【架构笔记】Android 内存泄漏知识点汇总
检测内存是否泄漏非常简单,只要在任意位置调用 Debug.dumpHprofData(file) 即可,通过拿到 hprof 文件进行分析就可以知道哪里产生了泄漏,但 dump 的过程会 suspend 所有的 java 线程,导致用户界面无响应,所以又不能随意 dump。为了能找到合理的 dump 时机,leakCanary 就采用预判的方式,在 onDestroy 中先检测一下当前 Activity 是否存在泄漏的风险,如果有这种情况,就开始 dump。需要注意的是,在 onDestroy 做检测仅仅只是预判,一种时机,并不能断定真的发生了泄漏,真正的泄漏需要通过分析 hprof 文件才能知晓。
hprof 是由 JVM TI Agent HPROF 生成的一种二进制文件,文件格式可以查看 Binary Dump Format:
一、如何预判内存泄漏
- 主动检测法
- 阈值检测法
1、主动检测法
- Activity 的检测预判
- Service 的检测预判
- Bitmap 大图的检测预判
1、Activity 的检测预判 LeakCanary 中对 Activity 的预判是在 onDestroy 生命周期中通过弱引用队列来持有当前 Activity 引用,如果在主动触发 gc 之后,泄漏对象集合中仍然能找到该引用实例,则说明发生了内存泄漏,就开始 dump
2、Service 的检测预判 LeakCanary 对 Service 的内存泄漏检测时机,是 hook 监听 ActivityThread 的 stopService,然后记录这个 binder 到弱引用集合中,然后代理 AMS 的 serviceDoneExecuting 方法,通过 binder 在弱引用集合中去移除,移除成功的话,说明发生了内存泄漏,就开始 dump
3、Bitmap 大图检测预判 Bitmap 不像 Activity、Service 这种,能够通过生命周期主动监测当前是否有内存泄漏的可能,他一般是在 Activity、Service 发生泄漏 dump 的时候,顺便检测一下 Bitmap 。在 Koom 中,Bitmap 大图检测是分析 hprof 中是否有超过 Bitmap 设置的阈值 size (width * height)
2、阈值检测法
阈值检测法的代表框架是 Koom,他抛弃了 LeakCanary 的实时检测性,采用定时轮训检测当前内存是否在不断累加,增长达到一定次数(可自己配置)时会进行 dump hprof,这种方式会牺牲一定的时效性,但对于应用到线上的 Koom 的框架,他完全不需要这么高的时效性
二、如何分析内存泄漏
分析工具代表:
- MAT
- Android Studio
- HaHa
- Matrix
- LeakCanary 1.x
- shark
- Liko
- Koom
- LeakCanary 2.x
1、MAT
MAT 工具下载可点击链接 ,Android 生成的 dump 需要做一下转换才能被 MAT 识别,转换指令:
hprof-conv
<新生成的文件>
eg:
hprof-conv android.hprof mat.hprof
hprof-conv 跟 adb 在同一个文件夹下,配置了 adb 命令的可以直接用这个命令执行。
MAT 查内存泄漏会有点费劲,毕竟是个 java 通用工具,并不会指明告诉你是哪个 Activity 发生了泄漏,但可以分析个大概。
一般泄漏的都是比较大的实例:
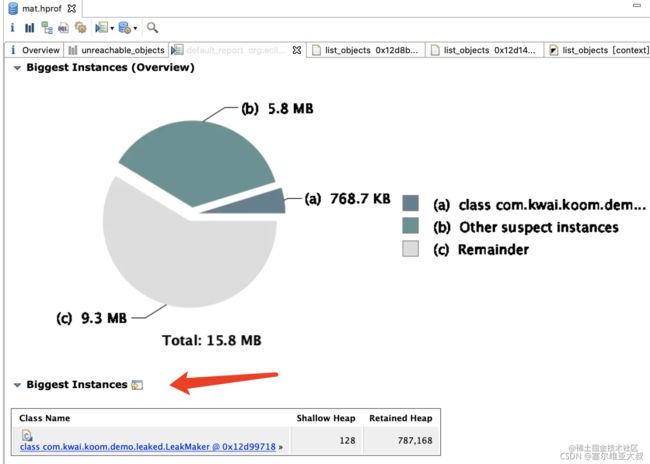
点击类名进入查看:
在这里插入图片描述
ActivityLeakMaker 占用了近 190944 byte 的内存空间,并且引用链里面有 Activity 相关的内容,切回代码来看问题,原来是静态变量持有了 Activity 实例导致:
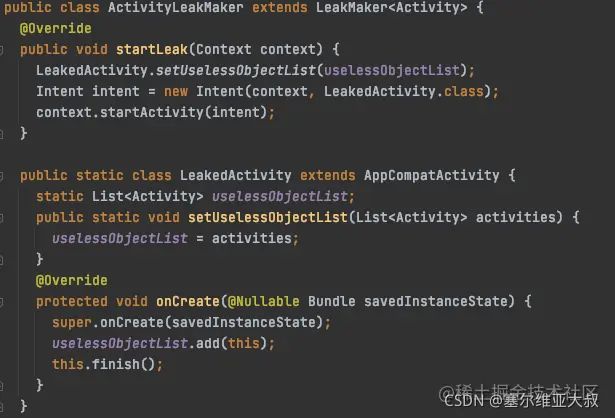
2、Android Studio
Android Studio 的 Profiler 工具支持 hprof 的解析,并且很智能的提示当前 leak 了哪些对象,打开方式很简单,将 hprof 文件拖拽至 as,然后双击 hprof 文件即可:

我们可以很直观的看到,当前 LeakedActivity 和 ReportFragment 发生了泄漏。
如果我们的需求仅仅只是在开发阶段进行内存泄漏检测的话,并且又不想接入 LeakCanary(因为有时候想调试下自己模块的代码,其他模块经常报内存泄漏,冻结当前线程,很影响调试),那么我们可以在应用里面埋个彩蛋,比如单击 5 次版本号,然后调用 Debug.dumpHprofData ,然后将 hprof 文件导出到 as 进行分析,这就将原本可能会进行数次 dump 的过程,改成了自己需要去检测的时候再去 dump。
