Java云同桌学习系列(二十一)——redis数据库
本博客java云同桌学习系列,旨在记录本人学习java的过程,并与大家分享,对于想学习java的同学,我希望这个系列能够鼓励大家一同与我学习java,成为“云同桌”。
每月预计保持更新数量三章起,每章都会从整体框架入手,介绍章节所涉及的重要知识点及相关练习题,并会设置推荐学习时间,每篇博客涉及到的点都会在开篇目录进行总览。(博客中所有高亮部分表示是面试题进阶考点)
很抱歉大家,最近两周在,忙着找工作以及收拾毕业的包裹,所以拖更了一周之久,所幸也拿到了10K+的offer,接下来今天带给大家的是Redis数据库,我们之前学过Mysql数据库,主要是用于存放大量的数据,但对于一些常用的数据,频繁的从MySQL中调取会浪费很多资源与时间,所以可以将一些常用的数据作为缓存,放到Redis缓存数据库中使用,优化数据持久化。
redis数据库
-
- 1. NoSQL与redis概述
- 2. Linux环境下安装redis数据库
- 3. redis数据类型
- 4. redis常用命令
- 5. redis事务管理
- 6. redis订阅机制
- 7. Jedis连接Redis
- 8. redis持久化策略
-
- 8.1 RDB持久化策略
- 8.2 AOF持久化策略
- 8.3 RDB与AOF的比较
- 9. redis主从复制与哨兵模式
-
- 9.1 搭建主从数据库结构步骤
- 9.2 哨兵模式
- 10. redis集群
-
- 10.1 集群哈希槽机制
- 10.2 集群容错机制
- 10.3 集群搭建步骤
- 10.4 Jedis连接集群
- ==11. redis缓存问题==
-
- 11.1 缓存雪崩
- 11.2 缓存击穿
- 11.3 缓存穿透
学习时间:一周
学习建议:redis缓存数据库在一些需要大量数据交互的场景下非常有用,可以显著降低主数据库压力,因此很要必要进行学习。
1. NoSQL与redis概述
随着数据量的不断增大、高并发处理要求提高,于是便兴起了NoSQL(非关系型数据库)
NoSQL有一些显著的特点:
- 可扩展性强
NoSQL数据库去掉的关系型数据库之间数据的关系,提高了架构扩展能力 - 可应对大数据量数据,交互性能强
NoSQL所使用的是一种细粒度的Cache,对于数据频繁的交互相对更大级别的Cache性能更高 - 数据模型灵活
NoSQL无需事先为数据建立字段,可随时自定义数据的数据格式 - 高可用
NoSQL在不太影响性能的情况,就可以方便的实现高可用的架构。比如Cassandra,HBase模型,通过复制模型也能实现高可用。
常见的一些NoSQL数据库特点及比较:
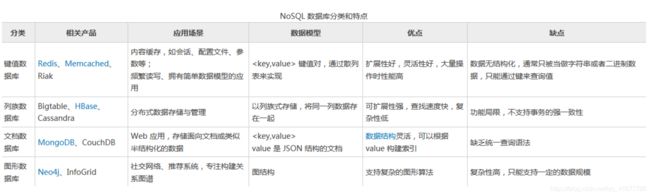
redis数据库:基于内存运行并支持持久化的一个高性能(key-value)分布式NoSQL数据库
redis的优点:
- 丰富数据类型
Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储 - 可持久化且性能较高
可将数据保存在磁盘中,读写速度较快 - 原子性
Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。 - 单线程
避免各种多线程常见问题,不需要考虑锁问题与上下文切换问题 - 多路I/O
使用多路I/O复用模型,非阻塞IO;
redis的常见应用场景:
- 缓存
- 任务队列
- 分布式集群架构
2. Linux环境下安装redis数据库
详细步骤请查看:Ubuntu安装Redis及使用——作者hzlarm
-
网络环境下在线安装:
sudo apt-get install redis-server -
启动服务:
redis-server -
启动客户端:
redis-cli -h ip地址 -p 端口号(未修改/etc/redis/redis.conf下的bind时不需要指定ip地址和端口号) -
查看redis进程:
ps -aux | grep redis,可以看到redis默认的端口号是6379fb@fb-virtual-machine:~/redis$ ps -aux | grep redis redis 17954 0.3 0.1 53200 3844 ? Ssl 19:49 0:03 /usr/bin/redis-server 192.168.188.131:6379 fb 18245 0.0 0.0 16184 1020 pts/0 S+ 20:06 0:00 grep --color=auto redis
判断redis数据库是否连接成功:
1. 能够进入redis客户端,即`redis-cli -h ip地址 -p 端口号`不报错
2. 使用ping命令,会返回pong命令
redis图形化界面:推荐开源的AnotherRedisDesktopManager
