Java开发实习面试笔试题(含答案)
在广州一家中大公司面试(BOSS标注是1000-9999人,薪资2-3k),招聘上写着Java开发,基本没有标注前端要求,但是到场知道是前后端分离人不分离。开始先让你做笔试(12道问答+4道SQL题),接着面试也是八股文之类的,没有问项目,没有做算法,现分享笔试和面试题目给大家做参考。(基础的没复习忘了不会,只会几道感觉已经寄了,最重要的是前端基本不会)
一、笔试内容
1.Java有哪些数据类型,什么是自动装箱和拆箱?
Java有两种类型:基本数据类型和引用数据类型
(1)byte(1字节);short(2字节);int(4字节);long(8字节);float(4字节);double(8字节);char(2字节);boolean(只有两个值true或false);
字节为n, 范围为 -2^(n-1) ~ 2^(n-1) - 1
(2)类(class):如String,Employee等;接口(Interface);数组(Array)
(3)自动装箱是Java编译器自动将基本数据类型转化为对应的包装类对象的过程。例如:
int num = 5;
Integer boxedNum = num; // 自动装箱
拆箱(Unboxing)**是自动将包装类对象转换为基本数据类型的过程。例如:
Integer boxedNum = 5;
int num = boxedNum; // 拆箱
这种机制使得 Java 可以在基本数据类型和其对应的包装类之间进行自动转换,从而简化代码。
2.HashMap和Hashtable有什么区别?
HashMap和Hashtable都是Java中用于存储键值对的哈希表类,区别如下:
(1)线程安全:HashMap不是线程安全的,如果多个线程并发访问HahsMap,并且至少有一个线程做了修改,他必须通过外部同步来保证线程安全,否则可能会导致数据不一致的情况;而Hashtable是线程安全的,他的方法都被synchronized修饰,可以在多线程环境下安全的被访问;
(2)性能:HashMap性能通常优于Hashtable,特别是在单线程环境下;而Hashtable由于方法上都有同步锁,性能较差;
(3)Null值:HashMap允许一个null值(键唯一性)和多个null值;而Hashtable不允许出现null键或null值。
3.String 和 StringBuilder有什么区别?
String 和 StringBuilder 都用于表示和操作字符串,但它们在实现和使用上有一些关键的区别。以下是它们的主要区别:
(1)不可能性和可变性:String是不可变的,一旦被创建,它的内容就不能被更改。如果对String进行修改操作(比如拼接),实际上是创建了一个新的String对象;StringBuilder是可变的,它允许直接修改字符串的内容,而不需要创建新的对象;
(2)性能:由于String不可变,每次修改都会创建一个新的对象,会导致性能的损失;StringBuilder直接修改原值,比String更高效;
(3)线程安全性:String是线程安全的,因为它不可变不会被修改,多个线程可以共享一个String对象;而StringBuilder是线程不安全的,他没有同步机制,多线程环境下同时修改同一个StringBuilder可能会导致数据不一致。
4.int 和 Integer有什么区别?
(1)数据类型:int是Java中的基本数据类型;Integer是Java中的引用类型,是一个包装类;
(2)存储方式:int直接存储数值;Integer是个对象,它内部存储了一个int值;因此int性能更好
(3)可否为null:int不能为null,只能存储一个具体的整数值;Integer可以为null,表示没有值或空的情况
5.error 和 exception有什么区别?
(1)定义和分类:error是指验证的错误,通过是由JVM级别的错误引起的,这些错误通常是无法控制和处理的,比如内存溢出、线程死锁等;exception是指程序中的问题或异常情况,通常是由程序代码中的错误或不符合预期的情况引起的;
(2)继承关系:Error是Throwable类的一个子类,表示JVM无法恢复的严重问题;exception也是Throwable的子类,表示程序中的异常问题,exception可以分为受检查异常(Checked Exception)和运行时异常(Runtime Exception)
(3)能否恢复:Error是不可恢复的,它们代表了无法控制的系统级错误,程序通常无法处理这些错误,JVM 会退出或导致程序崩溃;Exception通常是可恢复的,特别是 Exception 类中的受检查异常。程序员可以捕获并处理这些异常,恢复程序的正常运行。
6.抽象类和接口有什么区别?
