一 项目描述
1.1 背景
MHA(Master HA)是一款开源的 MySQL 的高可用程序,它为 MySQL 主从复制架构提供了 automating master failover 功能。MHA 在监控到 master 节点故障时,会提升其中拥有最新数据的 slave 节点成为新的master 节点。自动FailOver的前置条件一定是MHA是启动运行的状态。在生产环境中,有时会因为没有及时开启或者运行异常停止而不知,导致MySQL主节点异常时,没有自动FailOver,影响了生产,或延长了处理时间,使故障升级。
此外,MHA发生FailOver后,MHA的运行状态会由 is running(0:PING_OK) 变更为stopped(2:NOT_RUNNING),从运行反馈结果变化上,可以判断是否可能发生了主从切换。可以作为一个Warning处理。
综上,对MHA的运行状态的监控很有必要。
1.2 实现设计
MHA是运行在Manager 节点上的,一个Manager 节点可以管理数十个集群。目前,我们的监控体系是Telegraf + InfluxDB + Grafana,所以,需要在Manager 节点部署Telegraf,去收集MHA的运行状态,保存到 InfluxDB。在既有的Grafana MySQL Dashboard中,添加一个关于 masterha_check_status 的panel 即可。
1.2.1 之前的方法
在 《以实现MongoDB副本集状态的监控为例,看Telegraf系统中Exec输入插件如何编写部署》 一文中的第七部分,我们有介绍一种方法实现MySQL MHA的监控,但这种方法是每一个集群都需要手动维护,自动发现的功能不够好,增加维护成本,特别是集团的MHA集群比较多时。
1.2.2 优化后的方法
Manager 节点为每个监控的MHA集群提供一个专用的配置文件,优化后的监控方法,根据配置文件自动发现、自动调整监控,不再需要逐一配置和维护。
部署的步骤如下:

二.实现详情
2.1 编辑Python可执行文件
可执行文件为telegraf_checkmhastatus.py
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import os
import io
import re
import ConfigParser
Path='/cnf/mhacnf'
#fout=open('输出文件名','w')
for Name in os.listdir(Path) :
Pathname= os.path.join(Path,Name)
## print(Pathname)
## print(Name)
config =ConfigParser.ConfigParser()
try:
config.read(Pathname)
server_item = config.sections()
server1_host = '' ##MHA cnf 配置文件中的节点1
server2_host = '' ##MHA cnf 配置文件中的节点2
server3_host = '' ##MHA cnf 配置文件中的节点3
mha_cnf_remark = ''
if 'server1' in server_item:
server1_host = config.get('server1','hostname')
else:
server1_host = ''
mha_cnf_remark = mha_cnf_remark + 'Server1未配置;'
if 'server2' in server_item:
server2_host = config.get('server2','hostname')
else:
server2_host = ''
mha_cnf_remark = mha_cnf_remark + 'Server2未配置;'
if 'server3' in server_item:
server3_host = config.get('server3','hostname')
##print(mha_cnf_remark)
except Exception as e:
print(e)
mha_status_result =''
if server1_host <> '' and server2_host <> '':
cmd_mha_status ='/usr/local/bin/masterha_check_status --conf='+Pathname
with os.popen(cmd_mha_status) as mha_status:
mha_status_result = mha_status.read()
if 'running(0:PING_OK)' in mha_status_result:
print('masterha_check_status,server='+server1_host+' Status=1i')
print('masterha_check_status,server='+server2_host+' Status=1i')
if 'stopped(2:NOT_RUNNING)' in mha_status_result:
##else:
print('masterha_check_status,server='+server1_host+' Status=0i')
print('masterha_check_status,server='+server2_host+' Status=0i')
说明:
- (1)遍历
/cnf/mhacnf目录下的文件(假设MHA配置文件的配置文件在此目录下); - (2)对每个文件执行
masterha_check_status --cong = XXXX,XXXX为具体的配置文件;判断运行结果; - (3)获取MHA集群节点;
- (4)因为我们MHA集群都是一主一从,所以,只
if server1_host <> '' and server2_host <>'':一种情况,大家可根据需要,根据具体的场景,变更。 - (5)数据保存到名叫
masterha_check_status的measurement中,Tag Key有host和server;当运行OK时,Status=1,否则,Status=0。 - (6)
Server对应的数据为Server IP(注意,会在grafana配置时以此关联)。
2.2 修改 telegraf 文件
文件默认目录为/etc/telegraf/,默认文件为telegraf.conf。
将执行文件嵌入到telegraf.conf中,由python驱动。
代码如下:
[[inputs.exec]] ##Commands array commands = ["python /data/check_mha_status/check_mha_status.py",] timeout='60s' data_format="influx"

