分析对象竞是我自己?我在 9 月上班划水 1510 分钟!
国庆 7 天假完全没有学习!上班好几天才找回状态,在内卷时代如此躺平,实在令人胆战心惊啊,时间都去哪儿了呢?空白的七天历史可能已经无法考究了,但笔者平时是有记录日程安排的习惯的,比如下面这份 9 月时间记录清单,就记录了笔者在工作日(划水摸鱼)勤奋刻苦的过程,想必老板看到也会很欣慰吧。那就来自我分析一波,看看到底都干了啥!

一、数据准备
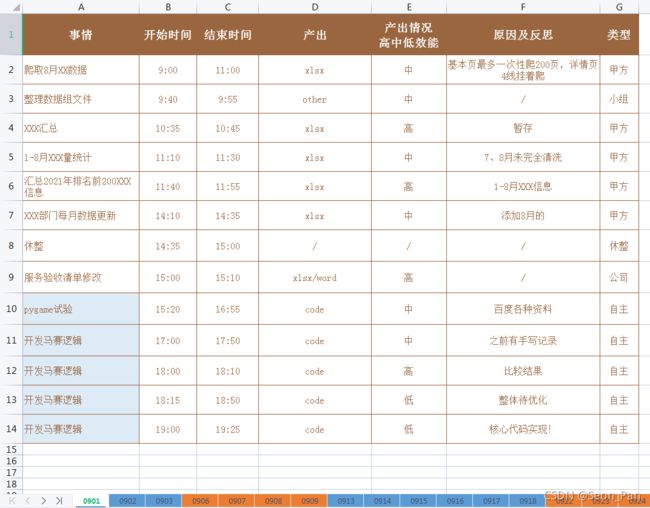
时间记录清单的字段如下所示,笔者将产出、效能、事务类型作了简单的分类,并记录了连续作业的起止时间,休息时间达到 20 分钟就会记录为休整,相同事务如果不是连续作业,会用相同的颜色予以填充。
本次采用以下工具进行分析和可视化:
import pandas as pd
from datetime import datetime, date, time
import openpyxl as op
import jieba
from pyecharts.charts import Bar, Pie, Grid, Polar, Timeline, WordCloud
from pyecharts import options as opts
from pyecharts.commons.utils import JsCode
为了便于分析,首先将所有子表合并,并增加一个日期字段,无需作日期运算,所以直接使用子表名称作区分即可。注意:sheet_name 未指定时默认读取第一个子表,指定其值为 None 时读取所有的子表为多个 DataFrame 格式。操作代码如下:
all_df = pd.read_excel('/home/mw/9月.xlsx', sheet_name=None)
data = pd.DataFrame()
sheets = all_df.keys()
for sheet in sheets :
df = all_df.get(sheet)
df['日期'] = sheet
data = data.append(df)
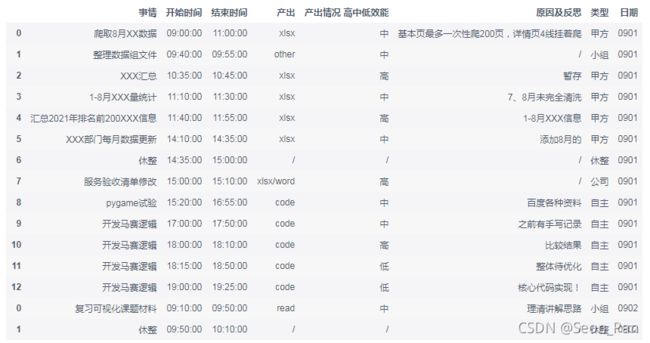
合并结果如下:
二、自我分析
1、在公司都做些什么?