在/etc/redis/redis.conf配置文件中将bind更改为linux系统的ip地址,即可通过图形化界面进行外部的连接,后续在使用jedis连接也需要这一步
3. redis数据类型

4. redis常用命令
详细内容请查看:菜鸟编程redis命令
- 远程连接redis数据库:
redis-cli -h host -p port -a password
可能出现中文乱码:可以使用redis-cli --raw
(注:返回值为1代表成功,返回值0代表失败,默认数据类型是String)、
- String类型
> set key hello,wolrd
OK
> get key
hello,wolrd
| 命令 | 描述 |
|---|---|
| set key value | 新建key-value |
| get key | 获取对应的value值 |
| mget key1 [key2…] | 获取所有(一个或多个)给定 key 的值。 |
| del key | 在 key 存在时删除 key |
| exists key | 检查给定 key 是否存在 |
| expire key seconds | 为给定 key 设置过期时间,以秒计 |
| keys pattern | 查找所有符合给定模式( pattern)的 key |
| rename key newkey | 修改 key 的名称 |
| getset key value | 将给定 key 的值设为 value ,并返回 key 的旧值(old value)。 |
| incr key | 将 key 中储存的数字值+1,可使用incrby命令与数字参数指定步长 |
| decr key | 将key中存储的数据-1,可使用decrby命令与数字参数指定步长 |
- 哈希(Hash)类型:Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表
> hset key_hash demo1 hello,hash
1
> hget key_hash demo1
hello,hash
> hgetall key_hash
demo1
hello,hash
| 命令 | 描述 |
|---|---|
| hset key field value | 将哈希表 key 中的字段 field 的值设为 value 。 |
| hget key field | 获取存储在哈希表中指定字段的值。 |
| hgetall key | 获取在哈希表中指定 key 的所有字段和值 |
| hdel key field1 [field2] | 删除一个或多个哈希表字段 |
- 列表(List):Redis列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)
> lpush key_list 1 2 3
3
> lpop key_list
3
> rpop key_list
1
| 命令 | 描述 |
|---|---|
| lpush key value1 [value2] | 将一个或多个值依次插入到列表最左 |
| lpop key | 移出并获取列表最左的元素 |
| rpush key value1 [value2] | 将一个或多个值依次插入到列表最右 |
| rpop key | 移出并获取列表最右的元素 |
| llen key | 获取列表长度 |
| lindex key index | 通过索引获取列表中的元素 |
| lset key index value | 通过索引设置列表元素的值(索引从0开始,对应从左往右的值,-1代表最右的值) |
| lrange key start end | 获取列表指定范围内的元素 |
- 集合(set):Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
> sadd key_set 1 1 2 3 4 5 6
6
> smembers key_set
1
2
3
4
5
6
| 命令 | 描述 |
|---|---|
| sadd key member1 [member2] | 向集合添加一个或多个成员 |
| smembers key | 返回集合中的所有成员 |
| srem key member1 [member2] | 移除集合中一个或多个成员 |
| scard key | 获取集合的成员数 |
- redis有序集合(sorted set):
- Redis 有序集合和集合一样也是 string 类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个 double 类型的分数。
- redis 正是通过分数来为集合中的成员进行从小到大的排序。
- 有序集合的成员是唯一的,但分数(score)却可以重复。
> zadd key_sortedSet 5 demo2 3 demo3 1 demo1
3
