C++重温笔记(四): 继承和派生
1. 写在前面
c++在线编译工具,可快速进行实验: https://www.dooccn.com/cpp/
这段时间打算重新把c++捡起来, 实习给我的一个体会就是算法工程师是去解决实际问题的,所以呢,不能被算法或者工程局限住,应时刻提高解决问题的能力,在这个过程中,我发现cpp很重要, 正好这段时间也在接触些c++开发相关的任务,所有想借这个机会把c++重新学习一遍。 在推荐领域, 目前我接触到的算法模型方面主要是基于Python, 而线上的服务全是c++(算法侧, 业务那边基本上用go),我们所谓的模型,也一般是训练好部署上线然后提供接口而已。所以现在也终于知道,为啥只单纯熟悉Python不太行了, cpp,才是yyds。
和python一样, 这个系列是重温,依然不会整理太基础性的东西,更像是查缺补漏, 不过,c++对我来说, 已经5年没有用过了, 这个缺很大, 也差不多相当重学了, 所以接下来的时间, 重温一遍啦
资料参考主要是C语言中文网和光城哥写的C++教程,然后再加自己的理解和编程实验作为辅助,加深印象。
今天这篇文章是C++非常重要的一块,关于类的继承和派生,我们知道C++面向对象开发有四大特性: 抽象,封装,继承和多态。 前面发现,通过定义类,把事物的数据和功能进行抽象,而通过隐藏对象的属性和实现细节,对外只提供接口的方式对类的内部成员形成了封装。 这两个前面都已经了解过, 而这篇文章主要是整理继承,即子类继承父类的特征和行为,使得子类具有父类的成员变量和方法, 继承最大的一个好处就是代码复用,两个类有一些相同的属性和方法。
这篇内容会有些偏多,还是各取所需即可
主要内容如下:
- C++继承和派生初识
- C++继承的三种方式
- C++继承时的名字遮蔽问题与作用域嵌套
- C++继承时的对象内存模型
- C++基类和派生类的构造函数和析构函数
- C++的多继承
- C++虚继承(虚基类,虚继承构造函数,虚继承内存模型)
- C++向上转型(派生类指针赋值给基类)与过程原理剖析
- 借助指针突破访问权限的限制
Ok, let’s go!
2. C++继承和派生初识
2.1 C++面向对象开发的四大特性
在聊C++继承和派生之前,先来看看C++面向对象开发的四大特性,这样能先宏观把握一下继承到底位于什么样的位置。
C++面向对象开发有四大特性: 抽象,封装,继承和多态, 正所谓编程语言的背后都非常相似,Java既然也是面向对象的语言,同样也会有这四大特性。
抽象和封装前面其实已经整理过了, 封装主要讲的是信息隐藏,保护数据,而抽象又可以从两个层面来理解。
- 抽象:
从现实生活的具体事物到类层面的抽象(包括各个成员),比如人,有姓名,年龄等各个属性,又有学习,运动等各项功能,那么就可以定义people类把这些数据抽象出来,再通过创建对象的方式把具体实体人创建出来,调用相应的方法实现相应的功能。
宏观上,这是一种大层面的抽象,而这里面其实又可以看成数据抽象(目标的特性信息)和过程抽象(目标的功能是啥,注意不关注具体实现逻辑) - 封装
所谓封装,就是隐藏对象的属性和实现细节,仅仅对外公开接口,控制程序对类属性的读取和修改。在类的内部, 成员函数可以自由修改成员变量,进行精确控制,但是在类的内部,通过良好的封装, 减少耦合,隐藏实现细节。 - 继承
继承,就是子类继承父亲的特征和行为,使得子类具有父类的成员变量和方法。 这个和生活中儿子继承他爹的家产差不多是一个道理,更有意思的是继承有两种模式,单继承和多继承,单继承比较好理解,一个子类只继承一个父类, 而多继承是一个子类,继承多个父类,联想到生活中,可能有好几个爸爸。 - 多态
同一个行为具有多个不同表现形式或形态的能力,有两种表现形式覆盖和重载,这个到这里不理解也不要紧,下一篇文章会重点整理。- 重载: 这个之前学习过,相同作用域中存在多个同名函数,但函数的参数列表会不一样
- 重写或者叫覆盖: 主要体现在继承关系里面,子类重写了从他爸那里继承过来的函数,如果子类的对象调用成员函数的时候,如果子类的成员函数重写了他爸的,那么就执行子类自己的函数,否则继承他爸的。 这个也比较好理解,比如同样是挣钱,他爸的路子很可能和儿子的不一样,那么儿子在调用挣钱的时候,肯定是先找找儿子有没有独特的挣钱方式,如果没有,就默认和他爸一样,走他爸的挣钱方式。
2.2 再看继承
有了上面的宏观把握,再看继承就比较容易理解, 简单的讲,继承就是一个类从另一个类获取成员变量和成员函数的过程。 此时,被继承的类称为父类或基类,而继承的类称为子类或派生类。
C++中派生和继承是站在不同角度看的同种概念。继承时从儿子的角度看,派生是父亲的角度看,实际说的是一回事。
派生类除了拥有他爹的成员,还可以定义自己的新成员,增强功能,此时的好处就是只需要定义新成员即可,老的成员和功能,直接继承,实现了代码复用。
下面是两种典型使用继承的场景:
- 创建的新类与现有类相似,只多出若干个成员变量和成员函数的时候,用继承,减少代码量,且新类会拥有基类的所有功能
- 创建多个类, 他们拥有很多相似的成员变量或函数,可以用继承,把这些类共同的成员提取出来,定义为基类,然后从基类继承, 可以减少代码量,也方便后续的修改。
继承的语法:
class 派生类名:[继承方式] 基类名{
派生类新增加的成员
};
直接看个栗子:
class People{
public:
void setname(string name);
string getname();
private:
string m_name;
int m_age;
};
void People::setname(string name){
m_name = name;}
string People::getname(){
return m_name;}
class Student: public People{
public:
void setage(int age);
int getage();
private:
int m_age;
};
void Student::setage(int age){
m_age = age;}
int Student::getage(){
return m_age;}
int main(){
Student stu;
stu.setname("zhongqiang");
stu.setage(25);
cout << stu.getname() << "的年龄是" << stu.getage() << endl;
return 0;
}
这个例子比较简单,不解释, 这里就会发现, Student继承了People之后,就有他的setname()和getname()方法,在子类里面可以直接调用。
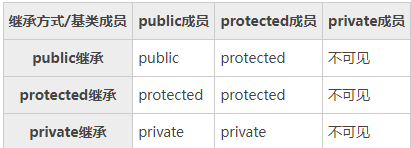
上面演示了public的继承方式,但继承方式其实有3种, public, private, protected, 这哥仨不仅可以修饰类的成员,还可以指定继承方式。如果不写,默认是private(成员变量和成员函数默认也是private), 那么这三种继承方式到底有啥区别呢?
