pytorch教程(学习笔记)——tensor操作+模型实例(线性回归、LR、MLP)
突然翻出了蛮早之前做的pytorch学习笔记,整理了一下决定发成博客方便复习,当时根据视频资料和网页资料整理的,视频资料现在找不到了,后面找到了再进行补充;网上的博客资料标在文中对应位置。
目录
- 一.pytorch安装
- 二.pytorch基础
-
- 1.pytorch张量与数据类型
- 2.张量基本操作
-
- (1).构建张量
- (2).size()、shape
- (3).adarray与tensor之间转换
- 3.张量运算与形状变换
-
- (1)张量运算——乘法
- (2)张量运算——加法
- (3)张量运算——均值、求和、tensor转标量、in-place函数
- (4)形状变换
- 4.张量自动微分
- 三.pytorch实例(线性回归、LR、MLP)
-
- 1.线性回归
- 2.逻辑回归 LR
- 3.多层感知机 MLP
- 4.使用Dataset、Dataloader对数据进行重构和加载,使用sklearn划分数据集
一.pytorch安装
安装的话就不细说了,随便找个博客照着装一下就行。我一般都是先装包环境管理工具anaconda,然后搭建虚拟环境,在虚拟环境中安装pytorch。
教程:https://blog.csdn.net/qq_32863549/article/details/107698516
二.pytorch基础
1.pytorch张量与数据类型
pytorch最基本的操作单位是:张量(tensor),它表示一个多维矩阵。
tensor类似于numpy的adarray;
pytorch类似于能让tensor操作在GPU上加速运行的numpy。
#使用dtype规定,使用tensor_a.type()查看
torch.float32 #等价于torch.FloatTensor
torch.float64
torch.int16
torch.int32
torch.int64
#张量进行类型转换 tensor.type()
tensor = torch.ones(2,3,dtype=torch.float64)
print(tensor)
print(tensor.type(torch.int16))
#output
tensor([[1., 1., 1.],
[1., 1., 1.]], dtype=torch.float64)
tensor([[1, 1, 1],
[1, 1, 1]], dtype=torch.int16)
2.张量基本操作
(1).构建张量
构建一个随机初始化张量:torch.rand()
a = torch.rand(2,3,dtype=torch.float64)
#output
tensor([[0.7320, 0.7675, 0.8107],
[0.0359, 0.9635, 0.0936]], dtype=torch.float64
全0矩阵:torch.zeros()
全1矩阵:torch.ones()
a = torch.zeros(2,3)
a = torch.ones(2,3)
#ouput
tensor([[0., 0., 0.],
[0., 0., 0.]])
tensor([[1., 1., 1.],
[1., 1., 1.]])
直接从数据构造张量:torch.tensor()
tensor = torch.tensor([1,2,3])
#output
tensor([1, 2, 3])
按顺序构建:torch.range()和torch.arange()
这两个方法的区别:
torch.arange(start=1, end=6)的范围是[0,6),类型是torch.LongTensor。
torch.range(start=1, end=6) 的范围是[0,6],类型是torch.FloatTensor。
注意:torch.range会提示在后续版本弃用,如下:
import torch
x = torch.arange(0, 6)
print(x)
print(x.type())
y = torch.range(0, 6)
print(y)
print(y.type())
#output
tensor([0, 1, 2, 3, 4, 5])
torch.LongTensor
tensor([0., 1., 2., 3., 4., 5., 6.])
torch.FloatTensor
D:/project/mine_project/test.py:17: UserWarning: torch.range is deprecated and will be removed in a future release because its behavior is inconsistent with Python's range builtin. Instead, use torch.arange, which produces values in [start, end).
