SpringBoot环境下的Apache Dubbo 源码学习第一篇
SpringBoot环境下的ConfigurationClassPostProcessor的工作机制
- 前言
- 自动装配配置类,包括Dubbo提供的
-
- 1. invokeBeanFactoryPostProcessors【IOC容器初始化阶段一】
-
- 1.0 OverrideBeanDefinitionRegistryPostProcessor
- 1.1 ConfigurationClassPostProcessor
-
- 1.1.1 将配置类及其相关类解析成BeanDefinition
-
- 1.1.1.1 从IOC容器中所有的BeanDefinitionName中筛选出是配置类的
- 1.1.1.2 对启动类配置类及其相关配置类@Configuration进行解析
- 1.1.1.3 对SpringBoot和Dubbo提供的自动配置类进行解析
-
- 1.1.1.3.1 MessageSourceAutoConfiguration的解析
- 1.1.1.3.2 PropertyPlaceHolderAutoConfiguration的解析
- 1.1.1.3.3 DubboRelaxedBinding2AutoConfiguration的解析
- 1.1.1.3.4 DubboRelaxedBindingAutoConfiguration的解析
- 1.1.1.3.4 DubboAutoConfiguration的解析
- 1.1.1.4 从配置类中向IOC容器加载BeanDefinitions
前言
Dubbo的服务提供是基于Spring环境下的,服务注册的机制贯穿SpringIOC容器初始化的流程中。这篇文章在讲述Dubbo机制之前,先详述分析一下SpringBoot的自动装配的工作机制。理解@Conditional在SpringBoot自动装配的地位和作用。
自动装配配置类,包括Dubbo提供的
1. invokeBeanFactoryPostProcessors【IOC容器初始化阶段一】
SpringBoot环境下的Spring IOC容器初始化的过程中执行。
/**
* Instantiate and invoke all registered BeanFactoryPostProcessor beans,
* respecting explicit order if given.
* Must be called before singleton instantiation.
*/
protected void invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory beanFactory) {
PostProcessorRegistrationDelegate.invokeBeanFactoryPostProcessors(beanFactory, getBeanFactoryPostProcessors());
// Detect a LoadTimeWeaver and prepare for weaving, if found in the meantime
// (e.g. through an @Bean method registered by ConfigurationClassPostProcessor)
if (beanFactory.getTempClassLoader() == null && beanFactory.containsBean(LOAD_TIME_WEAVER_BEAN_NAME)) {
beanFactory.addBeanPostProcessor(new LoadTimeWeaverAwareProcessor(beanFactory));
beanFactory.setTempClassLoader(new ContextTypeMatchClassLoader(beanFactory.getBeanClassLoader()));
}
}
1.0 OverrideBeanDefinitionRegistryPostProcessor
先执行已经存在的beanFactoryPostProcessors对象,比如Dubbo的OverrideBeanDefinitionRegistryPostProcessor对象,SpringBoot环境中。将这些早于BeanFactory先创建的BeanFactoryPostProcessor对象,创建对应的RootBeanDefinition,并添加到IOC容器中去。
BeanDefinitionRegistry registry = (BeanDefinitionRegistry) beanFactory;
List<BeanFactoryPostProcessor> regularPostProcessors = new ArrayList<>();
List<BeanDefinitionRegistryPostProcessor> registryProcessors = new ArrayList<>();
for (BeanFactoryPostProcessor postProcessor : beanFactoryPostProcessors) {
if (postProcessor instanceof BeanDefinitionRegistryPostProcessor) {
BeanDefinitionRegistryPostProcessor registryProcessor =
(BeanDefinitionRegistryPostProcessor) postProcessor;
registryProcessor.postProcessBeanDefinitionRegistry(registry);
registryProcessors.add(registryProcessor);
}
else {
regularPostProcessors.add(postProcessor);
}
}
其次,从IOC容器中所有的BeanDefinitionNames【在这一步中,不包含用户的,因为此时ConfigurationClassPostProcessor对象还没创建出来,一般是Spring核心对象benaName以及MapperScannerConfigurer对象beanName】中筛选出BeanDefinitionRegistryPostProcessor类型的。对这些符合条件的,进行对象的创建。在这一步中,最终能创建出的对象只有ConfigurationClassPostProcessor以及其他的实现了PriorityOrdered的BeanDefinitionRegistryPostProcessor类型的类,【这一步中是不会创建MapperScannerConfigurer该对象,因为未实现PriorityOrdered】。
// First, invoke the BeanDefinitionRegistryPostProcessors that implement PriorityOrdered.
