Java 集合类都在这里了,请带走!
文章目录
- Sun JDK集合包
-
- 普通集合包
-
- ArrayList
- LinkedList
- ArrayList vs. LinkedList
- Vector
- Stack
- HashSet
- TreeSet
- HashMap
- TreeMap
- 工具类
-
- Collections
- Arrays
- 并发集合包
-
- ConcurrentHashMap
- CopyOnWriteArrayList
- CopyOnWriteArraySet
- ArrayBlockingQueue
- AtomicInteger
- ThreadPoolExecutor
- Executors
- 特殊的 Fork/Join 线程计算框架
-
- Work-Stealing 算法
- ForkJoinTask
- FutureTask
- Semaphore
- CountDownLatch
- CyclicBarrier
- ReentrantLock
- Condition
- ReentrantReadWriteLock
Sun JDK集合包
关于集合的理解,需要从普通集合和能够支持并发的集合两个场景来进行,弄清楚每个典型的集合类的使用场景,每个集合的局限,以及和其他集合的比较。如何选择出合适的类来满足特定的需求,直接考验开发者的功底。
掌握这些类集合类的实现原理,以及在不同场景下的性能表现
普通集合包
理解集合包,主要从 Collection 和 Map 接口进行理解,然后考虑它们的衍生类
Collection <-- List <-- (ArrayList, LinkedList, Vector, Stack)
Collection <-- Set <-- (HashSet, TreeSet)
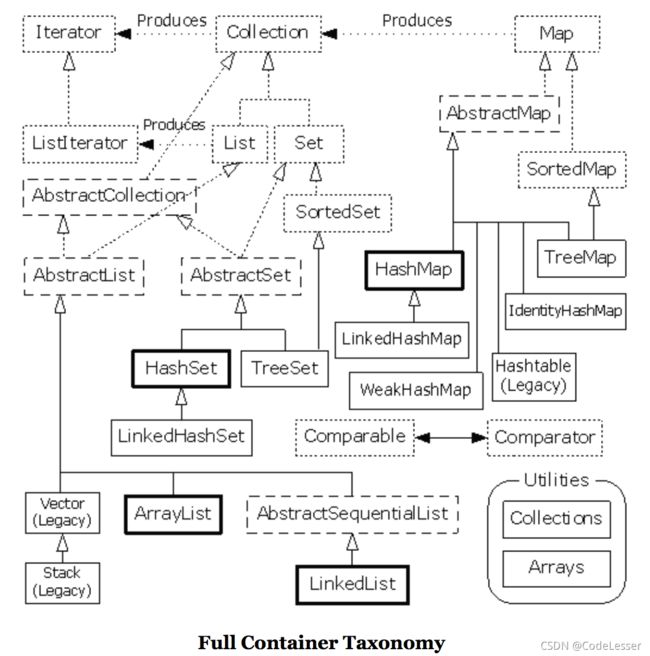
集合集成全貌
ArrayList
需要注意一下几点:
- ArrayList 是基于数组方式实现的,无容量的限制
- ArrayList 在执行插入元素时可能要扩容,在删除元素时并不会减小数组的容量(除非调用 trimToSize() 方法)
- 在查找元素时要遍历数组,对于非 null 的元素采取 equals 的方式寻找
- ArrayList 是非线程安全的
- add、ge t性能都不错,remove 性能较差
LinkedList
- LiinkedList 基于双向链表机制实现
- LinkedList 在插入元素时,须创建一个新的 Entry 对象,并切换相应元素的前后元素引用
- 在查找元素时,须遍历链表;在删除元素时,要遍历链表,找到要删除的元素,然后从链表上将元素删除即可
- linkedList 非线程安全的
ArrayList vs. LinkedList
很多教材上面都都有如下的推断:
[1]. 如果使用的 List 结构中,有频繁的 remove 动作,而 get 动作较少,推荐使用 LinkedList
[2]. 如果有大量的 get 动作,而 remove 动作较少,推荐使用 ArrayList
那么这些推断都是正确的吗?
