用图片带你串起进程列表、进程控制块、inode节点、文件描述符列表、文件实体、文件系统等知识(深度好文,建议收藏)
万文长篇,深入浅出地从进程讲起,用最简单明了的图片带你串起进程列表、进程控制块、inode节点、文件描述符列表、文件实体、文件系统等知识(深度好文,建议收藏)
- 前言
- 总览
- 一、进程、线程
-
- 1.1 什么是程序?
- 1.2 什么是进程?
- 1.3 什么是线程?
- 二、进程列表
-
- 2.1 PCB —— 进程控制块
- 2.2 小程序 —— 查看进程列表
- 三、进程实体
-
- 3.1 用户地址空间(VM)
- 3.2 进程实体与PCB、VM、PL的关系:
- 3.3 联系线程列表
- 四、通过进程联系文件系统
-
- 4.1 文件系统对文件的管理
-
- 系统(打开)文件表
- 4.2 文件描述符 fd(file descriptor)
- 4.3 进程对其打开文件的管理
- 4.3 重定向
- 五、vnode(V节点)与inode(i节点)
-
- 5.1 v节点
- 5.2 i 结点
- 5.3 文件结构和v节点、i节点关联
- 六、文件系统与磁盘
- 结语
前言
恭喜你点进一篇深度好文!推荐收藏!
如果你恰巧学习了操作系统,本文将带你把操作系统的知识细化,变得更为具体直观;
如果你还学习了Linux和Unix系统编程或是Unix高级环境编程,那么本文将有助帮你把学习到的零碎的知识点串通吃下!
本人维护该篇博客及其图片的著作权,转载请务必注明原著出处!
在于本人协商征得同以前不得用于商业用途!
总览
估计点进来的同学对于进程、线程等的概念应该都有了一定的了解,而且主要是想把关于文件的知识和进程串起来理解透,那这里就不再对进程和线程那一套知识体系(五态图、七态图等)做详细讲解了,大概讲一下进程等的概念后我们直接从进程列表开始,剥洋葱一样的开始学习。
一、进程、线程
1.1 什么是程序?
程序是用来完成特定任务的指令序列。
注意:集合是无序的,而序列是有序的
从实际上(就拿c语言)来说,一个.c文件经理预处理、编译、汇编、甚至链接这一系列过程中产生的文件,在广义上都还是属于程序的范畴。
上面说的“过程”简单示意为:
name.c —> name.o —> link成 a.out(可执行代码)
关于程序的编译过程,推荐参考这篇文章:Linux下详解gcc编译过程(含代码示例)&& gcc使用教程
1.2 什么是进程?
进程可以简洁地理解为“运行的程序”,有的解释为程序的一次执行。
更深入一些的理解:
- 当操作系统向内核数据结构中添加了适当信息,并为运行程序代码分配了必要的资源后,程序就编程了进程;
- 进程用于地址空间(它可以访问的内存)和至少一个被称为“线程(thread)”的控制流。
- 进程的五态图
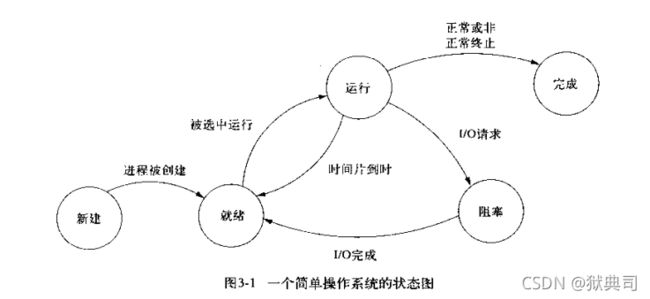
进程什么时候开始产生/运行?