3、HaHa
在 LeakCanary 的第一版的时候,是采用的 Haha 库来分析泄漏引用链,但由于后面新出的 Shark,比 HaHa 快 8 倍,并且内存占用还要少 10 倍,但查找泄漏路径的大致步骤与 Shark 无异,故此文就不分析 HaHa 了。
4、Shark
Shark 是 square 团队开发的一款全新的分析 hprof 文件的工具,其官方宣布比 Android Studio 用于 memory profiler 的核心库 perflib 要快 8 倍并且内存占用少 10 倍,更加适合手机端的分析工具。其目的就是提供快速解析hprof文件和分析快照的能力,并找出真正的泄漏对象以及对象到GcRoot 的最短引用路径链,以便帮助开发者更加直观的找出泄漏的真正原因。 – 引用自《LeakCanary2.0解析》
看了下 Koom 分析引用链的过程,大致可以分为以下几个步骤:
- 分析 hprof 文件,获取镜像所有的 instance 实例
- 遍历所有的实例,判断这个实例与各个 Detectors 是否有存在泄漏,如果有,则记录 objectId 到集合
- 根据 objectId 集合获取各个泄漏实例引用链,分析出 gcRoot,并遍历 gcRoot 下的引用路径
这个地方重点在于如何找到泄漏的 objectId,因为找到 objectId,即可找到泄漏引用链。在分析 hprof 的时候我们可以拿到 dump 时的内存实例,那么,我们可以根据这个实例来判断是否泄漏,例如:
- Activity : 判断实例是否是 android.app.Activity 的子类,并且 mFinished 或 mDestroyed 是否为 true (Activity 关闭时该值会为 true),因为 Activity 不泄露的话肯定是会被释放,所以,不可能存在于 dump 的实例中,有就是发生了泄漏
- Bitmap : 获取实例的类名称是否为 android.graphics.Bitmap,如果是的话,则获取实例的 mWidth 和 mHeight 实例变量,计算两者的乘积是否超过阈值,是的话,也判定为泄漏
- … (更多判断可以看 analysis 目录的各个 Detector)
Shark 根据 objectId 分析出的引用链路径:
┬───
│ GC Root: Local variable in native code
│
├─ android.os.HandlerThread instance
│ Leaking: UNKNOWN
│ ↓ HandlerThread.contextClassLoader
│ ~~~~~~~~~~~~~~~~~~
├─ dalvik.system.PathClassLoader instance
│ Leaking: UNKNOWN
│ ↓ PathClassLoader.runtimeInternalObjects
│ ~~~~~~~~~~~~~~~~~~~~~~
├─ java.lang.Object[] array
│ Leaking: UNKNOWN
│ ↓ Object[].[197]
│ ~~~~~
├─ com.kwai.koom.demo.leaked.ActivityLeakMaker$LeakedActivity class
│ Leaking: UNKNOWN
│ ↓ static ActivityLeakMaker$LeakedActivity.uselessObjectList
│ ~~~~~~~~~~~~~~~~~
├─ java.util.ArrayList instance
│ Leaking: UNKNOWN
│ ↓ ArrayList.elementData
│ ~~~~~~~~~~~
├─ java.lang.Object[] array
│ Leaking: UNKNOWN
│ ↓ Object[].[0]
│ ~~~
╰→ com.kwai.koom.demo.leaked.ActivityLeakMaker$LeakedActivity instance
• Leaking: YES (This is the leaking object), Signature: 39f4102649e5d3a5be12db591c2e5f68a1c0d2e9
三、如何应用于线上
1、解决 dump 冻结问题