我们来测试一下ArrayList 和 LinkedList 随机 removey 以及 get 的效率,数据量分别为 10000、30000、50000、100000
根据现象进行推理:
在随机执行 remove 的动作中,ArrayList 的 remove 效率反而比 LinkedList 的效率高,是不是感觉很意外呢?为何会出现这种情况?理论上来说,LinkedList 是基于链表的,删除只是需要修改一下指针的指向,而 ArrayList 是基于数组的,还有数组位置移动的时间代价,因而 ArrayList 的 remove 效率应该不如 LinkedList
在随机执行 get 的动作中,ArrayList 的 get 效率的确比 LinkedList 的效率高,原因是 LinkedList 每次执行 get 的时候,都是需要进行遍历寻找,这个耗时较为严重
BUT,请看下面的代码
// 在LinkedList执行删除的时候,会执行如下代码来寻找Node,该Node对象中包含了实际你add的对象
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
结论:
LinkedLis t的 remove 操作,但就链表的指针指向动作,的确比 ArrayList 的数组拷贝要快速,但是 LinkedList 在 node 方法进行对象定位的过程中,时间损耗是很客观的
那么到底上述推断[1],是不是就完全不正确了呢?其实不然,如果 List 在顺序进行 remove 的时候,ArrayList 的 remove 效率非常的糟糕,LinkedList 的 remove效率此时的优势就体现出来了,还是上面的代码 for (int i = 0; i < index; i++) 只需要遍历一次,就能定位到 Node;如果是逆序进行 remove,ArrayList 和 LinkedList 在 remove 操作上的效率相差无几,ArrayList 不用移动数组中的对象,LinkedList 也只需要遍历一次就能定位到 Node, for (int i = size - 1; i > index; i–)
get 操作可以用上述方式进行推论
所以教科书上的东西,很多都是人云亦云,技术必须自己验证过,才放心使用。话有说回来,集合类的选用,应该追求实际的业务场景,追求一种平衡
Vector
- Vector是基于 Synchronized 实现的线程安全的 ArrayList,但在插入元素时容量扩充的机制和 ArrayList 稍有不同,并可通过传入 capacityIncrement ` 来控制容量的扩充(如果不传入 capacityIncrement,则溢出时容量扩充为现有 size 的两倍)
Stack
- Stac k基于 Vector 实现,支持 LIFO
HashSet
- HashSet 基于 HashMap 实现,无容量限制
- HashSet 是非线程安全的
TreeSet
- TreeSet 基于 TreeMap 实现,支持排序
- TreeSet 是非线程安全的
HashMap
HashMap 非常的重要,要弄清楚它的实现原理
关键参数:
size:表示 HashMap 中存放 KV 的数量
capacity:指 HashMap 中桶的大小,默认为 16
loadFactor = 0.75f:装载因子,衡量 HashMap 满的程度
threshold:当 HashMap 中的 size 大于 threshold 会触发 resize 操作
需要注意一下几点:
- HashMap 采用数组方式存储 (key -> value) 构成的Entry对象,无容量限制
- HashMap 基于 key hash 寻找 Entry 对象存放到数组的位置,对于 hash 冲突采用链表的方式来解决
- Hash 在插入元素时,可能会要扩大数组的容量,在扩大容量时需要重新计算 hash,并复制对象到新的数组中
- HashMap 是非线程安全的
TreeMap
是一个典型的基于红黑树的实现,因此它要求一定要有 key 比较的方法,要么掺入 Comparator ,要么 key 对象实现 Comparable 接口
要点:
- 基于红黑树实现,无容量限制
- 是非线程安全的
工具类
Collections
需要掌握的api有:
- Collections.sort()
- Collections.copy()
- Collections.emptyXXX()
- Collections.max()
- Collections.min()
Arrays
Arrays.asList()
Arrays.sort()
Arrays.parallelSort()
Arrays.copyOf()
并发集合包
ConcurrentHashMap
关键参数:
initialCapacity、loadFactor、concurrencyLevel(default 16、0.75、16)
Segment(ReentrantLock) -> HashEntry[] , threshold=(newTable.length * loadFactor)
