前端组件化
组件化

什么是组件化?
前端组件化开发,就是将页面的某一部分独立出来,将这一部分的数据层(M)、视图层(V)和控制层(C)用黑盒的形式全部封装到一个组件内,暴露出一些开箱即用的函数和属性供外部调用。无论这个组件放到哪里去使用,它都具有一样的功能和样式,从而实现复用(只写一处,处处复用),这种整体化的思想就是组件化。
每个组件都是独立的个体,都只负责一块功能。组件之间互相独立,通过特定的方式进行沟通。外部完全不用考虑组件的内部实现逻辑。一个好的前端组件,必须要把维护性,复用性,扩展性,性能做到极致。
组件化与模块化的区别
从历史发展角度来讲
随着前端开发越来越复杂、对效率要求越来越高,由项目级模块化开发,进一步提升到通用功能组件化开发,模块化是组件化的前提,组件化是模块化的演进
从整体概念来讲
- 模块化是一种分治的思想,述求是解耦,一般指的是 JavaScript 模块,比如用来格式化时间的模块
- 组件化是模块化思想的实现手段,述求是复用,包含了 template,style,script,script又可以由各种模块组成
从复用的角度来讲
- 模块一般是项目范围内按照项目业务内容来划分的,比如一个项目划分为子系统、模块、子模块,代码分开就是模块,位于架构业务框架层,横向分块
- 组件是按照一些小功能的通用性和可复用性抽象出来的,可以跨项目的,是可复用的模块,通常位于架构底层,被其他层所依赖

**从划分的角度来讲**
- 模块是从代码逻辑的角度进行划分,方便代码分层开发,保证每个功能模块的职能单一
- 组件时从 UI 界面的角度进行划分,前端的组件化,方便 UI 组件的重用
为什么要前端组件化
随着前端项目复杂度的急剧增加,我们很容易遇到以下这些场景:
- 页面逻辑越来越多,代码越写越庞大,容易牵一发而动全身
- 同样的逻辑在多个地方重复编写,改一个问题要在多个地方进行同样的修改
以上场景带来的问题就是:
- 项目复杂度增加
- 重复性劳动多,效率低
- 代码质量差,不可控
因此前端组件化可以给我们带来:
- 增加代码的复用性,灵活性
- 提高开发效率,降低开发成本
- 便于各个开发者之间分工协作、同步开发
- 降低系统各个功能的耦合性,提高了功能内部的聚合性
- 降低代码的维护成本
应用组件化需要考虑的问题
- **如何分成各个模块?**我们可以根据业务来进行划分,对于比较大的功能模块可以作为应用的一个模块来使用,但是也应该注意,划分出来的模块不要过多,否则可能会降低编译的速度并且增加维护的难度。
- 如何解决组件之间的隔离?
- 各个模块之间如何进行数据共享和数据通信?
- **如何防止资源名冲突问题?**遵守命名规约就能规避资源名冲突问题。
组件的划分
划分方法
尽可能抽象和解耦。不断抽象出一个跟业务没有关系的模块,它是可以继承的,这就是组件化设计的思维转换。
划分粒度:需要根据实际情况权衡,太小会提升维护成本,太大又不够灵活。
目前还没有一套原则和方法论来指导组件的划分,我们只能根据前人的经验再结合实际情况来进行组件的划分。
关于组件划分的一些建议:
- 组件之间的依赖应该尽可能的少。
- 单个组件代码量最好不要超过1000行。
- 组件划分的依据通常是业务逻辑、功能,要考虑各组件之间的关系是否明确,以及组件的可复用度。
- 每一个组件都应该有其独特的划分目的,有的是为了复用实现,有的是为了封装复杂度、清晰业务实现。
我经常的做法是:如果看到有多个页面都出现了这个重复元素,则抽取成一个组件。还有在开发之中发现结构相似的也可以考虑抽取成一个组件。没有必要在一开始就把所有都抽取成一个个组件。
组件分类
基础UI组件
这是最小化的组件,它们不依赖于其他组件。作为页面中最少的元素而存在,比如按钮、下拉菜单、对话框等。其中大部分是对原生 Web 元素的封装,例如: 、 、 ,它们以简单的形式存在。
在创建基础组件的过程中,要遵循一个基本原则:基础组件是独立存在的。它们可以共享配置,但是不能相互依赖,依赖意味着它不是基础组件。
像 antd、iview、element-ui 里提供的基本都是基础 UI 组件。
复合组件
复合组件是在多个基础的 UI 组件上的进一步结合。大部分复合组件,包含了一些复杂的组件,往往需要花很长的时间,才能变成一个可稳定使用的版本。复合组件包含以下几个部分:
- 表格。表格往往带有复杂的交互,比如固定行、固定列、可编辑、虚拟滚动等。由于其数据量大,往往又对性能有很高的要求。
- 图表。图表的门槛相对比较高,并且种类繁多,对于显示、交互的要求也高。
- 富文本编辑器。几乎是最复杂的组件,其功能需求往往与 Word 进行对比,其代码量可能接近 Word 的数量级。
业务组件
业务组件是我们在实现业务功能的过程中抽象出来的组件,其作用是在应用中复用业务逻辑。当它们涉及一些更复杂的业务情形时,就要考虑是否将这些组件放入组件库中。
通常是根据最小业务状态抽象而出,有些业务组件也具有一定的复用性,但大多数是一次性组件。
特点:UI可配置,业务逻辑完整。有完整的后台流程,数据结构。
组件的隔离
由于前端基础技术栈自身的原因,html 、css 、js 运行在一个页面上时是没有隔离的,也就是说 js 可以根据选择器获取到任意的 dom 节点,一条 css 规则也会应用在文档中所有满足规则的节点, js 代码中可以随意的创建和使用全局变量。
因此,要想实现组件化,我们应该尽可能的去实现每个组件的隔离。
组件隔离其实就是模块化,这里我们需要实现 CSS 模块化和 JS 模块化。
在 vue 中,我们可以为组件中 style 标签增加一个 scoped 的标识, vue-loader 在编译的过程中会为组件每一个元素节点增加 scopeId 作为属性,同时为所有的样式类加上属性选择器 scopeId ,从而达到隔离的效果。如下图:

组件间通信
高内聚低耦合必然会带来数据流动上的壁垒,所以隔离后的组件就要解决组件之间的通信处理。组件通信分为父子组件通信和非父子组件通信,这就涉及到接口设计、事件处理和状态管理三块内容。
在 vue 中,可以使用 props ,事件监听 ,EventBus 的方式来实现组件间的通信。
组件的按需加载
iview 、antd 使用的都是 babel-plugin-import 插件,可以实现组件的按需加载。
本质上就是将对整个库的引用,变为具体模块的引用。这样 webpack 收集依赖模块时就不是整个组件库,而是具体的某个模块了。
如果所用 ui 组件库不符合 babel-plugin-import 的转换规则,可以通过 babel-plugin-import 提供的 customName 字段来自定义转换后的路径。通过 style 字段,来进一步自定义转换后的 style 路径。
怎么设计一个组件
组件的设计原则
- 标准性:任何一个组件都应该遵守一套标准,可以使得不同区域的开发人员据此标准开发出一套标准统一的组件。
- 单一职责原则:一个组件只专注做一件事,且把这件事做好。一个功能如果可以拆分成多个功能点,那就可以将每个功能点封装成一个组件,当然也不是组件的颗粒度越小越好,只要将一个组件内的功能逻辑控制在一个可控的范围内即可。
- 开闭原则:对扩展开放,对修改关闭。属性配置等 API 对外开放,组件内部状态对外封闭。
- 追求短小精悍
- 避免太多参数**,扁平化参数**:除了数据,避免复杂的对象,尽量只接收原始类型的值。
- 合理的依赖关系:父组件不依赖子组件,删除某个子组件不会造成功能异常
- 适用SPOT(Single Point of Truth)法则:尽量不要重复代码
- 追求无副作用
- 复用与易用
- 避免暴露组件内部实现
- 入口处检查参数的有效性,出口处检查返回的正确性
- 稳定抽象原则(SAP)
- 组件的抽象程度与其稳定程度成正比
- 一个稳定的组件应该是抽象的(逻辑无关的)
- 一个不稳定的组件应该是具体的(逻辑相关的)
- 为降低组件之间的耦合度,我们要针对抽象组件编程,而不是针对业务实现编程
- 良好的接口设计,API 尽量和已知概念保持一致
可配置性
一个组件,要明确它的输入和输出分别是什么。
组件除了要展示默认的内容,还需要做一些动态的适配。
要做可配置性,最基本的方式是通过属性向组件传递配置的值,而在组件初始化的声明周期内,通过读取属性的值做出对应的显示修改。还有一些方法,通过调用组件暴露出来的函数,向函数传递有效的值;修改全局 CSS 样式;向组件传递特定事件,并在组件内监听该事件来执行函数等。
在做可配置性时,为了让组件更加健壮,保证组件接收到的是有效的属性、函数接收到的是有效的参数,需要做一些校验。
属性的值的校验
- 属性值的类型是否是有效的
- 属性是否是必填的
函数的参数的校验
函数的参数校验,校验函数的入参和出参。
生命周期
一个组件,需要明确知道在生命周期的不同阶段做该做的事。
初始化阶段,读取属性的值,如果需要做数据和逻辑处理的话,在这个阶段进行。
属性值变化时,如果属性发生变化,且需要对变化后的数据进行处理的话,在这个阶段进行处理。
组件销毁阶段,如果组件已经创建了一些可能会对系统产生一些副作用的东西,可以在这个阶段进行清除。