y = torch.range(0, 6)
(2).size()、shape
查看张量size/shape:a.shape / a.size()
a = torch.ones(2,3)
print(a.shape)
print(a.size())
#output
torch.Size([2, 3])
torch.Size([2, 3])
(3).adarray与tensor之间转换
adarray转tensor:torch.from_numpy(numpy矩阵)
tensor转adarray:tensor矩阵.numpy()
a = np.random.rand(2,3)
a = torch.from_numpy(a)
print(a)
a = a.numpy()
print(a)
#output
tensor([[0.2882, 0.0426, 0.2148],
[0.1452, 0.7684, 0.3942]], dtype=torch.float64)
[[0.28821183 0.04255934 0.214766 ]
[0.14523209 0.768359 0.39420861]]
3.张量运算与形状变换
(1)张量运算——乘法
参考文章https://blog.csdn.net/da_kao_la/article/details/87484403,里面有详细示例,这里就简单整理一下
tensor乘法一共有四种:
- 1.点乘
*
(1)标量
tensor与标量k相乘:tensor1 * k
结果是tensor中每个数都与k相乘
(2)一维向量
tensor与行向量相乘:
结果是每列乘以行向量对应列的值(相当于把行向量的行复制,成为与lhs维度相同的Tensor). 注意此时要求Tensor的列数与行向量的列数相等。
tensor与列向量相乘:
结果是每行乘以列向量对应行的值(相当于把列向量的列复制,成为与lhs维度相同的Tensor). 注意此时要求Tensor的行数与列向量的行数相等。
(3)矩阵
两个举证A与B做点积A * B:
要求A与B的维度完全相同,即A的行数=B的行数,A的列数=B的列数
(4)broadcast
点积是broadcast的。broadcast是torch的一个概念,简单理解就是在一定的规则下允许高维Tensor和低维Tensor之间的运算。
例如:a是二维Tensor,b是三维Tensor,但是a的维度与b的后两位相同,那么a和b仍然可以做点积,点积结果是一个和b维度一样的三维Tensor,运算规则是:若c = a * b, 则c[i,*,*] = a * b[i, *, *],即沿着b的第0维做二维Tensor点积,或者可以理解为运算前将a沿着b的第0维也进行了expand操作,即a = a.expand(b.size()); a * b。
个人理解:就是上面一维向量乘法运算的推广。 - 2.torch.mul
用法与 * 相同,同样支持广播。
- 3.torch.mm
是数学里的矩阵乘法,要求相乘的矩阵维度满足矩阵乘法的维度要求。即:假设A的维度是mn,则与A相乘的矩阵维度需要为nx。
- 4.torch.matmul
torch.mm的broadcast版本。
(2)张量运算——加法
矩阵相加:tensor1 + tensor2
tensor1.add() #返回相加结果,不作用与tensor1自身
tensor1.add_() #作用于自身
广播:tensor1 + 一个常数
tensor1 = torch.rand(2,3)
tensor2 = torch.rand(2,3)
print('tensor1 = ',tensor1)
print('tensor2 = ',tensor2)
print('tensor1 + tensor2 = ',tensor1 + tensor2)
print('tensor1 + 2 = ',tensor1 + 2)
print('tensor1.add(tensor2) = ',tensor1.add(tensor2))
tensor1.add_(tensor2)
print('tensor1 = ',tensor1)
#output
tensor1 = tensor([[0.3285, 0.9291, 0.3383],
[0.1075, 0.1656, 0.5728]])
tensor2 = tensor([[0.6592, 0.1881, 0.5364],
[0.2333, 0.3622, 0.0747]])
tensor1 + tensor2 = tensor([[0.9877, 1.1172, 0.8747],
[0.3408, 0.5278, 0.6475]])
tensor1 + 2 = tensor([[2.3285, 2.9291, 2.3383],
[2.1075, 2.1656, 2.5728]])
tensor1.add(tensor2) = tensor([[0.9877, 1.1172, 0.8747],
[0.3408, 0.5278, 0.6475]])
tensor1 = tensor([[0.9877, 1.1172, 0.8747],
[0.3408, 0.5278, 0.6475]]) #此时使用add_()后tensor1被改变
(3)张量运算——均值、求和、tensor转标量、in-place函数