ConcurrentHashMap 基于 concurrencyLevel 划分出多个 Segment 来对 key-value 进行存储,从而避免了每次 put 操作都得锁住整个数组,在默认的情况下,最佳情况下可以允许 16 个线程并发无阻塞的操作集合对象,尽可能地减少并发时阻塞现象
ConcurrentHashMap 内部构造:

CopyOnWriteArrayList
使用 CopyOnWriteArrayList 是一个线程安全,使用 ReentrantLock 来保证线程安全
CopyOnWriteArraySet
基于 CopyOnWriteArrayList 实现
ArrayBlockingQueue
是一个基于数组、先进先出、线程安全的集合类、其特色为可实现指定时间的阻塞读写,并且容量是可限制的
AtomicInteger
基于 CAS 的方式
ThreadPoolExecutor
理解 ThreadPoolExecutor 的核心是,理解 Worker、Thread、corePoolSize、queue 等对象之间相互作用
4 种 RejectedExecutionHandler的实现:
- CallerRunsPolicy:当线程池中的线程数等于最大线程数后,则交由调用者线程来执行此 Runnable 任务
- AbortPolicy:当线程池中的线程数等于最大线程数时,直接抛出 RejectedExecutionException
- DiscardPolicy:当线程池中的线程数等于最大线程数时,不做任何动作
- DiscardOldestPolicy:当线程池中的线程数等于最大线程数时,抛弃要执行的最后一个 Runnable 任务
Executors
提供了一些方便创建 ThreadPoolExecuto r的方法
newFixedThreadPool(int):创建固定大小的线程池,线程 keepAliveTime 为 0,默认情况下,ThreadPoolExecutor 中启动的 corePoolSize 数量的线程启动后就一直运行,并不会犹豫 keepAliveTime 时间到达后仍没有任务需要执行就推出(LinkedBlockingQueue)
newSingleThreadExecutor():相当于创建大小为1单位的固定线程池,当使用此线程池时,同时执行的task只有1个,其他 task 都在 LinkedBlockingQueue中
newCachedThreadPool:创建 corePoolSize 为 0,最大线程数为整型的最大数,线程 keepAliveTime 为 1 分钟,缓存任务的队列为 SynchronousQueue。在使用时,放入线程池的task都会服用线程或启动新线程来执行,知道启动的线程数达到整型最大数后抛出 RejectedExecutionExeception,启动后的线程存活时间为 1 分钟
newScheduledThreadPool(int):创建 corePoolSize 为传入参数,最大线程为整型的最大数,线程 keepAliveTime 为 0,缓存任务的队列为 DelayedWorkQueue 的线程池
特殊的 Fork/Join 线程计算框架
是一个把大任务分割成若干个小任务,最后汇总每个小任务结果到大任务结果的框架
Work-Stealing 算法
某个线程从其他队列里面窃取任务来执行
ForkJoinTask
有两个子类:
RecursiveAction:代表没有返回值任务
RecursiveTask:代表有返回值任务
FutureTask
FutureTask 可用于主要异步获取执行结果或取消执行任务的场景,通过掺入 Runnable 或 Callable 的任务给 FutureTask,直接调用其 run 方法或者放入线程池执行,之后可在外部通过 FutureTask 的 get 异步获取执行结果
FutureTask 可以确保即使调用了多次 run 方法,它都只会执行一次 Runnable 或 Callable 任务,或者通过 cancel 取消 FutureTask 的执行
Semaphore
是并发包中提供的用于控制某资源同时被访问的个数的类
CountDownLatch
是并发包中提供的一个可用于控制多个线程同时开始某个动作的类,其采用的方式为减计数的方式
CyclicBarrier
和 CountDownLatch 不同,CyclicBarrier 是当 await 的数量达到设定的数量后,才继续往下执行。可重复使用
ReentrantLock
一个更为方便的控制并发资源的类
Condition
Conditio n是并发包中提供的一个接口,典型的实现有 ReentrantLock,ReentrantLock 提供一个 newCondition 的方法,以便用户竞争同一个锁的情况下可以更具不同的情况执行等待或唤醒动作
ReentrantReadWriteLock
提供做了读锁(ReadLock)和写锁(WriteLock),相比较 ReentrantLock 只有一把锁的机制而言,读写分离的好处是在读多写少的场景中可大幅提升读的效率