利用Python自动更换电脑壁纸

公众号后台回复“图书“,了解更多号主新书内容
作者:叶庭云,https://blog.csdn.net/fyfugoyfa
一、前言
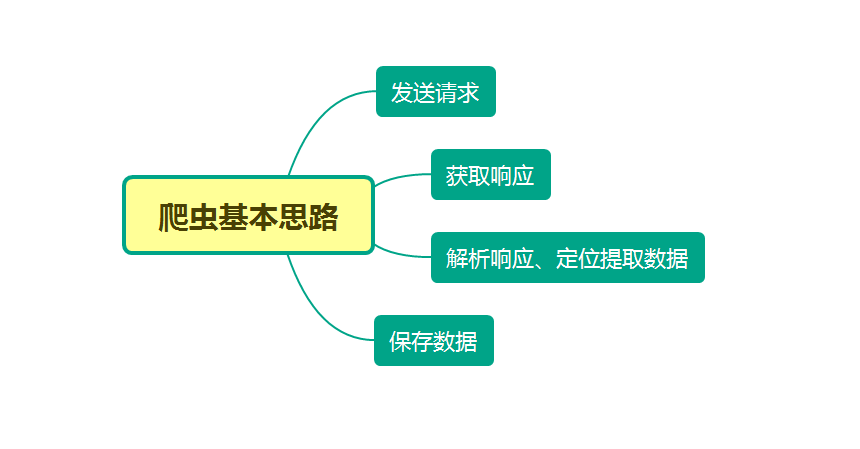
美桌网里有大量的高清图片素材和壁纸,并且可以免费下载,读者也可以根据自己需要爬取其他类型图片,方法是类似的,本文通过 python 爬虫批量下载美桌网的风景壁纸,熟悉写 python 爬虫的基本方法:发送请求、获取响应、解析并提取数据、保存到本地。图片保存到本地文件夹后,调用 windows 有关的API,实现自动更换电脑壁纸。
二、获取壁纸
目标URL:http://www.win4000.com/wallpaper_208_0_0_1.html
1. 分析网页
翻页查看 URL 变化规律:
http://www.win4000.com/wallpaper_208_0_0_1.html
http://www.win4000.com/wallpaper_208_0_0_2.html
http://www.win4000.com/wallpaper_208_0_0_3.html
http://www.win4000.com/wallpaper_208_0_0_4.html
http://www.win4000.com/wallpaper_208_0_0_5.html
页面里看到的每张图片点击进去有详情页,里面是套图
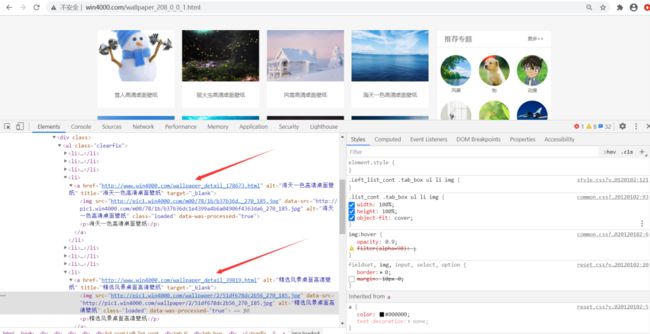
网页结构简单,容易提取到图片数据并下载到本地。
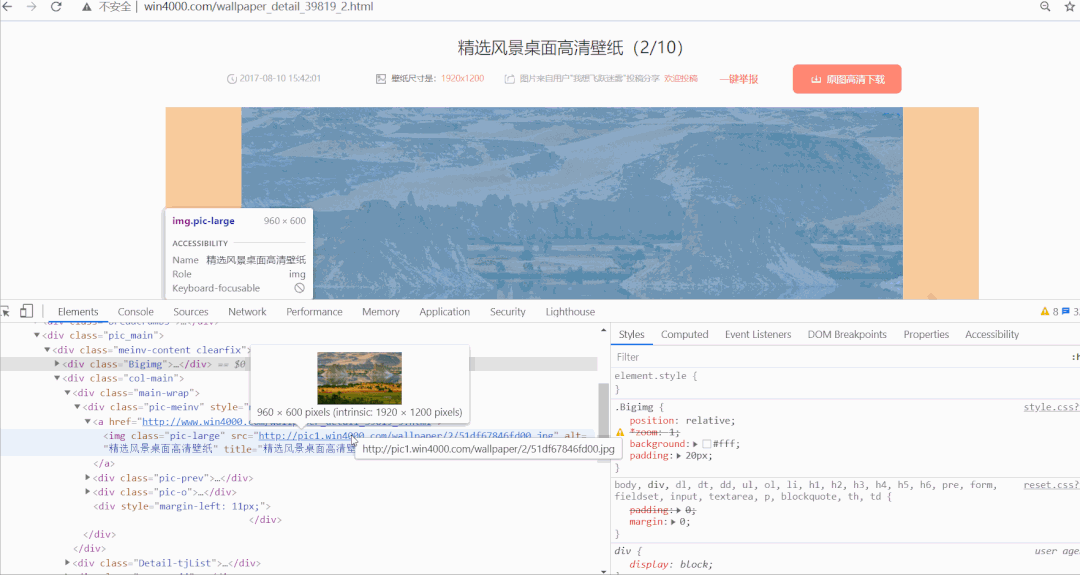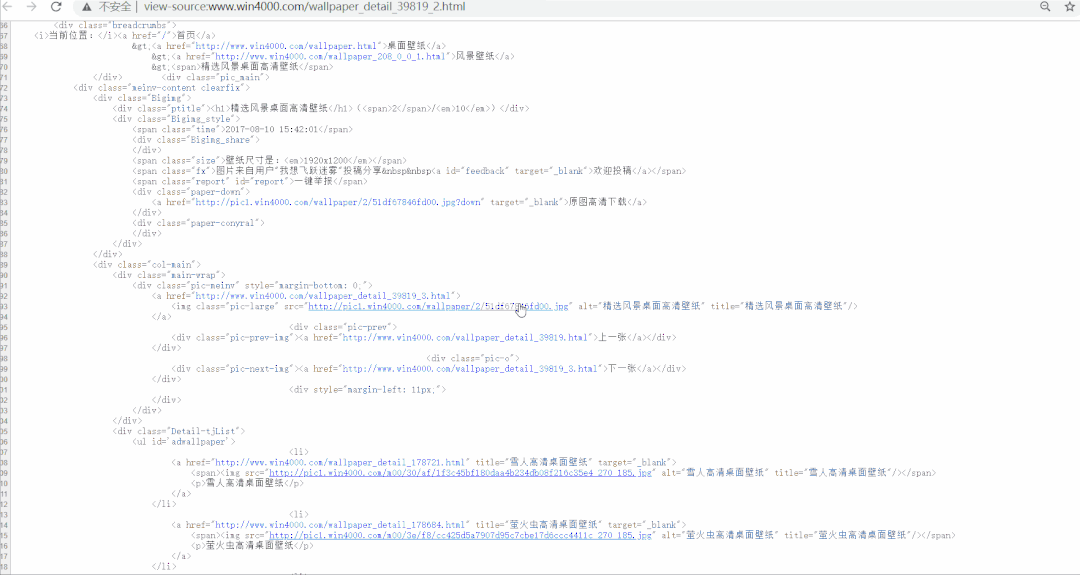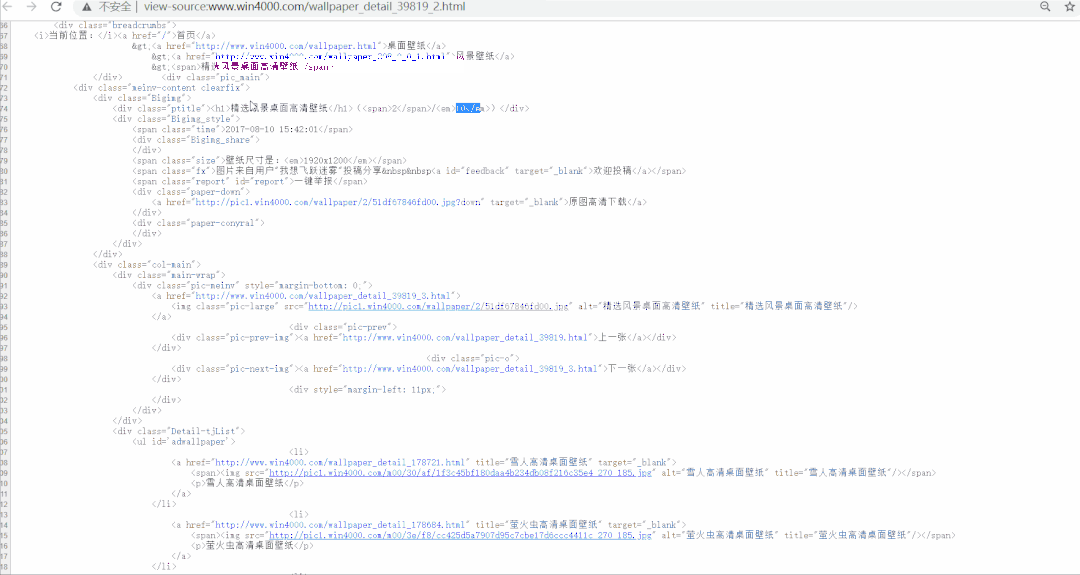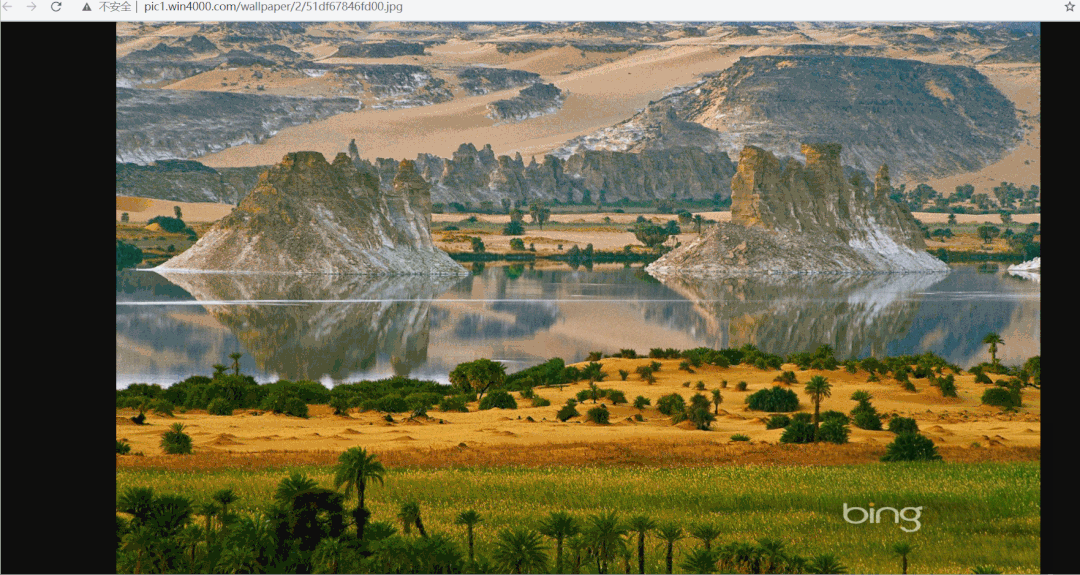
2. 爬虫基本思路
3. Python代码实现
导入用到的库
import requests
from random import randint
from lxml import etree
import os
import logging
from fake_useragent import UserAgent
from concurrent.futures import ThreadPoolExecutor
from time import sleep
获取5页的套图的URL
# 获取5页的套图的URL
def get_taotu_url():
taotu_urls = []
for i in range(1, 6):
url = f'http://www.win4000.com/wallpaper_208_0_0_{i}.html'
# 随机生成请求头 伪装
headers = {