均值:tensor1.mean()
求和:tensor1.sum()
tensor1 = torch.rand(2,3)
print(tensor1)
print(tensor1.mean())
print(tensor1.sum())
#output
tensor([[0.8335, 0.7906, 0.6367],
[0.5129, 0.8101, 0.9918]])
tensor(0.7626)
tensor(4.5755)
tensor转标量:
若要将上述mean()结果转为标量:tensor1.mean().iter()
tensor1 = torch.rand(2,3)
print(tensor1)
print(tensor1.mean())
print(tensor1.mean().item())
#output
tensor([[0.5874, 0.6445, 0.4822],
[0.8164, 0.3147, 0.9425]])
tensor(0.6313)
0.6312952041625977
in-place(内建函数)
torch中所有带有‘_’的函数都是in-place(内建)函数,即作用于对象本身。
如:
相加:.add() / .add_()
逐元素乘法:.mul() / .mul_()
以e为底的指数:.exp() / .exp_()
(4)形状变换
tensor1.view() / tensor1.resize()
- tensor.view()
方法可以调整tensor的形状,但必须保证调整前后元素总数一致。view不会修改自身的数据,返回的新tensor与原tensor共享内存,即更改一个,另一个也随之改变。
tensor1 = torch.rand(2,3)
print(tensor1.view(3,2))
#output
tensor([[0.7265, 0.1727],
[0.5833, 0.4920],
[0.6138, 0.9458]])
注意:当view()的第一个参数为-1时候,则表示自动计算(根据第二个参数自动计算维度)
tensor1 = torch.rand(2,3)
print(tensor1.view(-1,1)) #由于维度=1的矩阵长度为1,所以转换后shape为(6,1)
print(tensor1.view(-1,2))
#output
tensor([[0.8563],
[0.7502],
[0.7580],
[0.1978],
[0.5422],
[0.4821]])
tensor([[0.8563, 0.7502],
[0.7580, 0.1978],
[0.5422, 0.4821]])
- tensor1.resize()
resize是另一种可用来调整size的方法,但与view不同,它可以修改tensor的尺寸。如果新尺寸超过了原尺寸,会自动分配新的内存空间,而如果新尺寸小于原尺寸,则之前的数据依旧会被保存下来。
import torch
a = torch.arange(0, 6).view(2, 3)
print(a)
b = a.resize_(1, 3)
print(b)
c = b.resize_(3, 3)
print(c)
#output
tensor([[0, 1, 2],
[3, 4, 5]])
tensor([[0, 1, 2]])
tensor([[ 0, 1, 2],
[ 3, 4, 5],
[2130189901024, 2130189901024, 2130189901024]])
4.张量自动微分
将Torch.Tensor属性.requires_grad 设置为True,pytorch将开始跟踪对此张量的所有操作。
完成计算后,可以调用.backward()并自动计算所有梯度。该张量的梯度将累加到.grad属性中。(因此一般在每个batch训练中会先将梯度清零)
tensor = torch.ones(2,3,requires_grad=True)
print(tensor)
print(tensor.requires_grad)
#output
tensor([[1., 1., 1.],
[1., 1., 1.]], requires_grad=True)
True
Tensor数据结构:
包含三个部分:.data, .grad, .grad_fn
.data:该tensor的值
.grad:该tensor的梯度
.grad_fn:保存着该tensor梯度计算的function的引用
tensor=torch.ones(2,2,requires_grad=True)
print(tensor.grad_fn)
tensor1 = tensor + 2
print(tensor1.grad_fn)
tensor2 = tensor1 * tensor1 + 3
out = tensor2.mean()
out.backward()
print(tensor.grad)
print(tensor.data)
print(out.grad_fn)
#output
None
<AddBackward0 object at 0x00000205F87B1518>
tensor([[1.5000, 1.5000],
[1.5000, 1.5000]])
tensor([[1., 1.],
[1., 1.]])