3. C++继承的三种方式
3.1 哥仨修饰类成员
public, private, protected这哥仨,可以修饰类成员,之前见识过public和private了, 这里加上protected之后统一整理下访问权限的问题。
类成员的访问权限从高到低依次是public --> protected --> private。 public成员可以通过对象来访问, private成员不能通过对象访问, protected成员和private成员蕾西, 也不能通过对象访问。
But, 如果存在继承关系的时候, protected和private就不一样了: 基类中的protected成员可以在派生类中使用,但是基类中的private成员不能再派生类中使用。
3.2 继承方式会影响基类成员在派生类中的访问权限
不同的继承方式使得基类成员在派生类中的访问权限也不一样, 下面这个很重要:
- public继承方式
- 基类中所有public成员 -> 继承到派生类 -> public属性
- 基类中所有protected成员 -> 继承到派生类 -> protected 属性
- 基类中所有private 成员 -> 继承到派生类 -> 不能使用
- protect继承方式
- 基类中所有public成员 -> 继承到派生类 -> protected属性
- 基类中所有protected成员 -> 继承到派生类 -> protected 属性
- 基类中所有private 成员 -> 继承到派生类 -> 不能使用
- private继承方式
- 基类中所有public成员 -> 继承到派生类 -> private属性
- 基类中所有protected成员 -> 继承到派生类 -> private 属性
- 基类中所有private 成员 -> 继承到派生类 -> 不能使用
使用方法:
- 基类成员在派生类中的访问权限不得高于继承方式中指定的权限,也就是说**继承方式中的public, protected, private是用来指明基类成员在派生类中最高访问权限的。
- 不管继承方式如何, 基类中的private成员在派生类中始终不能使用(不能在派生类的成员函数中访问或者调用)
- 如果希望基类的成员能够在派生类继承并且使用, 那么这些成员应该声明public或者protected, 只有那些不希望在派生类中使用的成员声明为private
- 如果希望基类的成员既不向外暴露(不能通过对象访问), 还能在派生类中使用, 那么就声明为protected。
下面通过上面的代码例子来演示下, 由于private和protect继承方式会改变基类成员在派生类中的访问权限,导致继承关系复杂, 所以实际开发中一般使用public。
把上面的栗子修改下, 测试下上面的这几种情况,方便理解,这里只看public继承下面的。
class People{
public:
void setname(string name);
string getname();
void setage(int age);
int getage();
void setsex(string sex);
string getsex();
void setwork(string work);
string getwork();
// 属性
string m_sex;
protected:
string m_work;
private:
string m_name;
int m_age;
};
void People::setname(string name){
m_name = name;}
string People::getname(){
return m_name;}
void People::setage(int age){
m_age = age;}
int People::getage(){
return m_age;}
void People::setsex(string sex){
m_sex=sex;}
string People::getsex(){
return m_sex;}
void People::setwork(string work){
m_work=work;}
string People::getwork(){
return m_work;}
class Student: public People{
public:
void setscore(float score);
float getscore();
// 定义问候方法,这里面会访问基类的私有属性
string helloname();
string hellowork();
string hellosex();
private:
float m_score;
};
void Student::setscore(float score){
m_score = score;}
float Student::getscore(){
return m_score;}
// 访问基类中的公有属性
string Student::hellosex(){
return "hello, " + m_sex;}
// 访问基类中的protect属性
string Student::hellowork(){
return "hello, " + m_work;}
// 访问基类中的私有属性
// string Student::helloname(){return "hello, " + m_name;} error: 'std::string People::m_name' is private within this context
int main(){
Student stu;
stu.setname("zhongqiang");
stu.setsex("man");
stu.setwork("student");
stu.setage(25);
stu.setscore(66.6);
cout << stu.getname() << "今年" << stu.getage() << ",性别: " << stu.getsex() << ", 职业: " << stu.getwork() << ", 分数: " << stu.getscore() << endl;
//cout << stu.helloname() << endl;
cout << stu.hellowork() << endl;
cout << stu.hellosex() << endl;
// 直接通过对象访问属性
cout << stu.m_sex << endl; // 公有属性到子类中依然是公有, 可以被访问
//cout << stu.m_name << endl; // error 'std::string People::m_name' is private within this context
//cout << stu.m_work << endl; // error 'std::string People::m_work' is protected within this context
//cout << stu.m_score << endl; // error 'float Student::m_score' is private within this context
return 0;
}