'User-Agent': ua.random
}
# 发送请求 获取响应
rep = requests.get(url, headers=headers)
# print(rep.status_code) # 状态码 200
# print(rep.text)
html = etree.HTML(rep.text)
taotu_url = html.xpath('//div[@class="tab_tj"]/div/div/ul/li/a/@href')
print(len(taotu_url))
print(taotu_url)
# 一个页面有24组套图
# print(taotu_url, len(taotu_url), sep='\n')
taotu_urls.extend(taotu_url)
print(taotu_urls)
return taotu_urls
运行效果如下:
进入套图详情页爬取图片
# 进入套图详情页爬取图片
def get_img(url):
headers = {
'User-Agent': ua.random
}
# 发送请求 获取响应
rep = requests.get(url, headers=headers)
# 解析响应
html = etree.HTML(rep.text)
# 获取套图名称 最大页数
name = html.xpath('//div[@class="ptitle"]/h1/text()')[0]
os.mkdir(r'./桌面壁纸/{}'.format(name))
max_page = html.xpath('//div[@class="ptitle"]/em/text()')
# 字符串替换 便于之后构造url请求
url1 = url.replace('.html', '_{}.html')
# 翻页爬取这组套图的图片
for i in range(1, int(max_page[0]) + 1):
# 构造url
url2 = url1.format(i)
# 休眠
sleep(randint(1, 3))
# 发送请求 获取响应
reps = requests.get(url2, headers=headers)
# 解析响应
dom = etree.HTML(reps.text)
# 定位提取图片下载链接
src = dom.xpath('//div[@class="main-wrap"]/div[1]/a/img/@src')[0]
# 构造图片保存的名称
file_name = name + f'第{i}张.jpg'
# 请求下载图片 保存图片 输出提示信息
img = requests.get(src, headers=headers).content
with open(r'./桌面壁纸/{}/{}'.format(name, file_name), 'wb') as f:
f.write(img)
logging.info(f'成功下载图片:{file_name}')
完整实现如下:
# -*- coding: UTF-8 -*-
"""
@File :spider.py
@Author :叶庭云
@CSDN :https://yetingyun.blog.csdn.net/
"""
import requests
from random import randint
from lxml import etree
import os
import logging
from fake_useragent import UserAgent
from concurrent.futures import ThreadPoolExecutor
from time import sleep
# 日志输出的基本配置
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
# 随机产生请求头
ua = UserAgent(verify_ssl=False, path='fake_useragent.json')
# 不存在文件夹 就创建
if not os.path.exists('桌面壁纸'):
os.mkdir('桌面壁纸')
# 获取5页的套图的URL
def get_taotu_url():
taotu_urls = []
for i in range(1, 6):
url = f'http://www.win4000.com/wallpaper_208_0_0_{i}.html'
# 随机生成请求头 伪装
headers = {
'User-Agent': ua.random
}
# 发送请求 获取响应
rep = requests.get(url, headers=headers)
# print(rep.status_code) # 状态码 200
# print(rep.text)
html = etree.HTML(rep.text)
taotu_url = html.xpath('//div[@class="tab_tj"]/div/div/ul/li/a/@href')
print(len(taotu_url))
print(taotu_url)
# 一个页面有24组套图
# print(taotu_url, len(taotu_url), sep='\n')
taotu_urls.extend(taotu_url)
# print(taotu_urls)
return taotu_urls
# 进入套图详情页爬取图片
def get_img(url):
headers = {
'User-Agent': ua.random
}
# 发送请求 获取响应
rep = requests.get(url, headers=headers)
# 解析响应
html = etree.HTML(rep.text)