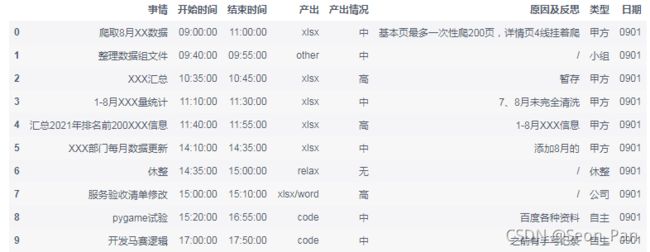
这个问题可以从产出内容的形式来看,笔者将其分为 code、xlsx、word、ppt、txt、other 等 6 种,other 一般是会议或其他输出形式。有时一个事务会涉及多种产出,用 / 分隔,且休整事务仅用一个 / 来表示无产出,因此我们可以先将休整的产出替换成 relax,并且也修改一下产出情况一列:
data.loc[data['产出']=='/', '产出'] = 'relax'
data.rename(columns={
'产出情况\n高中低效能': '产出情况'}, inplace=True)
data.loc[data['产出情况']=='/', '产出情况'] = '无'
再把有多种产出的事务展开,统计一下频率,并用 pyecharts 来画一个饼图:
produces = data['产出'].str.split('/').to_list()
counter = {
}
for produce in produces:
for p in produce:
counter[p] = counter.get(p, 0) + 1
pie = (Pie()
.add('',
[list(z) for z in counter.items()],
radius=["30%", "70%"]
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {d}%"))
)
pie.render_notebook()
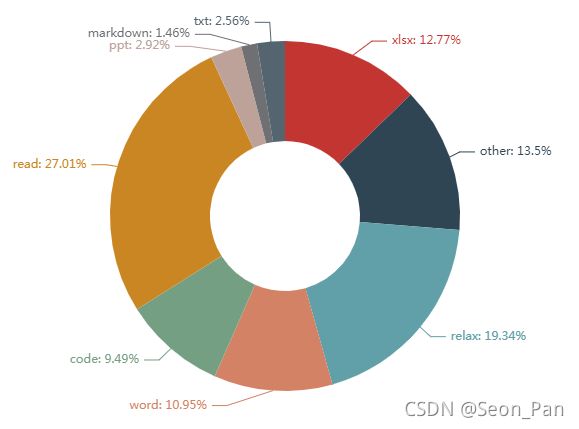
惊人地发现笔者居然在阅读上的产出最多!或是自主学习时查阅资料,或是摸鱼时阅读书籍,当然笔者相信更多是浏览工作材料,嗯一定是这样的,绝无偷懒之嫌。
其次是休整,啊,其次是休整啊,看来还是有在偷懒呢。
但是老板别着急,这只是次数记录,时长记录才能说明问题。
此外再看,笔者作为小表哥也有 12.77% 的事务是在输出 EXCEL 表格的,占比相近的还有 WORD 形式的报告文档(10.95%),以及一些脚本代码(9.49%)等。
另外 other 之中大部分是参加会议,好歹也是个小组长嘛。
2、各种事情都投入多长时间?