事件传递
组件接收用户的输入后,需要反馈给外部。
例如一个输入框组件,用户输入数字后,组件需要告诉外部自己接收到了用户的输入,以及输入内容。
输出一般有两种方式:
- 执行回调方法:直接执行 attribute 、 property 传入的 onXXX 方法,并且把数据通过函数传参的方式。大部分开源类库都使用这种方式。
- 事件触发器:使用 EventEmitter ,来触发约定好的事件名。调用方则需要对该事件名进行监听,数据对传到事件监听的回调方法里。
Web Component
在近几年里,Web Components 也被叫做 Custom Elements ,已经变成一个标准让开发者可以仅使用 HTML , CSS 和 JavaScript 来实现一个可复用的组件。这个概念最初于 2011 年提出。最低能在 IE11 上实现 Web Component ,通过 polyfill 的方式。
使用 web component 改变了我们 UI 的架构:
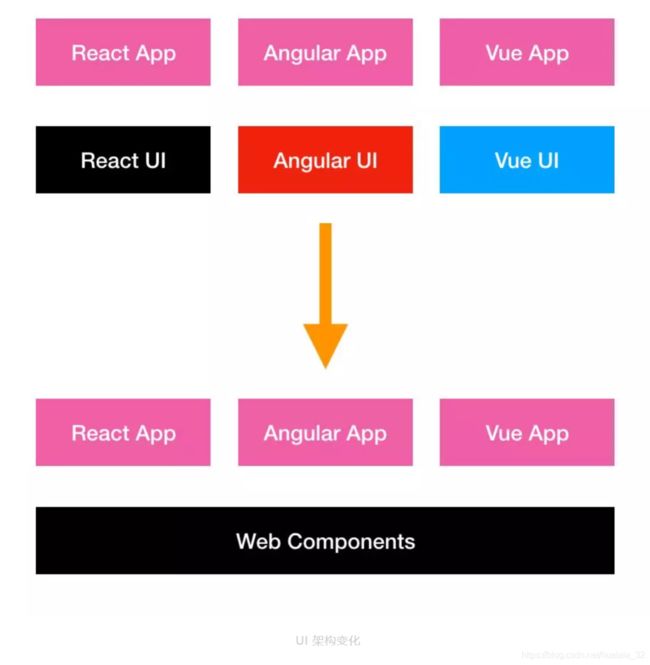
你可以创建自定义的 HTML 标签,它能够从被扩展的 HTML 元素那里继承所有的属性,然后只需要简单地导入一段脚本,就可以在任何支持 Web Component 的浏览器中使用。组件中定义的所有 HTML 、 CSS 和 JavaScript 的定义域都仅限于组件内部。不需要框架,也不需要编译。
组成 web components 技术的四部分:
- Template Element
- Custom Element
- Shadow DOM
- HTML Imports
Template Element
定义组件的 HTML 模板。
本身不会被 html 解析影响文档,只有它的结构被附加到真实的节点上才会影响文档,里面可以写 style 还有 script ,style 里面的 css 不会影响布局, script 里面的脚本不会被执行,并且因为惰性,只能是内联的,不能是外部引入的。
<template>
<style>
button {
display: block;
padding: 0 16px;
font-size: 16px;
width: 100%;
height: 40px;
cursor: pointer;
}
style>
<button>Labelbutton>
template>
template 是用标签包裹着模板内容,不同之处在于获取模板内容的方式,
获取模板内容:
console.log(document.querySelector('template').content);
Custom Element
对外提供组件的标签。
通过 document.createElement 方法来创建自定义元素。w3c 规范规定必须以连字符(-)分隔。
class Button extends HTMLElement {
constructor() {
super();
//...
}
}
window.customElements.define('my-button', Button);
<my-button>my-button>
浏览器兼容性:

Shadow DOM
通过 Shadow DOM 封装组件的内部结构。
什么是 Shadow DOM。
封装使程序员能够限制对某些对象组件的未授权访问。在此定义下,对象以公共访问方法的形式提供接口作为与其数据交互的方式。这样对象的内部表示不能直接被对象的外部访问。
Shdow DOM 将此概念引入 HTML 。它允许你将隐藏的,分离的 DOM 链接到元素。
Shadow Root 是 Shadow 树中最顶层的节点,是在创建 shadow DOM 时被附加到常规 DOM 节点的内容。具有与之关联的 Shadow Root 的节点称为 Shadow Host。我们可以像使用普通 DOM 一样将元素附加到 Shadow Root。链接到 Shadow Root 的节点形成 Shdow 树。如下图:

可以使用 Element.attachShadow() 方法来将一个 shadow root 附加到任何一个元素上。它接受一个配置对象作为参数,该对象有一个 mode 属性,值可以是 open 或者 closed 。open 表示可以通过页面内的 JavaScript 方法来获取 Shadow DOM 。比如使用 Element.shadowRoot 属性。
class Button extends HTMLElement {
constructor() {
super();
// Shadow DOM:将 Shadow Root 附加到 custom element 上。
this._shadowRoot = this.attachShadow({
mode: "open" });
const para = document.createElement('p');
this._shadowRoot.appendChild(para);
}
}
Html imports
控制组件的依赖加载。
使引入组件不再麻烦,传统的引入需要单独引入 css 和 js , html 引入用 link 标签直接引入 html ,一个标签就可以引入一个组件,不管你有多少 css 和 js 文件。
HTML import 为原生 HTML 提供了导入 HTML 文件的功能,使用 link 标签, rel 设置为 import , href 为被导入文件路径。
<link rel="import" href="header.html">
HTML 导入之后不会立即被浏览器解析并渲染,需要手动插入到 DOM 节点,这点跟 CSS 不同
不过很遗憾,现在这个功能得兼容度很不友好。暂不考虑使用。

生命周期回调函数
生命周期方法的顺序:
constructor → attributeChangedCallback → connectedCallback
- connectedCallback:当自定义元素第一次被连接到文档 DOM 时被调用。
- disconnectedCallback:当自定义元素与文档 DOM 断开连接时被调用。
- attributeChangedCallback:当自定义元素的一个属性被增加、移除或更改时被调用。
constructor 和 connectedCallback 的区别在于, constructor 在元素被创建时调用,而 connectedCallback 是在元素真正被插入到 DOM 中时调用。
与connectedCallback 相对的是 disconnectedCallback ,当元素从 DOM 中移除时会调用该方法。在这个方法中可以进行必要的清理工作,但要记住这个方法不一定会被调用,比如用户关闭浏览器或关闭浏览器标签页的时候。
另一个常用的生命周期方法是 attributeChangedCallback 。当属性被添加到 observedAttributes 数组时该方法会被调用。该回调函数仅在属性存在于 observedAttributes 数组中时才会被调用。该方法调用时的参数为属性的名称、属性的旧值和新值:
class MyElement extends HTMLElement {
constructor() {
super();
}
static get observedAttributes {
return ['foo', 'bar'];
}
attributeChangedCallback(attr, oldVal, newVal) {
switch(attr) {
case 'foo':
// do something
case 'bar':
// do something
}
}
}
总结
前端组件化我认为更多的还是要先有组件化的思想才能更好的实践。实现组件化的手段工具有很多,重要的还是要有组件化的思想,编码前多思考。但是又要注意不要过度设计组件。
相关链接
https://juejin.im/post/5dd696765188254dfe47c74a
漫谈Web前端的『组件化』
Web Components(MDN)
谈谈组件设计
javascript组件化
前端架构之路(6) - 组件化
微软官方的 Web Components 组件库
Web Components 入门实例教程 —— 阮一峰
深入理解Shadow DOM v1
Web 组件势必取代前端?