# 获取套图名称 最大页数
name = html.xpath('//div[@class="ptitle"]/h1/text()')[0]
os.mkdir(r'./桌面壁纸/{}'.format(name))
max_page = html.xpath('//div[@class="ptitle"]/em/text()')
# 字符串替换 便于之后构造url请求
url1 = url.replace('.html', '_{}.html')
# 翻页爬取这组套图的图片
for i in range(1, int(max_page[0]) + 1):
# 构造url
url2 = url1.format(i)
# 休眠
sleep(randint(1, 3))
# 发送请求 获取响应
reps = requests.get(url2, headers=headers)
# 解析响应
dom = etree.HTML(reps.text)
# 定位提取图片下载链接
src = dom.xpath('//div[@class="main-wrap"]/div[1]/a/img/@src')[0]
# 构造图片保存的名称
file_name = name + f'第{i}张.jpg'
# 请求下载图片 保存图片 输出提示信息
img = requests.get(src, headers=headers).content
with open(r'./桌面壁纸/{}/{}'.format(name, file_name), 'wb') as f:
f.write(img)
logging.info(f'成功下载图片:{file_name}')
# 主函数调用 开多线程
def main():
taotu_urls = get_taotu_url()
with ThreadPoolExecutor(max_workers=4) as exector:
exector.map(get_img, taotu_urls)
logging.info('=================== 图片全部下载成功啦! =====================')
if __name__ == '__main__':
main()
运行效果如下:
程序运行一会,电脑壁纸就全部爬取下来保存在本地文件夹了,读者也可以自行改参数爬取自己其他类型壁纸,自己喜欢的。
三、自动更换壁纸
用到的 python 模块有win32api、win32con、win32gui、pathlib、time、random等,基本原理要用到电脑注册表、调用 windows 有关API。
win32api:提供了常用的用户API
win32gui:提供了有关 windows 用户界面图形操作的API
win32con:宏定义文件,基本上所有宏都集成在这里(5k+)
代码如下:
# -*- coding: UTF-8 -*-
"""
@File :demo1.py
@Author :叶庭云
@CSDN :https://yetingyun.blog.csdn.net/
"""
import win32api
import win32con
import win32gui
import time
from pathlib import Path
import random
def Windows_img(paperPath):
# 读取注册表
k = win32api.RegOpenKeyEx(win32con.HKEY_CURRENT_USER, "Control panel\\Desktop", 0, win32con.KEY_SET_VALUE)
# 在注册表中写入属性值
win32api.RegSetValueEx(k, "wapaperStyle", 0, win32con.REG_SZ, "2") # 0 代表桌面居中 2 代表拉伸桌面
win32api.RegSetValueEx(k, "Tilewallpaper", 0, win32con.REG_SZ, "2")
# 刷新桌面
win32gui.SystemParametersInfo(win32con.SPI_SETDESKWALLPAPER, paperPath, win32con.SPIF_SENDWININICHANGE)
def changeWallpaper():
time_ = int(input("请输入壁纸更换时间间隔:"))
path = input('请输入保存壁纸的路径:')
# D:\test\桌面壁纸
p = Path(r'{}'.format(path))
imgs = list(p.glob('**/*.jpg'))
wall_papers = []
for img in imgs:
wall_papers.append(str(img))
# 随机打乱顺序
random.shuffle(wall_papers)
# print(wall_papers)
num = 0
while True:
Windows_img(wall_papers[num])
time.sleep(time_) # 设置壁纸更换间隔,这里为3秒,根据用户自身需要自己设置秒数
num += 1
if num == len(wall_papers): # 如果到了最后一张图片,则重新回到第一张
num = 0
if __name__ == '__main__':
changeWallpaper()
运行效果如下:
四、打包成exe
Python脚本不能在没有安装 Python 的机器上运行。我们想把这个脚本分享给朋友使用,可她电脑又没有装Python。这个时候如果将脚本打包成 exe 文件,微信发送给她,即使她的电脑上没有安装 Python 解释器,这个 exe 程序也能在上面运行。岂不美哉?