2.3 修改telegraf service的运行账号
telegraf服务的启动账号默认为telegraf,但是,其中调用了Python和python的可执行文件,需要修改权限。为了简便,升级telegraf service的运行账号,修改成root。
修改telegraf.service,默认路径为/usr/lib/systemd/system/telegraf.service。
修改后的代码如下:
[Unit] Description=The plugin-driven server agent for reporting metrics into InfluxDB Documentation=https://github.com/influxdata/telegraf After=network.target [Service] EnvironmentFile=-/etc/default/telegraf ##User=telegraf User=root ExecStart=/usr/bin/telegraf -config /etc/telegraf/telegraf.conf -config-directory /etc/telegraf/telegraf.d $TELEGRAF_OPTS ExecReload=/bin/kill -HUP $MAINPID Restart=on-failure RestartForceExitStatus=SIGPIPE KillMode=control-group [Install] WantedBy=multi-user.target
2.4 启动Telegraf 服务
service telegraf start ####启动服务 service telegraf status ####服务状态查看 service telegraf stop ####关闭服务
2.5 配置Grafana,增加Panel
因为MySQL实例节点的telegraf也会汇报各自的数据,例如MySQL连接数、TPS、QPS、主从状态、延迟、资源(CPU、内存、磁盘、IOWait)等等,这些指标在一个Dashboard上,而新收集的MHA运行状态是新增的的一个MySQL指标,所以,应该将MHA运行状态作为既有MySQL Dashboard的一个Panel。
在MySQL实例节点上汇报的数据是各个节点的host 和 instance(Server IP:端口);而MHA 运行状态汇报的数据是manager节点的host 和 各个实例Server IP。所以,依据Host 关联,整合到一个Dashboard是实现不了的(因为没有关联性)。只能通过 instance(Server IP:端口) 和 Server IP 进行关联了。
首先,将instance(Server IP:端口) 正则下,去除端口数据,实现方式,增加一个grafana变量--server_ip,如下:
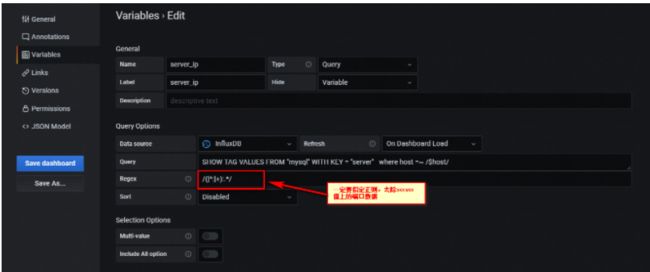
注意上面的数据源来自measurement为mysql。
然后,再增加一个grafana变量--mha_server,注意,会依赖上面的变量server_ip。
这样 mysql 和 masterha_check_status 两个measurement就关联起来了,可以联动了。

最后,增加 panel设置下,就可以了,如下。

SQL 语句如下:
SELECT mean("Status") FROM "masterha_check_status" WHERE ("server" =~ /^$mha_server$/) AND $timeFilter GROUP BY time(1m) fill(null)
三 .实现

运行状态为1,异常或关闭为0.
还可以增加Alarm告警,例如邮箱、微信、钉钉等,在此就不展开了。
补充一点:
因为优化后的监控方法,根据配置文件自动发现、自动调整监控。所以,如果新增一个MHA,而这个过程又比较长,比如10分钟,这个时候,既有的MHA监控可能会报错或报警。
为了避免这种情况发生,建议新增的MHA的配置文件,最后再放至到MHA配置文件的目录上。或者,先将配置文件放到其他的目录上,MHA配置OK后,最后一步再移到/cnf/mhacnf目录下。
到此这篇关于MySQL MHA 运行状态监控介绍的文章就介绍到这了,更多相关MySQL MHA 运行状态监控内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!