抽象类(Abstract Class)和接口(Interface)在 Java 中都用于定义类的公共行为规范,但它们有一些显著的区别。以下是抽象类和接口的主要区别:
(1)继承关系:
-
抽象类:抽象类是一个不能实例化的类,用于定义子类的公共行为和属性。一个类只能继承一个抽象类(Java 不支持多继承)。
-
接口:接口是一个完全抽象的类,只包含常量和抽象方法。一个类可以实现多个接口(Java 支持接口的多实现)。
(2)定义方法:
抽象类:使用 abstract 关键字来声明抽象类,类中可以有普通方法(有实现)和抽象方法(没有实现)。抽象类可以有成员变量、构造方法和其他方法。
public abstract class Animal {
public abstract void makeSound(); // 抽象方法
public void sleep() { // 普通方法
System.out.println("Sleeping");
}
}
接口:使用 interface 关键字来声明接口,接口中的方法默认是 public 和 abstract,并且不能包含方法的实现(Java 8 之后,接口可以包含默认方法 default 和静态方法 static)。接口只能有常量(public static final),不能有实例变量。
public interface Animal {
void makeSound(); // 抽象方法
default void sleep() {
System.out.println("Sleeping");
}
}
(3)方法实现:
-
抽象类:可以包含已经实现的方法,也可以有抽象方法(没有实现)。抽象方法的子类必须实现所有的抽象方法,除非该子类也是抽象类。
-
接口:接口中的方法默认是 抽象的,必须由实现接口的类来实现方法。Java 8 引入了 默认方法(default method),允许接口中有方法的实现。
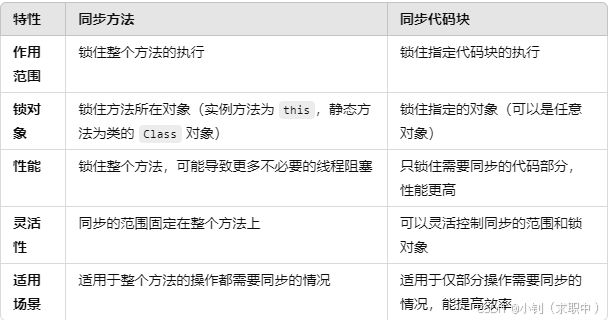
7.同步代码(方法)和同步代码块有什么区别?
同步代码和同步代码块在 Java 中用于保证多线程环境下的数据一致性和线程安全。它们的区别主要体现在 作用范围 和 使用方式 上。以下是它们的主要区别:
(1)同步方法是指在方法定义上使用 synchronized 关键字来标识,这意味着在方法执行时,必须保证同一时刻只有一个线程可以执行该方法。
(2)同步代码块是通过 synchronized 关键字来修饰某一段代码,而不是整个方法。它允许在多线程环境中更加灵活地控制同步的范围,只锁定需要同步的部分代码。
8.创建线程的方式有哪些,你喜欢哪一种,为什么?
(1)继承Thread类并重写run( ) 方法;
(2)实现Runnable接口并实现run方法;
(3)实现Callable接口并实现call( )方法。两个接口的区别为:Runnable接口的run方法没有返回值,而Callable接口是个泛型,它的call方法有返回值,可以利用Futrue来获取结果;Callable接口的call方法允许抛出异常,而Runable接口的run方法的异常只能在内部处理(try-catch),不能向上抛。
(4)创建线程池,使用submit方法提交任务,shutdown方法关闭线程池。
创建线程池比较常用,因为它避免了频繁的创建和销毁线程的开销,可以复用线程,适用于高并发的场景;
9.数据库的优化?
(1)表设计优化
- 选择合适的数据类型,尽量使用最小的数据类型(比如使用INT替代BIGINT,使用CHAR替代VARCHAR)来减少存储和查询成本;
- 分区表:对于数据量极大的表可以考虑分区表,将表按某些规则分割成多个小表,提高查询效率;
- 主从复制、读写分离:如果数据库读的操作比较多,为了避免写操作所造成的性能影响,可以采用读写分离的架构;
(2)索引优化:
- 创建适当的索引,避免过多的索引,查照索引的创建原则;
- 覆盖索引:使用索引覆盖查询,避免回表,调高效率;
(3)SQL语句优化:
- 尽量明确指定需要的列,避免使用SELECT *,以减少不必要的数据传输;
- SQL语句要避免造成索引失效的写法;
- 尽量用union all 替代 union ,union多了一次过滤,效率较低;
- 避免子查询,特别是当子查询返回大量数据时,可以考虑JOIN或WITH子句替代
10.怎么选择表中的前50条数据?
