用Python分析了5w+《长津湖》影评,看看观众们都是怎么说?
来源:志斌的Python笔记
大家好,我是阳哥~
要说十一档最热门的电影,那肯定是长津湖了,在十一档电影中评分排名第一。

并且刚刚上映两天,票房就已经突破了六亿,破了十一项记录!

本文通过爬取《长津湖》豆瓣短评,进行数据可视化分析后,来看看这部电影为什么这么受大家欢迎!
01
数据采集
我们进入豆瓣电影的短评页面,按F12打开开发者模式后,对页面进行观察后发现,评论数据是存在于源网页中的。

在上面,我们已经找到数据存储的网页和方式,那么只需要找到页面之间的联系,构造好循环,就可以批量开始爬取啦~
接下来对不同页面之间的URL进行观察

我们发现,每翻一页,start这个参数就增加20,其他参数不变,至此我们就可以开始构建爬虫了。
数据采集的核心代码:
import requests
import re
import openpyxl
for page in range(80):
try:
params = (
('start', str(page * 20)),
('limit', '20'),
('status', 'P'),
('sort', 'new_score'),
('comments_only', '1'),
('ck', 'qN8_'),
)
r = requests.get('https://movie.douban.com/subject/32493124/comments', headers=headers, params=params, cookies=cookies)
yonghumingchengs = re.findall('', r.json()['html'], re.S)
youyongshus = re.findall('(.*?)', r.json()['html'], re.S)
pinglunshijians = re.findall('', r.json()['html'], re.S)
pingluns = re.findall('(.*?)', r.json()['html'], re.S)
for i in range(20):
a = a + 1
sheet.append([yonghumingchengs[i], youyongshus[i], pinglunshijians[i].split()[0].split("-")[-1],
pinglunshijians[i].split()[1].split(":")[0], pingluns[i]])
print(f"已爬取完第{page}页数据,存入{i + 1}条数据....")
except:
wb.save("全部.xlsx")
print(f"共爬取{page}页数据,存入{a}条数据....")
~~~02
数据处理
01
导入评论数据
用pandas读取合并后的影评数据并预览。
import pandas as pd
df = pd.read_excel('全部.xlsx',names=['用户名称','点赞数','评论日期','评论时间','评论内容'])
df.head()
02
删除重复数据
df.drop_duplicates()03
查看数据类型
df.info()字段类型和缺失值对可视化分析的影响非常大,所以要在进行可视化分析前要对其进行查看。

字段类型和缺失值符合分析需要,无需另做处理。
03
可视化分析
现在对处理过的评论数据进行可视化分析。
01
词云图展示

对评论进行词云图展示后,我们发现战争、历史、震撼、志愿军这几个词出现非常多,很符合这部剧的主题。
02
各类星级占比

从图中,我们可以明显的看出,打4星的观众最多,占了36.3%,其次是3星和5星,分别占30.8%和25.6%。这样看来,观众还是非常肯定这部影片的。
03
主演提及次数

吴京和易烊千玺的提及数最多,没想到提及最少的是段奕宏。
04
评论发表时间分布
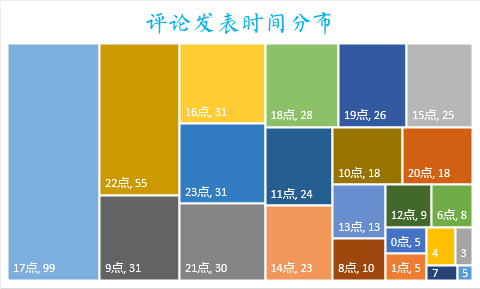
从图中,我们可以看出,大部分影评发表时间在17点、22点影院,所以可以适当增加这两个时间点的场次。
04
小结
1. 本文仅供学习研究使用,提供的评论仅供参考。
2. 本人对影视的了解有限,言论粗糙,还请勿怪。
---------End---------
顺便给大家推荐下我的微信视频号「Python数据之道」,欢迎扫码关注。