PyInstaller是一个跨平台的Python应用打包工具,支持Windows/Linux/MacOS三大主流平台,能够把 Python 脚本及其所在的 Python 解释器打包成可执行文件,从而允许最终用户在无需安装 Python 的情况下执行应用程序。
pyinstaller安装
pip install pyinstaller -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
pyinstaller打包python程序
PyInstaller 最简单使用只需要指定作为程序入口的脚本文件。PyInstaller 执行打包程序后会在当前目录下创建下列文件和目录:main.spec 文件,其前缀和脚本名相同,指定了打包时所需的各种参数;build 子目录,其中存放打包过程中生成的临时文件。warnxxxx.txt文件记录了生成过程中的警告/错误信息。如果 PyInstaller 运行有问题,需要检查warnxxxx.txt文件来获取错误的详细内容。xref-xxxx.html文件输出PyInstaller 分析脚本得到的模块依赖关系图。dist子目录,存放生成的最终文件。如果使用单文件模式将只有单个执行文件;如果使用目录模式的话,会有一个和脚本同名的子目录,其内才是真正的可执行文件以及附属文件。
pyinstaller参数详解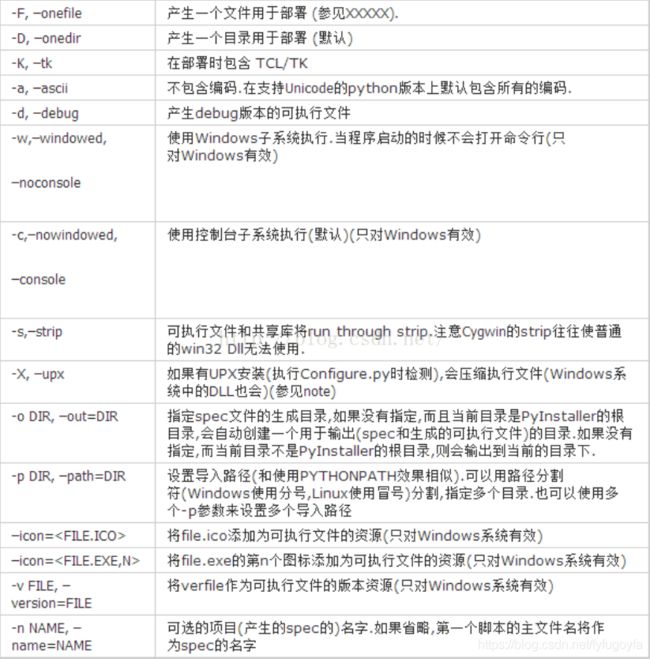
cmd切换到程序所在的目录,再输入以下代码:
pyinstaller -F -i 图标文件路径 .py文件路径
-F | --onefile:生成单一的可执行文件 -i | --icon:为执行文件指定图标
运行效果如下:
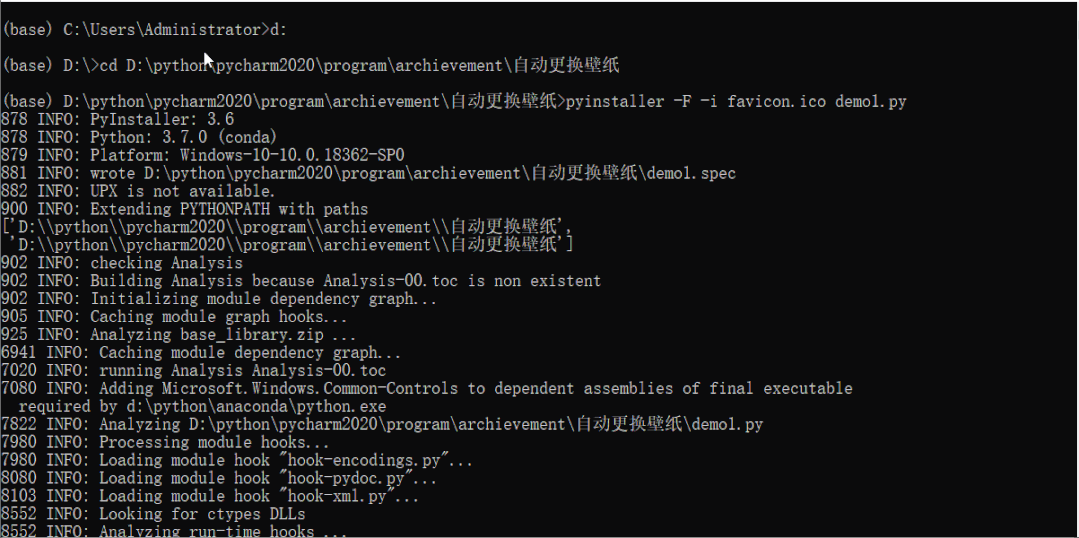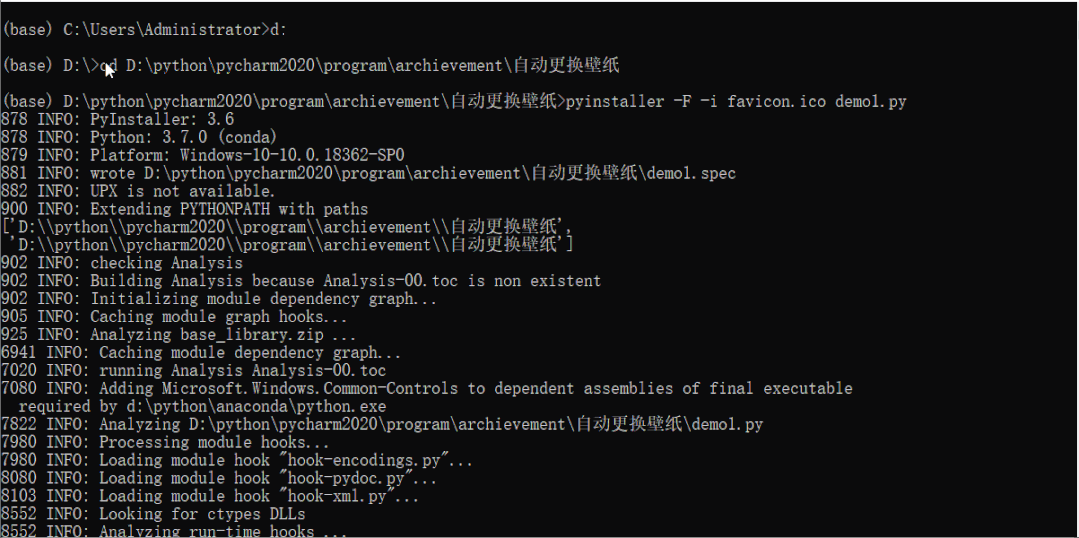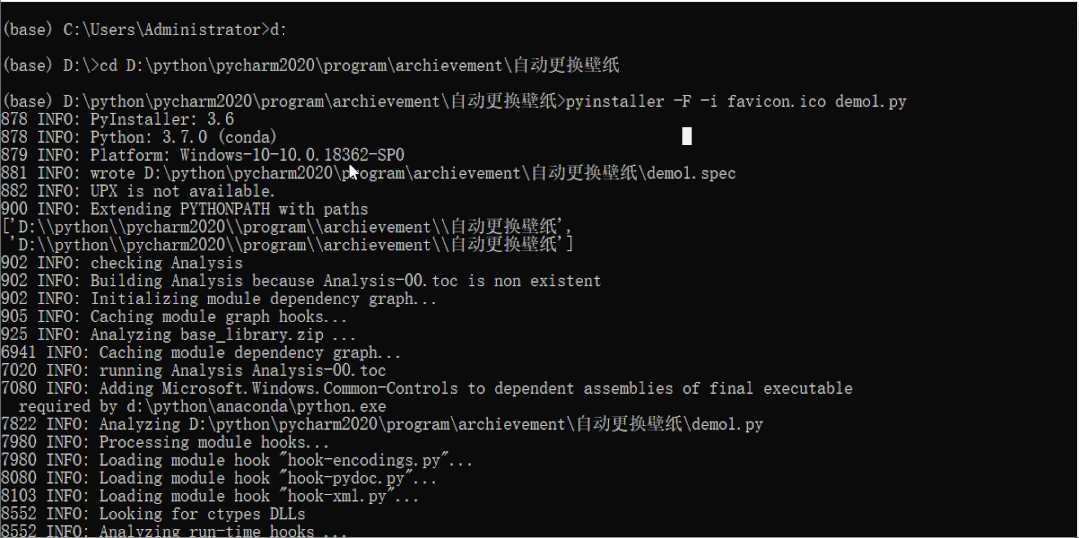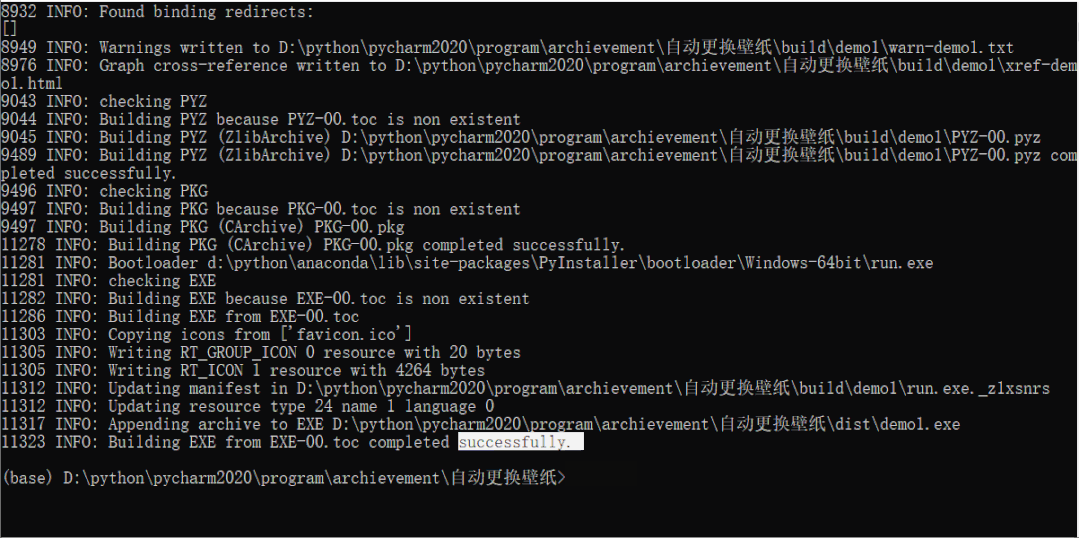
找到dist文件夹里的带图标的exe程序,双击运行,正常运行进入说明打包程序成功。结果如下:
◆ ◆ ◆ ◆ ◆麟哥新书已经在当当上架了,我写了本书:《拿下Offer-数据分析师求职面试指南》,目前当当正在举行活动,大家可以用相当于原价5折的预购价格购买,还是非常划算的:
数据森麟公众号的交流群已经建立,许多小伙伴已经加入其中,感谢大家的支持。大家可以在群里交流关于数据分析&数据挖掘的相关内容,还没有加入的小伙伴可以扫描下方管理员二维码,进群前一定要关注公众号奥,关注后让管理员帮忙拉进群,期待大家的加入。
管理员二维码:
猜你喜欢
● 卧槽!原来爬取B站弹幕这么简单● 厉害了!麟哥新书登顶京东销量排行榜!● 笑死人不偿命的知乎沙雕问题排行榜
● 用Python扒出B站那些“惊为天人”的阿婆主!● 你相信逛B站也能学编程吗