由于涉及多种产出的事务不好评估其用时,在此仅对单一产出的用时进行分析。先计算出每项事务的历时,换算成以分钟为单位。注意:xx:xx:xx 格式的时间字符串会被 pandas 识别成 datetime.time 类型,无法直接进行计算,需先添加上日期后进行转换。
data['开始时间'] = data['开始时间'].apply(lambda x: datetime.combine(date.today(), x))
data['结束时间'] = data['结束时间'].apply(lambda x: datetime.combine(date.today(), x))
data_ = data[~data['产出'].str.contains('/')]
data_['历时'] = data_['结束时间'] - data_['开始时间']
data_['历时'] = data_['历时'].apply(lambda x: x.seconds/60)
data_['历时'].values

再统计各类产出的平均每日总用时和平均每次用时,保留 2 位小数并降序排列。
grp_day = data_.groupby(['日期', '产出'])['历时'].sum().reset_index()
grp_day_mean = grp_day.groupby('产出')['历时'].mean().reset_index().round(2)
grp_day_mean.sort_values(by='历时', inplace=True, ascending=False)
grp_per_mean = data_.groupby('产出')['历时'].mean().reset_index().round(2)
grp_per_mean.sort_values(by='历时', inplace=True, ascending=False)
画两个柱状图对比一下。
bar_d = (Bar()
.add_xaxis(grp_day_mean['产出'].to_list())
.add_yaxis('', grp_day_mean['历时'].to_list())
.set_global_opts(title_opts=opts.TitleOpts(title="平均每日总用时"))
)
bar_p = (Bar()
.add_xaxis(grp_per_mean['产出'].to_list())
.add_yaxis('', grp_per_mean['历时'].to_list())
.set_global_opts(title_opts=opts.TitleOpts(title="平均每次用时", pos_top = '50%'))
)
grid = Grid()
grid.add(bar_d, grid_opts=opts.GridOpts(pos_bottom="60%"))
grid.add(bar_p, grid_opts=opts.GridOpts(pos_top="60%"))
grid.render_notebook()
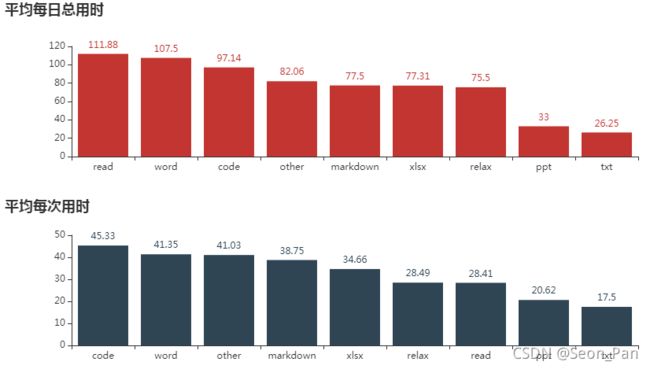
可见笔者每天在阅读和写报告上花的时间最多,均超过 100 分钟,划水也不过 1 个小时多一点嘛。而从单次连续作业来看,更加沉迷于写代码,也可能是个人编码效率太低哈哈。阅读则是一口气能看半个小时左右,因为通常会被其他事情打断。
3、一般几点正式开工 OR 下班饮茶?
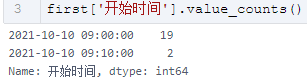
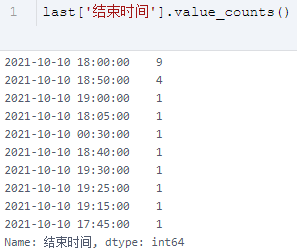
那么每天的工作什么时候正式开始呢,经分析后发现,有记录的 21 个工作日中有 19 天都是 9 点准时开工的,而仅有 9 天是准时下班的,还有 1 天加班到半夜。
first = data.groupby('日期').first()['开始时间'].reset_index()
last = data.groupby('日期').last()['结束时间'].reset_index()
我们可以将时间转成 24 小时制的数值,
first['开工'] = first['开始时间'].apply(lambda x: x.hour + x.minute/60).round(1)
last['收工'] = last['结束时间'].apply(lambda x: x.hour + x.minute/60).round(1)
dict1 = first['开工'].value_counts().to_dict()
dict2 = last['收工'].value_counts().to_dict()
dict2.update(dict1)
dict2.update({
24.0: 0})
![]()
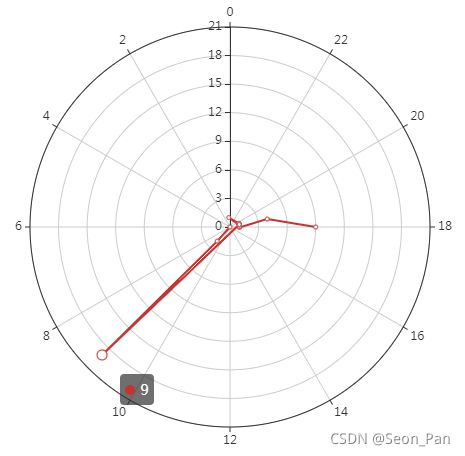
再用极坐标柱状图形象地表示一个 24 点的钟表盘,以此呈现可视化,可见基本是指向 9 点或 18 点两个时刻,看来还不算是血汗工厂呀。
lst = [(k, v) for v,k in dict2.items()]
pl = (
Polar()
.add("", lst, type_="line", label_opts=opts.LabelOpts(is_show=False))
)
pl.render_notebook()
4、工作/学习的效率如何?