<MeanBackward0 object at 0x00000205F87B1518>
如果设置了requires_grad = True,在torch.no_grad()的上下文中不会跟踪梯度
with torch.no_grad():
print((tensor * tensor).requires_grad)
#output
False
如果设置了requires_grad = False,可以通过tensor.requires_grad_(True)进行修改。
但是需要注意的是:只有float类型可以这样用:
tensor = torch.ones(2,3,dtype=torch.int16)
tensor.requires_grad_(True)
#output
Traceback (most recent call last):
File "D:/project/mine_project/test.py", line 65, in <module>
tensor.requires_grad_(True)
RuntimeError: only Tensors of floating point dtype can require gradients
三.pytorch实例(线性回归、LR、MLP)
1.线性回归
本示例场景:
假设数据为:学历(x)与收入(y)——y = wx+b,使用均方误差作为损失函数;使用SGD所谓优化函数
import torch
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from torch import nn
data = pd.read_csv ('dataset_Income.csv')
data.info() #查看数据信息
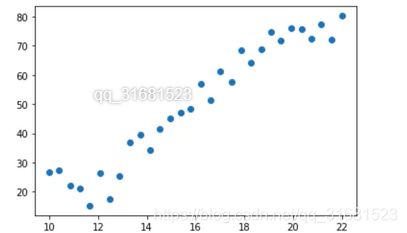
plt.scatter(data.Education,data.Income) #绘制散点图
plt.xlabel ('Education')
plt.show()
#数据预处理
#.values 返回数据取值,将data.Education由pandas的sequences转换为ndarray,再使用from_numpy转为tensor
X = torch.from_numpy(data.Education.values.reshape(-1,1).astype(np.float32))
Y = torch.from_numpy(data.Income.values.reshape(-1,1).astype(np.float32))
#建立模型
model = nn.Linear(1,1) #output = w*input+b
loss_fn = nn.MSELoss() #损失函数
lr = 0.0001 #学习率
opt = torch.optim.SGD(model.parameters(),lr=lr) #优化器
#训练 可通过model.weight 和 model.bias访问模型参数
epoch = 5000
for epoch in range(5000):
for x,y in zip(X, Y):
y_pred = model(x) #使用模型预测
loss = loss_fn(y,y_pred) #根据预测结果计算损失
opt.zero_grad() #把变量梯度清0
loss.backward() #求解梯度
opt.step() #优化模型参数
#训练结果可视化
plt.scatter(data.Education,data.Income)
plt.plot(X.numpy(),model(X).data.numpy(),c='r')


2.逻辑回归 LR
线性回归预测的是一个连续的值
逻辑回归回答的是“是否”的问题
所以给线性回归增加一个sigmoid层就可进行二分类;增加一个softmax进行多分类.;使用交叉熵损失函数。
代码包含数据预处理可能使用到的一些方法:
data = pd.read_csv(' dataset/credit-a.csv')#读取数据
print(data.info()) #数据总览
print(data.head()) #前n列,默认为5
X = data.iloc[:, :-1] #取特定列
Y = data.iloc[:,-1] #取特定列
print(data.unique()) #唯一值
# 如:data = pd.Series([1,2,4,4,5])
# print(data.unique())
# output:[1 2 4 5]
X = torch.from_numpy (X.values).type(torch.float32) #数据转换
Y = torch.from_numpy(Y.values.reshape(-1,1)).type(torch.float32)
#创建模型 out = sigmiod(w1*x1+w2*x2+ ... +w15*x1 + b)
model = nn.Sequential(
nn.Linear(15,1),
nn.Sigmoid()
)
#超参设定
loss_fn = nn.BCELoss()
opt = torch.optim.Adam(model.parameters(),lr=0.0001)
batch_size = 16
no_of_batch = 653//16
epoches = 5000
#训练
for epoch in range(epoches) :
for i in range(no_of_batch):
start = i*batch_size
end =start + batch_size
x = X[start: end]
y = Y[start: end]
y_pred = model(x)
loss = loss_fn(y_pred,y)
opt.zero_grad()
loss.backward()
opt.step()
model.state_dict() #查看状态字典
#模型评估
out = (model(X).data.numpy() >0.5).astype('int') #将模型输出转为0 1
acc = (out == Y.numpy()).mean() #求正确率
3.多层感知机 MLP
MLP结构就不赘述
代码依旧包含一些可能用到的数据预处理:
data = pd.read_csv(' dataset/HR.csv')#数据读取
#数据预处理
print(data.info())#总览
print(data.groupby(['salary', 'part']).size()) #分组查看数据量
print(data.left.value_counts()) #查看left列各值的数量
data.join(pd.get_dummies(data.salary)) #按需将部分列独热编码
Y_data = data.left.values.reshape(-1,1)
Y = torch.from_numpy(Y_data).type(torch.FloatTensor)
X_data = data[[c for c in data.columns if c !='left']].values #取除了y值那一列的其他列
X = torch.from_numpy(X_data).type(torch.FloatTensor)
#创建模型,本实例模型类继承于nn.Module
class Model(nn.Module):
def __init__(self):
supe().__init__o
self.Hiner_1 = nn.Linear(20, 64)
self.finer_2 = nn.Linear(64, 64)