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
}
}
接着,排序,然后就是执行创建出来的BeanDefinitionRegistryPostProcessor类型的对象。下面着重介绍ConfigurationClassPostProcessor这个Spring的核心类。
1.1 ConfigurationClassPostProcessor
基于注解开发的Spring的核心对象。这个是BeanDefinitionRegistryPostProcessor处理器,是解析@Configuration注解的,实际解析交由ConfigurationClassParser的doProcessConfigurationClass方法来处理。在这个方法中,涉及了被@Configuration声明的类中其他注解的解析,包括@PropertySource,@ComponentScan,@Import,@ImportResource,该声明类中的用@Bean声明的方法的解析等,这些解析,是向将Class文件解析成对应的BeanDefinition,并添加到IOC容器中去。
1.1.1 将配置类及其相关类解析成BeanDefinition
由于ConfigurationClassPostProcessor的postProcessBeanDefinitionRegistry方法简单,这里只讲述一下其方法中的processConfigBeanDefinitions方法,因为这个方法是解析的外部入口。
1.1.1.1 从IOC容器中所有的BeanDefinitionName中筛选出是配置类的
// 获取所有的BeanDefinitionName,这里还是不会包含用户定义的Bean
String[] candidateNames = registry.getBeanDefinitionNames();
for (String beanName : candidateNames) {
BeanDefinition beanDef = registry.getBeanDefinition(beanName);
if (beanDef.getAttribute(ConfigurationClassUtils.CONFIGURATION_CLASS_ATTRIBUTE) != null) {
if (logger.isDebugEnabled()) {
logger.debug("Bean definition has already been processed as a configuration class: " + beanDef);
}
}
// 筛选出是配置类的,进行解析;
// 因为配置类中可能涉及到其他外部类引入资源引入方法中创建bean等外部功能入口
// @PropertySource @ComponentScan @Import @ImportResource @Bean
// 所以要对配置类进行解析
else if (ConfigurationClassUtils.checkConfigurationClassCandidate(beanDef, this.metadataReaderFactory)) {
configCandidates.add(new BeanDefinitionHolder(beanDef, beanName));
}
}
// Return immediately if no @Configuration classes were found
if (configCandidates.isEmpty()) {
return;
}
1.1.1.2 对启动类配置类及其相关配置类@Configuration进行解析
// Parse each @Configuration class
ConfigurationClassParser parser = new ConfigurationClassParser(
this.metadataReaderFactory, this.problemReporter, this.environment,
this.resourceLoader, this.componentScanBeanNameGenerator, registry);
Set<BeanDefinitionHolder> candidates = new LinkedHashSet<>(configCandidates);
Set<ConfigurationClass> alreadyParsed = new HashSet<>(configCandidates.size());
do {
// 此时,从IOC容器中选出符合ConfigurationClass
// 的BeanDefinitionNames进行解析。
// 我是SpringBoot启动的,且应用中再没有@Configuration注解的类,
// 因此,这里的candidates就是我的启动类
// @SpringBootApplication
// @EnableDubbo(scanBasePackages="com.xxx...dubbo")
// public class DubboApacheProviderApplication { ... }
parser.parse(candidates);
parser.validate();
Set<ConfigurationClass> configClasses = new LinkedHashSet<>(parser.getConfigurationClasses());
configClasses.removeAll(alreadyParsed);
// Read the model and create bean definitions based on its content
if (this.reader == null) {
this.reader = new ConfigurationClassBeanDefinitionReader(
registry, this.sourceExtractor, this.resourceLoader, this.environment,
this.importBeanNameGenerator, parser.getImportRegistry());
}
// 加载beanDefinition信息
this.reader.loadBeanDefinitions(configClasses);
alreadyParsed.addAll(configClasses);
candidates.clear();
if (registry.getBeanDefinitionCount() > candidateNames.length) {
String[] newCandidateNames = registry.getBeanDefinitionNames();
Set<String> oldCandidateNames = new HashSet<>(Arrays.asList(candidateNames));
Set<String> alreadyParsedClasses = new HashSet<>();
for (ConfigurationClass configurationClass : alreadyParsed) {
alreadyParsedClasses.add(configurationClass.getMetadata().getClassName());
}
for (String candidateName : newCandidateNames) {
if (!oldCandidateNames.contains(candidateName)) {
BeanDefinition bd = registry.getBeanDefinition(candidateName);
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bd, this.metadataReaderFactory) &&
!alreadyParsedClasses.contains(bd.getBeanClassName())) {
candidates.add(new BeanDefinitionHolder(bd, candidateName));
}
}
}
candidateNames = newCandidateNames;
}
}
while (!candidates.isEmpty());
下面对这个ConfigurationClassParser的parse方法具体阐述。
由于SpringBoot启动类被解析成BeanDefinition,当判断是AnnotatedBeanDefinition,进入第一个解析方法parse(AnnotationMetadata metadata, String beanName)。
if (bd instanceof AnnotatedBeanDefinition) {
// 这三个重载方法,最后都交由processConfigurationClass进行统一处理,因此
// 这三个重载方法做的就是将不同参数对象转换成统一对象ConfigurationClass
parse(((AnnotatedBeanDefinition) bd).getMetadata(), holder.getBeanName());
}
else if (bd instanceof AbstractBeanDefinition && ((AbstractBeanDefinition) bd).hasBeanClass()) {
parse(((AbstractBeanDefinition) bd).getBeanClass(), holder.getBeanName());
}
else {
parse(bd.getBeanClassName(), holder.getBeanName());
}
Spring会对有BeanDefinition转换成的配置类ConfigurationClass做一些处理,这个处理包括Spring提供的条件引入@Conditional,意思就是,需要判断是否达到引入条件等TODO。
if (this.conditionEvaluator.shouldSkip(configClass.getMetadata(), ConfigurationPhase.PARSE_CONFIGURATION)) {
return;
}
接下来需要做的就是将ConfigurationClass转换成SourceClass,并进行配置类的外部引入等的递归处理。这里采用的是do-while循环变相递归。这里注意一下命名规范,比如
doProcessConfigurationClass,做了实际的处理工作,而先前的processConfigurationClass可以简单认为做的是批处理工作。
// Recursively process the configuration class and its superclass hierarchy.