> zrange key_sortedSet 0 -1
demo1
demo3
demo2
| 命令 | 描述 |
|---|---|
| zadd key score1 member1 [score2 member2] | 向有序集合添加一个或多个成员,或者更新已存在成员的分数 |
| zrem key member [member …] | 移除有序集合中的一个或多个成员 |
| zrank key member | 返回有序集合中指定成员的索引 |
| zcard key | 获取有序集合的成员数 |
| zrevrank key member | 返回有序集合中指定成员的排名,有序集成员按分数值递减(从大到小)排序 |
redis默认有16个数据库,下标从0-15,客户端默认连接第0号数据库
- 切换数据库
select 数据库下标 - 数据库之间移动数据
move key 数据库下标
5. redis事务管理
redis中的事务可以一次执行多个命令,事务中的命令要不全部失败,要不全部成功
通过分为:开始事务、命令入队、执行事务
- 开始事务命令:
multi - 命令入队:输入要放入事务的命令
- 执行事务命令:
exec - 回滚事务命令:
discar
> multi
OK
> set key hello,redis
QUEUED
> get key
QUEUED
> exec
OK
hello,redis
对于事务回滚的能力与mysql中是不同的:
-
Redis在执行事务命令的时候,在命令入队的时候, Redis 就会检测事务的命令是否正确,如果不正确则会产生错误。无论之前和之后的命令都会被事务所回滚,就变为什么都没有执行。
-
当命令格式正确,而因为操作数据结构引起的错误 ,则该命令执行出现错误,而其之前和之后的命令都会被正常执行,只有该错误会导致该条指令不执行。
举个简单的例子:
- 如果我们的命令语法出错,事务就会回滚
- 如果我们命令语法没有出错,是因为比如无法给字符串自增这样的问题导致执行时出现问题,则不影响事务中其他命令
所以,在使用redis时,就需要程序员特别注意数据类型不合适这些可能在执行中导致命令出错的情况
6. redis订阅机制
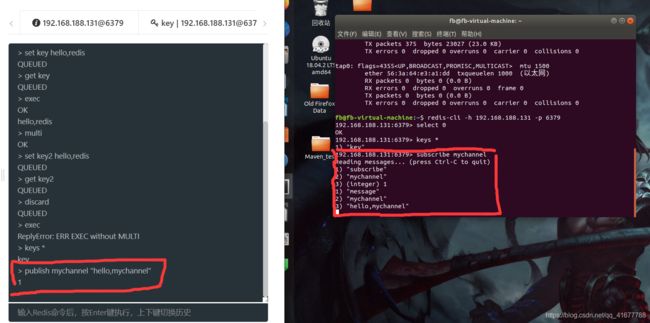
redis存在一种通信模式:订阅模式,即多个客户端订阅了一个频道后,可以自动接收发布到该频道的内容

- 订阅频道:
subscribe 频道名 - 发布内容至频道:
publish 频道名 内容字符串
7. Jedis连接Redis
连接redis数据库一般我们使用Jedis来进行连接,又可分为直接连接和使用连接池连接数据库
1.直接连接
jedis的最新版maven坐标为:
<dependency>
<groupId>redis.clientsgroupId>
<artifactId>jedisartifactId>
<version>3.4.1version>
<type>jartype>
<scope>compilescope>
dependency>
确保redis数据库所在主机能够被ping通,通过Jedis构造方法建立与redis的连接
//传入redis主机ip地址和redis对应端口号
Jedis jedis = new Jedis("192.168.188.131",6379);
//同样,使用完毕后不要忘记关闭
jedis.close();
使用过程中,jedis的方法名基本和redis命令一致,上手还是非常快的
2.使用连接池连接
jedis中野通过连接池类来方便连接,即jedisPool类,非常的简单便于管理,也可以作为一个工具类随取随用
// 1.获取连接池配置对象,设置配置项
JedisPoolConfig config = new JedisPoolConfig();
// 1.1最大的连接数 config.setMaxTotal(30);
// 1.2最大的空闲
config.setMaxIdle(10);
// 2.获取连接池
JedisPool jedisPool = new JedisPool(config, "192.168.188.131", 6379);
Jedis jedis = null;
try {
jedis = jedisPool.getResource();
// 3. 取出数据
jedis.select(0);
System.out.println(jedis.get("key"));
} catch (Exception e) {
e.printStackTrace();
} finally {
//关闭连接
if (jedis != null) {
jedis.close();
}
// 4.虚拟机关闭的时候,释放资源,关闭连接池
if (jedisPool != null) {
jedisPool.close();
}
}
8. redis持久化策略