self.liner_3 = nn.Linear(64, 1)
self.relu = nn.ReLUO
self.sigmoid = nn.Sigmoid()
def forward(self, input):
x = self.liner_1(input)
x = self.relu(x)
x = self.liner_2(x)
x = self.relu(x)
x = self.liner_3(x)
x = self.sigmoid(x)
return x
#注意 以上类也可以使用nn.functional的API,如下:
'''
import torch.nn.functional as F
class Model(nn.Module) :
def __init__(self):
superO.__init__o
self.liner_1 = nn.Linear(20,64)
self.liner_2 = nn. Linear(64,64)
self.liner_3 = nn. Linear(64,1)
def forward(self, input) :
x = F.relu(self.liner_l(input))
x = F.relu(self.liner_2(x))
x = F.sigmoid(self.liner_3(x))
return x
'''
model = Model()
#超参
lr = 0.0001
opt = torch. optim.Adam(model.parametersO,lr=lr)
loss_fn = nn. BCELoss()
batch_size = 64
no_of_batches = len(data)//batch_size
epochs = 100
#训练
for epoch in range(epochs):
for i in range(no_of_batches):
start = i*batch_size
end = start + batch_size
x = X[start: end]
y = Y[start: end]
y_pred = model(x)
loss = loss_fn(y_pred,y)
opt.zero_grad()
loss.backward()
opt.step()
with torch.no_grad():
print('epoch: ', epoch, 'loss: ',loss_fn (model(X),Y).data.item())
4.使用Dataset、Dataloader对数据进行重构和加载,使用sklearn划分数据集
- Dataset
#使用dataset对数据进行重构
from torch.utils.data import TensorDataset
HRdataset = TensorDataset(X, Y)
#MLP实例代码训练部分可以修改为:
for epoch in range(epochs):
for i in range(no_of_batches):
x,y = HRdataset[i*batch_size:(i+1)*batch_size]
y_pred = model(x)
loss = loss_fn(y_pred,y)
opt.zero_grad()
loss.backward()
opt.step()
with torch.no_grad():
print('epoch: ', epoch, 'loss: ',loss_fn (model(X),Y).data.item())
- Dataloader
Dataloader参数详情见pytorch中文文档:https://pytorch.org/docs/stable/data.html?highlight=dataloader#torch.utils.data.DataLoader

from torch. utils.data import DataLoader
HR_ds = TensorDataset(X,Y)
HR_dl = DataLoader(HR_ds,batch_size=batch_size,shuffle=True)
#MLP实例代码训练部分可以修改为:
for epoch in range(epochs):
for x,y in HR_dl:
y_pred = model(x)
loss = loss_fn(y_pred,y)
opt.zero_grad()
loss.backward()
opt.step()
with torch.no_grad():
print('epoch: ', epoch, 'loss: ',loss_fn (model(X),Y).data.item())
- sklearn划分数据集
from sklearn. model_selection import train_test_split
train_x,test_x,train_y,test_y = train_test_split(X_data,Y_data) #默认0.25的比例划分
train_x = torch.from_numpy(train_x).type(torch.float32)
train_y = torch.from_numpy(train_y).type(torch.float32)
test_x = torch.from_numpy(test_x).type(torch.float32)
test_y = torch.from_numpy(test_y).type(torch.float32)
train_ds = TensorDataset(train_x, train_y)
train_dl = DataLoader(train_ds,batch_size=batch_size,shuffle=True)
test_ds = TensorDataset(test_x, test_y)
test_dl = DataLoader(test_ds,batch_size=batch_size)
#计算验证精度
def accuracy(y_pred,y_true) :
y_pred= (y_pred > 0.5).type(torch.int32)
acc = (y_pred == y_true).float().mean()
return acc.item()
#训练打印增加正确率,则上述MLP训练代码修改为
for epoch in range(epochs):
for x,y in HR_dl:
y_pred = model(x)
loss = loss_fn(y_pred,y)
opt.zero_grad()
loss.backward()
opt.step()
with torch.no_grad():
epoch_train_accuracy = accuracy(model(train_x), train_y)
epoch_train_loss = loss_fn(model(train_x), train_y).data
epoch_test_accuracy = accuracy(model(test_x), test_y)
epoch_test_loss = loss_fn(model(test_x), test_y).data
print('epoch: ', epoch,
'train_loss: ', epoch_train_loss.item(),
'train_accuracy: ',epoch_train_accuracy,
'test_loss: ', epoch_test_loss.item(),
'test_accuracy: ', epoch_test_accuracy,
)
青古の每篇一歌
《广寒宫》
云母屏风花烛映影深
幻影成茧奈何奴身不由己几分