SourceClass sourceClass = asSourceClass(configClass, filter);
do {
sourceClass = doProcessConfigurationClass(configClass, sourceClass, filter);
}
while (sourceClass != null);
接下来,分析一下doProcessConfigurationClass做的事情。先解析的是启动类的。由于启动类上的注解@SpringBootApplication本身就是一个@Component。因此程序会进入到processMemberClasses(configClass, sourceClass, filter)中去,解析配置类中是否有内部类。
if (configClass.getMetadata().isAnnotated(Component.class.getName())) {
// Recursively process any member (nested) classes first
processMemberClasses(configClass, sourceClass, filter);
}
当执行完配置类中内部类的处理后,接着就开始配置类中相关的其他Spring提供的注解的解析工作。
首先,处理的是配置类中声明的@PropertySource。如果启动类中有@PropertySource注解就会处理,常用于将properties文件中定义的键值对添加到Spring容器中去。
接着,处理配置类中声明的@ComponentScan。由于此处解析的是启动类,启动类中的@SpringBootApplication本身其实也是一个ComponentScan。
// Process any @ComponentScan annotations
Set<AnnotationAttributes> componentScans = AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), ComponentScans.class, ComponentScan.class);
... // 省略条件判断逻辑 this.conditionEvaluator.shouldSkip
// 下面就是对获取的每一个ComponentScan进行解析
for (AnnotationAttributes componentScan : componentScans) {
// The config class is annotated with @ComponentScan -> perform the scan immediately
Set<BeanDefinitionHolder> scannedBeanDefinitions =
this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName());
由于启动类中并没有@Conditional条件注解,因此会立即执行扫描包,即用ComponentScannerParser来实际解析,将配置类转换成BeanDefinition,介绍一下该解析的工作机制。这里说明一下,如果不在@SpringBootApplication中特别指定扫描包,SpringBoot采取的机制使用启动类所在的包进行扫描解析。下面是对该Parser的parse方法的介绍。
...
// 由于我这里的@SpringBootApplication没有指定basePackages扫描包路径,因此获取的是空集合
String[] basePackagesArray = componentScan.getStringArray("basePackages");
for (String pkg : basePackagesArray) {
String[] tokenized = StringUtils.tokenizeToStringArray(this.environment.resolvePlaceholders(pkg),
ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS);
Collections.addAll(basePackages, tokenized);
}
// @SpringBootApplication也没有指定basePackageClasses,获取的也是为空
for (Class<?> clazz : componentScan.getClassArray("basePackageClasses")) {
basePackages.add(ClassUtils.getPackageName(clazz));
}
// 这里就是网上初学者,经常搜的说是SpringBoot启动报错,找不到bean,包结构不对
if (basePackages.isEmpty()) {
// 默认的扫描机制是采用启动类所在的包下
basePackages.add(ClassUtils.getPackageName(declaringClass));
}
当这些都做完了以后,开始扫描该包路径下的解析成BeanDefinition。
// 为了方便scanner是什么东东,备注一下ClassPathBeanDefinitionScanner scanner
return scanner.doScan(StringUtils.toStringArray(basePackages));
接下来继续分析ClassPathBeanDefinitionScanner的doScan扫描工作,这个扫描包是一个循环扫描,因为baseScanPackages是一个包路径数组,从包路径下选出符合条件的BeanDefinition,即方法findCandidateComponents(basePackage)。这里,符合条件指的是用@Component注解的类解析成对应的BeanDefinition。接下来介绍一下该方法的工作机制。由于这个方法比较简单,重点在父类的scanCandidateComponents(String basePackage)。因此介绍这个方法的工作机制。这里限于篇幅,删除了一些部分代码。
// 将Java的包结构转换成对应的路径的包搜索类结构
// 比如,basePackage = com.dubbo.apache.provider
// 转换成,packageSearchPath = classpath*:com/dubbo/apache/provider/**/*.class
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
// 接着,根据通过资源读取器找到该搜索路径下的Java的class文件,即FileSystemResource
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
...
// 接着,遍历获取到的每一个Java文件,筛选出@Component的,创建ScannedGenericBeanDefinition
for (Resource resource : resources) {
if (resource.isReadable()) {
// 先获取的是启动类
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
// 筛选出@Component @Service @Configuration的
// 由于启动类在这个方法判断中包含在excludeFilters,因此不再创建BeanDefinition了。
// if (tf.match(metadataReader, getMetadataReaderFactory())) {
// 启动类走的是这个判断逻辑,所以即便启动类中有@SpringBootApplication,也是个@Component
// 但由于excludeFilters中包含了启动类,所以不符合筛选条件
// return false;
// }
// 这个includeFilters的判断逻辑
// if (tf.match(metadataReader, getMetadataReaderFactory())) {
// 基于条件注解的判断@Confitional
// return isConditionMatch(metadataReader);
// } 我这里两个资源文件除了启动类,就是一个UserService类,@Component dubbo的@Service
if (isCandidateComponent(metadataReader)) {
// 因此会对UserService创建ScannedGenericBeanDefinition
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setSource(resource);
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
candidates.add(sbd);
}
}
}
}
当找到了候选的BeanDefinition,还需要对这些BeanDefinition做一些处理。包括为这些BeanDefnition生成beanName,以及注册到IOC容器中去。
...