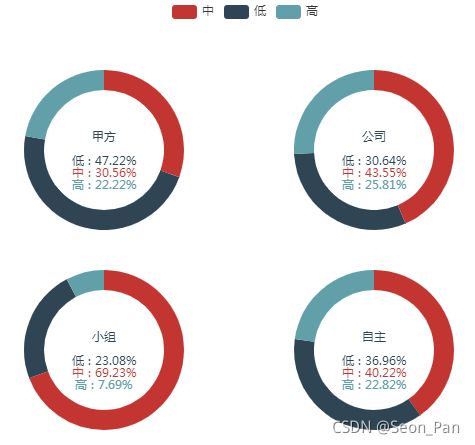
下面我们再来瞅瞅从为谁开展事务时效率更高,笔者分为了甲方、公司、小组、自主等 4 类。虽然打工人打工魂,为(资本)人民服务的同时,也不能忘了最终还是为了自我提升呀!笔者猜想肯定是自主学习时的整体效率最高,先计算一下吧。
work_data = data[data['类型']!='休整']
grp = work_data .groupby(['类型', '产出情况'])['事情'].count()
再用一点点骚操作画个圆环图矩阵,pyecharts 虽然配置丰富,但操作起来还是比较复杂,对于官方文档还要多多学习和试验才行。
fn = """
function(params) {
if(params.name == '中')
return '\\n\\n\\n\\n' + params.name + ' : ' + params.percent + '%';
if(params.name == '高')
return '\\n\\n\\n\\n\\n\\n' + params.name + ' : ' + params.percent + '%';
return params.seriesName + '\\n\\n' + params.name + ' : ' + params.percent + '%';
}
"""
def new_label_opts():
return opts.LabelOpts(formatter=JsCode(fn), position="center")
pie_four = (Pie()
.add('甲方', grp.loc['甲方'].reset_index().values, center=["20%", "30%"], radius=[60, 80], label_opts=new_label_opts())
.add('公司', grp.loc['公司'].reset_index().values, center=["50%", "30%"], radius=[60, 80], label_opts=new_label_opts())
.add('小组', grp.loc['小组'].reset_index().values, center=["20%", "70%"], radius=[60, 80], label_opts=new_label_opts())
.add('自主', grp.loc['自主'].reset_index().values, center=["50%", "70%"], radius=[60, 80], label_opts=new_label_opts())
.set_global_opts(legend_opts=opts.LegendOpts(pos_left="27%"))
)
pie_four.render_notebook()
竟然是为公司工作时比较容易(25.81%)进入高效状态,老板这下还不提拔我哈哈哈!~而在为甲方工作时更容易(47.22%)出现低效的情况。
5、什么时间适合高效开工?