在这里面就可以看出来, 在Student里面的成员函数中,只能访问到他爹的public属性和protect属性,不能访问他爹的private属性。而如果是通过Student的对象, 那么只能访问public属性,protect和private的都访问不到。
在派生类中访问基类的private成员的唯一方法就是借助基类的非private成员函数,如果基类没有非private成员函数,那么该成员在派生类中将无法访问。
这里注意一个问题,这里说的是基类的 private 成员不能在派生类中使用,并不是说基类的 private 成员不能被继承。实际上,基类的 private 成员是能够被继承的,并且(成员变量)会占用派生类对象的内存,它只是在派生类中不可见,导致无法使用罢了。private 成员的这种特性,能够很好的对派生类隐藏基类的实现,以体现面向对象的封装性。
3.3 using改变访问权限
using关键字可以改变基类成员在派生类中的访问权限, 比如将public改成private, protected改成public。
注意:using 只能改变基类中 public 和 protected 成员的访问权限,不能改变 private 成员的访问权限,因为基类中 private 成员在派生类中是不可见的,根本不能使用,所以基类中的 private 成员在派生类中无论如何都不能访问
class People{
public:
void setname(string name);
string getname();
void setage(int age);
int getage();
void setsex(string sex);
string getsex();
void setwork(string work);
string getwork();
// 属性
string m_sex;
protected:
string m_work;
private:
string m_name;
int m_age;
};
void People::setname(string name){
m_name = name;}
string People::getname(){
return m_name;}
void People::setage(int age){
m_age = age;}
int People::getage(){
return m_age;}
void People::setsex(string sex){
m_sex=sex;}
string People::getsex(){
return m_sex;}
void People::setwork(string work){
m_work=work;}
string People::getwork(){
return m_work;}
class Student: public People{
public:
void setscore(float score);
float getscore();
// 定义问候方法,这里面会访问基类的私有属性
string helloname();
string hellowork();
string hellosex();
using People::m_work; // 将m_work提升成public权限
private:
float m_score;
using People::m_sex; // 将m_sex降低为private权限
};
void Student::setscore(float score){
m_score = score;}
float Student::getscore(){
return m_score;}
// 访问基类中的公有属性
string Student::hellosex(){
return "hello, " + m_sex;}
// 访问基类中的protect属性
string Student::hellowork(){
return "hello, " + m_work;}
// 访问基类中的私有属性
// string Student::helloname(){return "hello, " + m_name;} error: 'std::string People::m_name' is private within this context
int main(){
Student stu;
stu.setname("zhongqiang");
stu.setsex("man");
stu.setwork("student");
stu.setage(25);
stu.setscore(66.6);
cout << stu.getname() << "今年" << stu.getage() << ",性别: " << stu.getsex() << ", 职业: " << stu.getwork() << ", 分数: " << stu.getscore() << endl;
// 直接通过对象访问属性
//cout << stu.m_sex << endl; // 这个这时候就会报错了
cout << stu.m_work << endl; // 这个就可以访问了
return 0;
}
注意,using修改的是派生类里面的成员访问权限。并且是只能修改public和protected的访问权限。
4. C++继承时的名字遮蔽问题与作用域嵌套
4.1 名字遮蔽问题
这个说的情况是派生类中的成员(变量和函数),如果和基类中的成员重名,那么在派生类中使用该成员,实际上用的是派生类新增的成员,而不是从基类继承过来的。 即派生类遮蔽掉从基类继承过来的成员。
下面的这个例子,是Student继承了People, 又重写了People的show函数,那么通过Student对象调用show的时候,实际上是用的Student自身的show函数,但People的show函数也被Student继承了过来,如果想用,需要加上类名和域解析符。
class People{
public:
void show();
protected:
string m_name;
int m_age;
};
void People::show(){
cout << m_name << " " << m_age << endl;
}
class Student: public People{
public:
Student(string name, int age, string sex);
void show(); // 遮蔽基类的show()
private:
string m_sex;
};
Student::Student(string name, int age, string sex): m_sex(sex){
m_name = name;
m_age = age;
//m_sex = sex;
}
void Student::show(){
cout << m_name << " " << m_age << " " << m_sex << endl;
}
int main(){
Student stu("zhongqiang", 25, "man");
// 派生类新增的成员函数
stu.show(); // zhongqiang 25 man
// 使用从基类继承过来的成员函数
stu.People::show(); // zhongqiang 25
return 0;
}
这里我在实验的时候,发现个问题,就是Student的构造函数定义的时候, 本来是想用构造函数初始化列表的方式,一开始写的代码是这样:
Student::Student(string name, int age, string sex): m_name(name), m_age(age){
m_sex = sex;
}
此时编译错误, 报错原因class 'Student' does not have any field named 'm_name', 而如果写成上面那种形式,或者不用参数化列表的方式,就没问题, 所以这里我感觉,参数化列表那个地方的参数,应该是当前类具有的成员变量才行, 继承过来的应该是不能往这里写。
上面的例子,其实就是派生类对基类的函数重写,内部在执行的时候, 先找派生类里面有没有对应的函数,如果有,就先执行派生类里面的重名函数,如果没有,那么再执行基类里面定义的。
那么,如果派生类里面的函数和基类的函数重名,但形参列表不一样的时候,此时会发生重载现象吗? 答: 不会。 一旦派生类中有同名函数,不管他们的参数是否一样,都会把基类中所有的同名函数遮蔽掉。
这个就不用例子演示了,而是整理下背后的所以然吧。
4.2 作用域嵌套
之前整理过,每个类都会有自己的作用域, 在这个作用域内会定义类的成员,那么,当存在继承关系的时候, 派生类的作用域嵌套在基类的作用域之内,如果一个名字在派生类的作用域没有找到,编译器会继续到外层的基类作用域查找该名字的定义。
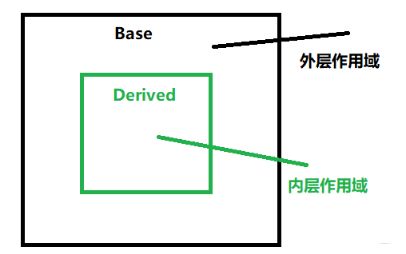
两条:
- 一旦在外层作用域中声明或定义了某个名字, 那么它嵌套着的所有内层作用域都能访问这个名字
- 同时,允许在内层作用域重新定义外层作用域中已经有的名字
看个嵌套作用域的例子:
class A{
public:
void func();
public:
int n = 500;
};
void A::func(){
cout<<"hello, changjinhu!!!"<<endl; }
class B: public A{
public:
int n = 5000;
int m;
};
class C: public B{
public:
int n = 50000;
int x;
};
int main(){
C obj;
cout << obj.n << endl;
obj.func();
cout<<sizeof(C)<<endl;
return 0;
}
这个例子中的继承关系, B继承A, C继承B,那么作用域的嵌套关系如下:

- obj是C类的对象, 访问成员变量n时,由于C类自己有n, 那么编译器就会直接用,此时不会去B或者A中找,即派生类中的成员变量会遮蔽基类中的成员变量。
- 访问成员函数
func()的时候,编译器没有在C类里面找到func这个名字,会继续到B作用域找,也没有找到,再往外,从A里面找到了,于是,调用A类作用域的func()函数。 - 对于成员变量,名字查找过程好理解,成员函数要注意,编译器仅仅是根据函数名字查找,不理会函数参数,所以一旦在内层作用域找到同名函数,不管有几个,编译器都不会再到外层作用域查找,编译器仅仅把最内层作用域的这些同名函数作为一组候选, 而也只有这组候选构成一组重载函数。 即只有一个作用域内的同名函数才会有重载关系,不同作用域的同名函数会造成遮蔽,外层函数会被内层遮蔽掉, 这其实也是重载和重写的一个区别了。
有了上面这些,就能回答上面的两点疑问:
- 构造函数的参数初始化列表那里, 初始化列表里面要列本类作用域里面的成员,如果是外层作用域,会报错找不到成员
- 派生类和基类拥有不同的作用域,所以它们的同名函数不具有重载关系, 而是重写或者覆盖。
5. C++继承时的对象内存模型
没有继承时对象内存的分布情况,成员变量和成员函数分开存储:
- 对象的内存中只包含成员变量,存储在栈区或者堆区(new创建)
- 成员函数与对象内存分离,存储在代码区
有继承关系的时候, 派生类的内存模型可以看成是基类成员变量和新增成员变量的总和,所有成员函数仍然存储在另外一个区域–代码区,由所有对象共享。
看个例子:
class A{
public:
A(int a, int b);
protected:
int m_a;
int m_b;
};
A::A(int a, int b): m_a(a), m_b(b){
}
class B: public A{
public:
B(int a, int b, int c);
private:
int m_c;
};
// 这种参数初始化应该是这么写
B::B(int a, int b, int c): A(a, b), m_c(c){
}
class C: public B{
public:
C(char a, int b, int c, int d);
private:
int m_d;
};
C::C(char a, int b, int c, int d): B(a, b, c), m_d(d){
}
// 成员遮蔽的情况
class D: public B{
public:
D(char a, int b, int c, int d);
private:
int m_b; // 遮蔽A类的成员变量
int m_c; // 遮蔽B类的成员变量
int m_d; // 新增成员变量
};
D::D(char a, int b, int c, int d): B(a, b, c), m_b(b), m_c(c), m_d(d){
}
这里面写了四个类,继承关系是A是最基类, B继承A,新增成员m_c, C继承B,新增成员m_d, D继承B,新增成员m_b, m_c, m_d, 前面两个产生了覆盖。
成员函数不必多说,与成员变量分开,存到了代码区,这里主要看下成员变量每个类的内存存储情况。

三点需要注意:
- 派生类的对象模型中,会包含所有基类的成员变量,但如果在派生类中通过派生成员函数访问到,必须基类的声明为protected或者public的。
- 基类的成员变量排在前面,派生类的成员变量排在后面
- 如果想在派生类构造函数中通过参数化列表给基类的成员变量赋值,此时要借助基类的构造函数才行,否则会报派生类field内找不到成员变量的问题,毕竟是继承过来的。
6. C++基类和派生类的构造函数和析构函数
6.1 构造函数
基类的成员函数可以被继承,可以通过派生类的对象访问,但类的构造函数不能被继承。
在设计派生类时, 对继承过来的成员变量初始化工作也要由派生类的构造函数完成,但大部分基类都有Private属性的成员变量,在派生类无法访问(不能用派生类构造函数初始化), 此时需要在派生类的构造函数中调用基类的构造函数。
下面这个例子:
class People{
public:
People(string name, int age);
protected:
string m_name;
int m_age;
};
People::People(string name, int age): m_name(name), m_age(age){
}
class Student: public People{
public:
Student(string name, int age, float score);
void display();
private:
float m_score;
};
//People(name, age)是调用基类的构造函数
Student::Student(string name, int age, float score): People(name, age), m_score(score){
}