进程以执行一个指令序列的控制流开始。
更深入一些的理解:
进程从单一控制流开始,从第一个激活记录(Activation Record ,可以简单理解为函数栈)产生的时候(大多数情况从main开始),执行指令序列。
拓展了解:
- cpu读取一条指令后会对PC的值做增量运算,遇到分支会做进一步修改;
- 可能有多个进程驻留在内存中并发的执行,他们基本上相互独立;
- 进程若要相互通信或合作,则必显示地通过文件系统、管道、共享内存或网络这样的操作系统结构来进行交互;
- 执行从 一个进程切到另一个进程的点被称为上下文切换;
1.3 什么是线程?
执行线程:
程序执行时,由进程程序计数器PC的值来决定下面该执行哪一条进程指令,得到的指令流被称为执行线程(thread of execution),它可以用此程序代码执行期间为程序计数器指定的零地址序列来表示。
上下文切换:
执行线程中的指令序列对于进程来说就像是一条不间断的地址流。但从处理器CPU的角度来看,来自不同进程的执行线程是混在一起的;执行从一个进程切换到另一个进程的点被称作上下文切换。
_
进程模型的自然拓展允许多个线程在同一个进程内执行。(同一进程)使用多个线程可以避免上下文切换,并允许共享代码和数据(即共享地址),籍此改善性能。
线程:
线程代表了进程内执行线程的一种抽象的类型,有独立的执行栈、程序计数器值、寄存器组和状态。
二、进程列表
为了管理与调度,操作系统会维护一张进程列表(简称为PL)。
以Linux来说,该进程列表的表项是一个PCB块。
PCB(Process Control Block,程序控制块)是一种数据结构,包含进程的相关信息。系统利用PCB描述进程的情况和活动过程,并控制管理进程。
一定要注意的是:PCB块是由内核来管理和调度的,不属于用户空间!
这个理解很重要!是理解进程实体的关键!
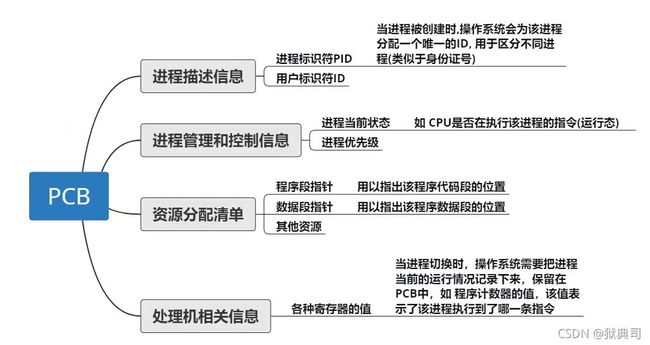
2.1 PCB —— 进程控制块
进程控制块(PCB 即 Process Control Block)是进程状态信息的集合,用来描述进程和用于进程的管理和调度,用PCB可以区分不同的进程。
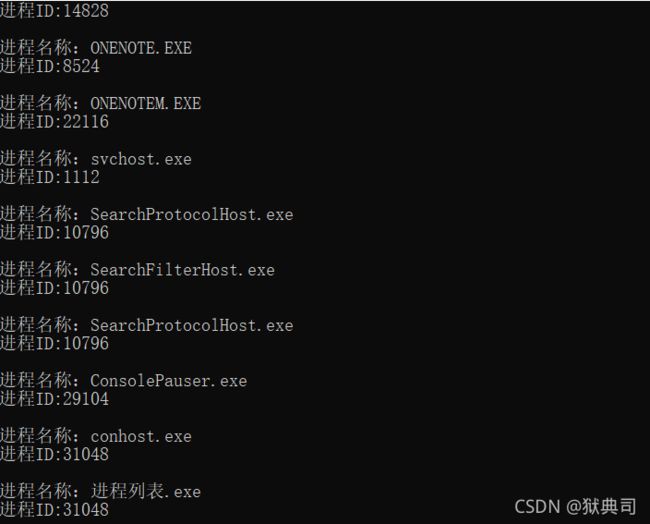
2.2 小程序 —— 查看进程列表
感兴趣的话可以跑一下面的c++程序,来看一下Windows下的进程列表。