SELECT * FROM table_name LIMIT 50;
11.final, finally, finalize有什么区别?
final、finally 和 finalize 都是 Java 中的关键字或术语,但它们的功能和使用场景完全不同。下面是这三者的区别:
1. final
final 是一个修饰符,用于声明常量、方法、类或变量,表示这些元素是不可更改或不可继承的。它有四种主要用途:
-
修饰变量(常量): 当
final修饰变量时,表示该变量的值一旦赋值就不能更改(即常量)。如果是引用类型的变量,final表示引用不可修改,但引用对象的内容可以修改。
final int MAX_VALUE = 100;
MAX_VALUE = 200; // 编译错误,因为 MAX_VALUE 是常量,不能改变其值
修饰方法: 当 final 修饰方法时,表示该方法不能被子类重写(Override)。
public class Parent {
public final void show() {
System.out.println("This is a final method.");
}
}
public class Child extends Parent {
@Override
public void show() { // 编译错误,无法重写父类中的 final 方法
System.out.println("Child method.");
}
}
修饰类: 当 final 修饰类时,表示该类不能被继承。
public final class MyClass {
// 类的内容
}
// 编译错误,无法继承 final 类
public class SubClass extends MyClass {
}
修饰参数: 当 final 修饰方法参数时,表示该参数的值在方法内部不能改变。
public void myMethod(final int value) {
value = 10; // 编译错误,value 是 final,不能修改
}
2. finally
finally 是一个用于异常处理的块,它总是会执行,不管是否发生异常。finally 主要用于释放资源、清理操作等,无论是否发生异常,都确保资源被正确释放。
finally语句块通常与try-catch配合使用,确保某些资源的清理操作(如文件关闭、数据库连接关闭等)始终会执行,即使try块中发生了异常。-
public void myMethod() { try { // 可能抛出异常的代码 int result = 10 / 0; } catch (ArithmeticException e) { System.out.println("Error: " + e.getMessage()); } finally { System.out.println("This will always execute, whether or not an exception occurs."); } }输出:
-
Error: / by zero This will always execute, whether or not an exception occurs.如果
try或catch中有return语句,finally块仍然会执行,且在finally块执行之后再返回结果。
3. finalize
finalize 是 Object 类的一个方法,用于在对象被垃圾回收之前执行清理操作。该方法在垃圾回收器准备销毁对象之前调用,通常用于释放资源,如关闭文件流或数据库连接等。它不是强制执行的,不一定每次都会被调用。
finalize()方法通常不建议使用,因为垃圾回收的时机不确定,而且无法保证一定会被调用。现在更多推荐使用try-with-resources语句和AutoCloseable来进行资源管理。-
public class MyClass { @Override protected void finalize() throws Throwable { System.out.println("finalize() method called. Resource cleanup..."); super.finalize(); } }finalize()可能会被 JVM 在垃圾回收时自动调用,或者由开发者显式调用,但这不应作为释放资源的主要方法,因为垃圾回收的时机不确定。
12. char 和 varchar有什么区别?