// 为UserServiceImpl这个BeanDefinition生成beanName,为userServiceImpl
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
// 为这些BeanDefinition填充默认beanDefinition属性
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
// 为这些BeanDefinition填充一些Spring提供的注解所指定的属性,@Lazy等
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
// 为这些BeanDefinition与其对应的beanName做一个映射,这个映射不是用Map而是用BeanDefinitionHolder
// 注意这个细节。而且注意命名方式XXXHolder。【多对映射Map,一对映射Holder】
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
// 将BeanDefinition注册到容器中去。
registerBeanDefinition(definitionHolder, this.registry);
}
当ComponentScannerAnnotationParser的parse完成后,需要对这些Component类再进行检查,是否还有其他的配置注解。我这里的Component类只有一个UserServiceImpl,启动类在之前的一步已经被excludeFilters剔除掉了。
// Check the set of scanned definitions for any further config classes and parse recursively if needed
for (BeanDefinitionHolder holder : scannedBeanDefinitions) {
BeanDefinition bdCand = holder.getBeanDefinition().getOriginatingBeanDefinition();
if (bdCand == null) {
bdCand = holder.getBeanDefinition();
}
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bdCand, this.metadataReaderFactory)) {
// 对该配置类作进一步的解析工作,UserServiceImpl类上其他注解的解析
// 又再次进入parse解析流程,跟之前分析的一样。
// @Component
// @org.apache.dubbo.config.annotation.Service
// public class UserServiceImpl implements UserService
parse(bdCand.getBeanClassName(), holder.getBeanName());
}
}
对该parse方法进行分析,解析Component类中其他的注解。本例中,我的是Component类只有一个UserServiceImpl,因此,此处的解析,就是解析该类的Dubbo的@Service注解。
parse(bdCand.getBeanClassName(), holder.getBeanName());。再次进入processConfigurationClass流程。
// 由于我的UserServiceImpl注解比较简单@Component @Service,
// 因此解析跳过了@PropertySource @ComponentScan 的逻辑
processImports(configClass, sourceClass, getImports(sourceClass), filter, true);
这个getImports由于涉及递归,因此比较复杂,这里介绍一下它的工作机制,也就是collectImports方法的机制。我这里的sourceClass其实就是UserServiceImpl类的。不是启动类的还没到启动类的processImports那一步,但却是启动类的处理@ComponentScan逻辑所触发的。不搞清楚这一点,很容易debug迷失
private void collectImports(SourceClass sourceClass, Set<SourceClass> imports, Set<SourceClass> visited)
throws IOException {
// 由getImports()触发,visited = []
// add调用之后,visited = [SourceClass(UserServiceImpl)]
// collectImports第一次递归触发add
// ,visited = [SourceClass(UserServiceImpl),SourceClass(Object)]
if (visited.add(sourceClass)) {
// sourceClass.getAnnotations()这个方法也比较重要,
// 他的机制是获取非Java和Spring包下的注解
// 我这里的UserServiceImpl 有两个注解 @Component 和 Dubbode @Service
// 经过这个获取后得到的是【Object(替换掉@Component了),@Service】
// 追踪这个方法,替换的是在asSourceClass方法中
// 此时的className = org.springframework.stereotype.Component
// 这个filter:
// private static final Predicate DEFAULT_EXCLUSION_FILTER =
// className -> (className.startsWith("java.lang.annotation.")
// || className.startsWith("org.springframework.stereotype."));
// if (className == null || filter.test(className)) {
// return this.objectSourceClass;
// }
// 1. 刚开始 sourceClass = SourceClass(UserServiceImpl)
// 2. 递归后,sourceClass = SourceClass(Object),此时再次获取Object类
// 上的注解 为空,直接走到imports.addAll(空集合),
// 因为Object类上没有Import注解,此时递归的方法结束
// 开启SourceClass(UserServiceImpl)中的第二次循环
for (SourceClass annotation : sourceClass.getAnnotations()) {
// 第一次遍历时,这里的annotation是SourceClass(Object),
// 这个是Java包下和Spring包下的注解都被替换成Object
// 因此,此时的annName = java.lang.Object
// 第二次遍历时,这里的annotation是SourceClass(UserServiceImpl)
// 因此,此时的annName = org.apache.dubbo.config.annotation.Service
String annName = annotation.getMetadata().getClassName();
// 递归结束标志
if (!annName.equals(Import.class.getName())) {
// 2. 此时的annotation = SourceClass(Object)递归
// 3. 此时的annotation = SourceClass(UserServiceImpl)递归
collectImports(annotation, imports, visited);
}
}
imports.addAll(sourceClass.getAnnotationAttributes(Import.class.getName(), "value"));
}
}
当ConfigurationClassParser对UserServiceImpl的parse解析完后,即parse(bdCand.getBeanClassName(), holder.getBeanName());调用完成,此时又回到ConfigurationClassParser对启动类的解析。如下图。
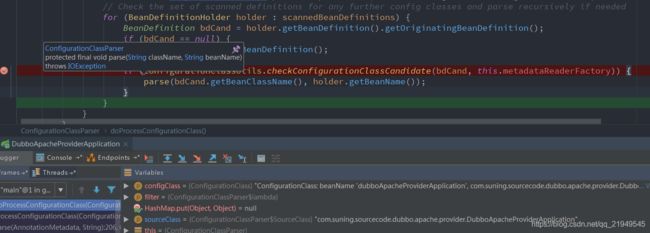
上述过程完成了ConfigurationClassParser对启动类的@ComponentScan的解析处理。