#include- 运行结果:
PCB主要包含的信息有
| 属性 | 说明 |
|---|---|
| 标识符PID(identifier) | 唯一标识进程 |
| 状态(state) | 进程的当前状态(运行/就绪/等待) |
| 优先级(priority) | 相对于其他进程的优先级别(做内存调度时使用) |
| 程序计数器(PC = Program Counter) | 即将被执行的下一条程序指令的地址 |
| 内存指针(memory pointers) | 包括指向程序代码、相关数据和共享内存的指针 |
| 上下文数据(context data) | 进程被中断时处理器寄存器中的数据,可以用于进程的恢复 |
| 记帐信息(accounting information) | 包括占用处理器时间、时钟数总和、时间限制、账号等,比如在进程处于退出态时可以取出PCB的记账信息来做性能分析 |
| I/O状态信息(I/O status information) | 包括显式I/O请求、分配给进程的I/O设备、被解除使用的文件列表等 |
三、进程实体
学习过操作系统的同学肯定都背过这样的标准答案:
“ 进程实体由代码段、数据段和PCB组成 ”;
这句标答确实没有毛病,但是对于学习Unix系统编程/高级Unix环境编程的同学来说这样的理解肯定是不够的,我们还要从内核空间和用户空间的角度对进程实体做区分。
首先我们来看看进程列表PL是怎么和进程实体挂上钩的
操作系统维护的进程列表的表项为PCB,而每个PCB对应一个进程实体。
回顾一下,我们在操作系统中记忆的标准答案——“进程实体由数据段、代码段、PCB构成”,这里所说的数据段和代码段其实指的是 “进程用户地址空间”。
3.1 用户地址空间(VM)
| 属性 | 说明 |
|---|---|
| 环境变量 | 用于指定操作系统运行环境的一些参数 |
| 栈 (Stack) | 存储局部、临时变量,函数调用时,存储函数的返回指针,用于控制函数的调用和返回。在程序块开始时自动分配内存,结束时自动释放内存,其操作方式类似于数据结构中的栈 |
| 堆 (Heap) | 存储动态内存分配,需要程序员手工分配,手工释放。注意它与数据结构中的堆是两回事,分配方式类似于链表 |
| 未初始化全局变量(BSS) | 在程序运行初未对变量进行初始化的数据 |
