提高带宽利用率!为什么要Pacing?
1986年的TCP拥塞崩溃事件让AIMD模型在1988年后出来应对时局,从此以后互联网协议的设计者和实现者聚焦于如何让网络不拥塞。
毫无疑问,这里最重要的是公平性,而非效率。不管是慢启动,加性增窗,乘性减窗,还是后来的Vegas算法的主动退让,其目标都在于保证多条流经过共享链路时能公平共享带宽。这种机制的目标不是让单条流跑得更快。
换句话说,1988年的模型是不患寡而患不均的模型。其中的 “不患寡” 给很多人带来了误解。
事情在2010年前后悄悄地起了变化。
AIMD模型的目标是不患寡,而患不均,这注定单条TCP的带宽利用率极低,因此HTTP协议一般会采用多条TCP流捆绑的方式来传输Web服务器的数据以增加带宽,然而多TCP连接意味着连接管理的开销会增大,同时数据同步的开销也会增加,这导致了人们倾向于使用单独的连接来完成所有的事情。
然而,又是一个然而,TCP固有的队头拥塞问题导致单独的TCP连接无法很好的进行HTTP流的多路复用,这个难题促进了Google对QUIC协议的设计和发布,同时,QUIC的一些显而易见的优势点也逐步的回移进了TCP(如果可能的话)。
不管怎样,如今确实是倾向于减少TCP连接数量,这便弱化了公平性的约束,如今,提高单条连接的带宽利用率,成了迫在眉睫的硬需求。
如何度量带宽利用率?
我倾向于用一种 综合的效用 来度量,而不仅仅是 把带宽跑满, 倘若如此,一个包发十遍肯定能把带宽跑满,然而此时的利用率高吗?
我倾向于把代价也算进去,最终,我们需要,在带宽尽可能大的同时,保证代价尽可能小。
设 G G G为收益, P P P为代价或者成本,那么一个综合效用可以用以下的比值表示:
E = G P E=\dfrac{G}{P} E=PG
我们的任务是,求出一组约束,使得 E E E的值最大,此时带宽的利用率最大。
上面的式子中,请注意 P P P由两部分组成:
- 待服务数据包的排队时延成本;
- 链路转发节点的空置时间成本;
大致画图如下:
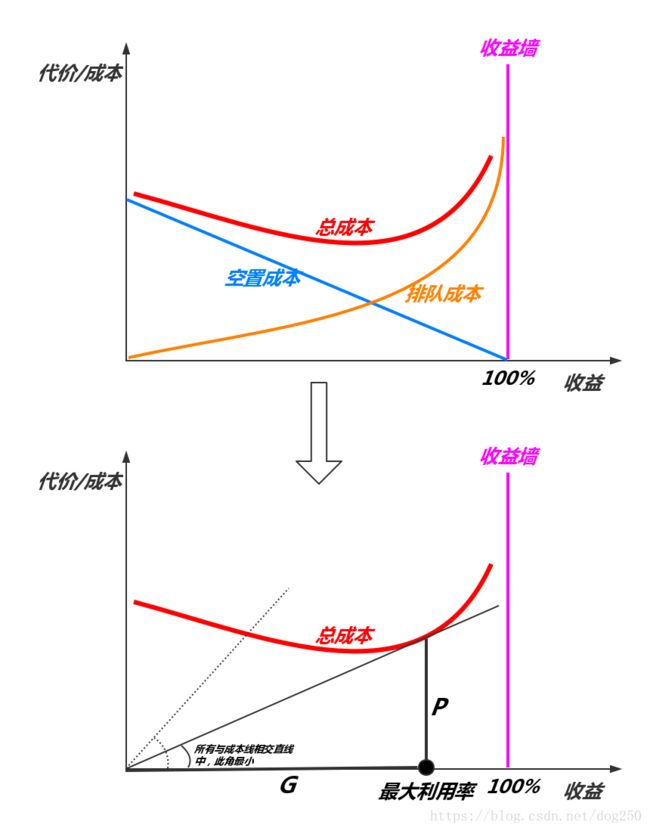
本文以下的讨论,假设链路的处理带宽为常数 U U U,处理方式为固定速率处理,处理单位为包粒度而不是字节,那么处理一个包的时间便是 1 U \dfrac{1}{U} U1,我们从一种极端情况开始,经由一种一般的情况,最终会得出结论,只有均匀按照每 1 U \dfrac{1}{U} U1时间匀速到达的数据包,其 E E E值最大,而这种方式就是Pacing!