void Student::display(){
cout << m_name << m_age << m_score << endl;
}
int main(){
Student stu("zhongqaing", 25, 100);
stu.display();
return 0;
}
这里给基类的成员变量赋值的时候,是调用的基类的构造函数People(name, age), 并将name和age作为实参传递给他,注意这里是调用,此时也可以用常量给他赋值,比如People("zhongqiang", 25),这样子。
派生类的构造函数,总是先调用基类的构造函数再执行其他代码(包括参数初始化列表以及其他函数体的代码)
关于构造函数的调用顺序, 基类的构造函数总是被优先调用,即创建派生类对象的时候, 会先调用基类的构造函数,如果继承关系好几层A --> B --> C, 那么创建C类对象构造函数的执行顺序: A类构造函数 --> B类构造函数 --> C类构造函数,另外就是派生类构造函数中只能调用直接基类的构造函数,不能调用间接基类的,即C不能调用A的构造函数,只能调用B的。 这么做是因为在B里面调用了A的构造函数, C如果再调,可能A构造函数调用了多次,重复了初始化工作。
事实上,通过派生类创建对象时必须要调用基类的构造函数,这是语法规定。换句话说,定义派生类构造函数时最好指明基类构造函数;如果不指明,就调用基类的默认构造函数(不带参数的构造函数);如果没有默认构造函数,那么编译失败
6.2 析构函数
和构造函数一样,析构函数也不能被继承,但派生类的析构函数中不用显式调用基类的构造函数,析构函数的执行顺序和构造函数的执行顺序恰好相反:
- 创建派生类对象时,构造函数的执行顺序和继承顺序相同,先执行基构造函数,再执行派生类构造函数
- 销毁派生类对象时,析构函数执行顺序和继承顺序相反,先执行派生类析构函数,再执行基类析构函数
class A{
public:
A(){
cout<<"A constructor"<<endl;}
~A(){
cout<<"A destructor"<<endl;}
};
class B: public A{
public:
B(){
cout<<"B constructor"<<endl;}
~B(){
cout<<"B destructor"<<endl;}
};
class C: public B{
public:
C(){
cout<<"C constructor"<<endl;}
~C(){
cout<<"C destructor"<<endl;}
};
int main(){
C test;
return 0;
}
// 结果
A constructor
B constructor
C constructor
C destructor
B destructor
A destructor
7. C++多继承
派生类只有一个基类,这叫单继承,在C++里面,允许一个派生类有多个基类,这叫多继承
多继承容易让代码逻辑复杂,思路混乱,在Java中取消了多继承
多继承语法:
class D: public A, private B, protected C{
//类D新增加的成员
}
7.1 多继承下的构造函数
和单继承形式基本相同,在派生类中的构造函数中,要调用多个基类的构造函数。
D(形参列表): A(实参列表), B(实参列表), C(实参列表){
//其他操作
}
基类构造函数的调用顺序和和它们在派生类构造函数中出现的顺序无关,而是和声明派生类时基类出现的顺序相同。这个无论怎么在这里写这个顺序,总是先调用A类构造函数,然后调用B类,最后调用C类的。
同理,析构函数的执行顺序和构造函数的执行顺序相反。
当两个或者多个基类有同名成员,如果直接访问该成员,会产生命名冲突,编译器不知道使用哪个基类的成员,这时候,要在成员名字前面加上类名和域解析符::,显式的指明到底使用哪个类的成员,消除二义性。
看个整体的例子:
#include 7.2 多继承时的对象内存模型
这个其实和单继承时候的差不多,直接看个有覆盖的例子即可。
//基类A
class A{
public:
A(int a, int b);
protected:
int m_a;
int m_b;
};
A::A(int a, int b): m_a(a), m_b(b){
}
//基类B
class B{
public:
B(int b, int c);
protected:
int m_b;
int m_c;
};
B::B(int b, int c): m_b(b), m_c(c){
}
//派生类C
class C: public A, public B{
public:
C(int a, int b, int c, int d);
public:
void display();
private:
int m_a;
int m_c;
int m_d;
};
C::C(int a, int b, int c, int d): A(a, b), B(b, c), m_a(a), m_c(c), m_d(d){
}
C继承A和B,主要是看下C里面内存分布图:
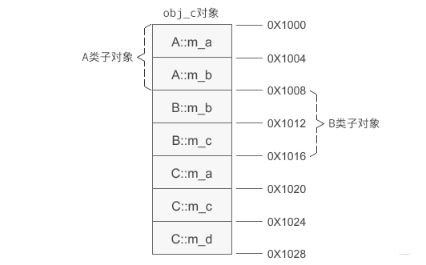
基类对象的排列顺序和继承时候声明的顺序相同。
8. C++虚继承
8.1 虚基类
多继承很容易产生命名冲突问题,比如下面这种情况:
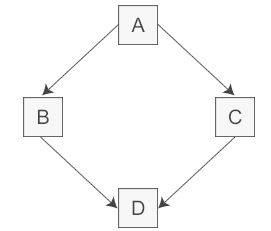
类 A 派生出类 B 和类 C,类 D 继承自类 B 和类 C,这个时候类 A 中的成员变量和成员函数继承到类 D 中变成了两份,一份来自 A-->B-->D 这条路径,另一份来自 A-->C-->D 这条路径。
在一个派生类中保留间接基类的多份同名成员,虽然可以在不同的成员变量中分别存放不同的数据,但大多数情况下这是多余的:因为保留多份成员变量不仅占用较多的存储空间,还容易产生命名冲突。假如类 A 有一个成员变量 a,那么在类 D 中直接访问 a 就会产生歧义,编译器不知道它究竟来自 A -->B-->D 这条路径,还是来自 A-->C-->D 这条路径。
为了解决多继承时候命名冲突和冗余数据问题,C++提出了虚继承,使得派生类中只保留一份间接基类的成员。
看个例子:
// 间接基类A
class A{
protected:
int m_a;
};
// 直接基类B
class B: virtual public A{
protected:
int m_b;
};
// 直接基类C
class C: virtual public A{
protected:
int m_c;
};
// 派生类D
class D: public B, public C{
public:
void seta(int a){
m_a = a;} // 如果不是虚继承, 这里会报错,编译器不知道这个m_a走的是B还是C这条线
void setb(int b){
m_b = b;}
void setc(int c){
m_c = c;}
void setd(int d){
m_d = d;}
private:
int m_d;
};
虚继承的目的是让某个类做出声明, 承诺共享它的基类。 其中,这个被共享的基类被称为虚基类,比如这里的A。 在这种机制下, 不论虚基类在继承体系中出现了多少次,在派生类中都包含一份虚基类的成员。