char 和 varchar 都是用于存储字符数据的 SQL 数据类型,但它们有一些显著的区别,主要体现在 存储方式、占用空间 和 性能 等方面。以下是它们的详细区别:
1. 存储方式
-
char:用于存储定长(固定长度)的字符串。无论实际存储的数据的长度如何,都会使用指定的长度来存储数据。即使存储的字符串长度小于定义的长度,char也会在末尾填充空格(通常是空格字符)。- 例如,定义
char(10),如果插入的数据是"abc",它会自动补充 7 个空格,使得存储的实际数据变为"abc "。
- 例如,定义
-
varchar:用于存储变长(可变长度)的字符串。它只会根据实际存储的数据的长度来占用空间,不会填充空格。- 例如,定义
varchar(10),如果插入的数据是"abc",它只会占用 3 个字符的空间,而不会填充空格。
- 例如,定义
2. 占用空间
-
char:无论实际存储的字符串长度是多少,它都会占用固定的字节数。比如定义char(10),不管你存储的是 3 个字符还是 10 个字符,它都会占用 10 个字符的空间。 -
varchar:只会根据实际存储的数据长度来占用空间,不会浪费空间。例如,定义varchar(10)存储 3 个字符时,只会占用 3 个字符的空间。
3. 性能
-
char:由于是定长字段,因此在读取数据时,数据库知道每个字段的长度是固定的,因此读取速度可能比varchar更快,尤其是在存储大量小数据(如固定格式的字符数据)时。 -
varchar:由于是变长字段,数据库需要存储每个字符串的实际长度,因此可能会有一些额外的开销。不过,当存储的字符串长度差异很大时,varchar更节省空间,性能表现会更好。
13.一个接口可以实现另一个接口吗?
在 Java 中,一个接口 不能实现 另一个接口,但它可以 继承 另一个接口。
14. 一个类可以继承多个类吗?
在 Java 中,一个类 不能继承多个类。这是 Java 的一个重要特性,称为 单继承。也就是说,一个类只能继承自一个直接父类。
15.String a = new String("123"); 这条语句创建了几个String Object?
在 Java 中,语句 String a = new String("123"); 如果字符串常量池已经存在就创建一个,不存在就创建了 两个 String 对象,分别是:
-
一个字符串常量对象:
"123"是一个字符串常量。每当你在代码中使用字符串字面量(如"123")时,Java 会检查字符串常量池中是否已经存在该字符串。如果没有,它会创建一个新的字符串对象并将其存储在字符串常量池中。 -
一个新的
String对象:new String("123")会创建一个新的String对象,该对象是通过构造函数显式地创建的,并且该对象的内容是"123"。这个对象是在堆内存中创建的。
"123":在字符串常量池中创建了一个字符串对象(如果之前没有创建过)。new String("123"):在堆内存中创建了一个新的String对象,内容为"123",并且该对象引用了常量池中的"123"。
二、面试内容
1.能说一下你对redis的理解吗,几种数据缓存的应用为什么要使用redis?
对 Redis 的理解
Redis(Remote Dictionary Server)是一个开源的内存数据存储系统,常用作数据库、缓存和消息中间件。它支持多种数据结构,比如 字符串、哈希、列表、集合、有序集合、位图、HyperLogLog 和 地理位置 等,提供了高性能的数据存取能力,广泛应用于 缓存、会话管理、分布式锁、消息队列 等场景。
Redis 主要特点包括:
- 高性能:通过内存存储,Redis 在数据读写方面速度非常快,能够支持每秒数十万次读写操作。
- 支持丰富的数据类型:不仅支持常见的字符串类型,还支持哈希、列表、集合等多种复杂的数据结构。
- 持久化机制:Redis 提供了两种持久化方式(RDB 和 AOF),可以根据需求选择是否持久化数据。
- 分布式特性:支持主从复制、分片和高可用集群等功能,能够在分布式系统中有效地扩展。
- 支持事务:通过 Redis 提供的事务机制,可以保证多个命令的原子性执行。
为什么要使用 Redis 进行数据缓存
Redis 被广泛用作缓存系统,原因如下:
-
高性能:
- Redis 作为一个基于内存的数据存储,读取和写入操作速度极快,适用于需要高并发和快速响应的场景。例如,缓存数据库查询结果或频繁访问的数据时,Redis 能显著提高性能,减少数据库压力。
-
减少数据库负载:
- 在高并发系统中,数据库可能成为性能瓶颈。通过将热数据缓存在 Redis 中,可以有效减轻数据库的压力,避免频繁的磁盘访问和复杂查询,减少数据库负载,提高整个系统的响应速度和吞吐量。
-
支持丰富的数据结构:
- Redis 提供了多种数据结构(如哈希、列表、集合、排序集合等),这使得它不仅仅是一个简单的 key-value 存储。可以根据具体需求选择不同的数据结构,提升缓存系统的灵活性。
-
分布式特性:
- Redis 支持主从复制和分布式集群,能够在分布式架构中横向扩展,满足大规模数据缓存的需求。可以通过 Redis Cluster 实现数据的分片,保证数据的高可用性和负载均衡。
-
持久化机制:
- Redis 提供了持久化选项(RDB 快照和 AOF 日志),即使发生故障,数据也不会丢失,适合需要缓存数据持久化的场景。比如,存储用户的购物车数据,尽管是缓存,但如果系统宕机,用户数据依然可以恢复。
2.说一下spring的核心是什么?
