通过Python + Paddle框架入门机器深度学习(1)
通过Python + Paddle框架入门机器深度学习(1)
小白,自学Python入门,想着弄清楚机器学习是怎么回事。testflow、pytorch太英文了,感觉还是中文社区化的paddle框架更适合于我这种小白入门。
这里记录一些作为入门者需要弄清楚的基本概念与知识点,作为自己的学习笔记,也为了方便与我一样的后来者。
训练集、验证集、测试集
在训练模型(俗称炼丹)时,使用到的数据集是训练集train_dataset与验证集val_dataset,一般比赛课题中拿到的数据集有2种:一种是带标签的数据,一种是不带标签的数据。
带标签的数据,在训练时要分割成训练集与验证集,用于“炼丹”(训练模型);
不带标签的数据,是训练完毕模型后,用来”算命”(预测)用的,它的表标签只有赛事官方知道,用于检验你的模型预测的准确率。
对于带标签的数据,训练集取data中前80%的数据,验证集取data中后20%的数据(比例可以自定)。
all_size = len(data) #获取数据的总长度
train_size = int(all_size * 0.8) # 设定训练集取80%数据
train_data_list = data[:train_size] #训练集取80%的数据放入train_data_list中
val_data_list = data[train_size:] #验证集取剩下的数据(即20%)放入val_data_list中
(pythonic的写法)
self.samples = data[-int(len(data)*0.2):] if is_val else data[:-int(len(data)*0.2)]
数据数量整理
拿到的数据集,不同类别的数量经常是不一样的。例如说需要训练判断图片上是狗还是猫,进行训练时,本应该狗和猫的照片各一半,这样训练效果最好;但实际拿到的不一样时怎么办?
1)将多的图片删除掉,得到一样的最小集(你以为带标签的图片不要钱啊?这么浪费)
2)将少的照片进行处理,得到一样数量的最大集(正解)
# labelshuffling
def labelShuffling(dataFrame, groupByName = 'class_num'):
groupDataFrame = dataFrame.groupby(by=[groupByName]) # 依据类别进行分类(得到的一串'pandas.core.groupby.generic.DataFrameGroupBy'对象)
labels = groupDataFrame.size() # 得到各类型的数据
print("length of label is ", len(labels)) # 对种类数量进行打印
maxNum = max(labels) # 获得数量最多的数据(321)
lst = pd.DataFrame() # 建立空pandas类型数据
for i in range(len(labels)): # 循环打印各个类型的数量,同时对数据进行乱序处理
print("Processing label :", i)
tmpGroupBy = groupDataFrame.get_group(i)
createdShuffleLabels = np.random.permutation(np.array(range(maxNum))) % labels[i]
print("Num of the label is : ", labels[i])
lst=lst.append(tmpGroupBy.iloc[createdShuffleLabels], ignore_index=True)
print("Done")
# lst.to_csv('test1.csv', index=False)
return lst # 返回数据
原理如下,在生成各类别数量一致的数据后,再进行乱序,则可以获得一份优秀的训练集。
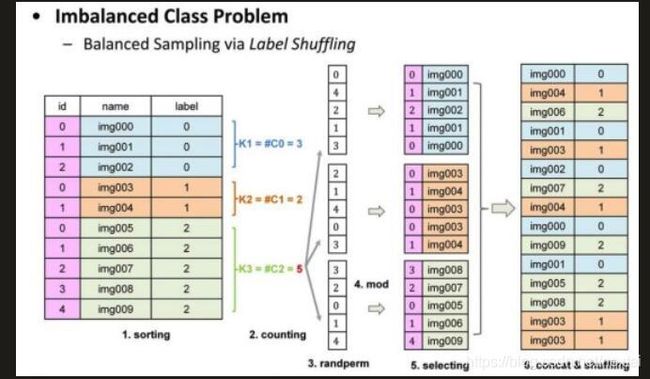
#数据打乱
df = labelShuffling(train_images_list) # 调用上面的函数,对训练集的数据进行乱序(验证集没有必要)
df = shuffle(df) # 对训练集的数据再次乱序
获得最终可用于训练与验证的数据集
定义MyDataset的类,用于获得最终的可使用的数据集
class MyDataset2(paddle.io.Dataset): #继承paddle.io.Dataset类
def __init__(self, mode='train'): #实现构造函数,定义数据读取方式,划分训练和测试数据集
super(MyDataset, self).__init__()
self.data = []
# 借助pandas读csv的库
self.train_images = pd.read_csv('lemon_homework/train.csv', usecols=['id','class_num'])
self.test_images = pd.read_csv('lemon_homework/val.csv', usecols=['id','class_num'])
#数据打乱
self.train_images = labelShuffling(self.train_images)
self.train_images = shuffle(self.train_images)
if mode == 'train':
# 读train.csv中的数据
for row in self.train_images.itertuples():
self.data.append(['lemon_homework/lemon_lesson/train_images/'+getattr(row, 'id'), getattr(row, 'class_num')])
else:
# 读test.csv中的数据
for row in self.test_images.itertuples():
self.data.append(['lemon_homework/lemon_lesson/train_images/'+getattr(row, 'id'), getattr(row, 'class_num')])
def load_img(self, image_path):
# 实际使用时使用Pillow相关库进行图片读取即可,这里我们对数据先做个模拟
image = Image.open(image_path).convert('RGB')
return image
def __getitem__(self, index):
"""
步骤三:实现__getitem__方法,定义指定index时如何获取数据,并返回单条数据(训练数据,对应的标签)
"""
image = self.load_img(self.data[index][0])
label = self.data[index][1]
return data_transforms(image), np.array(label, dtype='int64')
def __len__(self):
"""
步骤四:实现__len__方法,返回数据集总数目
"""
return len(self.data)
#获得最终可用于训练模型的训练数据集与验证数据集
train_dataset = MyDataset(mode='train')
val_dataset = MyDataset(mode='test')
(待续…)