微信报警

将对应秘钥填入alertmanager.yaml
1. 配置alertmanager.yaml
cat < alertmanager.yaml
global:
resolve_timeout: 2m
wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/'
route:
group_by: ['alert']
group_wait: 10s
group_interval: 1m
repeat_interval: 1h
receiver: wechat
receivers:
- name: 'wechat'
wechat_configs:
- api_secret: 'XXXXXXXXXX'
send_resolved: true
to_user: '@all'
to_party: 'XXXXXX'
agent_id: 'XXXXXXXX'
corp_id: 'XXXXXXXX'
templates:
- '/etc/config/alert/wechat.tmpl'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'production', 'instance']
EOF
2. 个性化配置报警模板,这个随意了网上有很多例子
cat < wechat.tpl
{
{ define "wechat.default.message" }}
{
{- if gt (len .Alerts.Firing) 0 -}}
{
{- range $index, $alert := .Alerts -}}
{
{- if eq $index 0 }}
==========异常告警==========
告警类型: {
{ $alert.Labels.alertname }}
告警级别: {
{ $alert.Labels.severity }}
告警详情: {
{ $alert.Annotations.message }}{
{ $alert.Annotations.description}};{
{$alert.Annotations.summary}}
故障时间: {
{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{
{- if gt (len $alert.Labels.instance) 0 }}
实例信息: {
{ $alert.Labels.instance }}
{
{- end }}
{
{- if gt (len $alert.Labels.namespace) 0 }}
命名空间: {
{ $alert.Labels.namespace }}
{
{- end }}
{
{- if gt (len $alert.Labels.node) 0 }}
节点信息: {
{ $alert.Labels.node }}
{
{- end }}
{
{- if gt (len $alert.Labels.pod) 0 }}
实例名称: {
{ $alert.Labels.pod }}
{
{- end }}
============END============
{
{- end }}
{
{- end }}
{
{- end }}
{
{- if gt (len .Alerts.Resolved) 0 -}}
{
{- range $index, $alert := .Alerts -}}
{
{- if eq $index 0 }}
==========异常恢复==========
告警类型: {
{ $alert.Labels.alertname }}
告警级别: {
{ $alert.Labels.severity }}
告警详情: {
{ $alert.Annotations.message }}{
{ $alert.Annotations.description}};{
{$alert.Annotations.summary}}
故障时间: {
{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
恢复时间: {
{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{
{- if gt (len $alert.Labels.instance) 0 }}
实例信息: {
{ $alert.Labels.instance }}
{
{- end }}
{
{- if gt (len $alert.Labels.namespace) 0 }}
命名空间: {
{ $alert.Labels.namespace }}
{
{- end }}
{
{- if gt (len $alert.Labels.node) 0 }}
节点信息: {
{ $alert.Labels.node }}
{
{- end }}
{
{- if gt (len $alert.Labels.pod) 0 }}
实例名称: {
{ $alert.Labels.pod }}
{
{- end }}
============END============
{
{- end }}
{
{- end }}
{
{- end }}
{
{- end }}
EOF
3. 部署secret
kubectl delete secret alertmanager-main -n monitoring
kubectl create secret generic alertmanager-main --from-file=alertmanager.yaml --from-file=wechat.tmpl -n monitoring