| 初始化全局变量(Data) | 在程序运行初已经对变量进行初始化的数据 |
| 程序段(Text) | 程序代码在内存中的映射,存放函数体的二进制代码 |
- 用户地址空间示意图
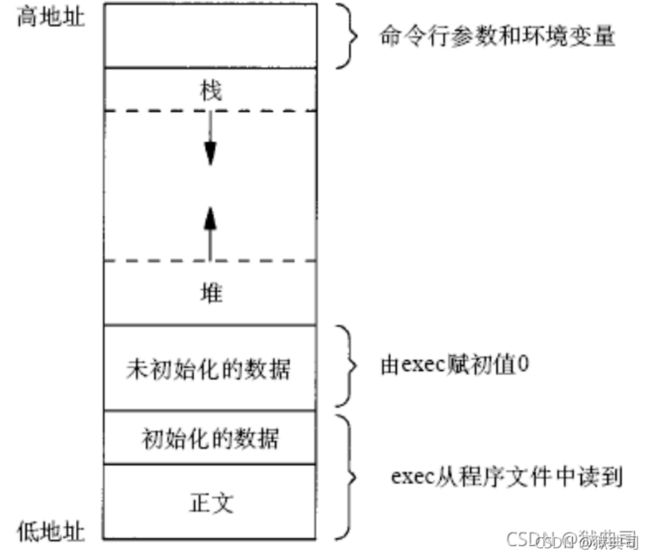
拓展理解性知识:
程序加载之后,可执行程序看起来占据了一个连续的内存块,这个连续的内存块被称为程序映像(program image)。程序映像有几个不同的分区。程序文本或代码显示在内存低端地址中。在映像中已初始化和未初始化的静态变员也有自己的分区。其他的分区包括堆、栈和环境。
活动记录(activation record)
活动记录是在进程栈顶端分配的一个内存块,用来 装载调用过程中函数的执行上下文 。每次函数调用都在栈上创建一个新的活动记录。假如嵌套的函数调用按照后调用先返回的次序工作,那么,函数返回时会将活动记录从栈中删除。
活动记录包括返回地址、参数(参数值从相应的命令行参数小拷贝而来)、状态信息和调用时某些CPU寄存器值的拷贝。进程从记录表示的调用中返回时,要恢复寄存器的值。活动记录中还包括含数执行时在其内部分配的自动变量。活动记录的特定格式取决于硬件和编程语言。
除了静态变量和自动变量之外,程序映像中还包括了argc和argv占用的空间以及 malloc分配的空间。 malloc含数族在一个被称为堆(heap)的空闲内存池中分配存储空间。在堆上分配的存储空间一直存在,直到它被释放或程序退出为止。 如果一个函数调用了 malloc,那么在这个函数返问之后,存储空间仍保持已分配状态。除非程序有一个在函数返叫之后仍然可以访间的指向该存储空间的指针,否则,返回后的程序就不能访问它。
在声明时没有显式初始化的静态变量在运行时被初始化为0。 注意,在程序映像中, 已初始化的静态变量和未初始化的静态变量占据不同的分区。 通常, 已初始化的静态变量是磁盘上可执行模块的一部分,而未初始化的静态变量则不是。 当然,自动变量不是可执行模块的一部分,因为只有当定义它们的程序块被调用时,它们才被分配。除非程序显式地对自动变运进行初始化,否则,它们的初始值是不确定的。
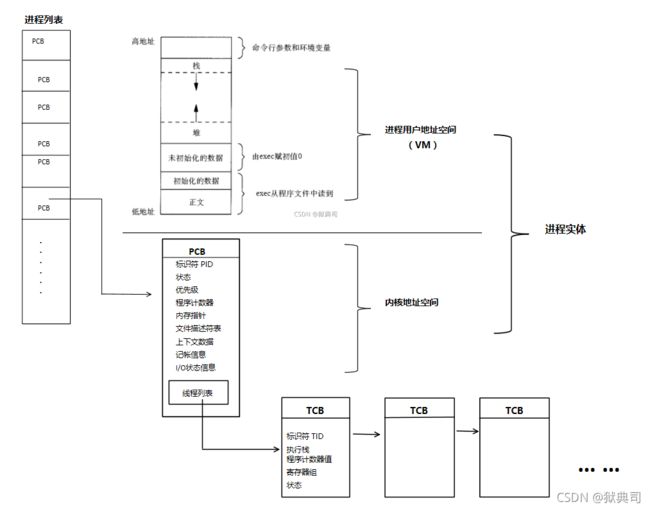
3.2 进程实体与PCB、VM、PL的关系:
经过上面知识的学习,我们可以还原构思出进程列表与进程实体、用户地址空间、程序控制块的联系了:

需要注意的是PCB属于内核空间,我们可以看到PCB中存储的信息都是供内核进行调度、管理、操作的(用户空间无法对其进行操作)。
3.3 联系线程列表
我们再来回顾一下线程的概念:
(1)(同一进程)使用多个线程可以避免上下文切换,并允许共享代码和数据(即共享地址)
(2) 线程代表了进程内执行线程的一种抽象的类型,有独立的执行栈、程序计数器值、寄存器组和状态。
- 线程列表示意图:
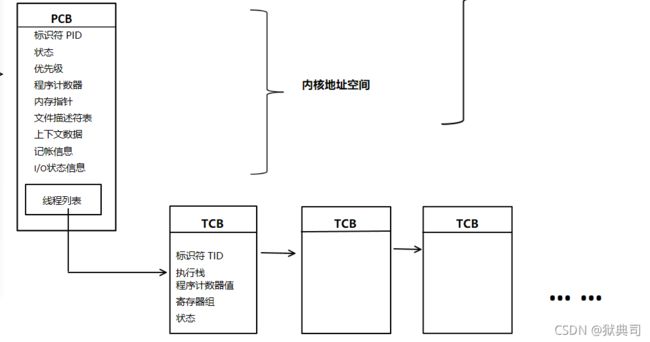
线程要执行的代码都共享进程用户地址空间中的文本段(Text),且共享进程用户地址空间中的数据,但是要注意的是线程有独立的执行栈、程序计数器值、寄存器组和状态。
- 进程相关关系全貌图:
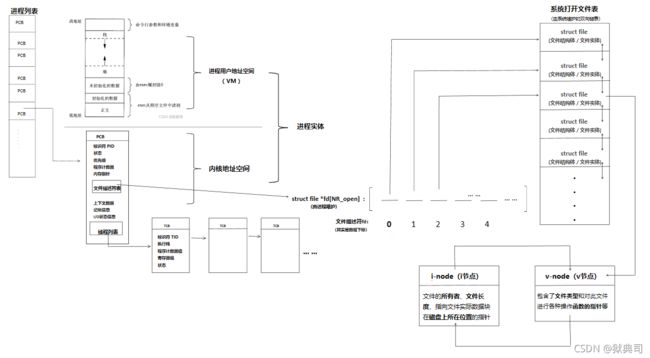
四、通过进程联系文件系统
关于操作系统中打开的文件,进程和文件系统对其各有各的管理,要注意区分进程对打开文件的管理和系统对打开文件的管理!
4.1 文件系统对文件的管理
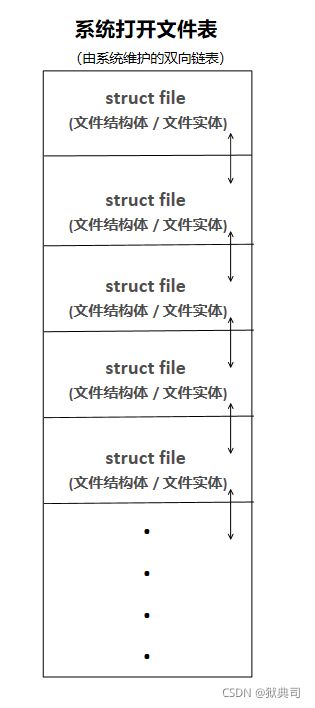
系统(打开)文件表
Linux系统内核把所有进程打开的活动文件集中进行管理,把它们组成“系统打开文件表”。
系统打开文件表是一个双向链表,它的每一个表项(节点)是一个file结构,称为文件结构体。
文件结构体 —— struct file
struct file {
mode_t f_mode; 文件的打开模式
loff_t f_pos; 文件的当前读写位置
unsigned short f_flags; 文件操作标志
unsigned short f_count 共享该结构体的计数值
struct file *f_next, *f_prev; 链接前、后节点的指针 (双向链表)
struct inode *f_inode; 指向文件对应的inode
void file_operations *f_op; 指向文件操作结构体的指针
void *private_data; 指向与文件管理模块有关的私有数据的指针
};
4.2 文件描述符 fd(file descriptor)
我们可以看到在PCB中有文件描述符表,这张表是进程本身用于对其打开的文件做相关操作的依据。
什么是文件描述符?