接着,继续由ConfigurationClassParser处理该配置类=启动类,启动类中的@Import注解的BeanDefinition解析。启动类中@SpringBootApplication的内部注解@EnableAutoConfiguration包含了@Import。而下面的getImports这种方法就是处理这种深度包含@Import注解的。由于我的启动类只有两个注解,因此,只能获得@SpringBootApplication下的@Import注解。
// Process any @Import annotations
processImports(configClass, sourceClass, getImports(sourceClass), filter, true);
这个getImports方法有点复杂,涉及递归。由于之前在ConfigurationClassParser对UserServiceImpl的解析时,已经collectImports机制,之前在UserServiceImpl的解析时介绍过一次了。这里,就简单介绍一下各个递归时期sourceClass的值,以便理清递归逻辑,找到规律。
sourceClass = 启动类,此时获取到的注解集合=【SourceClass(@SpringBootApplication),Source(@EnableDubbo)】
- 当对第一个@SpringBootApplication处理时,即for循环第一次:
此时的 annName = org.springframework.boot.autoconfigure.SpringBootApplication,不等于Import.class.getName(),递归处理@SpringBootApplication中包含的其他注解。【每一个注解类就是一个SourceClass,形成了递归关系】
对SourceClass(@SpringBootApplication)递归逻辑:
sourceClass.getAnnotations()返回的注解集合 = 【SourceClass(@SpringBootConfiguration),
SourceClass(@EnableAutoConfiguration),SourceClass(@ComponentScan)】依次处理这三个注解直到找到@Import注解退出当前递归。因此第一次循环会找到的import集合【org.springframework.boot.autoconfigure.AutoConfigurationPackages$Registrar, org.springframework.boot.autoconfigure.AutoConfigurationImportSelector】 - 当对第二个@EnableDubbo处理时,即for循环第二次,同上
- 最终找到的import集合=【org.springframework.boot.autoconfigure.AutoConfigurationPackages$Registrar, org.springframework.boot.autoconfigure.AutoConfigurationImportSelector, org.apache.dubbo.config.spring.context.annotation.DubboConfigConfigurationRegistrar, org.apache.dubbo.config.spring.context.annotation.DubboComponentScanRegistrar, org.apache.dubbo.config.spring.context.annotation.DubboLifecycleComponentRegistrar】
private void collectImports(SourceClass sourceClass, Set<SourceClass> imports, Set<SourceClass> visited)
throws IOException {
if (visited.add(sourceClass)) {
for (SourceClass annotation : sourceClass.getAnnotations()) {
String annName = annotation.getMetadata().getClassName();
if (!annName.equals(Import.class.getName())) {
collectImports(annotation, imports, visited);
}
}
imports.addAll(sourceClass.getAnnotationAttributes(Import.class.getName(), "value"));
}
}
上述getImports()方法执行完后,就开始对集合中的Import引入的类进行处理 ,即processImports。processImports这个方法处理逻辑比较简单,简单介绍一下其工作机制。由于之前已经获取了该配置类(启动类)所有通过@Import引入的类,理所当然的就需要将这些类加入到配置类ConfigurationClass中,实现外部类与配置类之间的关联关系,以便这些外部类能被处理。
接下来,就是对当前处理的配置类是否有通过@ImportResource引入,并加入到配置类ConfigurationClass中。实现外部xml文件与配置类之间的关联关系,以便这些外部xml文件能被处理。
// Process any @ImportResource annotations
AnnotationAttributes importResource =
AnnotationConfigUtils.attributesFor(sourceClass.getMetadata(), ImportResource.class);
if (importResource != null) {
String[] resources = importResource.getStringArray("locations");
Class<? extends BeanDefinitionReader> readerClass = importResource.getClass("reader");
for (String resource : resources) {
String resolvedResource = this.environment.resolveRequiredPlaceholders(resource);
// 将xml文件加入到配置类
configClass.addImportedResource(resolvedResource, readerClass);
}
}
@Bean的处理作用跟上述一样,就不再赘述了。
至此,ConfigurationClass对配置类【启动类】的解析处理已经处理完,接着进行importSelector的处理this.deferredImportSelectorHandler.process();。当这个也处理完,代表着ConfigurationClass对启动类的parse全部完成。下面,分析一下对importSelector处理,因为这里还涉及SpringBoot的自动装配。
public void process() {
// 这个deferredImportSelectors是在processImports中添加进去的
// 这里只有AutoConfigurationImportSelector
List<DeferredImportSelectorHolder> deferredImports = this.deferredImportSelectors;
this.deferredImportSelectors = null;
try {
if (deferredImports != null) {
DeferredImportSelectorGroupingHandler handler = new DeferredImportSelectorGroupingHandler();
deferredImports.sort(DEFERRED_IMPORT_COMPARATOR);
deferredImports.forEach(handler::register);
// 处理自动装配引入的类
handler.processGroupImports();
}
}
finally {
this.deferredImportSelectors = new ArrayList<>();
}
}
追踪这个processGroupImports方法,grouping.getImports()这个方法获取SpringBoot的和我的Dubbo的自动配置。
/**
* Return the imports defined by the group.