redis数据库持久化默认是使用RDB文件进行持久化存储,还有一种是使用AOF文件进行持久化
8.1 RDB持久化策略
RDB文件是二进制文件,RDB是默认的持久化策略,是在间隔某个时间段后将数据写入rdb文件,并替换原有rdb文件来进行数据保存。
这是间隔的时间段可以自己在配置文件中进行修改,,通过配置redis 在 n 秒内如果超过m 个 key 被修改这执行一次 RDB 操作。
如:
#save时间,以下分别表示更改了1个key时间隔900s进行持久化存储;更改了10个key300s进行存储;更改10000个key60s进行存储。
save 900 1
save 300 10
save 60 10000
所以在间隔时间内发生故障就可能会导致数据丢失,通常用于数据不是那么重要的情况下
但这种持久化策略是使用单线程进行持久化的,和主线程不会进行IO,确保了redis的高性能
8.2 AOF持久化策略
AOF(Append-Only File):将“操作 + 数据”以格式化指令的方式追加到操作日志文件.aof的尾部,在 append 操作返回后(已经写入到文件或者将要写入),才进行实际的数据变更,“日志文件”保存了历史所有的操作过程;当 server 需要数据恢复时,可以直接 replay 此日志文件,即可还原所有的操作过程,因为里面记录了所有操作和数据(可以理解为日志文件)
AOF 每1s就会进行一次持久化,所以相对可靠,且AOF 文件内容是字符串,非常容易阅读和解析。但.aof占用空间较大,恢复速度慢
开启AOF持久化策略的方式:修改配置文件 reds.conf:appendonly yes
##此选项为aof功能的开关,默认为“no”,可以通过“yes”来开启aof功能
##只有在“yes”下,aof重写/文件同步等特性才会生效
appendonly yes
同样,也可以自定义同步策略
##指定aof操作中文件同步策略,有三个合法值:always everysec no,默认为everysec,appendfsync ,everysec
- always:每一条 aof 记录都立即同步到文件,这是最安全的方式,也以为更多的磁盘操作和阻塞延迟,是 IO 开支较大。
- everysec:每秒同步一次,性能和安全都比较中庸的方式,也是 redis 推荐的方式。如果遇到物理服务器故障,有可能导致最近一秒内 aof 记录丢失(可能为部分丢失)。
- no:redis 并不直接调用文件同步,而是交给操作系统来处理,操作系统可以根据 buffer 填充情况 / 通道空闲时间等择机触发同步;这是一种普通的文件操作方式。性能较好,在物理服务器故障时,数据丢失量会因 OS 配置有关。
但因为.aof文件较大,密集操作时,磁盘IO负重较大,相对性能较低
8.3 RDB与AOF的比较
| RDB持久化策略 | AOF持久化策略 |
|---|---|
| 数据安全性较低 | 数据安全性高 |
| 性能较高 | 性能较低 |
| 占用空间小 | 占用空间大 |
9. redis主从复制与哨兵模式
在实际应用场景中,可能用户的读写需求比是:9:1
所以可能会搭建如下的数据库结构(一主两从或一主一从):选择一个数据库作为主数据库,其余数据库作为从数据库
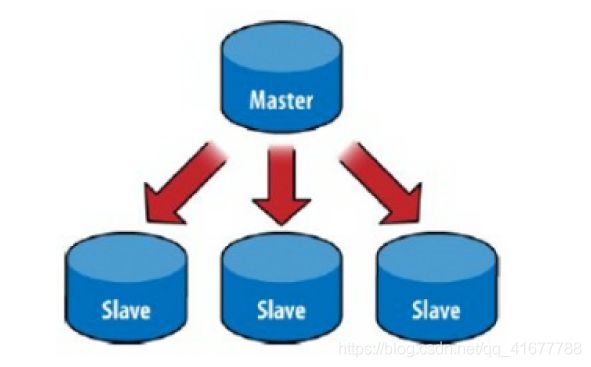
- 从数据库会完全复制主数据库数据,且每次主数据库数据变动都会进行更新
- 从数据库对数据只有读的权限,主数据库对数据才能拥有写的权限
9.1 搭建主从数据库结构步骤
-
找到主数据库的
redis.conf,redis-server,redis-cli文件,将其复制到你要存放从数据库的位置 -
配置redis.conf文件
# 绑定虚拟机ip地址 bind 192.168.188.131 # 设置了主数据库的ip和端口号 replicaof 192.168.188.131 6379 # 配置从数据库端口(未使用的端口) port 6380 # 关闭安全模式 protected-mode no # 允许后台访问 daemonize yes -
将配置文件更新到从机服务
./redis-server ./redis.conf -
连接从数据库进行验证
redis-cli -h 192.168.188.131 -p 6380
连接成功后查看数据库信息:info replication# Replication role:slave master_host:192.168.188.131 master_port:6379 master_link_status:up master_last_io_seconds_ago:2 master_sync_in_progress:0 slave_repl_offset:2996 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:46b1484e5456450ac1e70ada68de4655db0a54ff master_replid2:0000000000000000000000000000000000000000 master_repl_offset:2996 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1779 repl_backlog_histlen:1218其中,role为:slave,且主数据库中也可以查看到此从数据库信息则表示主从关系构建成功