内核(kernel)利用文件描述符(file descriptor)来访问文件。文件描述符是非负整数。打开现存文件或新建文件时,内核会返回一个文件描述符。读写文件也需要使用文件描述符来指定待读写的文件。
按照惯例,Unix系统shell把文件描述符0与进程的标准输入(STDIN_FILENO)相关联系,将文件描述符1与进程的标准输出(STDOUT_FILENO)相关联,将文件描述符2与进程的标准错误输出(STDERR_FILENO)相关联。
4.3 进程对其打开文件的管理
对于一个进程打开的所有文件,由进程的两个私有结构进行管理:
(1)fs_struct 结构:记录着文件系统根目录和当前目录
(2)files_struct 结构:包含着进程打开的文件表
fs_struct结构 —— 记录着文件系统根目录和当前目录
struct fs_struct {
int count; 共享此结构体的计数值
unsigned short umask; 文件掩码
struct inode *root, *pwd 根目录和当前目录的inode指针
};
files_struct 结构——包含着进程打开文件表
Struct files_struct {
int count; 共享该结构的计数值
fd_set open_fds; 文件描述符状态位
struct file *fd[NR_open] 进程(打开)文件表描述符表
//可以看到这里面以指针数组的形式存储着文件描述符表,指向的是 struct file结构
( struct file结构即系统管理文件表中的表项 —— 文件结构体)
}
有点绕?不要着急,看一下文字理论先有个印象再看图片就清晰了。
上面这个files_struct 结构中的
struct file *fd[NR_open]数组就是我们所说的“进程实体中的(打开)文件描述符表”,需要注意的是文件描述符在这里并不做实际的变量,而是这个数组的下标 !!!

上图中所标出的指针就是struct file *fd[NR_open]中存储的指针,即文件结构体的地址(或者说是指向文件结构体的指针),我们把它俩串起来:

4.3 重定向
有了上图的理解,那理解重定向就简单了。
重定向的操作就是将文件描述符表中指向文件结构的指针替换成其他文件(或设备)的文件结构的指针。
比如在Unix的shell中一般规定文件描述符1是标准输出,将文件描述符1的对应的指针指向别的文件,就可以完成一个简单重定向,把标准输出输出到指定的文件中。
然后我们再把进程实体也联系进来:

需要注意的是:
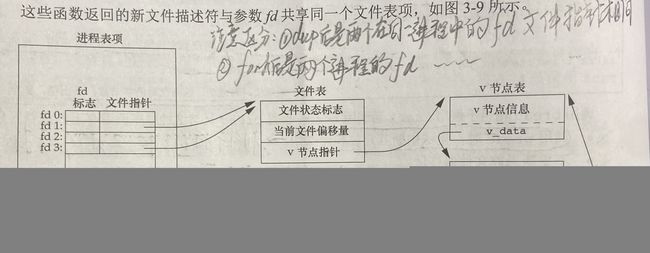
不同的进程 “打开” (这个打开的概念很重要)一个相同的文件时,并不会指向系统文件表中的同一个文件结构体(struct file),而是各自创建各自的文件结构体,并在自身(进程实体)的文件描述符表中存储指向该文件结构的指针。