* @return each import with its associated configuration class
*/
public Iterable<Group.Entry> getImports() {
// 这个deferredImports = ConfigurationClassParser$DeferredImportSelectorHolder
for (DeferredImportSelectorHolder deferredImport : this.deferredImports) {
// group = AutoConfigurationImportSelector$AutoConfigurationGroup
this.group.process(deferredImport.getConfigurationClass().getMetadata(),
deferredImport.getImportSelector());
}
return this.group.selectImports();
}
继续追踪process方法,根据注解元数据annotationMetadata来获取自动配置实体。AutoConfigurationEntry autoConfigurationEntry = ((AutoConfigurationImportSelector) deferredImportSelector) .getAutoConfigurationEntry(annotationMetadata);具体的工作机制是利用SpringFactoriesLoader,获取所有的SpringBoot默认的自动配置类名,有130个。
/**
* Return the auto-configuration class names that should be considered. By default
* this method will load candidates using {@link SpringFactoriesLoader} with
* {@link #getSpringFactoriesLoaderFactoryClass()}.
* @param metadata the source metadata
* @param attributes the {@link #getAttributes(AnnotationMetadata) annotation
* attributes}
* @return a list of candidate configurati ons
*/
protected List<String> getCandidateConfigurations(AnnotationMetadata metadata, AnnotationAttributes attributes) {
// getSpringFactoriesLoaderFactoryClass() -> EnableAutoConfiguration.class
List<String> configurations = SpringFactoriesLoader.loadFactoryNames(getSpringFactoriesLoaderFactoryClass(),
getBeanClassLoader());
Assert.notEmpty(configurations, "No auto configuration classes found in META-INF/spring.factories. If you "
+ "are using a custom packaging, make sure that file is correct.");
return configurations;
}
获取完所有默认的自动配置类后,再获取SpringBoot提供的三个配置类过滤器,分别是OnClassCondition,OnBeanCondition,OnWebApplicationCondition,然后进行filter顾虑配置。
这是filter的部分代码。
String[] candidates = StringUtils.toStringArray(configurations);
boolean skipped = false;
for (AutoConfigurationImportFilter filter : this.filters) {
// 匹配结果 candidates 130个
// SpringBoot提供的自动配置有764
boolean[] match = filter.match(candidates, this.autoConfigurationMetadata);
for (int i = 0; i < match.length; i++) {
if (!match[i]) {
candidates[i] = null;
skipped = true;
}
}
// 当都匹配结果都为true,比如Spring Boot中对启动类的处理。
if (!skipped) {
// 对启动类的filter匹配就会走这一步
return configurations;
}
}
追踪这3个filter的match的工作机制是在它们的父类FilteringSpringBootCondition中。这里要分清两个变量的含义:autoConfigurationClasses自动配置类,autoConfigurationMetadata自动配置类跟以及相应的要引入的类的对应关系。比如:
自动配置类autoConfigurationClass【要对这个配置类进行bean对象的创建】:org.springframework.boot.autoconfigure.web.servlet.DispatcherServletAutoConfiguration
org.springframework.boot.autoconfigure.amqp.RabbitAutoConfiguration
autoConfigurationMetadata配置类元数据【根据元数据判断是否对这个类进行bean对象的创建】:
org.springframework.boot.autoconfigure.web.servlet.DispatcherServletAutoConfiguration.ConditionalOnClass -> org.springframework.web.servlet.DispatcherServlet
org.springframework.boot.autoconfigure.amqp.RabbitAutoConfiguration.ConditionalClass -> com.rabbitmq.client.Channel,org.springframework.amqp.rabbit.core.RabbitTemplate
@Override
public boolean[] match(String[] autoConfigurationClasses, AutoConfigurationMetadata autoConfigurationMetadata) {
ConditionEvaluationReport report = ConditionEvaluationReport.find(this.beanFactory);
// 获取匹配的结果,这三个filter具体匹配的逻辑由它们各自实现。
ConditionOutcome[] outcomes = getOutcomes(autoConfigurationClasses, autoConfigurationMetadata);
boolean[] match = new boolean[outcomes.length];
for (int i = 0; i < outcomes.length; i++) {
match[i] = (outcomes[i] == null || outcomes[i].isMatch());
if (!match[i] && outcomes[i] != null) {
logOutcome(autoConfigurationClasses[i], outcomes[i]);
if (report != null) {
report.recordConditionEvaluation(autoConfigurationClasses[i], this, outcomes[i]);
}
}
}
return match;
}
- OnClassCondition的getOutComes()工作机制:
- 追踪该类的getOutComes(),采用二分法进行匹配,二分的是这个130个自动配置
- 0-65由新起的线程进行匹配,firstHalfResolver,StandardOutComesResolver
- 65-130由当前线程进行匹配,secondHalfResolver,
- 分别获取这两个解析的结果