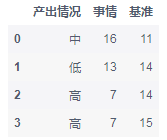
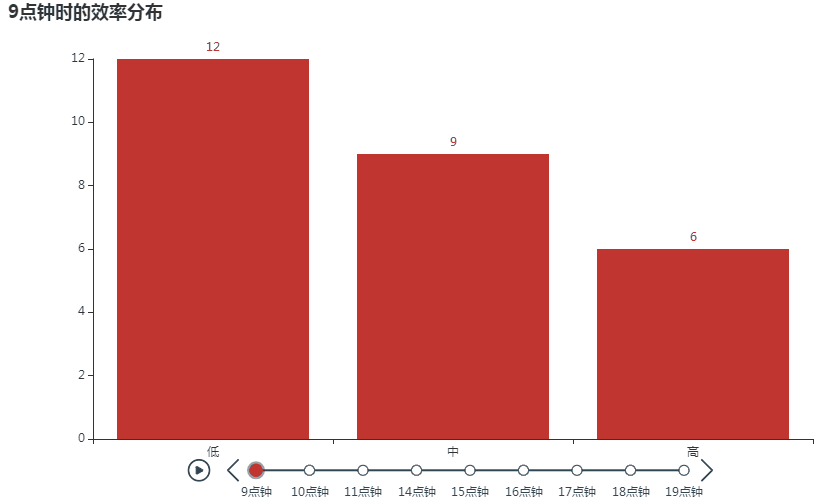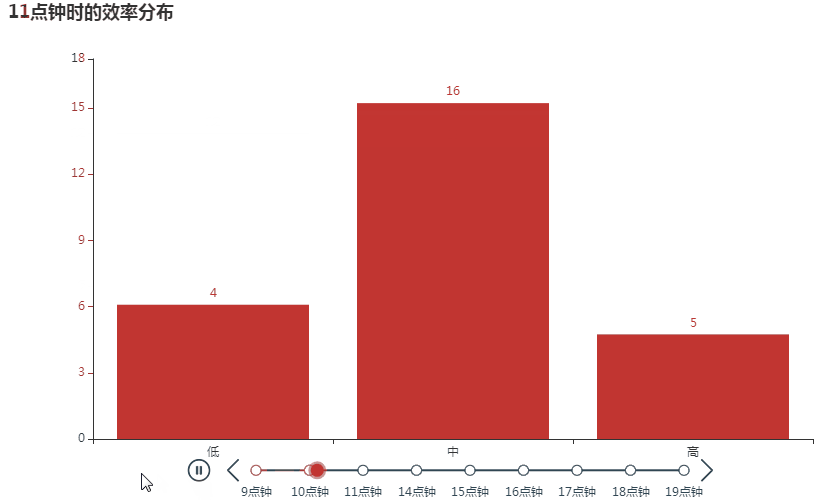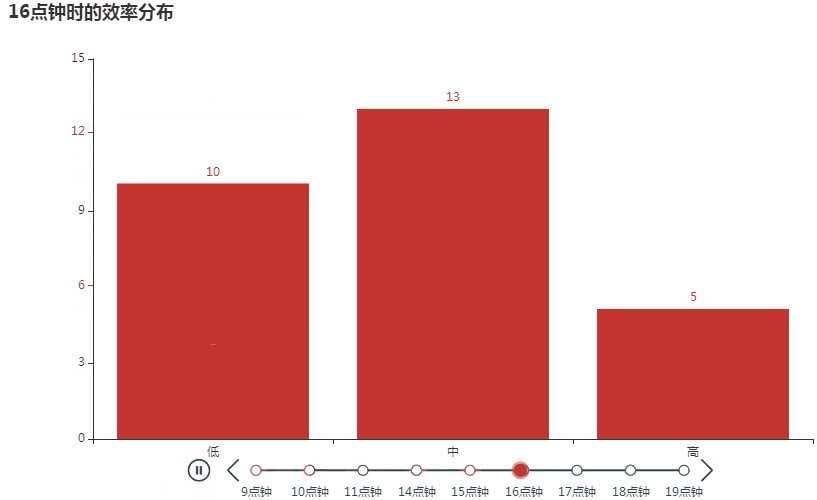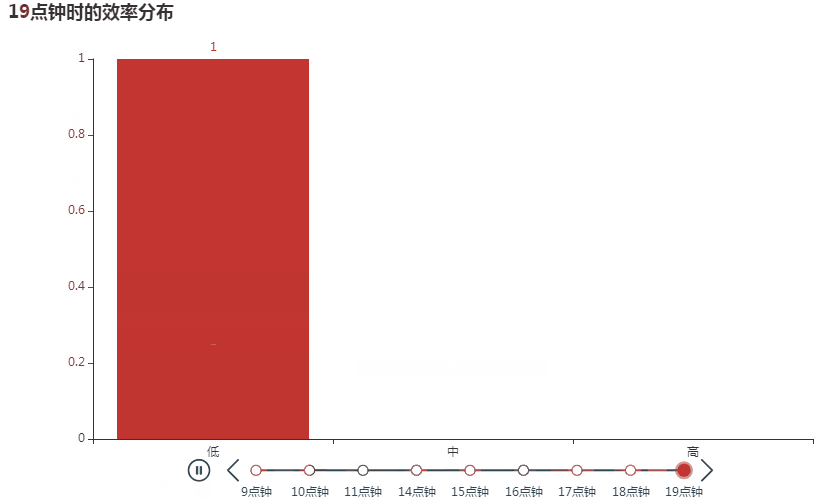
我们选取起止时间的中间时刻作为基准,分析低、中、高效在各基准点的分布。如下所示,大部分低效事务出现在 14 点,害,正是最困的时候;大部分中效事务出现在 11 点,临近干饭加把劲的感觉;大部分高效事务也出现在 14 点,另外还有 15 点,应该是有午睡的话,下午就会比较容易进入状态。
work_data['基准'] = ((work_data['开始时间'].dt.hour + work_data['结束时间'].dt.hour)/2).astype(int)
grp_median = work_data.groupby(['产出情况', '基准'])['事情'].count().reset_index()
grp_max = grp_median.groupby('产出情况')['事情'].max().reset_index()
grp_result = pd.merge(grp_max, grp_median, on=['产出情况', '事情'], how='left')
grp_result
还可以用时间轴柱状图动态展现各时间点的效率分布,为便于观察,需将 X 和 Y 轴值按低、中、高的顺序排列后再制图。
tl_data = work_data.groupby(['基准', '产出情况'])['事情'].count().reset_index()
order_x = ['低', '中', '高']
tl = Timeline()
tl.add_schema(play_interval=700)
for clock in tl_data['基准'].unique():
order_y = [t[1] for i in order_x for t in tl_data[tl_data['基准']==clock][['产出情况', '事情']].values if i == t[0]]
bar = (