虚继承有一个不太直观的特征: 必须在虚派生的真实需求出现前就已经完成虚派生的操作,比如当当以D类时才出现对虚派生的需求,但如果B类和C类不是从A类虚派生的,那么D还是会保留A的两份成员。 即虚派生只影响从指定了虚基类的派生类中进一步派生出来的类,不会影响派生类本身(B或者C)
在实际开发中,位于中间层次的基类将其继承声明为虚继承一般不会带来什么问题。通常情况下,使用虚继承的类层次是由一个人或者一个项目组一次性设计完成的。对于一个独立开发的类来说,很少需要基类中的某一个类是虚基类,况且新类的开发者也无法改变已经存在的类体系。
因为在虚继承的最终派生类中只保留了一份虚基类的成员,所以该成员可以被直接访问,不会产生二义性。此外,如果虚基类的成员只被一条派生路径覆盖,那么仍然可以直接访问这个被覆盖的成员。但是如果该成员被两条或多条路径覆盖了,那就不能直接访问了,此时必须指明该成员属于哪个类。
比如,上面这个图, 假设A定义了一个x的成员变量,当在D中直接访问x的时候,会有三种可能性:
- 如果B和C都没有x的定义,那么x将被解析为A的成员,此时不存在二义性
- 如果B或C其中一个类定义了x,也不会有二义性,派生类的x要比虚基类的x优先级更高
- 如果B和C都定义了x,那么直接访问x会产生二义性问题。
总之, 多继承不提倡使用,能用单一继承解决的问题,不要用多继承,这也是Java等不支持多继承的原因, 写多了容易混乱。
8.2 虚继承的构造函数
虚继承中,虚基类由最终的派生类进行初始化的,即最终派生类的构造函数必须要调用虚基类的构造函数。 对最终派生类来说, 虚基类是间接基类,不是直接基类。 这跟普通继承不同,在普通继承中,派生类构造函数只能调用直接基类的构造函数,不能调用间接基类的。
下面这个例子,会体现虚继承和普通多继承的不一样:
//虚基类A
class A{
public:
A(int a);
protected:
int m_a;
};
A::A(int a): m_a(a){
}
//直接派生类B
class B: virtual public A{
public:
B(int a, int b);
public:
void display();
protected:
int m_b;
};
B::B(int a, int b): A(a), m_b(b){
}
void B::display(){
cout<<"m_a="<<m_a<<", m_b="<<m_b<<endl;
}
//直接派生类C
class C: virtual public A{
public:
C(int a, int c);
public:
void display();
protected:
int m_c;
};
C::C(int a, int c): A(a), m_c(c){
}
void C::display(){
cout<<"m_a="<<m_a<<", m_c="<<m_c<<endl;
}
//间接派生类D
class D: public B, public C{
public:
D(int a, int b, int c, int d);
public:
void display();
private:
int m_d;
};
// 这行比较关键 如果去掉A(a), error: no matching function for call to 'A::A()'
D::D(int a, int b, int c, int d): A(a), B(90, b), C(100, c), m_d(d){
}
void D::display(){
cout<<"m_a="<<m_a<<", m_b="<<m_b<<", m_c="<<m_c<<", m_d="<<m_d<<endl;
}
int main(){
B b(10, 20);
b.display();
C c(30, 40);
c.display();
D d(50, 60, 70, 80);
d.display();
return 0;
}
在上面D构造函数初始化的时候,除了调用B和C的构造函数,还调用了A的构造函数。说明D不但要负责初始化直接基类B和C,还要负责初始化间接基类A。 在以往普通多继承,派生类构造函数只负责初始化它直接基类,再由直接基类构造函数初始化间接基类。
现在采用了虚继承,虚基类 A 在最终派生类 D 中只保留了一份成员变量 m_a,如果由 B 和 C 初始化 m_a,那么 B 和 C 在调用 A 的构造函数时很有可能给出不同的实参,这个时候编译器就会犯迷糊,不知道使用哪个实参初始化 m_a。
为了避免出现这种矛盾的情况,C++ 干脆规定必须由最终的派生类 D 来初始化虚基类 A,直接派生类 B 和 C 对 A 的构造函数的调用是无效的。
另外注意,构造函数的执行顺序。 虚继承构造函数的执行顺序和普通继承也不同, 在最终派生类构造函数调用列表中,不管各个构造函数出现的顺序如何,编译器总是先调用虚基类构造函数,再按照声明继承时候各个基类出现的顺序,相应调用他们的构造函数。
8.3 虚继承下的内存模型
对于普通继承,基类成员变量始终在派生类成员变量前面,且不管继承层次多深,相对于派生类对象顶部的偏移量固定。
看个例子:
class A{
protected:
int m_a1;
int m_a2;
};
class B: public A{
protected:
int b1;
int b2;
};
class C: public B{
protected:
int c1;
int c2;
};
class D: public C{
protected:
int d1;
int d2;
};
int main(){
A obj_a;
B obj_b;
C obj_c;
D obj_d;
return 0;
}
这是一个多层单继承, 比较好理解,这时候,内存模型也非常容易画:
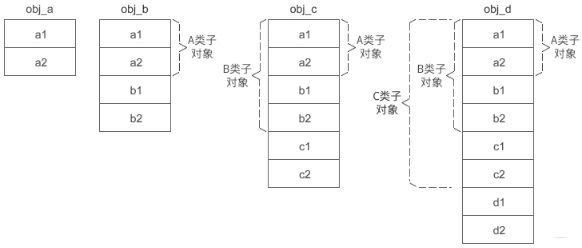
A 是最顶层的基类,在派生类 B、C、D 的对象中,A 类子对象始终位于最前面,偏移量是固定的,为 0。b1、b2 是派生类 B 的新增成员变量,它们的偏移量也是固定的,分别为 8 和 12。c1、c2、d1、d2 也是同样的道理。
编译器在知道对象首地址的情况下,通过计算偏移来存取成员变量。对于普通继承,基类成员变量的偏移是固定的,不会随着继承层级的增加而改变,存取起来非常方便。
但是,对于虚继承,恰恰和普通继承相反,大部分编译器会把基类成员变量放在派生类成员变量的后面,这样随着继承层级的增加,基类成员变量的偏移就会改变,就得通过其他方案计算偏移量
比如,上面假设A是B的虚基类, B是C的虚基类,那么各个对象的内存模型图编程下面这个样子:
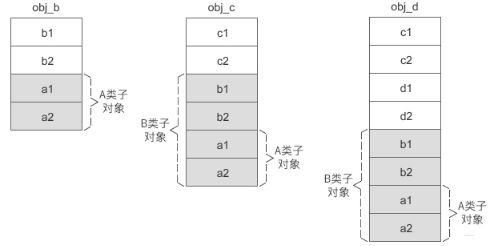
不管是虚基类的直接派生类还是间接派生类,虚基类的子对象始终位于派生类对象的最后面。上面图里面,虚继承时的派生类对象被分成了两部分:
- 不带阴影的一部分偏移量固定,不会随着继承层次增加而改变,称为固定部分
- 带阴影的一部分是虚基类的子对象,偏移量会随着继承层次增加而改变,称为共享部分
当访问对象的成员变量时,需要知道对象的首地址和变量的偏移,对象的首地址很好获得,关键是对象偏移。对于固定部分,偏移是不变的,好计算。 而对于共享部分,偏移会随着继承层次的增加而改变,这就需要设计一种方案,在偏移不断变化过程中准确计算偏移。 各个编译器可能不一样。
对于虚继承,将派生类分为固定部分和共享部分,并把共享部分放在最后,几乎所有的编译器都在这一点上达成了共识。主要的分歧就是如何计算共享部分的偏移,可谓是百花齐放,没有统一标准。