9.2 哨兵模式
但是如果IO操作大于数据库承受能力,可能会导致主数据库爆掉,那么此时,从数据库也可以起到一个备胎顶上的作用,即将从数据库设置为哨兵模式,主数据库宕机时,开启选举工作,哨兵模式的从数据库自动成为主数据库
哨兵的作用就是对Redis系统的运行情况监控,它是一个独立进程,它的功能:
- 监控主数据库和从数据库是否运行正常;
- 主数据出现故障后自动将从数据库转化为主数据库;
配置哨兵模式从数据库:
-
给从数据库添加 sentinel.conf配置文件
文件内容为:sentinel monitor mastername 主数据库ip 主数据端口 最低选举通过票数
# sentinel monitor mastername 主数据库ip 主数据端口 最低选举通过票数 sentinel monitor mastername 192.168.188.131 6379 1 -
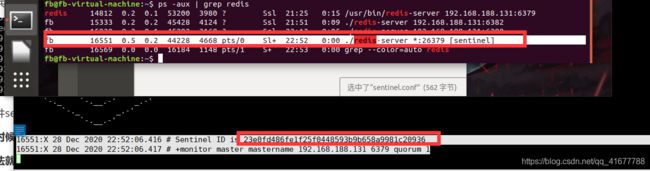
以哨兵模式启动从数据库服务
./redis-server sentinel.conf --sentinel然后就可以看到多了一个独立哨兵线程,且可以看到被监控的主数据库信息,即哨兵配置成功
10. redis集群
在实际场景中,可能主从复制模式都不能满足用户需求,就需要一种更加高效的架构方案,目前主流的是如下图所示的集群架构方案:
redis集群架构图:
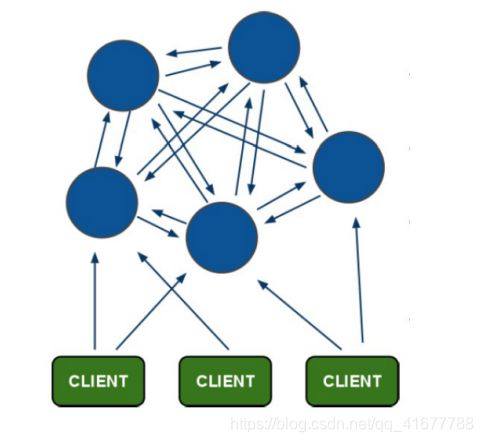
- 图中蓝色圆点代表redis数据库,彼此之间互联(ping-pong)
- 客户端只需要连接任一集群中的redis数据库,即可访问集群其余redis数据库
- 每个节点都需要通过集群中超过半数的节点检测(ping-pong)有效时整个集群才生效
- 当有数据存储时,会对key计算哈希值,存储在对应哈希槽范围内的节点数据库里
- 当有数据读取需求时,会自动到集群中对应哈希槽主机中取数据
这样的架构可以极大地提升数据存储容量与抗压能力
10.1 集群哈希槽机制
Redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value 时,redis 先对 key 使用 crc16算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点

10.2 集群容错机制

如上图所示,如果只有一条无法与黄色节点进行联结,尚未确定该节点宕机
但如果有两条(大于50%)无法与红色节点进行联结,则可以确定该节点宕机
- 只要有一个节点宕机(该master宕机,且无slave),该集群fail,即集群的[0-16383]slot映射不完全
- 如果集群超过半数以上master挂掉,无论是否有slave,集群进入fail状态。
10.3 集群搭建步骤
集群这里比较的繁琐,推荐一篇大佬的文章,讲的很细,基于Redis的主从复制、哨兵模式以及集群的使用,史上最详细的教程来啦~
-
先按照如下架构图,在一个redis-cluster文件夹中构建如下6台数据库,不用指定主从关系

-
集群数据库redis.conf中都需要配置:
cluster-enable yes,代表可开启集群,该设置默认是关闭 -
为方便每次更新集群数据库配置文件,可以写一个脚本文件,并赋予可执行权限
cd 7001 ./redis-server ./redis.conf cd .. cd 7002 ./redis-server ./redis.conf cd .. cd 7003 ./redis-server ./redis.conf cd .. cd 7004 ./redis-server ./redis.conf cd .. cd 7005 ./redis-server ./redis.conf cd .. cd 7006 ./redis-server ./redis.conf cd .. -
创建集群
在任意一台redis数据库中创建集群,使彼此互联
- redis 4.0 以上版本:
redis-cli --cluster create ip:port ip:port --cluster-replicas 1 - redis4.0 及以下版本:
/redis-trib.rb create --replicas ip:port ip:port
参数