Bar()
.add_xaxis(order_x)
.add_yaxis('', order_y)
.set_global_opts(
title_opts=opts.TitleOpts(f'{
clock}点钟时的效率分布'),
)
)
tl.add(bar, f'{
clock}点钟')
tl.render_notebook()
可见随着时间推移,效率是越来越高的哈哈,越战越勇啊。
6、效率高低是为什么?
做一个形式主义的词云图来分析一下,为什么说是形式主义呢,因为笔者(根本就没有好好记录)记录原因的方式比较简略,所以简单分词一下取前 100 个词制图即可,不必对停用词进行过滤。
work_data['分词'] = work_data['原因及反思'].apply(lambda x: ','.join(jieba.lcut(x)))
jieba_str = ','.join(work_data['分词'].values)
words_counter = {
}
for word in jieba_str.split(','):
words_counter[word] = words_counter.get(word, 0) + 1
words_data = sorted(list(words_counter.items()), reverse=True, key=lambda x: x[1])[:100]
wc = (WordCloud(init_opts=opts.InitOpts(width="830px", height="600px", bg_color="transparent"))
.add(
"关键词",
words_data,
shape="diamond",
)
)
wc.render_notebook()
咳咳,不管怎么说,从词云图还是能发现问题的,影响效率主要是因为在做数据清洗时,对 pandas 等工具运用不熟,之类之类的(你倒是给我搞熟它啊!)

7、被交叉事务打断的情况有多少?
这个问题处理起来比较复杂,需要通过分析 EXCEL 表中事情一列是否存在颜色填充来回答。前文提到,相同事务如果不是连续作业,会用相同的颜色予以填充。但两个相同的颜色上下邻近,则表示这件事没有被其他事情打断,只是自己有短暂的喘息。获取单元格的填充属性就不能靠潘大师啦,下面有请 openpyxl !