这个比较复杂,只看一类编译器VC的解决。 VC引入了虚基类表,如果某个派生类有一个或多个虚基类,编译器就会在派生类对象中安插一个指针,指向虚基类表。 虚基类表就是一个数组,数组中的元素存放各个虚基类的偏移。
假设A是B的虚基类, B是C的虚基类,那么有了虚基类表的内存模型:
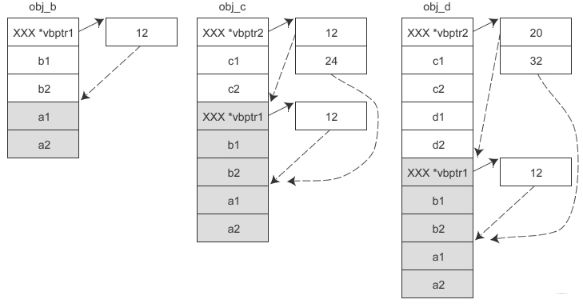
虚继承表中保存的是所有虚基类(直接继承和间接继承)相对于当前对象的偏移,这样通过派生类指针访问虚基类成员变量时,不管继承层次多深,只需要一次间接转换即可。
9. C++向上转型
C++中经常发生数据类型转换,比如int->float, 编译器先把int类型数据转为float再赋值,反过来也是同理, 数据类型转换的前提是编译器知道如何对数据取舍。
类也是一种数据类型,也可以发生数据类型转换,不过这种转换只有在基类和派生类之间才有意义。并且只能派生类赋值给基类(对象,指针,引用), 在C++中称为向上转型。向上转型比较安全,可以由编译器自动完成。
9.1 派生类对象赋值给基类对象
先来个例子:
//基类
class A{
public:
A(int a);
public:
void display();
public:
int m_a;
};
A::A(int a): m_a(a){
}
void A::display(){
cout<<"Class A: m_a="<<m_a<<endl;
}
//派生类
class B: public A{
public:
B(int a, int b);
public:
void display();
public:
int m_b;
};
B::B(int a, int b): A(a), m_b(b){
}
void B::display(){
cout<<"Class B: m_a="<<m_a<<", m_b="<<m_b<<endl;
}
int main(){
A a(10);
B b(66, 99);
//赋值前
a.display();
b.display();
cout<<"--------------"<<endl;
//赋值后
a = b;
a.display();
b.display();
return 0;
}
// 结果
Class A: m_a=10
Class B: m_a=66, m_b=99
----------------------------
Class A: m_a=66 // 这里注意,a的成员m_a的值已经变了
Class B: m_a=66, m_b=99
这里的B继承A, 由于派生类B包含了从基类A继承过来的成员,所以可以将派生对象b赋值给基类对象a。 此时再a.display(), 调用的是a的成员函数,访问的b中继承过来的成员变量。
赋值的本质是将现有的数据写入已分配好的内存,对象的内存只包含成员变量,所以对象之间的赋值时成员变量的赋值,成员函数不存在赋值问题。所以,对象之间的赋值不会影响成员函数,也不会影响this指针。
将派生类对象赋值给基类对象的时候,会舍弃派生类新增的成员。
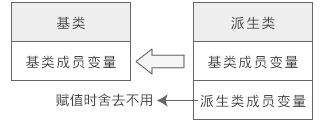
可以发现,即使将派生类对象赋值给基类对象,基类对象也不会包含派生类的成员,所以依然不同通过基类对象来访问派生类的成员。对于上面的例子,a.m_a 是正确的,但 a.m_b 就是错误的,因为 a 不包含成员 m_b。
所以只能用派生类对象给基类对象赋值,而不能用基类对象给派生类对象赋值。因为基类不包含派生类成员变量。
9.2 派生类指针赋值给基类指针
派生类指针可以赋值给基类指针,看个例子:
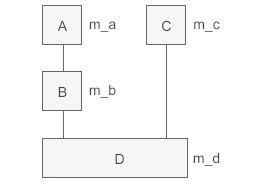
这个翻译成代码就是:
//基类A
class A{
public:
A(int a);
public:
void display();
protected:
int m_a;
};
A::A(int a): m_a(a){
}
void A::display(){
cout<<"Class A: m_a="<<m_a<<endl;
}
//中间派生类B
class B: public A{
public:
B(int a, int b);
public:
void display();
protected:
int m_b;
};
B::B(int a, int b): A(a), m_b(b){
}
void B::display(){
cout<<"Class B: m_a="<<m_a<<", m_b="<<m_b<<endl;
}
//基类C
class C{
public:
C(int c);
public:
void display();
protected:
int m_c;
};
C::C(int c): m_c(c){
}
void C::display(){
cout<<"Class C: m_c="<<m_c<<endl;
}
//最终派生类D
class D: public B, public C{
public:
D(int a, int b, int c, int d);
public:
void display();
private:
int m_d;
};
D::D(int a, int b, int c, int d): B(a, b), C(c), m_d(d){
}
void D::display(){
cout<<"Class D: m_a="<<m_a<<", m_b="<<m_b<<", m_c="<<m_c<<", m_d="<<m_d<<endl;
}
int main(){
A *pa = new A(1);
B *pb = new B(2, 20);
C *pc = new C(3);
D *pd = new D(4, 40, 400, 4000);
pa = pd;
pa -> display();
pb = pd;
pb -> display();
pc = pd;
pc -> display();
cout<<"-----------------------"<<endl;
cout<<"pa="<<pa<<endl;
cout<<"pb="<<pb<<endl;
cout<<"pc="<<pc<<endl;
cout<<"pd="<<pd<<endl;
return 0;
}
// 结果如下
Class A: m_a=4
Class B: m_a=4, m_b=40
Class C: m_c=400
-----------------------
pa=0x9b17f8
pb=0x9b17f8
pc=0x9b1800
pd=0x9b17f8
这个例子里面,尝试将派生类指针赋值给基类指针。与对象变量赋值不同的是,对象指针之间并没有拷贝对象的成员,也没有修改对象本身的数据,仅仅是改变了指针的指向。
所以这个要和对象变量赋值区分开了, 那个地方是会拷贝对象成员的,然后把数据填入,而这里只改变指针的指向。
-
通过基类指针访问派生类的成员
这里要知道将派生类指针赋值给基类指针时,通过基类指针只能使用派生类的成员变量,但不能使用派生类的成员函数, 这里得分析一下了。
上面的pa=pd,pa->display()这行代码,将派生类指针pd赋值给了基类指针pa, 即pa指向了派生类D的对象,所以呢, 在display()内部使用的是D类对象的成员变量,但是呢? 后面调用的成员函数却是基类的。 这是为啥呢?