-replicas指定每台master分配多少台从机,这里我们指定1,让集群自动分配主从机fb@fb-virtual-machine:~/redis/redis-cluster/7001$ ./redis-cli --cluster create 192.168.188.131:7001 192.168.188.131:7002 192.168.188.131:7003 192.168.188.131:7004 192.168.188.131:7005 192.168.188.131:7006 --cluster-replicas 1 >>> Performing hash slots allocation on 6 nodes... Master[0] -> Slots 0 - 5460 Master[1] -> Slots 5461 - 10922 Master[2] -> Slots 10923 - 16383 Adding replica 192.168.188.131:7005 to 192.168.188.131:7001 Adding replica 192.168.188.131:7006 to 192.168.188.131:7002 Adding replica 192.168.188.131:7004 to 192.168.188.131:7003 >>> Trying to optimize slaves allocation for anti-affinity [WARNING] Some slaves are in the same host as their master M: 96d1ad158cce58b247866ba0df66f9f21d00feaf 192.168.188.131:7001 slots:[0-5460] (5461 slots) master M: 35ec7550d1a4f41a8663037e41eb657e249370d7 192.168.188.131:7002 slots:[5461-10922] (5462 slots) master M: adb531086a3e55fbfd5403475598477939d1eecd 192.168.188.131:7003 slots:[10923-16383] (5461 slots) master S: ce5a1ba3ade115ab9ed59978f45b4752a88ccf84 192.168.188.131:7004 replicates 35ec7550d1a4f41a8663037e41eb657e249370d7 S: d522421a0ce398d366affabffd781737e6600986 192.168.188.131:7005 replicates adb531086a3e55fbfd5403475598477939d1eecd S: bcf6a4e3f625d56c0b76eccc11c1a1a5ee07a53c 192.168.188.131:7006 replicates 96d1ad158cce58b247866ba0df66f9f21d00feaf >>> Nodes configuCan I set the above configuration? (type 'yes' to accept): yes >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join . >>> Performing Cluster Check (using node 192.168.188.131:7001) M: 96d1ad158cce58b247866ba0df66f9f21d00feaf 192.168.188.131:7001 slots:[0-5460] (5461 slots) master 1 additional replica(s) S: d522421a0ce398d366affabffd781737e6600986 192.168.188.131:7005 slots: (0 slots) slave replicates adb531086a3e55fbfd5403475598477939d1eecd S: ce5a1ba3ade115ab9ed59978f45b4752a88ccf84 192.168.188.131:7004 slots: (0 slots) slave replicates 35ec7550d1a4f41a8663037e41eb657e249370d7 S: bcf6a4e3f625d56c0b76eccc11c1a1a5ee07a53c 192.168.188.131:7006 slots: (0 slots) slave replicates 96d1ad158cce58b247866ba0df66f9f21d00feaf M: adb531086a3e55fbfd5403475598477939d1eecd 192.168.188.131:7003 slots:[10923-16383] (5461 slots) master 1 additional replica(s) M: 35ec7550d1a4f41a8663037e41eb657e249370d7 192.168.188.131:7002 slots:[5461-10922] (5462 slots) master 1 additional replica(s) [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.从这里详细信息我们可以看到:
集群哈希槽范围 对应主机 0-5460 7001 5461-10922 7001 10923-16383 7001 - redis 4.0 以上版本:
-
验证集群数据存储
通过任意方式以集群模式(-c)连入:
redis-cli -h ip -p port -cfb@fb-virtual-machine:~/redis/redis-cluster/7001$ ./redis-cli -h 192.168.188.131 -p 7001 -c 192.168.188.131:7001> set key "hello,redis_cluster!" -> Redirected to slot [12539] located at 192.168.188.131:7003 OK 192.168.188.131:7003> get key "hello,redis_cluster!"我们可以看到,我们存入的数据被存放到了12539这个哈希槽,该哈希槽对应集群中的7003主机,自动就帮我们切换到了该主机,我们可以调出数据
10.4 Jedis连接集群
Jedis中有一个适用于集群的类 JedisCluster,但需要传入ip地址与端口
这里我们可以利用一个 HostAndPort来保存ip地址和端口
@Test
public void test_redisCluster(){
Set<HostAndPort> hostAndPorts = new HashSet<>();
hostAndPorts.add(new HostAndPort("192.168.188.131",7001));
hostAndPorts.add(new HostAndPort("192.168.188.131",7002));
hostAndPorts.add(new HostAndPort("192.168.188.131",7003));
hostAndPorts.add(new HostAndPort("192.168.188.131",7004));
hostAndPorts.add(new HostAndPort("192.168.188.131",7005));
hostAndPorts.add(new HostAndPort("192.168.188.131",7006));
//将ip和端口号传入Jedis集群类
JedisCluster jedisCluster = new JedisCluster(hostAndPorts);
//存入数据
jedisCluster.set("helloByJava","hello,redis_cluster by java");
//取出数据
System.out.println(jedisCluster.get("helloByJava"));
//关闭Jedis连接
jedisCluster.close();
/*输出:
hello,redis_cluster by java
*/
}
11. redis缓存问题
redis数据库的一大应用场景,就是作为缓存数据库使用 ,即第一次加载某数据时,同时将其放置到redis数据库保存,下次直接从redis数据库更加高效的读取数据
对于java狭义的缓存而言,主要是三大类,速度依次减慢:
- 虚拟机缓存(ehcache,JBoss Cache)
- 分布式缓存(redis,memcache)
- 数据库缓存
基本的缓存数据流向图:

11.1 缓存雪崩
缓存雪崩:原有缓存大量数据失效,新缓存未更新时,大量请求直接访问数据库,导致数据库宕机
解决方案
- 缓存失效后,通过加锁或队列控制读写数据库的线程数量,虽然降低l数据库压力,但也减少了系统吞吐量
- 将缓存数据的过期时间分散或随机,防止同一时间大量数据过期现象发生
11.2 缓存击穿
缓存击穿:针对某单个热点key在缓存中过期时,被大量请求访问,直接对数据库进行访问,导致宕机
解决方案:
- 将此热点key在缓存中设置为永不过期
- 通过加锁或队列控制读写数据库的线程数量
11.3 缓存穿透
缓存穿透:请求反复要访问一个不存在的数据,缓存中没有,数据库也没有,比如id=“-1”的数据,很可能是受到了攻击,重复的请求对数据库访问,可能导致宕机
解决方案:
- 在持久层之前进行请求拦截,通过表单验证,请求条件判断等等
- 将key-value写为key-null,将null值回送到缓存让请求进行访问,降低数据库压力