- 继续追踪getOutcome(),对于OnConditionalClass来说,获取没有所有OnConditional的配置类的类加载结果。outComes中值为null的代表类加载加载了该配置类,不是为null的代表找不到类,比如
org.springframework.boot.autoconfigure.amqp.RabbitAutoConfiguration自动配置类加载不到@ConditionalOnClass did not find required class 'com.rabbitmq.client.Channel',因此就不会对其进行bean对象的创建。只有当RabbitMQ和Spring AMQP 客户端类库在classpath下,这个RabbitAutoConfiguration才被激活创建。(由于我classpath下没有这两个库,也就导致由StandardOutComesResolver匹配结果解析器对自动配置类RabbitAutoConfiguration匹配的结果为@ConditionalOnClass did not find required class 'com.rabbitmq.client.Channel,红色很显著,嘿嘿。)

- OnWebApplicationCondition的工作机制:
- 追踪该类的getOutcomes()方法,循环处理每一个自动配置类
- 如果在循环的过程中,当前配置类为null,代表该配置类已经被OnClassCondition处理过了而且还是不用对该配置类创建bean对象的。
- 只有不为null的配置类,才进行对其进行结果匹配。
- 举例说明:
autoConfigurationClass=org.apache.dubbo.spring.boot.autoconfigure.DubboAutoConfiguration进行OnWebApplicationCondition结果匹配,根据autoConfigurationMetadata.get(autoConfigurationClass, "ConditionalOnWebApplication")计算其对应的元数据value为null,跳过。
autoConfigurationClass=org.springframework.boot.autoconfigure.web.embedded.EmbeddedWebServerFactoryCustomizerAutoConfiguration进行OnWebApplicationCondition结果匹配,同样计算其对应的元数据为"",该元数据的value即不是SERVLET也不是REACTIVE,且classpath下不存在org.springframework.web.context.support.GenericWebApplicationContext也不存在org.springframework.web.reactive.HandlerResult,返回不存在结果,即@ConditionalOnWebApplication did not find reactive or servlet web application classes
- OnBeanCondition的工作机制:
- 追踪该类的getOutcomes()方法, 循环处理每一个自动配置类
- 如果在循环的过程中,当前配置类为null,代表该配置类已经被OnClassCondition或者OnWebApplicationCondition处理过了而且还是不用对该配置类创建bean对象的。
- 只有不为null的配置类,才进行对其进行结果匹配。先进行ConditionalOnBean的结果匹配,如果为空,再进行ConditionalOnSingleCandidate的结果匹配。
综上当对这130个配置类都进行了过滤后,剩下符合的只有22个配置类,这里的符合指的是要对这22个配置类进行配置类的注解引用其他类等的处理,也就是说完成了grouping.getImports()这个过程。接着对这些配置类进行引入跟解析。
// 22个自动配置类,即SpringBoot引入的
grouping.getImports().forEach(entry -> {
ConfigurationClass configurationClass = this.configurationClasses.get(entry.getMetadata());
try {
// 引入配置类跟之前的处理是一样的,就不再重复介绍处理逻辑了。
// configurationClass 启动类
// exclusionFilter ConfigurationClassParser的默认的filter以及AutoConfigurationImportSelector的ConfigurationClassFilter
// 追踪asSourceClass,filter.test(classType.getName()) 这个filter就是上述的exclusionFilter
// debug的过程中会发现执行后,直接到Predicate的return (t) -> test(t) || other.test(t);
// 这是因为在获取exclusionFilter中,采用的是ConfigurationClassParser的getCandidateFilter
// 即mergedFilter.or(selectorFilter);最终执行的是AutoConfigurationImportSelector的filter
processImports(configurationClass,
// 启动类
asSourceClass(configurationClass, exclusionFilter),
// 通过启动类引入的配置类。这里介绍的是Dubbo的引入。
Collections.singleton(asSourceClass(entry.getImportClassName(), exclusionFilter)),
exclusionFilter, false);
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to process import candidates for configuration class [" +
configurationClass.getMetadata().getClassName() + "]", ex);
}
});
1.1.1.3 对SpringBoot和Dubbo提供的自动配置类进行解析
这里对SpringBoot提供的部分自动配置类及Dubbo提供的自动配置类进行解析。
1.1.1.3.1 MessageSourceAutoConfiguration的解析
接着上述的processImports,继续追踪,processConfigurationClass,对之前一笔带过的this.conditionEvaluator.shouldSkip(configClass.getMetadata(), ConfigurationPhase.PARSE_CONFIGURATION) 进行详细分析。
追踪ConditionEvaluator的shouldSkip方法:
- 由于MessageSourceAutoConfiguration配置类有@Conditional的声明会进行下一步。
- 由于ConfigurationPhase不为null,进行下一步,获取条件类conditionClasses
- 第一个条件类为ResourceBundleCondition,对其进行实例化
- 第二个条件类为OnBeanCondition,对其进行实例化。有小伙伴可能有疑问,这个OnBeanCondition从哪来? MessageSourceAutoConfiguration中只有
@Conditional(ResourceBundleCondition.class),其实是在@ConditionalOnMissingBean中@Conditional(OnBeanCondition.class) - 对获取的Condition进行匹配
- ResourceBundleCondition的匹配,应用的classpath下没有classpath*:messages.properties或者yml中spring.messages.basename定义的等,匹配结果为false,因此跳过对该自动配置类的process
1.1.1.3.2 PropertyPlaceHolderAutoConfiguration的解析
当调用shouldSkip方法时,由于PropertyPlaceHolderAutoConfiguration该类没有@Conditional的声明,因此直接返回false,并处理这个自动配置类。【通过MessageSourceAutoConfiguration和PropertyPlaceHolderAutoConfiguration对比,应该清楚了 @Conditional的工作机制和使用条件了,同时也能清晰的意识到 @Conditional在SpringBoot中对自动装配所起到的地位和作用。】
分析到这,来总结一下,我们如何使用@Conditional或者我们如何自定义一个自动装配?