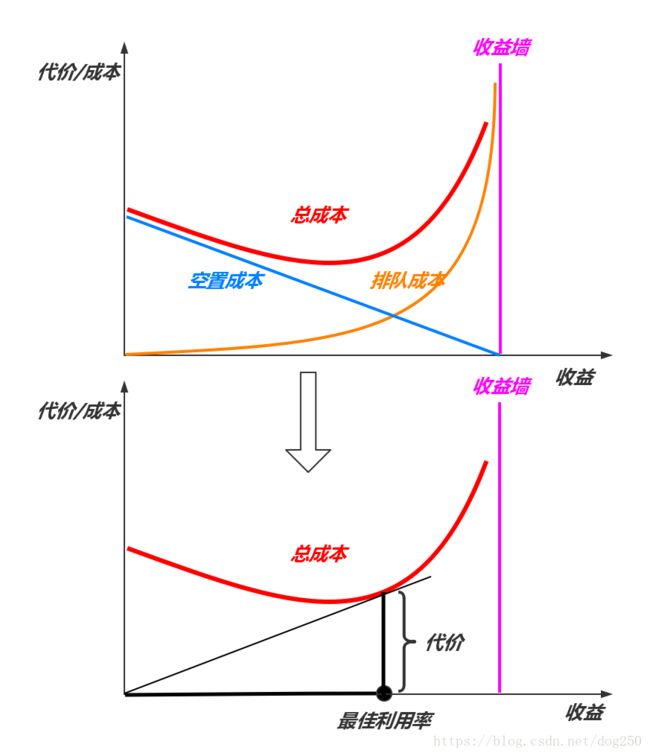
先看以极端情况下完全突发到达的数据包,即当到达率为 λ \lambda λ时,单位时间内所有的 λ \lambda λ个数据包同时到达。
我们知道,单位时间内系统可以处理 U U U个数据包,是为服务率为 U U U,然而当 λ \lambda λ个数据包在 1 U \dfrac{1}{U} U1时间同时到达时,必然会有 λ − 1 \lambda-1 λ−1个数据包排队,而单位时间的空置时延依然是 1 − λ U 1-\dfrac{\lambda}{U} 1−Uλ,因此总代价就是常数。如下图所示:

虽然看样子利用率接近了100%,然而代价确实巨大的!通过计算可知,这种情况下的 E E E值并不高。然而这么多年,TCP的AIMD正是工作在这个模型上。
然而,正如我们分析网络数据流看到的那样,情况可能比上面的模型展示的结果更加糟糕,这是为什么?我们来接着分析。
下面我们看一种更加一般,更加符合真实环境的情况,即泊松到达的情况。这里将会揭示一个关于 100%利用率的神话永不可达 的事实:
至于说泊松到达的情况下,这张图为什么长这个样子,我就不推导了,从排队论的公式简单理解作图就能得到。注意这里的事实,最佳利用率而不是最大利用率,为什么?
从图上可以看出,如果我们在泊松到达的情况下想逼近收益墙附近的最大100%利用率,代价将是无法承受的,我们看到队列长度将趋向无穷大,这是根本无法处理的情况!
这背后的原因其实非常简单,即在泊松到达到达的情况下,单位时间到达的数据包会有概率性的大于 μ \mu μ,此时就将付出排队延时的代价,而同样会有概率性的小于 μ \mu μ,此时便要付出空置的代价,而不管是排队还是空置,对于服务方而言,都是成本,不幸的是,这两种成本是叠加而非抵消的关系!它们对数据包到达的影响效果仅仅是在数值意义上使得其到达均值为到达率 λ \lambda λ!
这便是100%利用率永不可达的神话!
这个故事不断在我们生活中上演,这也是为什么运维们很怕CPU利用率达到100%的原因,100%并不意味着系统利用率高,而是意味着系统卡死!
同样,我们的工作看上去永远也做不完,因为你永远不知道接下来会发生什么,只要你没有空闲的时候,那么就意味着你将永远没有空闲的时候。你仔细想想,是不是这个道理。
如何解决这个问题呢?
破除泊松到达模式即可,取而代之,我们要适配固定的服务速率,即带宽 μ \mu μ,如果我们能完全按照每 1 μ \dfrac{1}{\mu} μ1的时间发送一个数据包,那岂不是意味着 既不用排队,也不会空置 了吗?这才是真正的100%的利用率!