编译器是通过指针的指向来访问成员变量,但不是通过指针的指向访问成员函数,编译器是通过指针的类型访问成员函数。这个在第二篇成员函数调用整理过。 编译器在编译的时候, 会给这个display()一个新的函数名,并且会传入一个当前对象的指针,通过这个指针访问成员变量。 即new_func_name(A * const p){cout << p->m_a;},这么看就容易理解了, p是A类的指针,指向的是D类对象,所以访问的时候,访问的D类成员变量。
编译器通过指针访问成员变量,指针指向哪个对象就使用哪个对象的数据;
编译器通过指针的l类型访问成员函数,指针属于哪个类的类型就使用哪个类的函数。 -
赋值前后不一致
上面代码里面,将最终派生类的指针pd分别赋值给基类指针pa, pb, pc, 正常来讲,它们指向的同一块内存,值应该相等,但运行结果发现pc比较特殊,和那俩哥们的值并不一样。即pc=pd之后,pc和pd值不相等, why?
赋值是将一个变量的值交给另外一个变量,但注意,赋值以前,编译器可能对现有的值进行处理。比如double类型赋值给int类型,编译器会抹掉小数部分, 导致两边变量值不相等。
派生类指针赋给基类指针的时候也是同理,编译器可能在赋值前进行处理。先看下D类对象的内存模型:
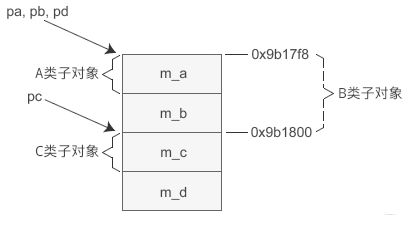
对象的指针必须要指向对象的起始位置。对于A类和B类来说,它们子对象的起始位置和D类对象一样,所以将pd赋值给pa、pb时不需要做任何调整,直接传递现有的值。 而C类子对象距离D类对象的开头有一定偏移,将pd赋值给pc时要加上这个偏移,这样pc才能指向C类子对象的起始位置。 即执行pc=pd,编译器对pd的值进行了调整,导致了pc,pd的不同。pc = (C*)( (int)pd + sizeof(B) );
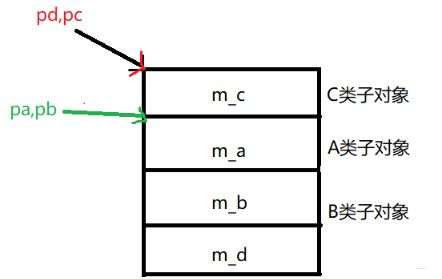
如果将B,C的继承顺序换下class D: public C, public B此时,再输出,结果就变了
pa=0x4a5ed4 pb=0x4a5ed4 pc=0x4a5ed0 pd=0x4a5ed0这个的原因是D类对象的内存模型成了下面这个样子:
所以呢, 原理就是这样啦。
9.3 派生类引用赋值给基类引用
引用本质上通过指针方式实现,基类的指针可以指向派生类对象,那么基类的引用也指向派生类对象,表现和指针类型。
这个就不详细整理了, 引用仅仅是指针简单封装, 只需要注意, 向上转型通过基类的对象,指针和引用只能访问从基类继承过去的成员(成员变量和成员函数),不能访问派生类新增的成员。
10.借助指针突破访问权限的限制
这里再补充一点小知识,算是开阔眼界了,实际中并用不到感觉。
C++不允许通过对象访问private, protected属性的成员变量
class A{
public:
A(int a, int b, int c);
private:
int m_a;
int m_b;
int m_c;
};
A::A(int a, int b, int c): m_a(a), m_b(b), m_c(c){
}
int main(){
A obj(10, 20, 30);
int a = obj.m_a; //Compile Error
A *p = new A(40, 50, 60);
int b = p->m_b; //Compile Error
return 0;
}
但是呢, 我们可以通过更加灵活的指针来突破这个限制。
10.1 偏移
在对象模型中,成员变量和对象的开头位置会有一定的距离,比如上面的obj对象
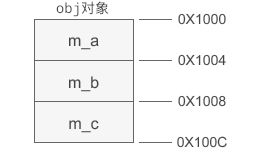
假设它起始地址0x1000, m_a, m_b, m_c与对象开头分别相距0,4,8个字节,这个距离就是偏移。 一旦知道对象的起始位置,加上偏移,就能求出成员变量的地址。知道了成员变量的地址和类型,就能知道值。指针访问成员变量的时候,编译器也是用这种方式取得它的值。

所以,如果将成员变量的访问权限改为public的时候, 此时可以通过对象访问,而访问的背后,就是编译器通过指针偏移,对成员变量的寻址过程,比如:
int b = p->m_b;
// 编译器内部的转换
int b = *(int *)((int)p + sizeof(int));
10.2 突破访问权限限制
我们如果想突破的话呢? 手动计算偏移即可。
比如上面的例子中,主函数修改了:
int main(){
A obj(10, 20, 30);
int a1 = *(int*)&obj;
int b = *(int*)( (int)&obj + sizeof(int) );
A *p = new A(40, 50, 60);
int a2 = *(int*)p;
int c = *(int*)( (int)p + sizeof(int)*2 );
cout<<"a1="<<a1<<", a2="<<a2<<", b="<<b<<", c="<<c<<endl;
return 0;
}
不过,上面这个代码有的编译器编译失败,会报error: cast from 'A*' to 'int' loses precision,这里知道原理就行了, 这种方法还是不要用。
这篇内容有些多了,详细内容还是参考上面的第一个链接。