但是有三种种情况比较特殊:
- 当父进程fork出子进程时,由于父进程文件描述符表也被子进程复制(连同指针),故这时子进程和父进程虽然不是同一个进程,但是都指向同一个文件结构,直到子进程被exec擦除其文件描述符表(之类关闭文件描述符的情况);注意fork操作并没有涉及open操作(有“一次open创建一个struct”的说法)。

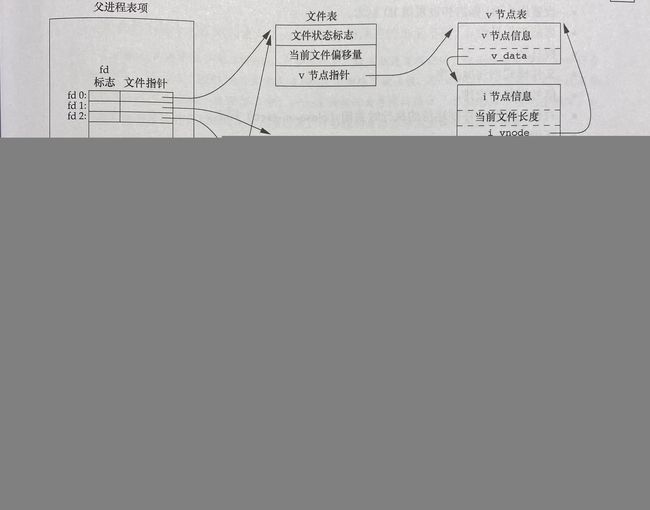
- 当同一进程使用dup函数(用于复制fd到最小未使用fd)时,文件描述符表中复制出来的fd和被复制的fd指向同一个文件结构。
- 当同一进程使用时dup2函数时,会在把fd1复制到fd2后把fd1关掉(若是fd2已存则先把fd2关掉),有点剪切那意思;
注:dup2函数:用于复制fd到指定fd,函数形式为dup2(fd1,fd2),其中fd1是被复制的fd,fd2是指定复制到的fd。
[图片引用自《高级Unix环境编程》(第三版)]
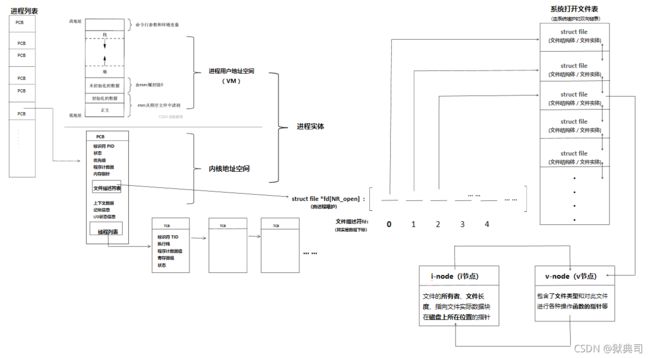
五、vnode(V节点)与inode(i节点)
读到这里相信我们对进程与文件的一系列关系以及比较明朗了,但是在文件系统中还有两个很重要的角色 —— i节点与 v节点。
5.1 v节点
每个 打开文件(或设备) 都有 唯一的v节点(v-node)结构。
v 节点包含了 文件类型和对 此文件进行各种操作函数的指针。
对于大多数文件,v节点还包含了该文件的i节 点(i-node,索引节点)。这些信息是在打开文件时从磁盘上读入内存的,所以文件的所有相关信息都是随时可用的。
Linux 没有使用v节点,而是使用了通用i节点结构。虽然两种实现有所不同司,但在概念上 v节点与i节点是一样的。两者都指向文件系统特有的i节点结构。
5.2 i 结点
i节点包含了文件的所有者、文件长度、指向文件实际数据块在磁盘上所在位置的指针等;
i节点又指向v节点。i-node节点结构(128B):
- 文件编号
- 文件类型
- 文件权限
- 文件长度
- Block 的数量
- 最近的时间信息(创建、访问、修改)
- 指针(直接指针、二级指针、三级指针)
- 存储该文件的目录数
5.3 文件结构和v节点、i节点关联
示意图如下:
六、文件系统与磁盘
讲到 i-node的话再往下就是磁盘的相关知识了,这里暂时不再往下拓展了,暂时先放两张图,之后会专门写一篇关于i-node和磁盘的博客,要是写完了会把链接贴在这里滴,不妨点个关注再走哦 。^ _ ^ 。
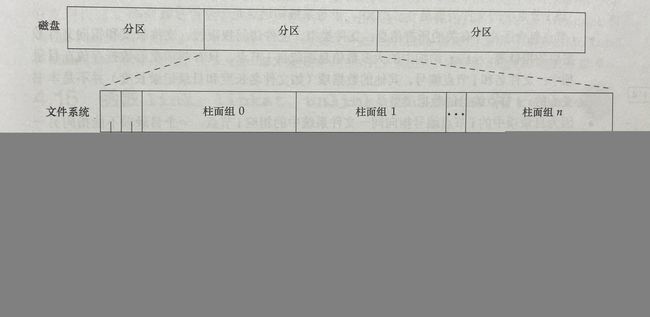

[图片引用自《高级Unix环境编程》(第三版)]
结语
原创不易,如有帮助,感谢点赞收藏关注!