- AutoConfiguration结尾的配置类
- 将该配置类声明为@Configuration
- 将该配置类声明为@Conditional
- 定义一个~Condition条件类,该类继承SpringBootCondition,并实现匹配结果等相应方法
1.1.1.3.3 DubboRelaxedBinding2AutoConfiguration的解析
当调用shouldSkip方法时,虽然DubboRelaxedBinding2AutoConfiguration该类并没有直接的 @Conditional的声明,但是有间接的声明。
经过计算,总共有两个Condition,@OnClassCondition和@OnPropertyCondition。这两个是SpringBoot提供的条件类,经过追踪该类发现,已经继承了SpringBootCondition。
当执行到!condition.matches(this.context, metadata)时,其实是SpringBootCondition提供的模板方法。【顺带提一下,流程在抽象类,实现类提供具体操作方法】
- OnClassCondition的getMatchOutcome机制:
- 获取ConditionalOnClass注解中引入的name跟value
- 对这些通过@ConditionalOnClass引入的类在当前类加载器下用
ClassNameFilter.MISSING进行filter ,通俗点说,当前类加载器能否找到该类 - ConditionalOnMissingClass同理也是如此
- 条件结果匹配
ConditionOutcome.match(matchMessage);返回匹配结果
- OnPropertyCondition的getMatchOutcome机制:
- 获取ConditionalOnProperty注解中的所有属性
- 对这些属性进行条件结果匹配
1.1.1.3.4 DubboRelaxedBindingAutoConfiguration的解析
匹配机制同理,就不详述了。这里只是简单提一下匹配结果,跟之前ConditionalOnClass的对比,以便更好理解这个注解。匹配结果@ConditionalOnClass did not find required class 'org.springframework.boot.bind.RelaxedPropertyResolver',直接跳过对该配置类的处理。
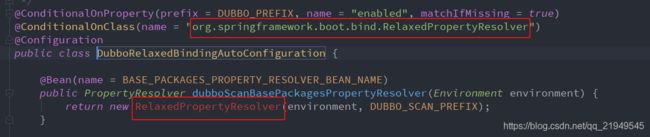
1.1.1.3.4 DubboAutoConfiguration的解析
由于DubboAutoConfiguration也只有一个OnPropertyCondition,且当前应用环境中dubbo.enabled=true。匹配结果为true,对DubboAutoConfiguration进行解析。
由于DubboAutoConfiguration有内部类,因此会调用processMemberClass进行处理。这个处理就是将内部配置类相关注解引用外部类或者bean的xml等进行处理。
1.1.1.4 从配置类中向IOC容器加载BeanDefinitions
当完成了对配置类的解析处理后,紧接着就是将解析后的配置类解析成BeanDefinition,并向IOC中注册。区分一下,之前的parse,是将所有的配置类都解析成公共数据结构ConfigurationClass。现在的解析也即loadBeanDefinition,注意区分,便于理解。
// Read the model and create bean definitions based on its content
if (this.reader == null) {
this.reader = new ConfigurationClassBeanDefinitionReader(
registry, this.sourceExtractor, this.resourceLoader, this.environment,
this.importBeanNameGenerator, parser.getImportRegistry());
}
// 加载这些配置类
this.reader.loadBeanDefinitions(configClasses);
这个加载beanDefinition的方式跟XML的不一样,这是为通过注解加载bean而提供的。对每一个处理过的ConfigurationClass进行bean的加载。但是这里加载的beanDefinition只涉及@Import @ImportResource @Bean等。
接下来,介绍其中的加载逻辑。
- UserServiceImpl的loadBeanDefinition,由于我的UserServiceImpl简单,跳过
- 启动类的loadBeanDefinition
- 启动类引入的AutoConfigurationPackages的BeanDefinition注册,BasePackages
- @EnableDubbo所引入的DubboConfigConfigurationRegistrar的相关BeanDefinition注册,包括DubboConfigConfiguration.Single.class等
- @DubboComponentScan所引入的DubboComponentScanRegistrar的相关BeanDefinition注册,即涉及处理Dubbo的@Service的ServiceAnnotationBeanPostProcessor和处理@Reference的ReferenceAnnotationBeanPostProcessor的BeanDefinition注册。
- @EnableDubboLifecycle所引入的DubboLifecycleComponentRegistrar的相关BeanDefinition注册,即DubboLifecycleComponentApplicationListener和DubboBootstrapApplicationListener
- PropertyPlaceHolderAutoConfiguration的loadBeanDefinition
- 程序运行到此时,该配置类已经被imported了,即之前的process处理。

此时,执行该方法代表,将该配置类作为BeanDefinition向IOC容器中注册。 - 该配置类的通过@Bean所引入的Bean的注入,也有涉及static的@Bean
- 程序运行到此时,该配置类已经被imported了,即之前的process处理。
- DubboAutoConfiguration的处理同上
- 这里有一个EnableConfigurationPropertiesRegistrar所起到的作用就是properties定义的变量跟实体类进行绑定所需要的beanDefinition。【这三张图,是为了我们自己实现自动装配时,properties文件中变量跟实体类的绑定,我们应该怎么实现,葫芦画瓢就可以。】


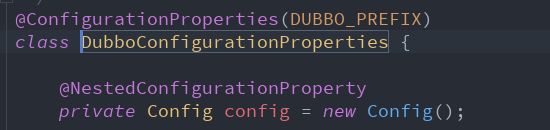
- 这里有一个EnableConfigurationPropertiesRegistrar所起到的作用就是properties定义的变量跟实体类进行绑定所需要的beanDefinition。【这三张图,是为了我们自己实现自动装配时,properties文件中变量跟实体类的绑定,我们应该怎么实现,葫芦画瓢就可以。】