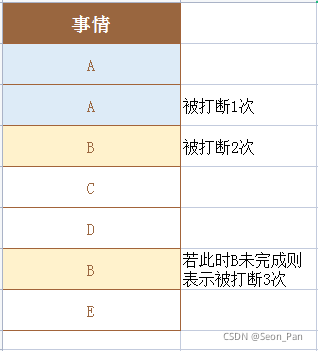
先读取第一个子表的 A1 单元格试试,读取到了该单元格颜色对象的参数列表,那么我们只需遍历获取 每个单元格的 rgb 值即可区分颜色。
book = op.load_workbook('/home/mw/9月.xlsx')
sheet = book.worksheets
color = sheet[0].cell(row=1, column=1).fill.fgColor

噫!怎么冒出这么个玩意儿,不用担心,theme 是一种颜色选择器,先不深究原理,只需要知道它是靠 theme 和 tint 两个值来确定颜色即可。为了方便,可以将两个值连在一起。

于是便有了以下遍历方式,同时把日期即子表名,加在颜色列表开头:
total = []
for sheet in book.worksheets:
column_data = []
for i in range(1, sheet.max_row + 1):
color = sheet.cell(row=i, column=1).fill.fgColor
if color.type=='rgb':
column_data.append(color.rgb)
else:
column_data.append(f'{
color.theme}-{
color.tint}')
column_data = [i for i in column_data if i != None][1:]
column_data = [sheet.title] + column_data
total.append(column_data)

但这么看着太花里胡哨了,还是翻译一下吧。
trans = {
'00000000':'无', 'FFFFFF00':'黄', '5-0.8':'灰绿', '9-0.8':'浅绿', '7-0.6':'金', '4-0.8':'蓝', '5-0.6':'橙'}
for lst in total:
for i, code in enumerate(lst):
if i > 0:
lst[i] = trans[code]

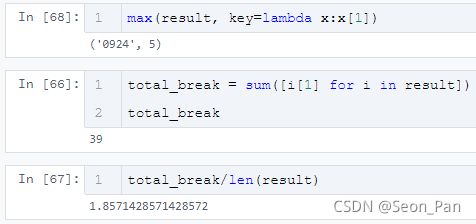
OK,热身完毕,接下来就是基于前述规则来统计被打断的情况啦。只要当前值不等于下一个值,且当前值在之后还有出现,即打断次数 +1。
result = []
for day in total:
count = 0
color_lst = day[1:]
for i, v in enumerate(color_lst):
if i < len(color_lst)-1:
if v != color_lst[i + 1] and v in color_lst[i+1:] and v != '无':
count += 1
result.append((day[0], count))
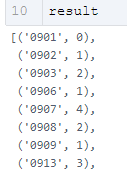
以被打断 4 次的 9 月 7 日为例,笔者将被打断的部分加粗表示,分别是浅绿、蓝、橙、浅绿等四处,可见结果符合判断规则。
[‘0907’, ‘无’, ‘无’, ‘无’, ‘无’, ‘无’, ‘浅绿’, ‘蓝’, ‘橙’, ‘蓝’, ‘蓝’, ‘无’, ‘浅绿’, ‘橙’, ‘无’, ‘浅绿’, ‘无’, ‘无’, ‘无’, ‘无’, ‘无’]
最后发现,一天最多被打断 5 次,一个月总共有 39 次,平均每天被打断近 2 次。啊啊啊,正干着一件事突然又有别的事插入,真的很不爽呢。
三、小结
至此,笔者通过数据分析与可视化对自己 9 月的工作生活进行了一次洞察,要改进的东西还有很多,除了工作节奏,时间清单的记录方式也可以优化,以便未来持续复盘分析,大家也可以记录自己的时间清单试试喔!这里是不划水会 S 的 Seon塞翁,下一篇,也找个上班时间来写吧!