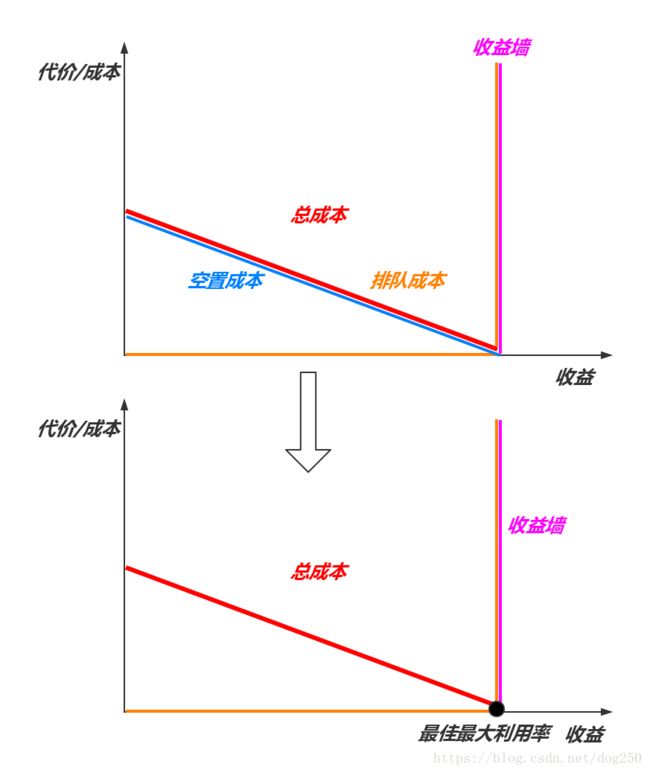
是的,这就是Pacing!
完全按照瓶颈带宽来空置发送的速率,使其和服务速率完全相匹配!这就是提高带宽利用率的最佳方法。上图也是TCP BBR的理论基础。
然而,说起来容易做起来难,首先,端到端的TCP如何知道带宽到底是多少?你又要说测量是不是?测量结果具有一个RTT的滞后性。因此你测得的结果永远都是以前的结果而不是现在的结果,由于网络情况存在随机性,更无法预测未来的情景,于是乎,完全按照瓶颈带宽来发送数据是不可能的,我们意识到一旦不可能实现这一点,就意味着会出现随机的排队或者资源空置,这无可避免!
其次,Pacing的方法增加了TCP端到端实现的复杂性,破坏了TCP完美的 自时钟。这个倒是有几句话可以说说。
事实上TCP的AIMD在设计之初就将Pacing的希望寄托于其ACK自时钟了。因为当时的设计者们相信,完美的 雅各布森管道 会把突发出去的数据包整成Pacing的方式到达对端,进而针对这些数据包ACK也会是Pacing的方式到达发送端,从而驱动下一轮的数据以Pacing的方式发送。
以上这个过程详见《TCP/IP详解(卷1)》。
然而事实证明,TCP的雅各布森管道并不完美,很少有网络能把突发的TCP数据整成Pacing的,最终,TCP便背上了突发协议的骂名。那么,雅各布森管道为什么不完美?有以下原因:
- 网络上存在多个TCP流而不是一个,新流的出现和旧流的消失不可预知;
- ACK的反向路径与数据包正向路径不对称导致形成的Pacing序列被破坏;
- ACK本身的丢失会导致突发;
- 一些路由器为了限制包量会根据TCP的积累应答机制将多个连续ACK聚合,造成突发;
- …
总之,网络链路太复杂,这使得依赖自时钟形成Pacing是不现实的,那么就不得不自己去算Pacing Rate了,而这个结果又是滞后的,或者说我们采集到的信息仅仅够算一个所谓的均值,这些信息远远不足以指导Pacing发送。
不管怎么样,我们依然会选择Pacing的方式来发送数据,至少在没有新的有别于AIMD的全新数学模型出现之前吧。
如此一来,只要我们选择了Pacing,那么就必然要在TCP发送端内置一套数据采集和计算引擎,这是AIMD模型所不需要的。
其实,很早以前就曾出现过一些争论,比如关于完全速率控制的Pacing Rate发送和完全ACK自时钟驱动的发送之间的争论,非常类似于中断和轮询之间的争论,最终,我们现在使用的Pacing发送,比如BBR的Pacing方式,事实上是融合了两者:
- 用ACK来驱动Pacing Rate的计算;
- 基于Pacing Rate来平滑发送数据。
总之,提高带宽的利用率的方法已经从捆绑多条TCP连接的方式进化到了提高单条TCP连接的带宽利用率。理论上证明Pacing的方法是最好的,但是如何精确计算Pacing却成了新的问题。
那么怎么办?