-
依赖注入(Dependency Injection,DI)
- 依赖注入是 Spring 框架的核心功能之一,它通过控制反转(IoC,Inversion of Control)来实现。传统的开发中,组件通常会显式地创建其依赖的对象,而 Spring 的 IoC 容器则负责管理对象的生命周期及其依赖关系。
- 简化开发:通过将对象的创建和管理交给 Spring 容器,开发者只需要关注业务逻辑,而无需手动创建和管理对象的实例。
- 解耦:对象之间的依赖关系由 Spring 容器管理,而不是硬编码在代码中,这样可以降低模块之间的耦合度,提高代码的灵活性和可测试性。
依赖注入方式:
- 构造器注入:通过构造器传递依赖对象。
- Setter 注入:通过 setter 方法注入依赖对象。
- 字段注入:直接在字段上使用注解来注入依赖。
-
面向切面编程(Aspect-Oriented Programming,AOP)
- AOP 允许通过横切关注点(如日志、事务管理等)来分离业务逻辑,减少代码重复。Spring 的 AOP 功能使得开发者可以在不修改核心业务代码的情况下添加额外的功能(例如日志记录、性能监控、事务管理等)。
- 切面(Aspect):AOP 的核心组成部分,表示对特定功能(如日志、事务等)的抽象。
- 通知(Advice):定义在切点上执行的操作。
- 切点(Joinpoint):程序执行过程中的某个点,例如方法调用或方法执行之前、之后等。
- 织入(Weaving):将切面应用到目标对象的过程。
-
Spring 的 IoC 容器
- IoC 容器是 Spring 的核心容器,它负责管理 Bean 的创建、配置和生命周期。容器通过配置文件(如 XML 配置文件)或注解(如
@Component、@Autowired等)来扫描和注入依赖。 - Bean:在 Spring 中,管理的对象被称为 Bean。Spring 容器负责这些 Bean 的实例化、配置和管理。
- ApplicationContext:
ApplicationContext是 Spring 容器的一个实现,提供了更强大的功能(如事件传播、国际化支持等)。
- IoC 容器是 Spring 的核心容器,它负责管理 Bean 的创建、配置和生命周期。容器通过配置文件(如 XML 配置文件)或注解(如
3.说一下Linux的一些基本命令?
Linux 是一个功能强大的操作系统,广泛应用于服务器和开发环境中。了解一些基本的 Linux 命令对于日常的系统管理和开发工作非常重要。下面是一些常用的 Linux 基本命令及其功能:
文件和目录操作命令
-
ls:列出目录内容ls:列出当前目录的文件和文件夹。ls -l:显示详细的文件信息(权限、所有者、大小、修改时间等)。ls -a:显示所有文件,包括隐藏文件(以点.开头的文件)。ls -lh:显示详细信息,并且以可读性更高的方式显示文件大小(例如:KB、MB)。
-
cd:改变目录cd <目录路径>:切换到指定目录。cd ..:返回到上一级目录。cd ~:切换到用户的主目录。
-
pwd:显示当前工作目录的路径pwd:打印当前的工作目录路径。
-
mkdir:创建目录mkdir <目录名>:创建一个新目录。
-
rmdir:删除空目录rmdir <目录名>:删除指定的空目录。
-
rm:删除文件或目录rm <文件名>:删除文件。rm -r <目录名>:递归删除目录及其内容。rm -f <文件名>:强制删除文件,不询问确认。
-
touch:创建空文件或更改文件时间戳touch <文件名>:创建一个空文件,或者更新现有文件的访问时间和修改时间。
-
cp:复制文件或目录cp <源文件> <目标文件>:复制文件。cp -r <源目录> <目标目录>:递归复制目录。
-
mv:移动或重命名文件/目录mv <源文件/目录> <目标路径>:将文件或目录移动到指定路径,或者重命名文件。
-
find:查找文件find <路径> -name <文件名>:在指定路径下查找指定名称的文件。find . -name "*.txt":在当前目录及其子目录中查找所有.txt文件。
文件内容查看和操作命令
-