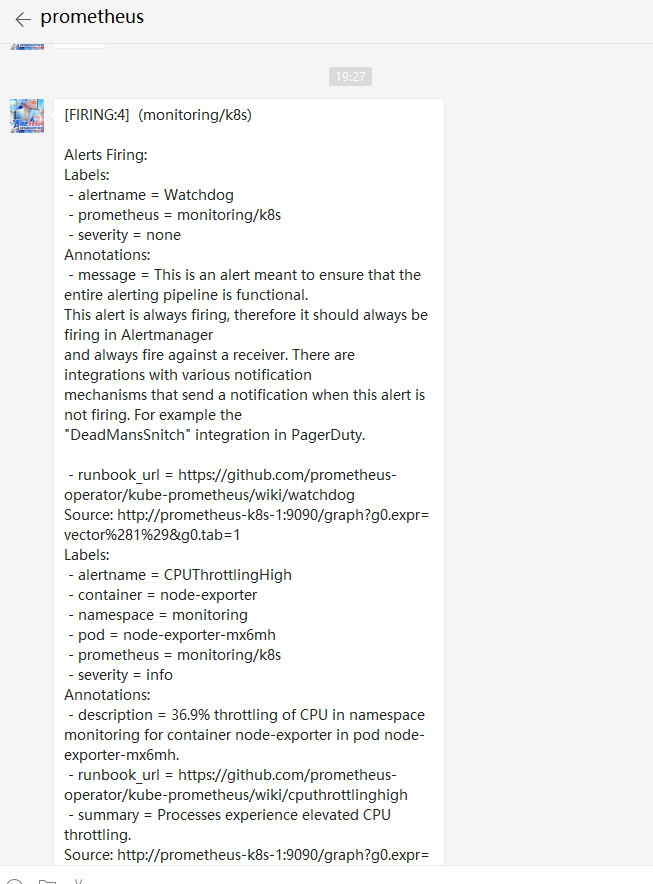
4. 验证
11. 彩蛋
正好个人想试一下kubernetes的HPA ,
[root@sh-master-02 yaml]# kubectl top pods -n qa
W0330 16:00:54.657335 2622645 top_pod.go:265] Metrics not available for pod qa/dataloader-comment-5d975d9d57-p22w9, age: 2h3m13.657327145s
error: Metrics not available for pod qa/dataloader-comment-5d975d9d57-p22w9, age: 2h3m13.657327145s
what Prometheus oprator不是有metrics吗 ?怎么回事
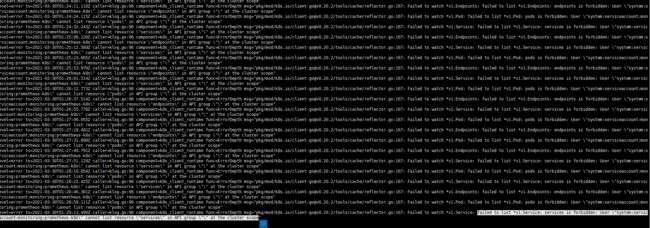
kubectl logs -f prometheus-adapter-c96488cdd-vfm7h -n monitoring
如下图… 我安装kubernete时候修改了集群的dnsDomain。没有修改配置文件,这样是有问题的
manifests目录下 修改prometheus-adapter-deployment.yaml中Prometheus-url

然后kubectl top nodes.可以使用了

12. 顺便讲一下hpa
参照https://blog.csdn.net/weixin_38320674/article/details/105460033。环境中有metrics。从第七步骤开始
1. 打包上传到镜像库
docker build -t ccr.ccs.tencentyun.com/XXXXX/test1:0.1 .
docker push ccr.ccs.tencentyun.com/XXXXX/test1:0.1
2. 通过deployment部署一个php-apache服务
cat php-apache.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
spec:
selector:
matchLabels:
run: php-apache
replicas: 1
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: ccr.ccs.tencentyun.com/XXXXX/test1:0.1
ports:
- containerPort: 80
resources:
limits:
cpu: 200m
requests:
cpu: 100m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apache
kubectl apply -f php-apache.yaml
3. 创建hpa
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
下面是释意:
kubectl autoscale deployment php-apache (php-apache表示deployment的名字) --cpu-percent=50(表示cpu使用率不超过50%) --min=1(最少一个pod)
--max=10(最多10个pod)
4.压测php-apache服务,只是针对CPU做压测
启动一个容器,并将无限查询循环发送到php-apache服务(复制k8s的master节点的终端,也就是打开一个新的终端窗口):
kubectl run v1 -it --image=busybox /bin/sh
登录到容器之后,执行如下命令
while true; do wget -q -O- http://php-apache.default; done
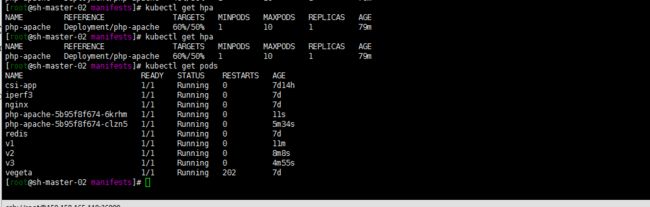
这里只对cpu做了测试。简单demo.其他的单单讲了.
13. 其他坑爹的
无意间把pv,pvc删除了… 以为我的storageclass有问题。然后重新部署吧 ? 个人觉得部署一下 prometheus-prometheus.yaml就好了,然后 并没有出现Prometheus的服务。瞄了一遍日志7.1整有了,重新执行下就好了,不记得自己具体哪里把这的secret 搞掉了…记录一下
kubectl create secret generic additional-configs --from-file=prometheus-additional.yaml -n monitoring