由于 dump hprof 会暂停所有 java 线程问题,致使 LeakCanary 只能应用于线下检测。但 Koom 和 Liko 另辟蹊径,采用 linux 的 copy-on-write 机制,从当前的主线程 fork 出一个子进程,然后在子进程进行 dump 分析,对于用户所在的进程不会有任何感知。
这个地方会有个坑,就是在 fork 子进程的时候 dump hprof。由于 dump 前会先 suspend 所有的 java 线程,等所有线程都挂起来了,才会进行真正的 dump。由于 copy-on-write 机制,子进程也会将父进程中的 threadList 也拷贝过来,但由于 threadList 中的 java 线程活动在父进程,子进程是无法挂起父进程中的线程的,然后就会一直处于等待中。
为了解决这个问题,Koom 和 Liko 采用欺骗的方式,在 fork 子进程之前,先将父进程中的 threadList 全部设置为 suspend 状态,然后 fork 子进程,子进程在 dump 的时候发现 threadList 都为挂起状态了,就立马开始 dump hprof,然后父进程在 fork 操作之后,立马 resume 恢复回 threadList 的状态
2、解决混淆问题
Shark 支持混淆反解析,思路也很简单,解析 mapping.txt 文件,每次读取一行,只解析类和字段:
- 类特征 :行尾为
:冒号结尾,然后根据->作为 index 分割,左边的为原类名,右边的为混淆类名 - 字段特征:行尾不为
:冒号结尾,并且不包含(括号(带括号的为方法),即为字段特征,根据->作为 index 分割,左边为原字段名,右边的为混淆字段名
将混淆类名、字段名作为 key,原类名、原字段名作为 value 存入 map 集合,在分析出内存泄漏的引用路径类时,将类名和字段名都通过这个 map 集合去拿到原始类名和字段名即可,即完成混淆后的反解析
leakCanary 内部是写死的 mapping 文件为 leakCanaryObfuscationMapping.txt,如果打开该文件失败,则不做引用链反解析:
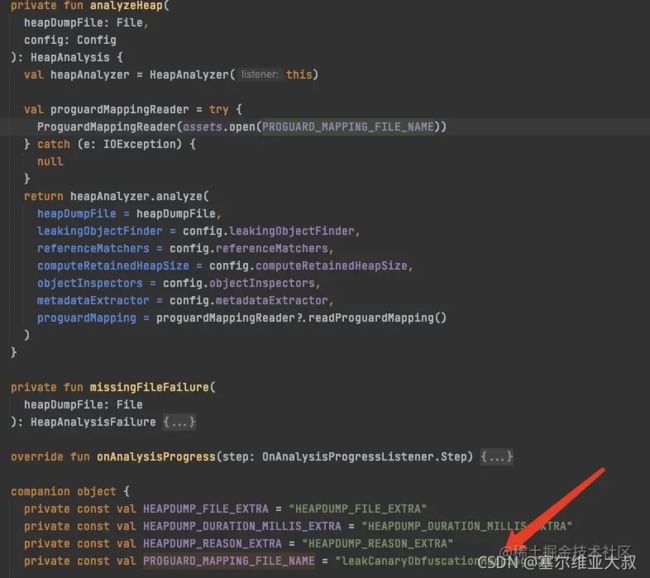
也即意味着,如果想 LeakCanary 支持混淆反解析,只需要将自己的 mapping 文件重命名为 leakCanaryObfuscationMapping.txt,然后放入 asset 目录即可
对于 Koom 的混淆反解析,Koom 并没有做,但我们可以自己去加这块代码:
private boolean buildIndex() {
...
try {
// 新增 ---------- start
InputStream is = KGlobalConfig.getApplication().getResources().getAssets().open("mapping.txt");
ProguardMapping mapping = new ProguardMappingReader(is).readProguardMapping();
// 新增 ---------- end
heapGraph = HprofHeapGraph.Companion.indexHprof(hprof, mapping,
kotlin.collections.SetsKt.setOf(gcRoots));
} catch (Exception e) {
e.printStackTrace();
}
return true;
}
将 mapping.txt 文件放到 asset 目录即可,如下是混淆与混淆反解析的引用链的对比:

3、泄漏兜底
在预判内存泄漏发生时,我们可以将 Activity 中引用到的 Bitmap、DrawingCache 等进行主动释放,以此来降低泄漏的影响面。做法是,在 Activity onDestory 时候从 view 的 rootview 开始,递归释放所有子 view 涉及的图片、背景、DrawingCache、监听器等等资源,让 Activity 成为一个不占资源的空壳,泄露了也不会导致图片资源被持有,eg:
...
Drawable d = iv.getDrawable();
if (d != null) {
d.setCallback(null);
}
iv.setImageDrawable(null);
...
...
但这一点对于阈值检测法的 Koom 来说,没办法做到,因为他拿不到 onDestroy 时的 Activity 实例,但也不要紧,我们可以将兜底操作做成通用操作,不管他泄漏与不泄露,都做 view 相关引用的卸载。
四、总结:
整体下来,分析个内存泄漏其实并不难,难就难在我们平时并没有养成好的习惯,对于引用的传递考虑的不周全,但我们可以加强自身的编码习惯,尽量减少项目中的泄漏问题