cat:查看文件内容cat <文件名>:查看文件的内容。
-
more:分页显示文件内容more <文件名>:分页显示文件内容,适用于文件内容较多的情况。
-
less:分页显示文件内容(比more更强大)less <文件名>:与more类似,但可以向前和向后滚动,支持更多的交互功能。
-
head:查看文件的开头部分head <文件名>:查看文件的前 10 行。head -n 20 <文件名>:查看文件的前 20 行。
-
tail:查看文件的末尾部分tail <文件名>:查看文件的最后 10 行。tail -n 20 <文件名>:查看文件的最后 20 行。tail -f <文件名>:实时查看文件的新增内容(常用于日志文件)。
-
grep:在文件中查找指定的字符串grep <关键词> <文件名>:查找文件中包含指定关键词的行。grep -r <关键词> <目录>:递归查找目录中的文件。
-
wc:统计文件中的字数、行数和字符数wc <文件名>:输出文件的行数、字数、字符数。wc -l <文件名>:仅统计文件的行数。
文件权限和所有者管理命令
-
chmod:修改文件或目录的权限chmod <权限> <文件名>:修改文件或目录的权限。chmod 755 <文件名>:将文件权限设置为可读、可写、可执行(对于所有者),可读、可执行(对于其他用户)。
-
chown:修改文件或目录的所有者chown <用户>:<用户组> <文件名>:修改文件或目录的所有者和用户组。
-
chgrp:修改文件或目录的用户组chgrp <用户组> <文件名>:将文件或目录的用户组更改为指定组。
系统信息命令
-
ps:查看当前正在运行的进程ps:显示当前终端的进程信息。ps aux:显示所有进程信息。ps -ef:显示所有进程信息(Linux 系统常用格式)。
-
top:实时查看系统资源使用情况top:实时显示进程和系统资源的使用情况(CPU、内存等)。
-
df:查看磁盘空间df:显示文件系统的磁盘空间使用情况。df -h:以人类可读的格式(如 GB、MB)显示磁盘空间。
-
du:查看磁盘使用情况du <目录>:查看目录及其子目录的磁盘使用情况。du -sh <目录>:显示目录的总大小。
-
free:查看内存使用情况free:显示系统的内存使用情况。free -h:以人类可读的格式显示内存使用情况。
-
uptime:查看系统运行时间和负载uptime:显示系统的运行时间、当前时间、用户数和系统负载。
-
hostname:查看或设置主机名hostname:显示当前系统的主机名。hostname <新主机名>:设置系统的主机名。
网络命令
-
ping:测试与目标主机的网络连接ping:发送 ICMP 请求,检查与目标主机的连接是否正常。
-
ifconfig(旧版命令)/ip(新版本命令):查看或配置网络接口ifconfig:显示网络接口的配置信息。ip a:显示网络接口信息。ip addr show:显示 IP 地址和网络接口的信息。
-
netstat:显示网络连接、路由表、接口统计等信息netstat:显示所有网络连接的状态。netstat -tuln:显示所有正在监听的端口。
-
curl:与服务器进行数据交互curl:发送 HTTP 请求并显示返回的响应。curl -I:仅获取 HTTP 响应头。
-
ssh:远程登录到服务器ssh <用户名>@<主机IP>:通过 SSH 协议远程登录到指定主机。
进程管理命令
-
kill:终止进程kill <进程ID>:发送信号终止指定的进程。kill -9 <进程ID>:强制终止指定进程。
-
killall:根据进程名终止进程killall <进程名>:终止所有名为<进程名>的进程。
-
bg:将任务放到后台执行bg <作业号>:将暂停的作业放到后台继续执行。
-
fg:将任务放到前台执行fg <作业号>:将后台的作业调到前台。
压缩和解压命令
-
tar:打包和解包tar -cvf <压缩包名> <目录>:将指定目录打包成.tar文件。tar -xvf <压缩包名>:解压.tar文件。
-
gzip/gunzip:压缩和解压.gz文件gzip <文件名>:压缩文件成.gz格式。gunzip <文件名.gz>:解压